一种蛋白质抗原表位的预测方法与流程
本发明涉及一种能够对蛋白质抗原表位进行精准、快速预测的方法,属于生物技术领域。
背景技术:
抗原表位是认识蛋白质抗原性的基础,正确而详细地绘制抗原表位图谱不仅有助于基础免疫学的研究,而且对生物活性药物及表位疫苗设计也具有重要的意义。在免疫系统中,b细胞和t细胞一道作用于人类的第二道防线“获得性免疫”过程,其作用是在免疫呈递过程中识别非己的抗原体,一旦发现入侵的抗原,两类细胞会产生各自的免疫效应。
抗原表位位置确定的传统方法有两种,即x-射线衍射方法和实验方法,这些方法的缺点是比较繁琐,工作量也非常大。随着计算机技术的发展和生物信息数据库的日益扩大,从已有数据中总结抗原表位的序列及结构特征,利用机器学习算法对表位进行筛选预测,再利用实验予以验证成为主流的技术路线。这种技术路线具有大幅节约成本,提高工作效率的优点。
利用计算机预测抗原表位是在氨基酸理化性质的基础上融合多个特征参数(如疏水性、亲水性、可及性、可变性、抗原性等)对表位点进行预测。机器学习算法以准确性高、效率高被广泛使用到表位预测中。机器学习算法预测抗原表位主要包括数据收集和处理、模型建立、参数优化和表位预测等步骤。常用的机器学习算法主要有:支持向量机器(svmhc)、隐马尔可夫模型(hmm)和人工神经网络(ann)等。这些算法的应用确实提升了抗原表位预测的效果,但也存在着运用单个算法很难取得较高的预测精度和训练样本数据选取的不科学等问题。目前国内外对于抗原表位的预测研究主要是通过互补预测能力的组合模型构造、科学的样本数据集合构造等来提升预测性能。这些研究多是利用现有预测工具的组合实验来发现具有互补预测能力的分类器组合,虽然这样的做法能够在一定程度上提升预测性能,但目前人们仍没有找到一种更为有效的预测方法。
技术实现要素:
本发明的目的在于针对现有技术之弊端,提供一种蛋白质抗原表位的预测方法,为精准、快速找到抗原表位提供有效方法。
本发明所述问题是以下述技术方案解决的:
一种蛋白质抗原表位的预测方法,所述方法首先从iedb(http://www.iedb.org/)专业数据库中采集经实验验证的抗原表位序列作为训练正样本,从uniport(http://www.uniprot.org/)蛋白质数据库中采集相应的蛋白质的一级序列,从这些蛋白质序列中抽取未经标记为表位的序列片段作为训练负样本,利用氨基酸的理化性质将样本序列转变为特征矩阵作为训练的输入;然后采用机器学习算法训练出互补预测分类器组及一个单独的分类性能比较好的分类器;最后运用训练好的分类器去预测表位,先利用互补预测分类器组获取第一候选表位集合,再利用一个独立的高性能分类器获取第二候选表位集合,并利用倾向性打分方法对两个候选表位集合中的序列进行打分排序。
上述蛋白质抗原表位的预测方法,预测按以下步骤进行:
a.数据采集:从iedb数据库中甄选表位序列数据作为训练正样本,在uniport蛋白质数据库中采集相应的蛋白质序列并从中抽取未经标记为表位的序列片段作为训练负样本,构建出学习训练样本集合,利用氨基酸的疏水性、可及性等理化性质特征信息,将样本中序列的每个氨基酸、相邻三氨基酸的疏水性与可及性的均值组成特征矩阵作为训练的输入;
b.互补预测分类器组的训练:
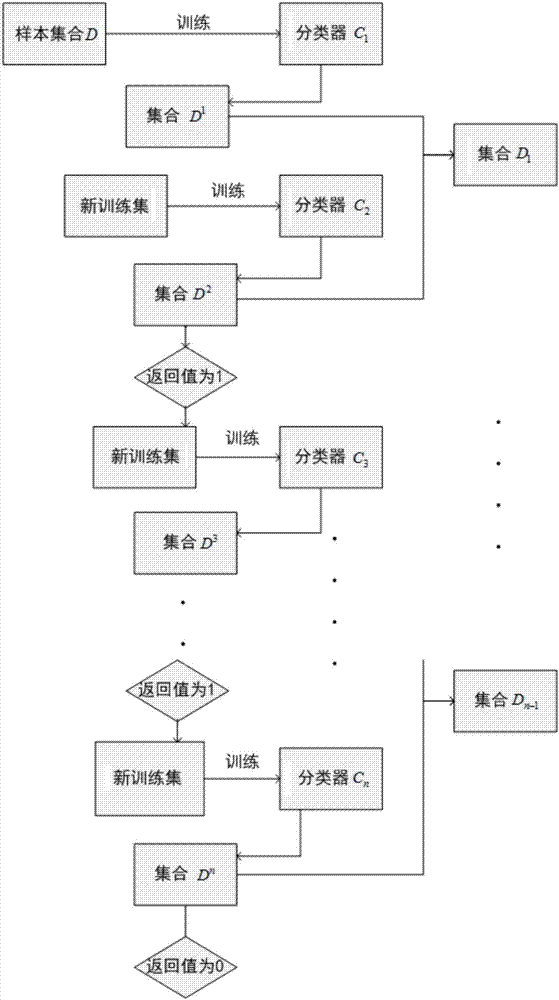
①设样本集合为d,利用二分类训练方法训练,当分类正确率大于λ(记λ为学习训练分类器的分类准确率,具体数值可根据实际情况设定,λ的取值范围为50%≤λ<100%)后即可获得第一分类器c1,在集合d中c1能正确识别的样本组成集合d1,
