一种基于CPU+GPU+FPGA架构的异构计算系统和方法与流程
本发明涉及异构计算技术领域,具体涉及一种基于cpu+gpu+fpga架构的异构计算系统和方法。
背景技术:
现代社会信息量的暴增对计算机的计算性能提出了更高的要求,通过纵向提高cpu的处理性能已经遇到了制作工艺、功耗等技术瓶颈。cpu的内核架构决定了其比较擅长于处理不规则数据结构和不可预测的存取模式,以及递归算法、分支密集型代码和单线程程序。gpu和fpga的内部架构决定了其具有较强的并行处理能力,使其更擅长于处理计算密集型任务。
现有技术中,gpu虽然能够有效提高计算性能,但存在着功耗高的问题,fpga能够有效降低功耗,具有较高的性能功耗比,但fpga的峰值性能要逊色于gpu。目前高性能计算领域中存在着计算任务之庞大,处理任务类型之繁多等问题,例如,有些应用场景更看重计算性能,而不太关注能耗问题,而有些应用场景既看重计算性能又要求功耗尽可能低,有些应用程序比较适合通过fpga进行加速,而有些应用程序比较适合通过gpu进行加速。
因此需要提出一种新型的计算系统,以适应上述不同的应用场景、满足不同类型的任务需求。
技术实现要素:
针对上述现有技术中的问题,需要针对不同应用场景和不同任务需求进行有针对性的计算,本发明的目的在于提供一种基于cpu+gpu+fpga架构的异构计算系统和方法。
为了实现上述目的,本发明采用的技术方案如下:
根据本发明,提供了一种基于cpu+gpu+fpga架构的异构计算系统,包括cpu主机单元、一个或多个gpu异构加速单元和一个或多个fpga异构加速单元,cpu主机单元分别与gpu异构加速单元、fpga异构加速单元通信连接,其中:
cpu主机单元用于资源管理,以及将处理任务分配给gpu异构加速单元和/或fpga异构加速单元;
gpu异构加速单元对来自cpu主机单元的任务进行并行处理;
fpga异构加速单元对来自cpu主机单元的任务进行串行或并行处理。
进一步地,gpu异构加速单元由opencl语言编程;
fpga异构加速单元由opencl语言编程。
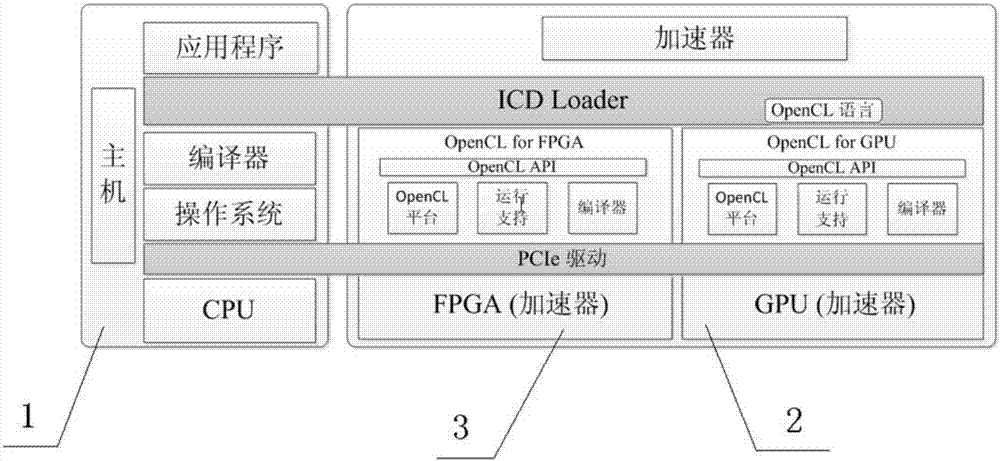
进一步地,通过openclicdloader将gpu异构加速单元和fpga异构加速单元统一到一起,openclicdloader提供所有openclapi接口。
进一步地,gpu异构加速单元包括opencl平台、运行支持库、编译器和opencl驱动;
fpga异构加速单元包括opencl平台、运行支持库、编译器和opencl驱动。
进一步地,cpu主机单元通过pcie与gpu异构加速单元进行通信;
cpu主机单元通过pcie与fpga异构加速单元进行通信。
进一步地,fpga异构加速单元包括固定区和可重构区,其中可重构区能够实现kernel算法的重新配置。
进一步地,gpu异构加速单元和/或fpga异构加速单元包括ddr4内存。
根据本发明,提供了一种基于cpu+gpu+fpga架构的异构计算方法,包括以下步骤:
s00:cpu主机单元对任务进行预处理,并且将所述任务分类为第一类任务和第二类任务;
s10:cpu主机单元通过调用openclicdloader来获取gpu异构加速单元和fpga异构加速单元的列表;
s20:cpu主机单元将第一类任务分配给列表中对应的gpu异构加速单元,并且将第二类任务分配给列表中对应的fpga异构加速单元;
s30:gpu异构加速单元对第一类任务进行并行处理,在处理完后以中断的形式通知cpu主机单元,并且将计算结果传给cpu主机单元;fpga异构加速单元对第二类任务进行串行或并行处理,在处理完后以中断的形式通知cpu主机单元,并且将计算结果传给cpu主机单元;
s40:cpu主机单元读取计算结果后,进行整合、后处理,再将最终结果返给用户。
进一步地,第一类任务为要求高运算速度的任务或图像处理任务;
第二类任务为要求低功耗运行的任务、接口通信任务或数据加解密任务。
进一步地,步骤s30中:
gpu异构加速单元处理的结果和/或fpga异构加速单元处理的结果通过pcie传给cpu主机单元。
本发明通过以上技术方案,能够获得以下有益技术效果:
通过设置分别与cpu主机单元通信连接的gpu异构加速单元和fpga异构加速单元,可以根据不同场景,以及对运算峰值和速度的要求或对功耗的要求,来调整分配给gpu异构加速单元和fpga异构加速单元的任务,从而满足以上要求;
