一种单目深度视频的二维人体骨骼点定位方法与流程
本发明涉及二维人体姿态识别、计算机视觉、模式识别和人机交互领域,特别涉及一种基于长短时记忆卷积神经网络的单目深度视频二维人体骨骼点定位方法。
背景技术:
人体骨骼点定位是计算机视觉研究领域的一个重要研究方向,其主要任务是让计算机能够自动地感知场景中的人是“什么姿势”,它被广泛应用于家庭娱乐、动作识别、智能监控、病人监护等需要人机交互的系统中。
人体姿态估计的目标是希望能够自动地从一段二维图像序列中,预测人肢体各个部分的姿态数据(即,骨骼点在图像中的坐标)。由于普通的rgb彩色图像或视频中存在光照、复杂背景等环境因素的影响,从单目彩色图像中预测出人体骨骼点非常困难,难以做到鲁棒。而由深度距离摄像机捕获的二维深度图像,与rgb彩色数据不同,其每个像素的灰度值表示的是该点对应区域在真实空间中与摄像机的毫米距离。因此,其具有一定的抗光照变化和背景复杂的能力,能有效地反映出图像场景中的几何轮廓信息,因此被认为是计算机视觉和人机交互的研究领域中重要的数据源。
基于深度图像的二维人体骨骼点定位是指从一张包含有人物或者人体的二维深度图片中,定位出人体各个骨骼点的位置。由于深度二维图像本身存在不可忽略的噪声和人体姿态中四肢之间的遮挡,稳定快速准确地识别以上所述的骨骼点仍然是非常困难的挑战。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种基于长短时记忆卷积神经网络的单目深度视频的二维人体骨骼点定位方法,该方法可以有效地从深度视频数据中,端到端自动地学习出复杂人物姿态的时空特征,提高人体骨骼点定位的准确率。
为实现上述目的,本发明采用以下技术方案:
一种单目深度视频的二维人体骨骼点定位方法,包括以下阶段:
s1、深层模型构建。该模型包括二维特征抽取模块和时序特征表达模块;
其中,二维特征抽取模块由多个二维卷积层和矫正线性单元层依次串联,其间穿插连接多个池化层组成,用于对深度视频数据进行逐帧处理,抽取人物姿态的二维空间特征,输出深度图像中人物的关键区域和二维人体骨骼点到时序特征表达模块;时序特征表达模块由长短时记忆卷积层组成,用于抽取连续多帧的二维深度图像的时空特征,输出k个概率置信图,k为待预测的骨骼点数目,用以预测出当前帧的二维人体骨骼点坐标。
s2、训练过程。该过程包含以下步骤:
s21收集训练样本。从深度距离摄像机,获取连续多帧二维深度图像的视频数据、每帧二维图像中真实的二维人体骨骼点坐标。其中,视频数据由深度距离相机采集,配合用户精细标注的二维人体骨骼点坐标,用于学习深层模型的参数。
s22生成训练目标。训练目标包含由真实的二维人体骨骼点坐标生成的概率置信图和关键区域坐标;其中,每个骨骼点对应一个二维的概率置信图。该图的每个像素值表示像这个骨骼点的概率;关键区域表示二维深度图像中包含人物的矩形框,该矩形框由4个变量表示,依次是中心的横坐标、中心的纵坐标、矩形框高、矩形框宽。
s23随机初始化深层模型及其参数。所述的参数由卷积层的参数和长短时记忆卷积层中的参数组成。其中,卷积层的参数包括卷积核的权重和偏置;长短记忆卷积层中的参数包括输入卷积门、输出卷积门、忘记卷积门和记忆元组的权重和偏置。
s24采用模型优化算法,端到端地利用训练样本更新深层模型的参数。所述模型优化算法具体地是指采用基于一阶梯度的随机优化算法adam(adaptivemomentestimation,adam),联合二维特征抽取模块和时序特征表达模块一起更新参数。学习过程用的损失函数是预测的关键区域坐标与真实的关键区域坐标的欧式距离,和预测的特征图与真实的置信图的欧氏距离;采用时序反向传播算法求长短时记忆层中各个参数的偏导数;根据长短时记忆层传入的残差,通过反向传播算法求卷积层中各个参数的偏导数;根据计算结果更新模型参数并重复迭代计算。
