一种基于大数据平台的智能配用电系统的制作方法
本发明涉及一种配用电系统,尤其是涉及一种基于大数据平台的智能配用电系统。
背景技术:
随着智能配用电网建设的不断深入,采集终端数量的急剧增长,采集频度的大幅增强,配用电数据量由tb级向pb级发展,面临着多源异构海量数据的有效集成、高效存储和高可扩展性的挑战。同时,配用电业务逐步向智能化、精益化方向发展,需要进一步提升跨业务、跨平台的数据分析和处理能力,从而对数据存储和处理的高效性、价值挖掘的准确性和实时性以及人机交互和可视化效果提出了更高要求。因此,有必要建立一个面向配用电业务应用的大数据体系架构,在此基础上提供统一的存储、处理、可视化功能,为配用电大数据业务应用提供有效支撑,以充分获取数据价值,使业务决策建立在更加科学的依据基础上,提高配用电运行效率、危机应对能力和公共服务水平。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于大数据平台的智能配用电系统。
本发明的目的可以通过以下技术方案来实现:
一种基于大数据平台的智能配用电系统,所述的系统包括依次连接的硬件模块、基础模块、应用模块和应用展示模块,所述的应用模块包括数据管理组件、数据服务组件、工作流管理组件、算法包管理组件、交互式查询组件、分析挖掘组件、可视化分子组件、权限管理组件和日志管理组件。
所述的基础模块包括数据集成基础组件、数据存储基础组件、数据计算基础组件、数据查询基础组件和数据分析基础组件,所述的数据集成基础组件、数据存储基础组件和数据计算基础组件依次连接,所述的数据集成基础组件还分别与数据查询基础组件和数据分析基础组件连接,所述的数据计算基础组件分别连接数据查询基础组件和数据分析基础组件,所述的数据存储基础组件分别连接数据查询基础组件和数据分析基础组件。
所述的数据集成基础组件收集的数据包括电网数据、用户数据和社会环境经济数据。
所述的数据存储基础组件采用master/slave的主从存储结构。
所述的数据集成基础组件进行数据流转的方法为:
将数据先从采集库迁移到原始库、再从原始库经处理后转存到中间库、最后由中间库迁移至结果库。
所述的应用展示模块包括分别与应用模块连接的用户用电行为分析组件、节电组件、用电预测组件、网架优化组件和错峰调度组件。
与现有技术相比,本发明具有以下优点:
1、完成了上海浦东新区电网数据、用户数据和社会环境经济数据等多源异构数据的标准化接入;
2、系统满足配用电大数据应用数据量大、并发度高、可靠性要求高的条件,满足用户对系统的性能要求,运行可靠,停机时间满足运维要求;
3、系统具备良好的扩展性和可移植性;具备业务处理的灵活配置,能随着业务功能的变化灵活重组与调整,同时提供标准的开放接口,便于系统的升级改造和与其它系统进行数据与信息的交互;
4、底层组件具有灵活性,通过配置可以改变组件的行为以适应业务需求;
5、智能配用电大数据应用系统应提供安全机制和技术手段保障系统安全稳定运行,满足国家电网公司对网络和信息系统安全运行的要求。
附图说明
图1为基于大数据平台的智能配用电系统示意图;
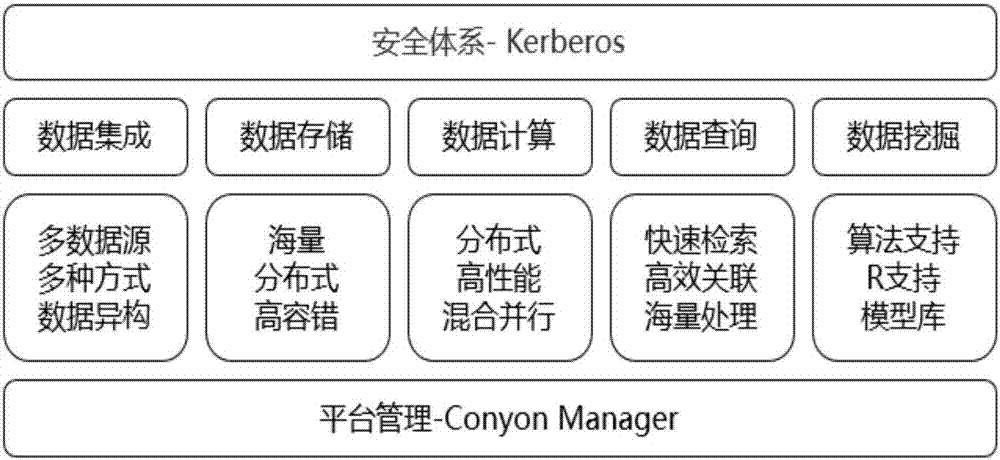
图2为大数据基础平台组件结构示意图;
图3为大数据基础平台组件关联示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
实施例
一种基于大数据平台的智能配用电系统,如图1所示,系统包括依次连接的硬件模块、基础模块、应用模块和应用展示模块,应用展示模块包括分别与应用模块连接的用户用电行为分析组件、节电组件、用电预测组件、网架优化组件和错峰调度组件;应用模块包括数据管理组件、数据服务组件、工作流管理组件、算法包管理组件、交互式查询组件、分析挖掘组件、可视化分子组件、权限管理组件和日志管理组件;基础模块包括数据集成基础组件、数据存储基础组件、数据计算基础组件、数据查询基础组件和数据分析基础组件。
大数据基础模块,如图2所示:
(1)conyonmanager
conyonmanager是浪潮hadoop生态圈的管理平台,提供了用户友好的管理界面、提供了系统安装、集群配置,安全访问控制、监控及预警等多方面支持,在可管理性方面优势显著。而且conyonmanager在统一存储上建立了资源管理层,提供企业用户统一的计算资源管理、动态资源分配、多部门之间资源配置和动态共享,灵活支持多部门多应用在统一平台上平滑运行。