cpu主机单元作为主机负责处理资源管理、任务分配等工作,gpu异构加速单元与fpga异构加速单元负责处理计算密集型任务。gpu异构加速单元强大的并行处理能力能够更好地图像处理、模式识别、机器学习任务。本发明的异构计算系统,能够充分发挥cpu的管控优势、gpu的并行处理优势、fpga的性能功耗比并且具有灵活配置的优势,可适应不同的应用场景,满足不同类型的任务需求。
当然,实施本发明的任一产品必不一定需要同时达到以上所述的所有技术效果。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例所述的基于cpu+gpu+fpga架构的异构计算系统的示意图;
图2为本发明实施例所述的基于cpu+gpu+fpga架构的异构计算系统的结构示意图;
图3为本发明实施例所述的基于cpu+gpu+fpga架构的异构计算系统一个示例的示意图;
图4为本发明实施例所述的基于cpu+gpu+fpga架构的异构计算方法的流程图。
具体实施方式
如在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可理解,硬件制造商可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求当中所提及的“包括”为一开放式用语,故应解释成“包括但不限定于”。说明书后续描述为实施本发明的较佳实施方式,然所述描述乃以说明本发明的一般原则为目的,并非用以限定本发明的范围。本发明的保护范围当视所附权利要求所界定者为准。
本发明的一个实施例中,如图1-2所示,本实施例提供的基于cpu+gpu+fpga架构的异构计算系统,包括cpu主机单元1、一个或多个gpu异构加速单元2和一个或多个fpga异构加速单元3。其中cpu主机单元1分别与gpu异构加速单元2、fpga异构加速单元3通信连接,具体地,cpu主机单元1通过pcie与gpu异构加速单元2进行通信和/或fpga异构加速单元3进行通信,具体地,pcie为pcie3.0、pcie3.0-dma。gpu异构加速单元2和fpga异构加速单元3为加速器,负责对计算密集型任务进行加速。cpu主机单元1用于资源管理,以及将处理任务分配给gpu异构加速单元2和/或fpga异构加速单元3,尤其是将计算量大的任务按照任务类型分配给gpu异构加速单元2和fpga异构加速单元3,以发挥gpu异构加速单元2和fpga异构加速单元3中的gpu和fpga各自的性能优势;gpu异构加速单元2对来自cpu主机单元1的任务进行并行处理;fpga异构加速单元3对来自cpu主机单元1的任务进行串行或并行处理。gpu异构加速单元2和fpga异构加速单元3由opencl语言编程。通过中间件openclicdloader将gpu异构加速单元2和fpga异构加速单元3统一到一起,openclicdloader提供所有openclapi接口,并将任务传递到指定的gpu异构加速单元2或fpga异构加速单元3上,以充分发挥gpu和fpga的各自性能优势,满足不同类型的应用需求,其中gpu异构加速单元2和fpga异构加速单元3的数量分别可以为多个。
进一步地,gpu异构加速单元2和fpga异构加速单元3分别包括各自的opencl平台、运行支持库、编译器和opencl驱动等部分。
进一步地,gpu异构加速单元2和/或fpga异构加速单元3包括ddr4内存。具体地,可采用具有8位ecc校验位的ddr4,可支持2个sodimm,其单条最大支持8gbddr4x72bit@1333mhz/2400mt/s。
进一步地,fpga异构加速单元3包括固定区和可重构区,即fpga内部逻辑分为固定区和可重构区两部分。fpga中固定区主要实现pcie3.0、ddr4控制器、serdes串行通信、dma等功能。固定区在整个fpga使用过程中固定不变。可重构区能够实现kernel算法的重新配置。用户可以根据不同的应用需求,将不同的kernel算法通过固定区下载到可重构区,从而实现不同的算法应用。该kernel算法可以通过opencl进行实现,也可以通过rtl进行实现。
具体地,fpga异构加速单元3采用alteraa10gx1150芯片。