s3、识别过程。该过程包含以下步骤:
s31输入单目深度视频帧。其中,单目深度视频帧由一个深度距离摄像机捕获,形成二维深度图像序列。
s32利用训练好的深层模型推断预测出其中的人体关节点位置。将s3-1形成的二维图像序列依次输入深层模型中,首先输出关键区域坐标,以从输入原图上提取关键区域,再紧接着输入网络,输出其中的人物各个骨骼点的概率置信图,最终根据置性图中的最大概率,得到骨骼点二维坐标。
与现有技术相比,本发明的有益效果是:
第一,本发明通过构建深层次的长短时卷积神经网络,采用数据驱动的方式,从大量的包含了多种深度距离摄像机摆放角度、深度距离摄像机与人不同距离和各种人的躯干四肢之间的遮挡等训练样本中,学习出有效的时空人物姿态特征。该特征不再受限于手工设计特征的先验条件和人体骨骼点的几何结构约束,可有效地用于定位人体的骨骼点。
第二,本发明用一个模型同时强调了人体二维骨骼点的空间关系和时序一致性;本发明建模的时空一致性具有端对端训练的可微分结构,结合数据驱动,可以自适应地整体优化模型的各个模块。同时,本发明借助优化出的人体骨骼点时空特征能抗深度数据噪声和人体自遮挡等多种挑战,实现了稳定可靠的二维人体骨骼点定位。
附图说明
图1是本发明提供的一种单目深度视频的二维人体骨骼点定位方法的流程示意图;
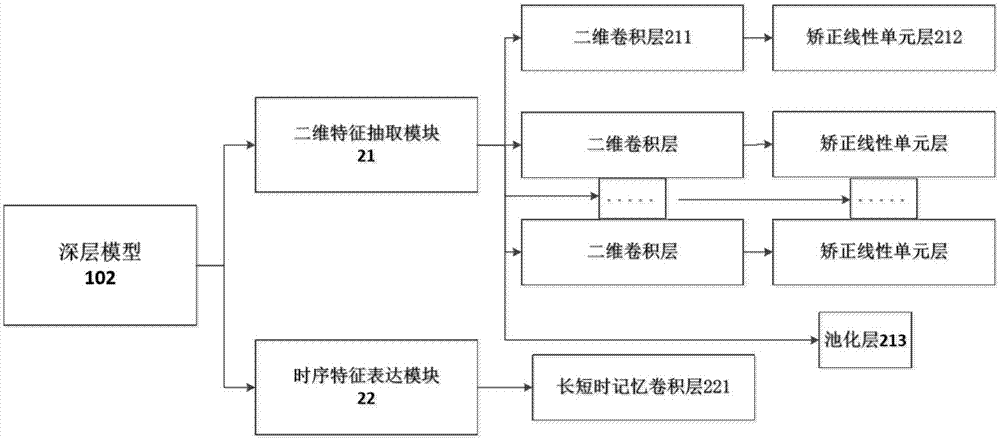
图2是本发明的深层模型框架图;
图3是本发明的深层模型中二维特征抽取模块的框架图;
图4是本发明的深层模型中二维特征抽取模块详细网络设置图;
图5是本发明的深层模型中时序特征表达模块的框架图;
图6是本发明提供的一种单目深度视频的二维人体骨骼点定位方法的数据流向图;
图7是本发明支持的15个人体骨骼点示意图。
具体实施方式
下面结合附图,对本发明的单目深度视频的二维人体骨骼点定位方法做详细说明。
如图1所示,本发明提供了一种单目深度视频的二维人体骨骼点定位方法,包括构建模型、训练过程和识别过程,具体的构建模型包括构建深层模型102;训练过程包括使用深度距离相机捕获数据100,收集训练样本生成训练目标101,初始化参数、训练模型103;识别过程包括使用深度距离相机捕获数据100,利用训练好的模型预测人体骨骼点104。
s1、深层模型构建,包括构建深层模型102。
s2、训练过程,该过程包含以下步骤:
s21收集训练样本,包括使用深度距离相机捕获数据100,具体为从深度距离摄像机,获取连续多帧二维深度图像的视频数据、每帧二维图像中真实的二维人体骨骼点坐标。其中,视频数据由深度距离相机采集,配合用户精细标注的二维人体骨骼点坐标,用于学习深层模型的参数。
s22生成训练目标,包括收集训练样本生成训练目标101,具体为训练目标包含由真实的二维人体骨骼点坐标生成的概率置信图和关键区域坐标;其中,每个骨骼点对应一个二维的概率置信图。该图的每个像素值表示像这个骨骼点的概率;关键区域表示二维深度图像中包含人物的矩形框,该矩形框由4个变量表示,依次是中心的横坐标、中心的纵坐标、矩形框高、矩形框宽。
s23随机初始化深层模型及其参数,包括初始化参数、训练模型103。所述的参数由卷积层的参数和长短时记忆卷积层中的参数组成。其中,卷积层的参数包括卷积核的权重和偏置;长短记忆卷积层中的参数包括输入卷积门、输出卷积门、忘记卷积门和记忆元组的权重和偏置。
s24采用模型优化算法,端到端地利用训练样本更新深层模型的参数。