(2)数据集成
本系统提供多种数据采集或迁移方式,例如qoop,flume,rsync,ftp等。用户可以根据数据产生频率,数据源类型,数据结构采用适合的方式。sqoop具有并行,安全,吞吐量大等特点,适合海量非实时结构化数据;flume具有分布式、可靠、和高可用同时可以对数据进行简单处理等特点,适合海量实时数据的处理;其他诸如rsync,ftp,scp等linux系统自带命令,为系统提供了更灵活的方式。
(3)数据存储
本系统采用分布式文件系统hdfs作为主要存储方式,hdfs是一个高度容错性的系统,适合部署在廉价的机器上。hdfs能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。hdfs具有按位存储和处理数据的能力,能够在节点之间动态地移动数据,并保证各个节点的动态平衡,并且能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。并且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。另外作为对实时采集数据存储的补充,hdfs上可以添加hbase作为存储接口,可以快速的接入流式数据。
(4)并行计算
系统采用对大量数据进行分布式处理的软件框架,包括海量计算框架mapreduce和内存计算框架spark等,同时提供资源管理层yarn,在其上可以添加其他计算框架。mapreduce对于大规模数据处理具有高可用,横向扩展,处理向数据迁移等特点,能稳定的对大数据量进行处理;spark不同于mapreduce的是job中间输出结果可以保存在内存中,从而不再需要读写hdfs,因此spark能更好地适用于数据挖掘与机器学习等需要迭代的mapreduce的算法。
(5)数据查询
本系统主要提供多种方式的数据查询,对于海量复杂需要高效关联的数据,采用hive及sparksql作为主要查询方式,hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为mapreduce任务进行运行;对于海量简单需快速响应数据,采用hbase作为主要查询方式,hbase是一个分布式的、面向列的开源数据库,也可以定义为一个结构化数据的分布式存储系统;另外也提供redis等轻量级内存数据库。
(6)数据挖掘
数据挖掘需是指从大量的数据中通过算法搜索隐藏于其中信息,本系统不仅提供数据存储,并行计算,而且提供数据挖掘算法的支持,例如决策树算法;高斯过程回归算法;径向基函数核算法等。同时系统也将r语言集成到分布式环境中,r作为一种统计分析软件,是集统计分析与图形显示于一体的,集成到分布式环境中后,极大的提到了数据读取和计算的性能。
(7)安全体系
kerberos实现的是机器级别的安全认证,也就是前面提到的服务到服务的认证问题。事先对集群中确定的机器由管理员手动添加到kerberos数据库中,在kdc上分别产生主机与各个节点的keytab(包含了host和对应节点的名字,还有他们之间的密钥),并将这些keytab分发到对应的节点上。通过这些keytab文件,节点可以从kdc上获得与目标节点通信的密钥,进而被目标节点所认证,提供相应的服务,防止了被冒充的可能性。解决服务器到服务器的认证,防止了用户伪装成datanode,tasktracker,去接受jobtracker,namenode的任务指派。解决client到服务器的认证,防止用户恶意冒充client提交作业的情况。
大数据应用模块
在架构设计上,平台采用松耦合架构设计,以元数据驱动各模块进行数据的处理。满足海量多源异构数据的批量和实时采集,实现数据批量离线存储和处理、实时在线处理、内存计算等需求,采用体系化分布式并行处理技术和流式计算组件等技术或框架,实现数据的高效和流程化处理。
在架构设计上,平台采用松耦合架构设计,以元数据驱动各模块进行数据的处理为主线。满足海量多源异构数据的批量和实时采集,实现数据批量离线存储和处理、实时在线处理、内存计算等需求,采用体系化分布式并行处理技术和流式计算组件等技术或框架,实现数据的高效和流程化处理。
平台实现多层架构松耦合:数据源层、数据采集层、存储与处理层、服务层、应用层。
平台分多个子系统并实现模块化,内部各层各模块间,实现标准化的接口和集成模式,与外部系统集成,在安全可控状态下,采用开放式的集成接口。