本发明的又一实施例中,如图4所示,本实施例提供的一种基于cpu+gpu+fpga架构的异构计算方法,包括以下步骤:首先,cpu主机单元1对任务进行预处理,并且将任务分类为第一类任务和第二类任务;之后,cpu主机单元1通过调用openclicdloader来获取gpu异构加速单元2和fpga异构加速单元3的列表;然后,cpu主机单元1将第一类任务分配给列表中对应的gpu异构加速单元2,并且将第二类任务分配给所述列表中对应的fpga异构加速单元3;之后,gpu异构加速单元2对第一类任务进行并行处理,在处理完后以中断的形式通知cpu主机单元1,并且将计算结果传给cpu主机单元1;fpga异构加速单元3对第二类任务进行串行或并行处理,在处理完后以中断的形式通知cpu主机单元1,并且将计算结果传给cpu主机单元1,具体地,gpu异构加速单元2处理的结果和/或fpga异构加速单元3处理的结果通过pcie传给cpu主机单元1;之后,cpu主机单元1读取计算结果后,进行整合、后处理后,将最终结果返给用户。
其中,cpu主机单元1中的应用程序可以通过调用openclicdloader来获取所有已经安装的gpu异构加速单元2和fpga异构加速单元3的列表,并从中选择使用gpu异构加速单元2或fpga异构加速单元3,应用程序的所有openclapi请求将被转移到指定的gpu异构加速单元2或fpga异构加速单元3上。
其中,第一类任务为要求高运算速度的任务或图像处理任务;第二类任务为要求低功耗运行的任务、接口通信任务或数据加解密任务。
本发明的一个具体实施例中,如图3所示,为视频会议的应用场景,通过本发明所提供的cpu+gpu+fpga架构的异构计算系统实现接口通信、数据加解密、图像处理等功能。由于fpga具有较强的接口逻辑实现功能,因此采用fpga异构加速单元3实现与外部的接口通信,并利用其对数据进行加解密。由于gpu先天的图像处理能力,采用gpu异构加速单元2负责图像处理任务将会获得性能的大幅提升。cpu主机单元1负责对任务进行分配,并将各异构加速单元所得结果进行后处理,再反馈给用户。通过本示例,可以看出,本发明所提供的cpu+gpu+fpga架构的异构计算系统能够充分发挥各异构加速单元各自的优势,大大提升计算系统的计算性能。
术语解释:
cpu:中央处理器,centralprocessingunit。
gpu:图形处理器,graphicsprocessingunit。
fpga:现场可编程门阵列,fieldprogrammablegatearray。
opencl:开放计算语言,opencomputinglanguage。
openclicdloader:openclinstallableclientdriver(icd)loader,是实现opencl应用程序与各硬件厂商提供的opencl驱动(platform)之间隔离的中间库。
api:应用程序编程接口,applicationprogramminginterface。
pcie:peripheralcomponentinterconnectexpress,一种高速串行计算机扩展总线标准。
以上实施例提供的一种基于cpu+gpu+fpga架构的异构计算系统和方法,具有以下有益效果:通过设置分别与cpu主机单元通信连接的gpu异构加速单元和fpga异构加速单元,可以根据不同场景,以及对运算峰值和速度的要求或对功耗的要求,来调整分配给gpu异构加速单元和fpga异构加速单元的任务,从而满足以上要求;
cpu主机单元作为主机负责处理资源管理、任务分配等工作,gpu异构加速单元与fpga异构加速单元负责处理计算密集型任务。gpu异构加速单元强大的并行处理能力能够更好地完成图像处理、模式识别、机器学习等任务。本发明的异构计算系统,能够充分发挥cpu的管控优势、gpu的并行处理优势、fpga的性能功耗比并且具有灵活配置的优势,可适应不同的应用场景,满足不同类型的任务需求。
采用openclicdloader将gpu异构加速单元和fpga异构加速单元统一到一起,并采用opencl编程语言对gpu和fpga统一编程,能够根据不同应用需求对gpu和fpga实现灵活配置,从而对不同的应用进行加速,以满足不同的应用需求,并且采用opencl语言对fpga进行编程能够大大缩短开发周期,实现fpga的在线灵活配置。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本发明的若干实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!