s3、识别过程,包括利用训练好的模型预测人体骨骼点104。该过程包含以下步骤:
s31输入单目深度视频帧。其中,单目深度视频帧由一个深度距离摄像机捕获100,形成二维深度图像序列。将s31形成的二维图像序列依次输入深层模型中,首先输出关键区域坐标,以从输入原图上提取关键区域,再紧接着输入网络,输出其中的人物各个骨骼点的概率置信图,最终根据置性图中的最大概率,得到骨骼点二维坐标。
s32利用训练好的深层模型推断预测出其中的人体骨骼点位置。
本发明中,如图2所示,构建深层模型102包括二维特征抽取模块21和时序特征表达模块22。二维特征抽取模块21由多个二维卷积层211和矫正线性单元层212依次串联,其间穿插连接多个池化层213组成,时序特征表达模块22由长短时记忆卷积层221组成。
二维特征抽取模块21如图3所示,二维特征抽取模块由多个二维卷积层和矫正线性单元层依次串联,其间穿插连接多个池化层组成,用于对深度视频数据进行逐帧处理,抽取人物姿态的二维空间特征。
时序特征表达模块22如图5所示,时序特征表达模块由长短时记忆卷积层组成,用于抽取连续多帧的二维深度图像的时空特征,输出k个概率置信图,k为待预测的骨骼点数目,用以预测出当前帧的二维人体骨骼点坐标。
下面将对本发明提出的深层模型进行详细说明。
如图4所示,给出了本发明的一种具体实施方式,二维特征抽取模块中包含23个二维卷积层(图中标记为卷积层),4个降采样池化层(图中标记为池化层)、2个全连接层(图中标记为全连接层)、1个反卷积层(图中标记为反卷积层)、1个特征图并联层(图中标记为并联层)和图像裁剪层。
二维卷积层:所述二维卷积层用于对输入的图像或者特征图在二维空间上进行卷积运算,提取层次化特征。假设输入深度图像的宽度和高度分别为w和h,通道数为1,二维卷积核的大小为w′×h′×m′,其中w′、h′、m′分别表示宽度、高度和通道数。卷积后可以获得一个特征图。其中位于特征图(x,y)位置处的值可以表示成,
其中p(x+i)(y+j)(s+k)表示输入的第(s+k)帧中(x+i,y+j)位置的像素值,ωijk表示卷积核的参数,b表示跟与该特征图相关的偏置。故此我们可以得到1个特征图,每个特征图的大小为(w-w'+1,h-h'+1)。由于单个卷积核只能抽取一种类型的特征,因此我们在每一层卷积层引入了多个卷积核抽取多种不同的特征。
降采样池化层:降采样我们使用max-pooling操作。该操作是指对特征图按照一定策略(选取最大值)进行降采样的过程。这是一种被广泛应用的有效过程,它能够提取出保持形状和偏移不变性的特征。对于一组特征图,max-pooling操作通过对它们降采样,得到同样数量的一组低分辨率特征图。更多地,如果在a1×a2大小的特征图上应用2×2的max-pooling操作,抽取2×2不重叠区域上的最大值,我们将得到大小为a1/2×a2/2的新特征图。
矫正线性单元层:该层是采用简单的非线性阈值函数,对输入进行只允许非负信号通过的变换。假设表示g本层的输出,w表示本层边的权重,a表示本层输入,则我们有
g=max(0,wta)
实验证明在深层次卷积神经网络中,使用矫正线性单元层可使得训练时网络的收敛速度比传统的激励函数更快。
全连接层:该层将输入的特征图直接拉成一个长特征向量。该向量即表示从深度图像抽取到的关键区域特征。它的每一维元素都连向第一个全连接层(隐藏层)的所有节点,并进一步全连接到所有的输出单元。输出单元共4个,这里表示关键区域的坐标,分别对应关键区域矩形框的中心的横坐标,中心的纵坐标、矩形框高、矩形框宽。
