一种面向流式数据的并行增量式关联规则挖掘方法与流程
本发明属于数据挖掘领域,具体涉及一种面向流式数据的并行增量式关联规则挖掘方法。
背景技术:
随着计算机技术、数据库技术和无线传感网络的飞速发展,对于在线实时数据挖掘的能力得到了越来越多的关注,对于流式数据的数据挖掘也成为了学术界新的研究课题。
数据流数据以流的形式广泛存在于日常生活中,例如各类传感器网络中的数据包流,金融证券领域波动的数据流,电信行业的通讯数据流、零售行业的交易数据流、web用户上网点击率的数据流等其他相关行业的领域。流式数据往往具有迅速多变,数据量庞大,无限取值,不可预测的特性。
与传统静态的数据挖掘相比,基于数据流的数据挖掘无疑对计算机资源的存储提出了更高的要求,如何从这些连续变化,快速生成的数据流数据中挖掘出有价值的、潜在的知识,无疑是数据挖掘领域热门的研究方向,这将对许多应用领域的发展带来重大的意义。
针对于此,提供设计一种面向流式数据的并行增量式关联规则挖掘方法,是非常有必要的。
技术实现要素:
本发明的目的就是为了解决传统关联规则发现方法资源消耗大,单台计算机计算能力有限以及候选项集庞大的缺陷,通过对传统的关联规则发现算法进行改进,提升知识的获取能力,具有知识可信度高、挖掘效率高等优点。
为实现上述目的,本发明给出以下技术方案:
一种面向流式数据的并行增量式关联规则挖掘方法,其特征在于,包括以下步骤:
步骤s1:针对原事务数据库的频繁项集挖掘,采用数据划分的方式,运用并行分层的思想,将原始数据库尽可能的均等划分;
步骤s2:数据划分中进行频繁项集的挖掘;
步骤s3:针对增量数据流的频繁项集挖掘算法,在数据流更新的条件下,利用已有的挖掘结果结合新增数据的特征,实现关联规则知识的快速更新。
作为优选,所述步骤s1包括以下步骤:
步骤s11:设q1,q2,…,qn为n台功能相互独立的计算机,这n台计算机除了进行网络通信外,无共享体系结构,无共同存储结构;设di(i=1,2,…,n)为分别存储于计算机q1,q2,…,qn硬盘上的独立数据库,每个数据库上的事务数为tj(j=1,2,…,n)个,则所有的数据库为
作为优选,所述的步骤s2包括以下步骤:
步骤s21:采用动态的支持度和置信度来评判关联规则挖掘的准确性,支持度揭示了事务a与b同时出现的概率,动态关联规则的支持度可表示为:
s=c(a∪b)/n(1)
其中,c(a∪b)表示项集a∪b在数据库中出现的频数,n表示数据库中所有事务的总频数,置信度揭示了当事务a出现时,事务b同样会出现的概率,动态关联规则的置信度可以表示为:
c=c(a∪b)/c(a)(2)
其中,c(a∪b)表示项集a∪b在数据库中出现的频数,c(a)表示在数据中项集a出现的频数,即a的支持度计数假设原始数据库为d,将事务数据库d随机划分成n个子集,这n个子数据库被分配到m个worker节点进行并行频繁项集挖掘,所用的时间由执行时间最长的分区决定;通过调用spark框架中的mappartitions()算子得到分区的频繁项集。
步骤s22:调用reducebykey()算子统计rdd上所有分区每个项集的支持度计数,即每个数据项在整个事务数据库中出现的次数,进而得到全局候选项集;
步骤s23:将全局候选项集通过广播变量方式传播到spark集群的各个工作节点上,调用filter()算子,将不满足全局支持度阈值的候选项集删除,得到全局频繁项集。最后调用collect()函数,以数组的形式,将数据集中的全局频繁项集返回给主节点,完成对原始数据库上频繁项集的挖掘。
作为优选,所述步骤s3包括以下步骤:
步骤s31:设原始数据库为db,新增数据流的数据集为db,项目集x在数据库db中的支持度计数为x.sup_db,在新增数据流d中的支持度计数为x.sup_db,min_sup为原始的支持度阈值;原数据集的大小为|db|,新增数据流的大小为|db|,更新后的数据集大小为|db∪db|,s为数据集的支持度。在原数据库db和新增数据集合db都频繁的项集为频繁项集;此时过滤后的候选项集主要分为两大类:在原数据库db中频繁但在新增数据流db中不频繁的项集和在原数据库db中不频繁但在新增数据流db中频繁的项集;在原数据库db中频繁而在新增数据流d中非频繁的数据只需要扫描新增数据流分层就可以确定频繁项集,如果x.sup_db+x.sup_db<0,则项集x在db∪db中就是非频繁的项目集,否则就是频繁项目集;只有在新增数据流db中频繁却在原数据库db中非频繁的才需要扫描整个数据集,这样只需要扫描一次原始数据集,减少了重复扫描原始数据集的时间,提高了规则发现的效率。。
