基于情感与信任的协同过滤推荐方法与流程
本发明涉及推荐系统领域,具体地,涉及基于情感与信任的协同过滤推荐方法。
背景技术:
随着信息时代的发展,互联网上日益庞大的数据流,使得人们想获取所需要的信息变得越来越困难,信息过载成为亟待解决的问题。而推荐系统由于提供的个性化服务、对信息进行排序过滤而广受学术界和工业界的关注。但在日益复杂的社交网络环境中,用户项目评分矩阵稀疏和信任的弱传递问题仍影响着推荐的精度。以协同过滤为代表的主流推荐算法还会由于近邻偏好推荐,容易受到托攻击。提高系统的准确度和性能已成为个性化推荐进一步发展的迫切需求。
近年来,有关社交网络个性化推荐算法的研究,吸引了众多学者。比较有代表性的算法分为以下五种:基于内容的推荐cbr、协同过滤推荐cf、基于效用推荐ubr、基于规则的推荐rbr以及基于知识推荐kbr。其中以协同过滤最具有影响力,但依然存在着数据稀疏、冷启动及扩展性三大问题。学者们提出了分解社交矩阵、自适应相似度计算、受限信任关系、改进关系网络等改进方法,但实验数据使用的多为显式的用户反馈评分信息,却忽略了更能反映用户个性化情感倾向的隐式反馈行为信息。
因此,基于现有技术,如何结合显式评分信息建立安全性强、推荐精度高的信任关系,如何深度挖掘社交网络中用户的隐式情感倾向,是能准确而安全地进行推荐需要面临的重大问题。
技术实现要素:
本发明的目的是提供一种基于情感与信任的协同过滤推荐方法,该基于情感与信任的协同过滤推荐方法克服了现有技术中推荐精度不高和易受托攻击的问题,实现了协同过滤。
为了实现上述目的,本发明提供一种基于情感与信任的协同过滤推荐方法,该基于情感与信任的协同过滤推荐方法包括:
步骤1,对用户项目已评分矩阵进行归一化处理后得到显式满意度;根据向量余弦法计算得到已评分项目和未评分项目之间的相似度,利用所述显式满意度和相似度计算得到隐式满意度,由显式满意度和隐式满意度构成扩充满意矩阵;
步骤2,根据扩充满意矩阵计算评分相似度和偏好相似度,利用评分相似度、偏好相似度以及由有监督的学习算法设置的权重得到用户对项目看法相似性产生的客观信任度;
步骤3,根据用户满意交互频率对用户社交网络进行抽象,基于六度分割理论建立带权有向图,计算得到用户间由熟悉性产生的主观信任度;
步骤4,使用有监督的学习算法将客观信任度和主观信任度加权得到增强信任度;
步骤5,根据情感评分向量和改进的vsm向量空间模型来计算用户间的情感一致性;
步骤6,利用top-n算法,按增强信任度筛选出预设大小的候选邻居集,并以情感一致性为标准对候选邻居集进行二次筛选得到最终邻居集,通过所述最终邻居集中的邻居用户对项目的扩充满意矩阵预测用户对项目的评分,选择较高评分的项目产生推荐集。
优选地,在步骤1中,对用户项目已评分矩阵进行归一化处理后得到显式满意度的公式包括:
其中,max表示评分值上限,m表示用户数,n表示项目数。
优选地,在步骤1中,根据向量余弦法计算得到已评分项目和未评分项目之间的相似度的方法包括:
其中,项目pi、pj之间的相似度为
优选地,在步骤1中,利用所述显式满意度和相似度计算得到隐式满意度的方法包括:
其中,用户u对项目p的隐式满意度为
优选地,在步骤1中,由显式满意度和隐式满意度构成扩充满意矩阵的方法包括:
如果用户u对项目p存在显式满意
优选地,在步骤2中,根据扩充满意矩阵计算评分相似度和偏好相似度的方法包括:
其中,评分相似性为pcc;
其中,偏好相似性为jac;
利用评分相似度、偏好相似度以及由有监督的学习算法设置的权重得到用户对项目看法相似性产生的客观信任度的方法包括:
其中,客观信任度为
优选地,在步骤3中,根据用户满意交互频率对用户社交网络进行抽象,基于六度分割理论建立带权有向图,计算得到用户间由熟悉性产生的主观信任度的方法包括:
其中,主观信任度为
优选地,在步骤4中,使用有监督的学习算法将客观信任度和主观信任度加权得到增强信任度的方法包括:
其中,增强信任度为
优选地,在步骤5中,根据情感评分向量和改进的vsm向量空间模型来计算用户间的情感一致性的方法包括:
其中,情感一致性为
优选地,在步骤6中,通过所述最终邻居集中的邻居用户对项目的扩充满意矩阵预测用户对项目的评分的方法包括:
其中,
通过上述技术方案,本发明所述的社交网络中基于情感与信任的推荐方法中,用户的邻居集由扩充满意矩阵、增强信任度和情感一致性共同决定。扩充满意矩阵包括显式满意和隐式满意,增强信任包括相似信任与熟悉信任,相似信任由评分和偏好共同决定,确保了与用户的爱好和兴趣领域相同;熟悉信任可保证推荐的安全有效性,免受恶意的托攻击;情感一致性更能反映项目的特征和用户的情感倾向,整个方法提高了邻居集的安全性、可信度和推荐的准确度。
本发明的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
图1是说明本发明的一种社交网络中基于情感与信任的协同过滤推荐方法的流程图;
图2a是说明本发明的一种六度分割理论的用户交互模型示意图;
图2b是说明本发明的另一种六度分割理论的用户交互模型示意图;
图3是说明本发明的一种情感极性模型示意图。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
在本发明的一种具体实施方式中,本发明提供一种基于情感与信任的协同过滤推荐方法,该基于情感与信任的协同过滤推荐方法包括:
步骤1,对用户项目已评分矩阵进行归一化处理后得到显式满意度;根据向量余弦法计算得到已评分项目和未评分项目之间的相似度,利用所述显式满意度和相似度计算得到隐式满意度,由显式满意度和隐式满意度构成扩充满意矩阵;
步骤2,根据扩充满意矩阵计算评分相似度和偏好相似度,利用评分相似度、偏好相似度以及由有监督的学习算法设置的权重得到用户对项目看法相似性产生的客观信任度;
步骤3,根据用户满意交互频率对用户社交网络进行抽象,基于六度分割理论建立带权有向图,计算得到用户间由熟悉性产生的主观信任度;
步骤4,使用有监督的学习算法将客观信任度和主观信任度加权得到增强信任度;
步骤5,根据情感评分向量和改进的vsm向量空间模型来计算用户间的情感一致性;
步骤6,利用top-n算法,按增强信任度筛选出预设大小的候选邻居集,并以情感一致性为标准对候选邻居集进行二次筛选得到最终邻居集,通过所述最终邻居集中的邻居用户对项目的扩充满意矩阵预测用户对项目的评分,选择较高评分的项目产生推荐集。
优选地,在步骤1中,对用户项目已评分矩阵进行归一化处理后得到显式满意度的公式包括:
根据用户项目评分矩阵r,将评分值rup归一化到[0,1]区间得到用户u对项目p的显式满意度
其中,max表示评分值上限,m表示用户数,n表示项目数。
优选地,在步骤1中,根据向量余弦法计算得到已评分项目和未评分项目之间的相似度的方法包括:
其中,项目pi、pj之间的相似度为
例如,假设用户数m=5,对项目pi评分的用户为u1,u2,u3,对项目pj评分的用户为u2,u3,u4,则评分向量
优选地,在步骤1中,利用所述显式满意度和相似度计算得到隐式满意度的方法包括:
用户u对项目pui存在显式满意,且用户u未评分的项目p与项目pui非常相似,则说明用户u对项目p存在隐式满意。根据显式满意度
其中,用户u对项目p的隐式满意度为
优选地,在步骤1中,由显式满意度和隐式满意度构成扩充满意矩阵的方法包括:
如果用户u对项目p存在显式满意
由显式满意度
优选地,在步骤2中,根据扩充满意矩阵计算评分相似度和偏好相似度的方法包括:
根据扩充满意矩阵sts得到的用户对项目的扩充满意向量,分别从微观和宏观上用户对项目的评分情况和偏好情况进行分析,根据余弦相似度和jaccard相似度分别计算评分相似性pcc和偏好相似性jac,
其中,评分相似性为pcc;
其中,偏好相似性为jac;
利用评分相似度、偏好相似度以及由有监督的学习算法设置的权重得到用户对项目看法相似性产生的客观信任度的方法包括:
结合评分相似性pcc和偏好相似性jac,计算用户ua和用户ub之间的客观信任度
其中,客观信任度为
优选地,在步骤3中,根据用户满意交互频率对用户社交网络进行抽象,基于六度分割理论建立带权有向图,计算得到用户间由熟悉性产生的主观信任度的方法包括:
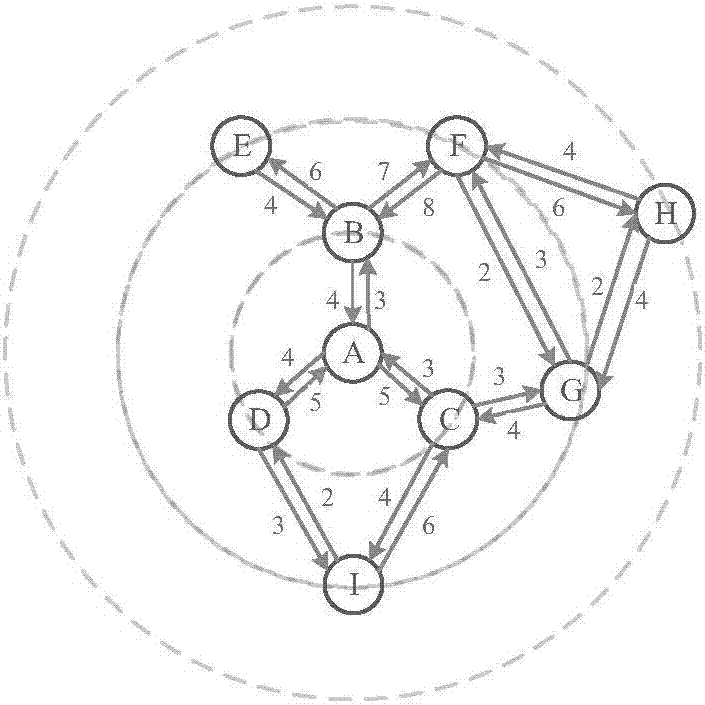