图像裁剪层:根据传入的关键区域坐标,在输入图片上裁剪出新的图片。传入的关键区域坐标是一个矩形框,由四个变量表示(中心的横坐标、中心的纵坐标、矩形框高、矩形框宽)。
反卷积层:对输入的图像或者特征图在二维空间上进行反卷积运算,进行上采样操作。假设输入深度图像的第i个像素点为xi,二维反卷积核中对其有贡献的权重为
特征图并联层:将多组特征图并联在一起,这些特征图有相同的批数量、宽度和高度。假设有两组特征图依次表示为四元组(批数量、通道数1、高度、宽度)、(批数量、通道数2、高度、宽度),则经过特征图并联层,输出为(批数量、通道数1+通道数2、高度、宽度),即从通道数上将特征图并联在一起。
在本发明实施例中,时序特征表达模块由一个长短时记忆卷积层构成,用于抽取连续多帧的二维深度图像的时空特征,输出k个概率置信图,k为待预测的骨骼点数目,用以预测出当前帧的二维人体骨骼点坐标。在本发明中,k初步设置为15。如图7所示,骨骼点可以包括头部1,颈部2,躯干中心3,左肩4,左肘5,左腕6,右肩7,右肘8,右腕9,左臀10,左膝11,左踝12,右臀13,右膝14,右踝15中的任何一个或者多个的组合。
长短时记忆卷积层:该层由一定数量的长短时记忆单元组成。如图5所示,每个长短时记忆单元包括1个输入卷积门、1个输出卷积门、1个忘记卷积门和1个记忆元组;具体来讲,输入卷积门用于对输入进行预处理,输出卷积门用于对输出做后处理,忘记卷积门用于控制记忆元组,对记忆元组记录的内容进行自适应地遗忘。这里的卷积门是指常规的卷积操作。长短时记忆卷积层不同于采用矩阵乘法的长短时记忆层,能够保留数据的二维空间结构信息,结合记忆元组对时序信息的建模,能够有效地学习出二维时序与空间结构特征(时空特征)。更具体的公式表示如下。
输入卷积门:
遗忘卷积门:
记忆元组:
输出卷积门:
输出:
第t帧输入卷积门、忘记卷积门和输出卷积门分别由it、ft、ot表示,记忆单元c(时序上不同时间的记忆单元状态不同,ct和ct-1分别表示在t和t-1时刻的记忆元组状态)。xt表示在t时刻的输入特征(可以为中间特征图或原图像),b表示卷积核中的偏置(bi、bf、bo依次表示输入卷积门、忘记卷积门和输出卷积门的偏置),w表示卷积核的权重(wi、wf、wo依次表示输入卷积门、忘记卷积门和输出卷积门的权重),σ表示sigmoid激活函数,tanh表示tanh函数,*和о分别表示卷积操作和点乘操作,ht和ht-1分别表示在t和t-1时刻的输出特征。在进行前向传播的时候,输入包括t时刻的输入特征xt和t-1时刻的输出特征ht-1,从而通过计算得到ht。
模型的训练:模型优化算法具体地是指采用基于一阶梯度的随机优化算法adam,联合二维特征抽取模块和时序特征表达模块一起更新参数。学习过程用的损失函数定义如下:
其中,p是预测出的关键区域坐标,p*是真实的关键区域坐标,k是骨骼点数目,bk(z)是骨骼点k的预测特征图,
图6是本发明提供的一种单目深度视频的二维人体骨骼点定位方法的数据流向图。从该图可以看出,经深度距离摄像机捕获的第t帧图像,1)传入二维特征抽取模块,首先历经多重卷积和池化,进行关键区域定位,根据定位结果对输入的第t帧图像进行裁剪,再经过多重卷积和池化,输出第t帧的二维人体骨骼点特征图;2)传入时序特征表达模块,历经输入、输出、忘记卷积门和在t-1次状态的记忆元组等相关操作,输出t+1次状态的记忆元组和第t帧的k个概率置信图;根据所得的第t帧的k个概率置信图,分别取其中最大概率的坐标,加上关键区域的坐标,最终得到预测的人体骨骼点坐标。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!