②当需要继续训练时,依照“四分类训练方法”及“适量增加的方法”将样本集合d-d2和d2-d1中表位和非表位的样本构建包含四种类别的训练样本集合,在新样本集合中进行学习训练,当分类正确率大于λ后获得第三分类器c3,在集合d-d1中c3能正确识别的样本组成集合d3,将集合d2与集合d3的交集记为d2,然后根据“训练终止规则”判断训练是否继续进行,当获得第n-1分类器cn-1后,还需要继续训练时,依照“四分类训练方法”及“适量增加的方法”将样本集合
c.在样本集合d中,采用二分类训练方法训练出各类别的分类准确率均在90%以上的分类器,我们称之为高性能分类器ec;
d.对于未知表位位置的蛋白质抗原,按照以下方法进行表位预测:
①将抗原蛋白的一级序列按照预测窗口分成若干个序列片段组成集合ssd,序列片段中的氨基酸按顺序将其疏水性、可及性、相邻三氨基酸的疏水性与可及性的均值组成特征矩阵作为训练的输入;
②首先利用训练好的互补预测分类器组依次进行预测,将分类器c1和分类器c2分别对集合ssd进行分类识别,由分类器c1预测结果为类别一同时分类器c2预测结果为类别三的片段组成集合erd1(记erdi为分类器ci预测结果为类别一同时分类器ci+1预测结果为类别三的片段组成集合,1≤i≤n-1);然后在集合ssd-erd1中用分类器c3进行分类识别,由分类器c2预测结果为类别一同时第三分类器c3预测结果为类别三的片段组成集合erd2,以此类推,直到在集合
③依照“倾向性打分”方法,对候选的每一序列片段进行打分,根据得分对第一候选表位集合fcs和第二候选表位集合scs中的序列片段进行综合排序,得分高的排在前面。
上述步骤b中,所述“四分类训练方法”的具体操作方法如下:
设第i(1≤i≤n)分类器ci正确识别的样本集合为di,集合di中表位、非表位数据组成的子集合分别是
上述步骤b中,所述“训练终止规则”如下:
设n=number(d)为样本集合d中元素的总数量,ni=number(di)是集合di中元素的数量,
当训练次数大于等于5次小于等于7次时,terminate的返回值为:
当训练次数大于等于8次时,terminate的返回值为:
如果终止参数terminate返回值为0,则训练结束,如果终止参数terminate返回值为1,则继续训练。
上述步骤b中,所述的“适量增加的方法”如下:
设第i分类器ci(i=1,2,...,n)正确识别的样本集合为di。
当i=1时,d1中共有类别一、类别二两种样本,当得到第一分类器c1后,按照以下规则从集合d1中选取第一、第二类数据组成新的训练样本集合:
设g1=d-d1,
当
当
当i=2,...,n时,di中共有类别一、类别二、类别三、类别四等四种类别的样本,分别用子集合
当
当
上述步骤d中,所述“倾向性打分”方法如下:
在抗原表位数据集合中,采用下式计算连续三个氨基酸任意类型组合在表位中的出现频率:
式中,aax,aay,aaz是20种氨基酸中的任意一种,aax-aay-aaz表示连续三个氨基酸的任意类型组合,
如果预测窗口为k,则抗原蛋白的一级序列分成的任意序列片段的倾向性得分为:
本发明在构造出多层分类结构的预测模型的基础上,利用多个具有互补能力的分类器对蛋白质抗原表位进行协同预测,我们在多个盲数据集进行预测实验,实验中预测准确率均大于70%,可见该方法能显著提高蛋白质抗原表位预测的准确性,为精准、快速找到抗原表位提供了有效方法。
附图说明
下面结合附图对本发明作进一步说明。
图1是用于本发明的预测抗原表位方法的“互补分类器组的训练流程图”;
图2是用于本发明的预测抗原表位方法的“表位预测的过程图”。