平台采用元数据驱动运行架构:所有平台数据处理的任务和过程,都通过元数据定义和驱动,通过统一的工作流进行管理和调度。
数据流转:
数据处理是指将采集库的数据迁移到大数据平台,以满足各单位依托大数据平台进行数据清洗、分析、挖掘的需求,同时优化存储处理后的数据,使其更有利于前台展示和交互体验。
本节按数据处理顺序分为:采集库到原始库、原始库到中间库、中间库到结果库三部分。其中第一部分(采集库到原始库)是将各业务系统的原始数据迁移到大数据平台的inceptor数据仓库,为各单位进行数据清洗和分析提供数据基础;第二部分(原始库到中间库)是借助大数据平台将原始数据进行合并、关联、去重、行列转置等操作,将处理后的数据和清洗后的数据按新的表结构存储到inceptor数据仓库,该数据是其他单位进行数据分析的原始数据;第三部分是将处理分析完成的数据从inceptor数据仓库迁移到更便于前台可视化查询的hyperbase数据库,提高查询效率和用户体验。
组件关联:
大数据基础平台各组件关联:
如图3所示,大数据基础平台按照组件功能划分,主要包括数据集成,数据存储,数据计算,数据查询以及数据分析5个功能模块,每个功能模块各司其职,又互相关联,各功能模块都包含若干功能组件,不同功能模块通过各组件接口相互调用。
(1)数据集成
数据集成是外部数据接入到大数据平台的首要过程,数据集成模块主要完成数据从数据源到大数据集群的接入工作。配用电大数据数据来源种类多样化,存储介质各有不同,按照时间周期划分,又分流式接入和批量接入。针对不同的数据源通过选用合适的数据集成组件,格式化原始数据,调用组件接口,开发数据接入程序,配置程序调度周期,完成源数据的持续不断接入,为后续模块的数据引用提供基础保障。
(2)数据存储
数据存储模块主要用于接收数据集成模块接入到集群的数据,大数据平台区别于传统数据中心的主要特点就是可以满足海量数据的存储,并且可以根据数据量的大小通过增加数据节点进行横向扩展,项目本期要求的集群数据存储规模800t已经达到,在当前集群的架构设计基础上,只需通过增加节点来继续增加集群的整体存储规模。
采用master/slave的主从存储结构,把数据的存储节点跟管理节点划分开来,同时采用副本冗余的方式,既降低了数据节点的硬件要求,也提高了数据的高可用性,降低了数据的易丢失性。
(3)数据计算
数据计算模块依托数据存储,对数据查询和数据分析提供相应支持,结合高速交互引擎面向配用电应用的清洗修正、统计分析、条件查询数据交互分析需求,屏蔽底层spark、mapreduce的编程复杂性,并利用ssd和内存计算引擎进行处理加速,满足高并发、低延迟服务响应需求。
依据数据密集型或计算密集型等不同数据运算要求,主要采用分布式批处理计算mapreduce等、分布式内存计算spark等、高性能计算mpi等三种方式实现大数据的密集、高速运算过程。
(4)数据查询
基于数据计算模块和数据存储模块,提供支持全局、局部和全文索引,高并发实时的数据查询或检索需要。根据查询数据特性的不同(历史数据检索、关联查询、流式访问等),提供不同的数据查询的组件,满足各种应用场景的查询需求。
(5)数据分析
数据分析模块主要是在其他模块的基础上为数据分析或挖掘人员提供足够丰富的数据挖掘算法,支持原生的数据挖掘语言(python、r),集成行业模型库,最大程度上方便上层用户的业务挖掘或分析需要。
数据分类
智能配用电大数据平台数据源从数据类型规划分为三类数据,分别为电网数据、用户数据和社会环境经济数据:
(1)电网数据
电网地理拓扑数据、电网电气拓扑数据、一次设备台账、配电网调度运行数据、10kv公变运行数据、配电网节点电压检测数据、配电网线损数据、可靠性数据、配电设备运维数据和电能质量数据。
(2)用户数据
用户档案数据、100kw以上用户用电数据、50kw-100kw用户用电数据、50kw以下用户用电数据、分布式电源数据和电动汽车充电桩数据。
(3)社会环境经济数据
地理信息数据、气象信息数据、社会经济数据和城镇未来规划。
这些数据分别属于不同管理部门(包含运检、营销、调控中心等)管理,不同的厂家(包含欣能、南瑞科技、朗新等)开发。根据各个业务系统的实际运行情况,接口集成方式主要分为oracle、ftp、webservice,交互数据格式主要包含xml、svg、cim_e、数据库格式。数据集成信息见表1:
表1数据集成信息表
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!