本发明的有益效果在于,解决传统关联规则发现方法资源消耗大,单台计算机计算能力有限以及候选项集庞大的缺陷,通过对传统的关联规则发现算法进行改进,提升知识的获取能力,具有知识可信度高、挖掘效率高等优点。此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著地进步,其实施的有益效果也是显而易见的。
附图说明
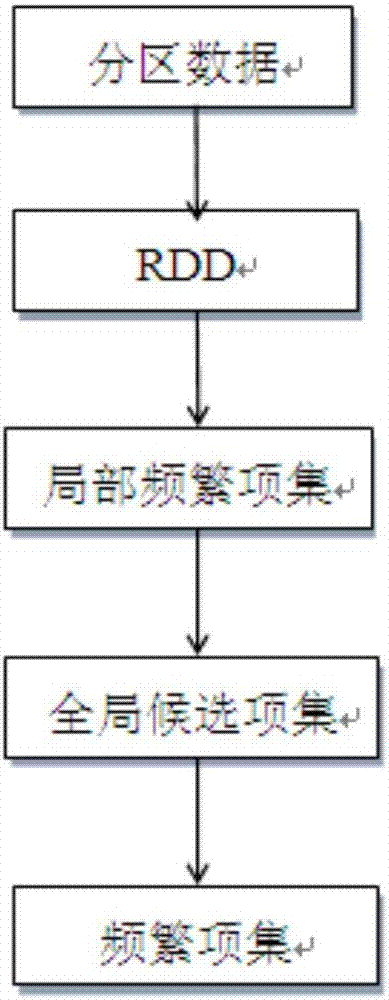
图1是基于原始数据库并行挖掘频繁项集的算法流程图。
图2所示是增量关联规则挖掘频繁项集的算法流程图。
具体实施方式
下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。
本实施例给出一种面向流式数据的并行增量式关联规则挖掘方法,包括以下步骤:
首先利用spark并行平台对原始事务数据库进行频繁项集挖掘。根据关联规则的挖掘规则,设最小支持度阈值为min_sup,最小置信度阈值为min_con。则当支持度s>min_sup且置信度c>min_con时,则称规则a=>b为强关联规则。在频繁项集挖掘过程中,利用最小支持度计数代替支持度阈值,则每个分区的支持度计数为s_count=min_sup×该分区的事务数。这样有利于减少频繁计算支持度阈值的概率。根据划分的思想,若x为频繁项集,则x的所有子集都是频繁项集。若x为非频繁项集,则x的所有的超集都是非频繁项集。假设原始数据库为d,根据实际挖掘过程的需要,将事务数据库d随机划分成n个非重叠区域,使各个子集的分区大小基本一致,保证每个项集有相同的概率进行频繁项集的挖掘,保证事物的同等重要性;在进行局部频繁项集挖掘时,运用并行分层的思想,若子集数据量庞大,每个分区di还可以继续向下划分成di1,di2,…,din,子分区d11,d12,…,d1s,d21,d22,…,d2s,…,di1,di2,…,din均可并行执行。尽量避免不同分区出现相同数据的现象,避免重复挖掘的低效性,提高挖掘结果的可信度和高效性。
spark读取事务数据库中的数据并对其划分,master节点利用spark的提供的textfile()算子扫描在hdfs上的事务数据库,即一个rdd。对分区的数据子集并行挖掘频繁项集,所用的时间由执行时间最长的分区决定。如果某项集x是频繁项集,那么必然会作为局部频繁项集出现在其中至少一个分区中。通过mappartitions()算子得到该分区的频繁项集,mappartitions()函数是基于分区的map,是map的一个变种。map的输入函数是应用于rdd中每个元素,mappartitions的作用对象是rdd的一整个分区,也就是把每个分区中的内容作为整体来处理的。mappartitions()函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭代器对整个分区的元素进行操作。每个分区中的内容将以iterator[t]传递给输入函数,输入函数的输出结果是iterator[u]。最终的rdd是由所有分区经过输入函数处理后的结果合并起来的。再采用reducebykey()算子来统计rdd上所有分区每个项集的支持度计数,即每个数据项在整个事务数据库中出现的次数,从而得到全局候选项集。reducebykey()函数的性能优于groupbykey()函数的性能,因为reducebykey()函数在数据混洗之前会进行本地规约处理,减少网络传输的时间开销。reducebykey()算子是transformation操作,reducebykey()只对键相同的值进行规约,对<key,value>结构的rdd进行聚合。