一种文本相似度确定方法与流程
本发明涉及人工智能领域,特别是指一种文本相似度确定方法。
背景技术:
目前,自然语言处理是人工智能领域内的一个困难重重同时引人注目的研究课题,理想结果就是能够使计算机像人那样理解、分析自然语言,从而解决文本分类、句法分析、语义理解、情感识别、语义推理等实际问题。
在智能对话引擎领域当中,因为存在不同客户口音、音量等问题,特别是在电话通信语音质量不高的情况下,很难实现语音识别的精准。
技术实现要素:
本发明要解决的技术问题是提供一种文本相似度确定方法,以解决现有技术所存在的语音识别精准度低的问题。
为解决上述技术问题,本发明实施例提供一种文本相似度确定方法,包括:
将预先确定的知识库中的单位名称用拼音表示;
接收用户输入的文本,提取接收到的所述文本中的单位名称并用拼音表示;
将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度;
根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识,其中,每条知识包括:单位名称。
进一步地,所述拼音表示包括:汉字的拼音表示,数字的拼音表示或英文字母的拼音表示;
其中,所述汉字的拼音表示包括:多音字的拼音表示和非多音字的拼音表示。
进一步地,在提取接收到的所述文本中的单位名称并用拼音表示之前,所述方法还包括:
对接收到的所述文本进行清洗,其中,所述清洗包括:去标点符号、去停用词、简称替换、英文和数字大小写的转换。
进一步地,所述将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度包括:
以汉字、数字或英文字母的拼音为基本单位,将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算两个拼音文本的最长公共子序列长度,其中,所述两个拼音文本包括:用拼音表示的所述文本中的单位名称和用拼音表示的所述知识库中的单位名称;
根据得到的两个拼音文本的最长公共子序列长度,计算两个拼音文本的相似度评分。
进一步地,所述计算两个拼音文本的最长公共子序列长度包括:
从两个拼音文本选定其中一个作为主文本,另外一个为从文本;
判断主文本的长度是否大于或者等于从文本的长度;
若主文本的长度大于或者等于从文本的长度,则利用第一公式计算主文本和从文本的最长公共子序列长度;其中,所述第一公式表示为:
其中,c[i][j]表示主文本xi和从文本yj的最长公共子序列的长度;xi={x1,x2,…,xm,…,xi},yj={y1,y2,…,yn,…,yj},i、j分别表示xi、yj的长度,m<i,n<j;c[i-1][j-1]表示主文本xi-1和从文本yj-1的最长公共子序列的长度;c[i][j-1]表示主文本xi和从文本yj-1的最长公共子序列的长度;c[i-1][j]表示主文本xi-1和从文本yj的最长公共子序列的长度。
进一步地,所述方法还包括:
若主文本的长度小于从文本的长度,以主文本的长度为基准长度,得出从文本具有所述基准长度的子串序列;
计算每个子串序列与主文本的最长公共子序列长度;
从各子串序列与主文本的最长公共子序列长度中,取长度最大值为主文本和从文本的最长公共子序列长度。
进一步地,通过第二公式,取长度最大值为主文本和从文本的最长公共子序列长度;其中,所述第二公式表示为:
其中,yk表示将从文本以主文本的长度为基准长度,得出从文本具有所述基准长度的子串序列k;c[[xi]][yk]表示主文本xi和子串序列yk的最长公共子序列的长度;lcsmax(xi,yj)表示主文本xi和从文本yj的最长公共子序列的长度。
进一步地,通过第三公式,计算两个拼音文本的相似度评分;其中,所述第三公式表示为:
其中,sim表示两个拼音文本的相似度评分,lcsmax(xi,yj)表示主文本xi和从文本yj的最长公共子序列长度,j表示yj的长度。
进一步地,所述根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识包括:
确定知识库中知识排序的其他因素,其中,所述其他因素包括:地址和部门;
按照得到的基于拼音的最长公共子序列的相似度由高到低进行第一次排序,从所述知识库中提取前若干条具有相同单位名称的知识;
对提取的具有相同单位名称的若干条知识,加入地址评分进行第二次排序,地址评分越高者,排序到越靠前的位置;