图中和文中各符号为:d为样本集合,ci为第i个分类器,di为分类器ci正确识别的样本集合,ec为高性能分类器,ssd为序列片段集合,fcs为第一候选表位集合,scs为第二候选表位集合,n=number(d)为样本集合的元素总数量,ni=number(di)是集合di的元素总数量,ri为分类器i和分类器i+1联合预测的正确比,r为第i+1次训练后总的预测比,terminate为终止参数,aax,aay,aaz是20种氨基酸中的任意一种,aax-aay-aaz表示连续三个氨基酸的任意类型组合,
iedb指http://www.iedb.org/专业数据库;uniport指http://www.uniprot.org/蛋白质数据库。
具体实施方式
抗原表位预测一般通过二元分类器实现,而构造具有互补预测能力的分类器,就要突破固有思维的限制。本发明中分类器的构造是在一个二元分类器的基础上,根据其分类结果将样本数据进行组合,在新样本中训练出新的分类器。我们研究发现,通过运用在一组分类器中两个相邻分类器的预测差异来构造多个分类器实现逐步寻优,提出了互补分类器组训练的机制,对抗原表位预测性能提升具有重要的推动作用。
为了能够更清楚地理解本发明的技术内容,下面结合图1、图2对本发明进行详细描述。应理解实例仅是用于说明本发明,而不是对本发明的限制。
1、数据采集
从iedb(http://www.iedb.org/)表位数据库中采集表位序列数据作为训练正样本,该数据库收录了很多被实验验证过的表位数据,覆盖人类、非人灵长类、其他动物等物种。在uniport(http://www.uniprot.org/)蛋白质数据库中找出与所选表位样本对应的蛋白质一级序列,从中抽取出未经标记为表位的序列片段(即非表位序列)作为训练负样本。在我们验证本方法的实验中共抽取了800个蛋白质序列,一共采集到5120个连续表位序列和5200条非表位序列片段。每个样本均以20个氨基酸为“基准长度”,对于非表位样本直接从蛋白序一级列中选取氨基酸个数为20个的未经标记为表位的序列片段。对于表位样本,由于表位序列包含的氨基酸数量存在差异,按照以下方法来满足“基准长度”的要求:对于氨基酸个数小于20且为偶数的表位序列从其所在的蛋白质序列的两侧选取相同个数的氨基酸作为递补,对于氨基酸个数小于20且为奇数的表位序列从其所在的蛋白质序列的前端递补数量比后端多一个来满足基准长度要求;对于氨基酸个数大于20且为偶数的表位序列则从两侧去掉相同个数的氨基酸来满足基准长度要求,而对于氨基酸个数大于20且为奇数的表位序列则从其所在的蛋白质序列的前端减掉数量比后端多一个来满足基准长度要求。对于样本序列,按照样本中氨基酸序列顺序的疏水性、可及性特征以及每相邻三氨基酸的疏水性与可及性的均值组成特征矩阵,该矩阵是训练及预测的输入矩阵。
2、模型建立
在样本集合中,进行互补分类器训练的方法如下:
设样本集合为d,利用二分类训练方法训练,当分类的正确率大于λ(记λ为学习训练分类器的分类准确率,具体数值可根据实际情况设定,λ的取值范围为50%≤λ<100%)后可获得分类器c1,在集合d中c1能正确识别的样本集合记为d1,
所述的“四分类训练方法”的具体内容如下:
在训练得到分类器c1后,将该分类器正确识别的两类样本数据作为新的样本数据参与到新的分类器训练中,即以后的分类器训练都是四分类的。设分类器c1正确识别的样本集合为d1,集合d1中类别一(表位)、类别二(非表位)数据组成的子集合分别是
所述的按照“适量增加的方法”构建新的训练样本集合的具体内容如下:
在得到分类器ci(i=2,...,n)后,进行下一个分类器训练时,根据样本集合在不同类别的数量进行新样本集合的构建。本方法中的样本增加是指将上一分类器正确识别的有关类别样本作为新样本类别参与到下一分类器训练中。一般情况下,一个分类器能够识别各类别的样本数据数量均大于未能正确识别的样本数量,所以需要比较数据集合中的样本数量进行新训练样本集合构建。设分类器ci正确识别的样本集合为di,di中共有四种类别数据分别用子集合
当
当
特别地,当得到训练分类器c1后,按照以下规则进行从集合d1中选取第一、第二类数据组成新的训练样本集合。设g1=d-d1,
当
当
所述的“训练终止规则”具体内容如下:
设n=number(d)为样本集合d中元素的总数量,ni=number(di)是集合di中元素的总数量,
从第3次训练开始前计算r,当训练次数小于等于4次,terminate的返回值为:
当训练次数大于等于5次小于等于7次,terminate的返回值为:
当训练次数大于等于8次,terminate的返回值为:
对于高性能分类器ec的训练,在样本集合d中只需要采用二分类训练当分类准确率达到90%即可。
3、表位预测
对于未知表位位置的蛋白质抗原,按照以下方法进行表位预测:第一步,将抗原蛋白的一级序列按照“基准长度”分成若干个序列片段集合ssd,每一个片段都按照步骤1的“数据采集”所述的方法计算出特征矩阵作为预测输入。第二步,首先利用训练好的互补预测分类器组依次进行预测,将分类器c1和分类器c2分别对集合ssd进行分类识别,由c1预测结果为类别一同时c2预测结果为类别三的片段组成集合erd1(记erdi为分类器ci预测结果为类别一同时分类器ci+1预测结果为类别三的片段组成集合,1≤i≤n-1));然后在集合ssd-erd1中用分类器c3进行分类识别,由c2预测结果为类别一同时c3预测结果为类别三的片段组成集合erd2,按照这种规则直到在集合
所述的“倾向性打分”方法具体内容如下:
在抗原表位数据集合中,采用下式计算连续三个氨基酸任意类型组合在表位中的出现频率:
其中,aax,aay,aaz是20种氨基酸中的任意一种,上式中aax-aay-aaz表示连续三个氨基酸的任意类型组合,
如果预测窗口为k,则抗原蛋白的一级序列分成的任意序列片段的倾向性得分为:
预测方法的准确性评价
本发明筛选了800个抗原蛋白质数据,共计5120条表位序列和5200条非表位序列组成的样本集合。利用了支持向量机(svm)和循环神经网络(rnn)两种算法分别做二分类和四分类训练,共进行了四次训练,分别是第一次采用svm进行二分类训练分类器1,第二次用rnn进行四分类训练分类器2,第三次采用rnn进行四分类训练分类器3,第四次采用rnn训练优出秀性能分类器4。分类器1预测出的第一类序列与分类器2预测出的第三类序列的条数是3325条,分类器2预测出的第一类序列与分类器3预测出的第三类序列的条数是1573条,综合预测准确率达到95.6%。经五重交叉验证分类器4预测准确率为91%。
我们在训练样本外收集了287个蛋白作为盲数据测试集,共包含已验证的表位序列2000条,每次随机抽取1000条进行测试。用上述训练的分类器组预测出的结果为:分类器1与分类器2预测出的表位序列共739条,其中正确的为551条,正确率为74.5%;分类器1与分类器2预测出的表位序列共492条,其中正确的为327条,正确率为66.5%;综合预测正确率为71.3%,正确结果的覆盖率达到了87.8%。分类器4预测出的表位序列共190条,其中正确的为75条,正确率为39.5%。综合两种分类器的结果,正确结果的覆盖率达到了95.3%。
从以上的实验结果来看,本方法具有较高的预测准确率,预测结果能包含大多数的表位,能为抗原表位的筛选提供有效的、科学的依据。
- 还没有人留言评论。精彩留言会获得点赞!