基于六度分割理论我们可以简化并抽象出社交网络中的用户交互模型,表现为带权有向图g(n,e,w),节点代表用户n,e代表用户节点之间的有向边,方向代表主动性;w为边上的权重,代表用户对邻居的熟悉性,用最小满意交互频率表示(如图2所示)。通过用户的满意交互频率与深度搜索得到的用户距离,可计算得到用户ua与用户ub间的由熟悉性产生的主观信任度
其中,主观信任度为
优选地,在步骤4中,使用有监督的学习算法将客观信任度和主观信任度加权得到增强信任度的方法包括:
为客观信任度
其中,增强信任度为
优选地,在步骤5中,根据情感评分向量和改进的vsm向量空间模型来计算用户间的情感一致性的方法包括:
利用网络爬虫技术,对用户行为数据进行文本挖掘,收集每位用户的隐式数据,为每份数据建立资源集f,对获取到的用户资源文档进行去噪处理和文本、词汇e的提取,并为用户打上相应的情感标签t。根据图3的情感极性模型可将得到的词汇进行情感分类,分为joy-sadness,anger-fear,trust-disgust,surprise-anticipation四种相对情感类型,将情感标签映射到相应的情感极性,并转换为相应的情感评分:每对情感极性,前者对应1分,后者对应0分,中性表示0.5分。根据情感评分和改进的vsm向量空间模型计算用户间的情感一致性
其中,情感一致性为
优选地,在步骤6中,
(4.1)根据top-n算法对增强信任度
(4.2)对候选邻居集进行二次筛选,筛选出情感一致性
(4.3)通过上述k位好友对项目p的扩充满意度来预测目标用户u对项目p的评分:
通过所述最终邻居集中的邻居用户对项目的扩充满意矩阵预测用户对项目的评分的方法包括:
其中,
根据预测评分,选择评分较高的项目产生推荐集。
具体来说,本发明所述的方法具有如下的有益效果:
(1)该方法考虑了社交网络中信任度的细化与精化的问题,保证了用户信任计算的准确性、安全性和全面性,相比于现有信任的衡量与计算方法,本方法考虑了用户信任来源与相似度量的多渠道问题,由于兴趣相似和交往密切的邻居集都有可能成为信任对象,而且相似性也应该从对同类项目的评分、对评过分的项目类别等多个维度考虑,因此本方法将信任度细粒度地刻画为相似信任和熟悉信任,建立相似性产生的客观信任度和熟悉性产生的主观相似度的增强信任模型,并采用评分相似度和偏好相似度的加权相似度,能更准确地融合社交网络中用户的社会关系。
(2)该方法考虑了社交网络中熟悉度的不易量化与计算问题,将用户的社交关系网以最小满意交互频率为权重建模成有向带权图(如附图2所示),同时考虑到用户社交圈的复杂和庞大,基于六度分割理论、树与图论的基本算法给出了熟悉度的具体计算,解决了信任网络中的信任传递量化与相关计算问题。
(3)该方法考虑了用户大量隐式反馈信息未加利用的问题,相对于直接表现出倾向信息的显式反馈,隐式反馈信息同样包含用户对资源隐含的观点和看法,而且收集成本更低,数据规模更大。根据用户间不同的历史行为数据、不同的社交网络关系,引入情感标签与感评分来计算用户间的情感一致性,可以约束信任在社交网络中的传播,并缓解数据稀疏性带来的预测准确度低的问题,一定程度上提高了评分覆盖率和防攻击能力,保证了推荐系统的安全性问题。
在本发明的一种最优选的实施方式中,
第一步,由用户项目评分矩阵r,经归一化处理得到显式满意度
第二步,根据第一步得到的sts,可分别从宏观上和微观上分析用户对项目的偏好情况和评分情况,从而计算评分相似度
第三步,根据用户满意交互频率对用户社交网络进行抽象,基于六度分割理论建立带权有向图,利用图与树的相关知识,计算得到用户间由熟悉性产生的主观信任度
第四步,使用有监督的学习算法将
第五步,利用网络爬虫技术挖掘用户的历史行为、文本评价等隐式信息,得到隐式的资源文档集f,进行去噪处理和词汇e的提取,为用户打上相应的情感标签t,并转换为相应的情感极性和情感评分。根据情感评分向量和改进的vsm向量空间模型来计算用户间的情感一致性
第六步,利用top-n算法,按信任度
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!