在第二次排序结果的基础上,针对单位名称和地址都相同的知识,加入部门评分进行第三次排序,部门评分越高者排序到越靠前的位置。
进一步地,所述在第二次排序结果的基础上,针对单位名称和地址都相同的知识,加入部门评分进行第三次排序,部门评分越高者排序到越靠前的位置还包括:
若部门评分都相同,则按照设定好的优先部门排序规则进行排序。
本发明的上述技术方案的有益效果如下:
上述方案中,将预先确定的知识库中的单位名称用拼音表示;接收用户输入的文本,提取接收到的所述文本中的单位名称并用拼音表示;将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度;根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识,其中,每条知识包括:单位名称。现有技术得到的语音识别结果往往是字错音准,这样,采用拼音进行匹配能够提高匹配精度,从而解决语音识别精准度低的问题;且基于拼音的最长公共子序列的相似度对知识库中的知识进行排序,能够进一步提高从所述知识库中选出的知识与用户输入的文本的匹配精度。
附图说明
图1为本发明实施例提供的文本相似度确定方法的流程示意图;
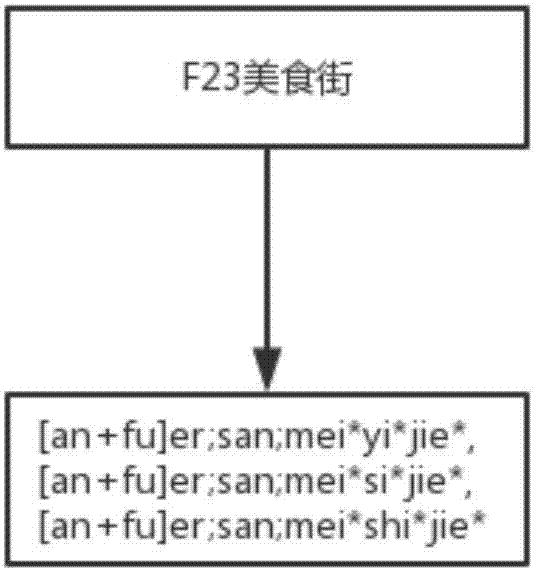
图2为本发明实施例提供的f23美食街的拼音表示示意图;
图3为本发明实施例提供的排序算法示意图;
图4为本发明实施例提供的114查询智能客服对话系统的结构示意图;
图5为本发明实施例提供的智能语义对话引擎的功能示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明针对现有的语音识别精准度低的匹配的问题,提供一种文本相似度确定方法。
实施例一
如图1所示,本发明实施例提供的文本相似度确定方法,包括:
s101,将预先确定的知识库中的单位名称用拼音表示;
s102,接收用户输入的文本,提取接收到的所述文本中的单位名称并用拼音表示;
s103,将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度;
s104,根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识,其中,每条知识包括:单位名称。
本发明实施例所述的文本相似度确定方法,将预先确定的知识库中的单位名称用拼音表示;接收用户输入的文本,提取接收到的所述文本中的单位名称并用拼音表示;将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度;根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识,其中,每条知识包括:单位名称。现有技术得到的语音识别结果往往是字错音准,这样,采用拼音进行匹配能够提高匹配精度,从而解决语音识别精准度低的问题;且基于拼音的最长公共子序列的相似度对知识库中的知识进行排序,能够进一步提高从所述知识库中选出的知识与用户输入的文本的匹配精度。
本实施例中,所述知识库中存储着已知的知识,每条知识包括但不限于:单位名称。
在前述文本相似度确定方法的具体实施方式中,进一步地,所述拼音表示包括:汉字的拼音表示,数字的拼音表示或英文字母的拼音表示;
其中,所述汉字的拼音表示包括:多音字的拼音表示和非多音字的拼音表示。
本实施例,例如,用户输入的文本为f23美食街,则f23美食街的拼音表示可以如图2所示,图2中“[]、;、;、,*”是为了区分是什么字符转成了拼音,括号“[]”表示英文字母转成了拼音,分号“;”表示是数字转成了拼音,星号“*”表示是汉字转成了拼音,逗号“,”区分的是当有多音字时文本转成拼音的排列组合。计算最长公共子序列的时候这些符号是去除的,不参与计算。
在前述文本相似度确定方法的具体实施方式中,进一步地,在提取接收到的所述文本中的单位名称并用拼音表示之前,所述方法还包括:
对接收到的所述文本进行清洗,其中,所述清洗包括:去标点符号、去停用词、简称替换、英文和数字大小写的转换。
本实施例中,对接收到的所述文本进行去标点符号(会影响输入文本的长度)、去停用词(例如帮我、电话等这些词)、简称替换(例如,中行转成中国银行)、英文和数字大小写的转换等操作,以数字大小写转换为例,大写“一”可以转换为小写“1”,大写“九”可以转换为小写“9”等。在实际应用中,可以根据实际情况对输入的文本进行清洗操作,可以去除输入文本中不必要的信息,使得匹配结果的更加精准。