reducebykey()就是对rdd中key相同的元素的value进行reduce,因此,key相同的多个元素的值被reduce为一个值,然后与原rdd中的key组成一个新的kv对。再采用广播变量的方式将全局候选项集传播到spark集群的各个工作节点上,调用filter()算子,删除不满足全局支持度阈值的候选项集,从而得到全局频繁项集。filter()函数的功能是对不满足条件的元素进行过滤,对每个元素应用f函数,返回值为true的元素在rdd中保留,返回值为false的元素将被过滤掉。此时得到的结果还是一个rdd。最后采用collect()函数收集rdd的元素到driver节点,会在本机上生成一个新的scalaarray数组,在这个数组上运用scala的函数式操作,以存储来自各个节点的所有数据,最后将数据集中的全局频繁项集返回给主节点。
对于流式数据来说,关联规则挖掘主要是研究在数据流更新的条件下,利用已有的挖掘结果,实现关联规则的快速更新。一般情况下,新增数据流db相对于历史数据要小得多,并且新增数据的数据特征也更容易取得。在原事务数据库db和新增数据流db融合生成新的数据集后,产生新的频繁项集主要面对以下两个问题:如何找出db中不在满足条件的频繁项集并删除;如何找出db融合db后满足条件的频繁项集并增加。当项目集x在原数据库db和新增数据库db中都是频繁项目集时,则x在db∪db的数据中一定也是频繁项目集。当项目集x在原数据库db和新增数据库db中都不是频繁项目集时,则x在db∪db的数据中也一定不是频繁项目集。过滤后的候选项集主要分为两大类:在原数据库db中频繁但在新增数据流db中不频繁的项集和在原数据库db中不频繁但在新增数据流db中频繁的项集。在原数据库db中频繁而在新增数据流d中非频繁的数据只需要扫描新增数据流分层就可以确定频繁项集,如果x.sup_db+x.sup_db<0,则项集x在db∪db中就是非频繁的项目集,否则就是频繁项目集。只有在新增数据流db中频繁却在原数据库db中非频繁的才需要扫描整个数据集,这样只需要扫描一次原始数据集,减少了重复扫描原数据库的时间,提高了算法的效率。
读取分布式文件系统hdfs中的新增数据流db作为预处理数据,按照时间序列划分成n个互不重叠、互不相交的数据块,且尽量各个数据块大小相似。master节点利用spark提供的textfile()算子并行扫描新增数据流,生成rdd。数据块被分发到m个worker节点并行处理,采用count()算子计算分区各项集的支持度计数。如果某项集的频数小于分区的最小支持度频数,采用局部剪枝的方法,删除该项集。通过mappartitions()函数计算得出每个项集的支持度计数,产生局部频繁项集lk。本地频繁项集以rdd<项集,1>键值对的形式存储于m个节点中。reducebykey()函数统计支持度计数count的值,对上一步产生的局部频繁项集进行合并,得到新增数据流中的局部候选项集ck。这些候选项集在整个数据库中不一定是频繁项集,还要分析它们在原数据库db中的频繁情况。将db的局部候选项集ck和原数据集db的频繁项集l(db)合并,在原数据库db和新增数据流db中公共的频繁项集加入到更新后的频繁项集l(db∪db)中。其他的项集分为两类:在原数据库db中频繁但在新增数据流db中不频繁的项集,在原数据库db中不频繁但在新增数据流db中频繁的项集。把这两种项集统一归为全局候选项集c(db∪db)。再将全局候选项集c(db∪db)分配到m个节点,各节点尽量大小均等、规模相当。并行扫描候选项集,如果项集的局部支持度频数小于局部支持度阈值,采用局部剪枝的方法,删除该项集。通过union()函数进行候选项集的全局连接,采用filter()算子删除不满足最小支持度阈值的数据项,从而得到全局候选项集c(db∪db)中的频繁项集。将得到的频繁项集与之前的频繁项集l(db∪db)合并,就得到数据流增量更新后完整的频繁项集。
如图1所示是基于原始数据库并行挖掘频繁项集的算法流程图,具体过程如下:
spark读取事务数据库db上的数据并对其进行分块,n个数据块被分配到m个worker节点进行处理。对分区的数据子集进行并行频繁项集挖掘,所用的时间由执行时间最长的分区决定,对每个子集中的项集进行支持度计数。由于局部频繁项集数据量庞大,如果直接进行连接产生候选项集,必然会降低算法的执行效率。因此先对局部频繁项集进行局部剪枝处理。若某项集的频数小于该分区的最小支持度计数,则去掉该项集。得到子集的候选频繁项集,即局部频繁项集。局部频繁项集可能是全局频繁项集,也可能不是全局频繁项集。然而如果项集x是频繁项集,那么必然会作为局部频繁项集出现在其中至少一个分区中。具体的生成步骤如下:
step1:通过textfile()算子扫描在hdfs上的事务数据库。
step2:通过mappartitions()算子得到该分区的频繁项集。
step3:通过reducebykey()算子来统计rdd上所有分区每个项集的支持度计数,即每个数据项在整个事务数据库中出现的次数,从而得到全局候选项集。
step4:将全局候选项集通过广播变量传播到spark集群的各个工作节点上,通过调用filter()算子,将不满足全局支持度阈值的候选项集删除,得到全局频繁项集。
step5:最后调用collect()函数,以数组的形式,将数据集中的全局频繁项集返回给主节点。
如图2所示是增量关联规则挖掘频繁项集的算法流程图,具体过程如下:
读取分布式文件系统hdfs中的新增事务数据库作为预处理数据,按照时间序列划分成n个互不重叠、互不相交的数据块,且尽量各个数据块大小相似。再计算各个分区各项集的支持度计数,通过每个项集的支持度计数,得到局部频繁项集。将局部频繁项集进行合并,得到新增数据流db中的局部候选项集ck。这些候选项集在事务数据库中不一定是频繁项集,还要分析它们在原数据库db中的频繁情况。将db的局部候选项集ck和原数据集db的频繁项集l(db)合并,在原数据库db和新增数据流db中公共的频繁项集加入到更新后的频繁项目集l(db∪db)中。其他的项集分为两种:在原数据库db中频繁但在新增数据流db中不频繁的项集,在原数据库db中不频繁但在新增数据流db中频繁的项集。把这两种项集统一归为全局候选项集c(db∪db)。将全局候选项集分配到m个节点中,各节点尽量大小均等、规模相当。如果项集的局部支持度频数小于局部支持度阈值,利用局部剪枝的性质,删除该项集。最后对候选项集全局连接,删除不满足最小支持度阈值的数据项,从而得到全局候选项集c(db∪db)中的频繁项集。将得到的频繁项集与之前的频繁项集l(db∪db)合并,就得到了数据流增量更新后完整的频繁项集。具体生成步骤如下:
step1:利用spark提供的textfile()算子对子区域进行并行扫描,生成rdd。将数据块分发到m个worker节点进行处理,利用count()算子计算分区各项集的支持度计数。同时将此支持度设置为频繁模式挖掘的最小支持度阈值。利用局部剪枝的方法,如果项集的频数小于分区最小支持度频数,则删除该项集。
step2:通过mappartitions()函数计算得出每个项集的支持度计数,产生局部频繁项集lk。本地频繁项集以rdd<item,1>键值对的形式存储于m个节点中。
step3:利用reducebykey()函数统计支持度计数count的值,对上一步产生的局部频繁项集进行合并,得到新增数据流db中的局部候选项集ck。
step4:在原数据库db中频繁但在新增数据流db中不频繁的项集,在原数据库db中不频繁但在新增数据流db中频繁的项集。把这两种项集统一归为全局候选项集c(db∪db)。将全局候选项集分配到m个节点中,各节点尽量大小均等、规模相当。
step5:各节点对分配的候选项集进行扫描。如果项集的局部支持度频数小于局部支持度阈值,利用局部剪枝的性质,删除该项集。通过union()函数进行候选项集的全局连接,利用filter()算子删除不满足最小支持度阈值的数据项,从而得到全局候选项集c(db∪db)中的频繁项集。
step6:将得到的频繁项集与之前的频繁项集l(db∪db)合并,就得到了数据流增量更新后完整的频繁项集。
以上公开的仅为本发明的优选实施方式,但本发明并非局限于此,任何本领域的技术人员能思之的没有创造性的变化,以及在不脱离本发明原理前提下所作的若干改进和润饰,都应落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!