在前述文本相似度确定方法的具体实施方式中,进一步地,所述将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算基于拼音的最长公共子序列的相似度包括:
以汉字、数字或英文字母的拼音为基本单位,将用拼音表示的所述文本中的单位名称与用拼音表示的所述知识库中的每个单位名称一一进行匹配,计算两个拼音文本的最长公共子序列长度,其中,所述两个拼音文本包括:用拼音表示的所述文本中的单位名称和用拼音表示的所述知识库中的单位名称;
根据得到的两个拼音文本的最长公共子序列长度,计算两个拼音文本的相似度评分。
本实施例中,可以利用动态规划算法计算两个拼音文本的最长公共子序列长度。本实施例中,计算最长公共子序列长度的基本单位不是单个字符,而是以汉字、数字、或英文字母的拼音为基本单位。具体计算方法如下:
设拼音文本(也可以称为:序列)x={x1,x2,…,xm}和y={y1,y2,…,yn}的最长公共子序列为z={z1,z2,…,zk},其中,xi={x1,x2,…,xm,…,xi},yj={y1,y2,…,yn,…,yj},x是xi的子串序列,y是yj的子串序列,每个序列的元素都是一个字符的拼音表示,则:
若xm=yn,则zk=xm=yn,且zk-1是xm-1和yn-1的最长公共子序列,其中,xm-1={x1,x2,…,xm-1},yn-1={y1,y2,…,yn-1},zk-1={z1,z2,…,zk-1};
若xm≠yn且zk≠xm,则z是xm-1和y的最长公共子序列;
若xm≠yn且zk≠yn,则z是x和yn-1的最长公共子序列。
由最长公共子序列的问题的最优子结构可知,当xm=yn时,找出是xm-1和yn-1的最长公共子序列,然后在其尾部加上xm(=yn)即可得x和y的最长公共子序列。当xm≠yn时,必须解两个子问题,即找出xm-1和y的一个最长公共子序列及x和yn-1的一个最长公共子序列。这两个公共子序列中较长者即为x和y的最长公共子序列。
由此递归结构容易看到最长公共子序列问题具有子问题重叠性质。首先建立子问题最优值的递归关系。用c[i][j]记录拼音文本xi和拼音文本yj的最长公共子序列的长度;其中,xi={x1,x2,…,xm,…,xi},yj={y1,y2,…,yn,…,yj},i、j分别表示xi、yj的长度,m<i,n<j。当i=0或j=0时,空序列是xi和yj的最长公共子序列,故此时c[i][j]=0。在其他情况下,由最优子结构性质可建立递归关系(第一公式)如下:
其中,c[i][j]表示主文本xi和从文本yj的最长公共子序列的长度;xi={x1,x2,…,xm,…,xi},yj={y1,y2,…,yn,…,yj},i、j分别表示xi、yj的长度,m<i,n<j;c[i-1][j-1]表示主文本xi-1和从文本yj-1的最长公共子序列的长度;c[i][j-1]表示主文本xi和从文本yj-1的最长公共子序列的长度;c[i-1][j]表示主文本xi-1和从文本yj的最长公共子序列的长度。
在前述文本相似度确定方法的具体实施方式中,进一步地,所述计算两个拼音文本的最长公共子序列长度包括:
从两个拼音文本选定其中一个作为主文本,另外一个为从文本;
判断主文本的长度是否大于或者等于从文本的长度;
若主文本的长度大于或者等于从文本的长度,则利用第一公式计算主文本和从文本的最长公共子序列长度;其中,所述第一公式表示为:
其中,c[i][j]表示主文本xi和从文本yj的最长公共子序列的长度;xi={x1,x2,…,xm},yj={y1,y2,…,yn},i、j分别表示xi、yj的长度,m<i,n<j;c[i-1][j-1]表示主文本xi-1和从文本yj-1的最长公共子序列的长度,c[i][j-1]表示主文本xi和从文本yj-1的最长公共子序列的长度,c[i-1][j]表示主文本xi-1和从文本yj的最长公共子序列的长度。
在前述文本相似度确定方法的具体实施方式中,进一步地,所述方法还包括:
若主文本的长度小于从文本的长度,以主文本的长度为基准长度,得出从文本具有所述基准长度的子串序列;
计算每个子串序列与主文本的最长公共子序列长度;
从各子串序列与主文本的最长公共子序列长度中,取长度最大值为主文本和从文本的最长公共子序列长度。
本实施例中,例如,主文本为1234,从文本为1234567,则以主文本1234的长度为基准长度,得出从文本1234567具有所述基准长度的子串序列包括:1234、2345、3456、4567等;将主文本1234和子串序列1234;主文本1234和子串序列2345,主文本1234和子串序列3456,主文本1234和子串序列4567分别计算最长公共子序列长度,并从计算结果中,取长度最大值为主文本1234和从文本1234567的最长公共子序列长度。
在前述文本相似度确定方法的具体实施方式中,进一步地,通过第二公式,取长度最大值为主文本和从文本的最长公共子序列长度;其中,所述第二公式表示为:
其中,yk表示将从文本以主文本的长度为基准长度,得出从文本具有所述基准长度的子串序列k;c[[xi]][yk]表示主文本xi和子串序列yk的最长公共子序列的长度;lcsmax(xi,yj)表示主文本xi和从文本yj的最长公共子序列的长度。
在前述文本相似度确定方法的具体实施方式中,进一步地,通过第三公式,计算两个拼音文本的相似度评分;其中,所述第三公式表示为:
其中,sim表示两个拼音文本的相似度评分,lcsmax(xi,yj)表示主文本xi和从文本yj的最长公共子序列长度,j表示yj的长度。
本实施例中,根据得到的两个拼音文本的最长公共子序列长度,计算两个拼音文本的相似度评分,具体的:本实施例根据相关理论得出了如下相似度计算公式,
其中,sim表示两个拼音文本的相似度评分,lcsmax(xi,yj)表示主文本xi和从文本yj的最长公共子序列长度,i,j分别表示xi、yj的长度。
对于本实施例的应用场景,对于每一轮的相似度评分计算,主文本的拼音序列长度是一定的,并且计算相似度是为了进行排序,所以以上公式可以化简为:
在前述文本相似度确定方法的具体实施方式中,进一步地,所述根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识包括:
确定知识库中知识排序的其他因素,其中,所述其他因素包括:地址和部门;
按照得到的基于拼音的最长公共子序列的相似度由高到低进行第一次排序,从所述知识库中提取前若干条具有相同单位名称的知识;
对提取的具有相同单位名称的若干条知识,加入地址评分进行第二次排序,地址评分越高者,排序到越靠前的位置;
在第二次排序结果的基础上,针对单位名称和地址都相同的知识,加入部门评分进行第三次排序,部门评分越高者排序到越靠前的位置。
本实施例中,根据得到的基于拼音的最长公共子序列的相似度,对所述知识库中的知识进行排序的同时,还需考虑其他因素,例如,地址和部门,在实际应用中,还可以考虑其他因素,考虑的因素由实际情况确定。
本实施例中,如图3所示,可以根据预设的排序规则和确定的排序因素,对所述知识库中的知识进行排序,从所述知识库中选出与用户输入的文本最相近的一条知识,具体步骤可以包括:
首先,按照得到的基于拼音的最长公共子序列的相似度由高到低进行第一次排序,从所述知识库中提取前若干条具有相同单位名称的知识;
然后,对提取的具有相同单位名称的若干条知识,加入地址评分进行第二次排序,提取的具有相同单位名称的若干条知识中,地址评分越高者,排序到越靠前的位置;具体的:拿地址的最后一个字和用户输入的文本进行匹配,匹配到了就往前取x个字,x是知识库中地址的文本长度,然后和知识库中的地址进行匹配;
例如,用户输入的文本为“学院路的中国银行”,知识库中有“学院路,中国银行”、“知春路中国银行”、“院路中国银行”。用户输入的文本与知识库中的第一条的地址评分就是学院和学院对比,评分是2;第二条的地址评分是学院和知春,评分是0;第三条的地址评分就是院和院,评分是1;那么得到的排序结果为:“学院路,中国银行”、“院路中国银行”、“知春路中国银行”。
最后,在第二次排序结果的基础上,针对单位名称和地址都相同的知识,加入部门评分进行第三次排序,部门评分越高者排序到越靠前的位置,如果部门评分都相同,则按照设定好的优先部门排序规则进行排序;
例如,部门优先顺序为“办公室、客服、后勤”;用户问“北科大的电话”,第二次排序结果中有“北科大办公室”“北科大后勤”“北科大客服”等的电话,用户没有指定是哪儿个部门,就按照设定好的顺序,优先播报办公室的电话。
又例如,用户问清华的电话,第二次排序结果中有“清华后勤”“清华客服”等的电话,用户没有指定是哪个部门,就按照设定好的顺序,优先播报客服的电话。
实施例二
将本实施例所述的文本相似度确定方法应用到了智能客服领域当中,具体的,基于本实施例所述的文本相似度确定方法,开发了一个114查询智能客服对话系统,如图4所示,所述系统包括:软交换系统、语音识别系统、语音合成系统以及智能语义对话引擎;其中,
(1)软交换系统包含以下几个部分:
1)、会话发起协议语音网关:根据中继接入类型,可以选择相应的会话发起协议(sessioninitiationprotocol,sip)语音网关设备。
2)、代理服务器:代理服务器可采用通用个人电脑服务器(personalcomputerserver,pcserver),负责处理sip信令接入、实现呼叫路由分配及对媒体服务器的负载分担功能。
3)、交互式语音应答服务器:交互式语音应答(interactivevoiceresponse,ivr)服务器用于处理ivr请求,执行ivr脚本和放音、双音多频(dual-tonemulti-frequency,dtmf)等媒体处理;通过ivr服务器可以实现语音自动导航和话务的区域分配。
4)、媒体服务服务器:处理软交换呼叫请求,实现话务分配、电话录音。规划每台服务器承载500座席业务量。各省话务员根据规划注册在相应的服务器上。媒体服务器集群采用7台服务器,n+1备份方案承载3000座席的业务量;媒体服务器的运行情况及备份切换由管理服务器负责。
5)、网络附加存储服务器:用于录音文件存储和数据备份的存储设备;为保证数据专长的效率,建议规划专用的存储网络承担媒体服务器与网络附加存储(networkattachedstorage,nas)服务器之间的数据传输。
6)、数据服务器:知识库用于存储软交换系统中的各种数据信息(如:录音信息、话务数据、报表数据等);数据服务器为语音交换平台提供基础的数据存储和查询功能。
7)、录音服务器:用于录音文件管理、录音文件格式转换、录音查询等功能。
8)、管理服务器:用于监控各个服务器的运行状态,统一系统管理,媒体服务器备份切换等功能。
(2)语音识别系统
语音识别系统负责接收由软交换系统发送过来的用户语音流,主要包括基于有限冲激响应(finiteimpulseresponse,fir)数字滤波器的语音去燥预处理模块和基于深度神经网络的语音识别模块。
(3)语音合成系统
语音合成系统又称文语转换(text-to-speechtts)系统,主要功能是将计算机中任意出现的文字转换成自然流畅的语音输出。一般认为,语音合成系统包括三个主要的组成部分:文本分析、韵律生成和语音生成。
(4)智能语义对话引擎
智能语义对话引擎模块是本系统的关键,智能语义对话引擎的语义计算模块又是智能语义对话引擎的关键,语义计算模块的关键算法用到了本实施例所述的文本相似度确定方法,智能语义对话引擎模块的功能示意图如图5所示,将输入的语音输入软交换系统转换为文本,并通过遵循具象状态传输(representationalstatetransferful,restful)规范的接口发送给所述智能语义对话引擎模块,接着,通过所述智能语义对话引擎模块执行以下功能:
基础词法分析、用户模型建模、语义分析、语义计算、输出整理及输出结果;其中,
所述基础词法分析包括:
分词:对输入文本进行切分词语;
拼音转写:文本转成拼音;
词性标注:对切分的词语进行词性标注,如动词、形容词等;
句法分析:分析词语在句子中的语法关系,如主语、宾语等;
词典:为分词和文本转拼音提供词典。
所述用户模型包括:
场景识别:识别用户意图场景,包括查询电话、查询地址等;
上下文建模:建立上下文关联模型;
上下文关联:记录每个用户查询的上下文内容。
所述语义分析包括:
全场景知识库:为语义分析提供地城支持,包括近义词库、简称词库、停用词词库。
语义归一化:对同一种意思的不通表达方式的语义归一化。
简称停用词:做简称替换和停用词删除处理。
近义词:对同义词或者近义词进行语义替换。
所述语义计算包括:
汉字语义计算:先对用户输入进行汉字匹配,如果汉字匹配不到,则进行拼音匹配;
拼音语义计算:按照本发明提出的基于拼音最长公共子序列的文本相似度计算算法进行计算;
语义相似度排序:根据本实施例提出的排序算法进行排序;
结构化索引、问答对索引:为语义的计算和排序提供结构化的支持。
所述输出整理:用于应答整理模块,根据引擎返回的答案,按照设定的语言表达方式进行文本整理。
所述输出结果:用于向软交换系统返回应答结果,并存储日志到知识库中。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!