文本隐含语义激活方法及系统与流程
本发明涉及计算机科学技术领域,尤其涉及一种文本隐含语义激活方法及系统。
背景技术:
面对当前互联网上的海量动态数据,信息过载问题成为网络用户获取有效信息的一大阻碍。以社交媒体平台为代表,用户生成的文本噪声多,语义模糊,内容风格自由且高速变化,导致了大量隐含信息的存在。因此,从大规模数据中挖掘隐含信息,实现高效准确的隐含语义分析,具有十分重要的应用价值。
以往的隐含语义分析工作主要可以分为两类,一类利用外部知识库(wordnet、维基百科等)或外部技术技术(搜索引擎,机器翻译等)扩充待测文本的语义信息。其代表性工作包括kim等(kim,h.-j.,k.-j.hongandj.y.chang(2015).semanticallyenrichingtextrepresentationmodelfordocumentclustering.proceedingsofthe30thannualacmsymposiumonappliedcomputing.)利用维基百科中的文本信息扩充待测文本,并应用在文本聚类工作中。这类方法的缺陷是需要借助外部知识,灵活性较差,且难以做到知识的实时更新以适应快速变化的互联网信息动态。另一类方法通过构建语言模型等方法来挖掘文本隐含语义信息,对文本进行向量化的抽象表示。其代表性方法包括blei等提出的lda(blei,d.m.,a.y.ngandm.jordan(2003)."latentdirichletallocation."thejournalofmachinelearningresearch3:993-1022)和le等提出的paragraph2vec(le,q.v.andt.mikolov(2014).distributedrepresentationsofsentencesanddocuments.proceedingsofthe31stinternationalconferenceonmachinelearning.)。这些方法通过建模获取文本的高层抽象语义信息,但是原有的文本信息会因此丢失,因而产生高层抽象内容难以直观解释、难以结合其他语义分析方法的问题。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决通过建模获取文本的高层抽象语义信息,致使原有的文本信息丢失,导致无法直观解释、难以结合其他语义分析方法的问题,本发明提供了一种文本隐含语义激活方法及系统。
为实现上述目的,本发明提供了如下方案:
一种文本隐含语义激活方法,所述激活方法包括:
获取待测文本的待测词项信息;
根据文本集合知识库及所述待测文本的待测词项信息,确定所述文本集合知识库的词表中每个参考词项的激活系数;所述文本集合知识库包括多个参考词项共同构成的词表、对应各参考词项的参考词向量及参考词频;
根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合;
将所述隐含语义集合添加到所述待测文本中进行语义扩充。
可选的,所述激活方法还包括:
对预收集的原始文本集合进行训练,构建文本集合知识库。
可选的,所述对预收集的原始文本集合进行训练,构建文本集合知识库,具体包括:
对原始文本集合进行训练进行预处理,确定包含全部参考词项的原始词项集合;
过滤掉所述原始词项集合中的停用词,获得参考词项集合;
根据所述参考词项集合中的各参考词项,构建词表;
统计各参考词项出现的次数,确定对应的参考词频;
通过词向量训练工具对文本集合进行训练,确定各参考词项对应的参考词向量。
可选的,所述获取待测文本的待测词项信息,具体包括:
对所述待测文本进行句段划分和分词,获得所述待测文本的待测词项;
基于所述文本集合知识库,确定所述各待测词项的待测词向量及待测词频。
可选的,所述确定所述各待测词项的待测词向量及待测词频,具体包括:
根据所述待测词项,对所述文本集合知识库中的各参考词向量进行检索,确定各待测词项对应的待测词向量;
根据所述文本集合知识库中各参考词频,确定各待测词项对应的待测词频。
可选的,所述确定各待测词项的待测词向量及待测词频,还包括:
通过词向量训练工具,对所述待测词项进行训练,获得所述待测词项对应的增量式的待测词向量;
统计所述待测文本中各待测词项出现的频率,并结合所述文本集合知识库中各参考词频,确定各待测词项的待测词频。
可选的,所述激活方法还包括:
将动态获得的所述待测文本更新的待测词项、待测词向量及待测词频添加到所述文本集合知识库中进行扩充,更新所述文本集合知识库的词表、参考词向量及参考词频。
可选的,所述确定所述文本集合知识库的词表中每个参考词项的激活系数,具体包括:
计算所述文本集合知识库的词表中每个参考词项与待测文本的联合关联强度;
根据每个参考词项的词频及其与待测文本的联合关联强度确定各参考词项的激活系数。
可选的,所述计算所述文本集合知识库的词表中每个参考词项与待测文本的联合关联强度,具体包括以下任意一种:
分别计算各参考词项所对应词向量与待测文本中的每个待测词项所对应词向量的相似度,计算各相似度的加权平均值,确定所述联合关联强度;
计算待测文本中的各待测词项所对应词向量的加权平均向量,计算所述加权平均向量与各参考词项所对应词向量的相似度,确定所述联合关联强度;
将待测文本进行句段划分,计算划分后的各集合中的划分词项所对应词向量的划分加权平均向量,分别计算各划分加权平均向量与各参考词项所对应词向量的相似度,计算各相识度的平均值,确定所述联合关联强度;
随机选取待测文本中的多个子片段,计算每个子片段中的片段词项所对应词向量的片段加权平均向量,分别计算各片段加权平均向量与各参考词项所对应词向量的相似度,计算各相似度的平均值,确定所述联合关联强度。
可选的,所述根据每个参考词项与待测文本的联合关联强度确定各参考词项的激活系数,具体包括以下任意一种:
每个参考词项与待测文本的联合关联强度作为对应各参考词项的激活系数;
计算各参考词项的参考词频与对应参考词项与待测文本的联合关联强度加权求和,确定各参考词项的激活系数。
可选的,所述根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合,具体包括:
基于所述待测文本,计算所述隐含语义集合的长度ny;
对各激活系数进行排序,根据排序结果和所述隐含语义集合的长度ny确定隐含语义集合。
可选的,所述基于所述待测文本,计算所述隐含语义集合的长度ny,具体包括:
根据以下公式确定所述隐含语义集合的长度ny:
ny=αnx;
其中,α表示激活比率,nx表示待测文本中的待测词项。
可选的,所述根据排序结果和所述隐含语义集合的长度ny确定隐含语义集合,具体包括以下任意一种:
选取激活系数从大到小排序的前ny个参考词项构成所述隐含语义集合;
依次选取激活系数最大的词项添加到所述隐含语义集合中;直到所述隐含语义集合中所有词项对应的激活系数之和大于或等于ny。
为实现上述目的,本发明还提供了如下方案:
一种文本隐含语义激活系统,所述激活系统包括:
获取单元,用于获取待测文本的待测词项信息;
确定单元,用于根据文本集合知识库及所述待测文本的待测词项信息,确定所述文本集合知识库的词表中每个参考词项的激活系数;所述文本集合知识库包括多个参考词项共同构成的词表、对应各参考词项的参考词向量及参考词频;
选取单元,用于根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合;
扩充单元,用于将所述隐含语义集合添加到所述待测文本中进行语义扩充。
可选的,所述激活系统还包括:
知识库构建单元,用于对预收集的原始文本集合进行训练,构建文本集合知识库。
可选的,所述知识库构建单元包括:
预处理模块,用于对原始文本集合进行训练进行预处理,确定包含全部参考词项的原始词项集合;
过滤模块,用于过滤掉所述原始词项集合中的停用词,获得参考词项集合;
构建模块,用于根据所述参考词项集合中的各参考词项,构建词表;
统计模块,用于统计各参考词项出现的次数,确定对应的参考词频;
训练模块,用于通过词向量训练工具对文本集合进行训练,确定各参考词项对应的参考词向量。
根据本发明的实施例,本发明公开了以下技术效果:
本发明文本隐含语义激活方法及系统通过文本集合知识库及所述待测文本的待测词项信息可确定所述文本集合知识库的词表中每个参考词项的激活系数,进而根据各激活系数确定待测文本的隐含语义集合,从而对所述待测文本中进行语义扩充,从而能够准确确定待测文本的隐含信息,准确度高。
附图说明
图1是本发明文本隐含语义激活方法的流程图;
图2是本发明文本隐含语义激活方法中确定激活系数的流程图;
图3是本发明文本隐含语义激活系统的结构示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
本发明的目的是提供一种文本隐含语义激活方法及系统,通过文本集合知识库及所述待测文本的待测词项信息可确定所述文本集合知识库的词表中每个参考词项的激活系数,进而根据各激活系数确定待测文本的隐含语义集合,从而对所述待测文本中进行语义扩充,从而能够准确确定待测文本的隐含信息,准确度高。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明文本隐含语义激活方法包括:
步骤110:获取待测文本的待测词项信息。
步骤120:根据文本集合知识库及所述待测文本的待测词项信息,确定所述文本集合知识库的词表中每个参考词项的激活系数。
所述文本集合知识库包括多个参考词项共同构成的词表、对应各参考词项的参考词向量及参考词频。
步骤130:根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合。
步骤140:将所述隐含语义集合添加到所述待测文本中进行语义扩充。
此外,本发明文本隐含语义激活方法还包括:
步骤100:对预收集的原始文本集合进行训练,构建文本集合知识库。
在根据本发明文本隐含语义激活方法进行隐含语义激活时,只需在首次使用时执行步骤100,构建知识库。
其中,预收集的原始文本集合至少包括1000篇同类型文本。所述文本类型可以为长文本或短文本。长文本单篇文档中词数为50以上,短文本单篇文档中的词数为2到50之间。
在步骤100中,所述对预收集的原始文本集合进行训练,构建文本集合知识库,具体包括:
步骤1001:对原始文本集合进行训练进行预处理,确定包含全部参考词项的原始词项集合。
其中,所述预处理包括对原始文本集合进行清洗、分词、语义集合划分,获得全部词项。
“词”代表文本中的最小语义单元。对于英文等以空格作为分隔符的文本,词为两空格间的一个单词;对于中文等没有空格作为分隔符的文本,词由分词工具进行分词后获得。词项代表不重复的词。
步骤1002:过滤掉所述原始词项集合中的停用词,获得参考词项集合。
统计文本集合中出现的所有词项,或去掉常用停用词,得到文本集合词表并保存为如下的集合形式:
{“雨”;“一直”;“下”;“气氛”;“不算”;“融洽”;……}。
步骤1003:根据所述参考词项集合中的各参考词项,构建词表。
步骤1004:统计各参考词项出现的次数,确定对应的参考词频。
针对词表中的每个词项,统计其在文本集合中出现的频率并保存为如下的字典形式:
{“雨”:20;
“气氛”:8;
“融洽”:32;
“人民”:20;
“金字塔”:12;
……}。
步骤1005:通过词向量训练工具对文本集合进行训练,确定各参考词项对应的参考词向量。
其中,词向量为1×l的词的向量化表示,每个词项有其唯一确定的词向量,作为其抽象化的语义信息。词向量通过word2vec等词向量训练工具获得。以word2vec为例,对于含m篇文档、v个词项的文本集合,word2vec的输入为m个列表,每个列表分别是相应文档的词序列;输出为v个1×l的词向量。词向量以如下的字典形式保存(该实施例中为展示方便以l=5为例):
{“雨”:[5.6,9.0,4.1,9.5,4.5];
“气氛”:[3.3,7.7,1.7,7.1,8.9];
“融洽”:[6.8,10.0,9.3,8.8,4.0];
“人民”:[5.4,9.4,1.8,6.2,4.2];
“金字塔”:[1.8,9.3,4.0,1.5,0.8];
……}
为了加快下一步的搜索速度,此处和以下提到的字典优先考虑使用哈希结构进行储存。
在步骤110中,所述获取待测文本的待测词项信息,具体包括:
步骤1101:对所述待测文本进行句段划分和分词,获得所述待测文本的待测词项。其中,划分标准可以是以句或子句划分,也可以是以自然段落划分,还可以根据实际使用需求以其他形式划分。词为英文单词,或由分词工具对中文文本进行分词后获得。
步骤1102:基于所述文本集合知识库,确定所述各待测词项的待测词向量及待测词频。
其中,步骤1102中,所述确定所述各待测词项的待测词向量及待测词频,具体包括:
步骤11021:根据所述待测词项,对所述文本集合知识库中的各参考词向量进行检索,确定各待测词项对应的待测词向量;
步骤11022:根据所述文本集合知识库中各参考词频,确定各待测词项对应的待测词频。
此外,在步骤1102中,所述确定所述各待测词项的待测词向量及待测词频,还可以包括:
步骤11021a:通过词向量训练工具,对所述待测词项进行训练,获得所述待测词项对应的增量式的待测词向量。这样做可以在利用已有词向量训练结果的同时获取新词项的词向量,大大提高了知识库的利用效率。
步骤11022a:统计所述待测文本中各待测词项出现的频率,结合文本集合知识库中各参考词频,确定各待测词项的更新后待测词频。
基于步骤11021a和11022a,本发明文本隐含语义激活方法还包括:
此外,在步骤110中,所述获取待测文本的待测词项信息,还可以包括将动态获得的所述待测文本的待测词项、待测词向量及待测词频添加到所述文本集合知识库中进行扩充,更新所述文本集合知识库的词表、参考词向量及参考词频。
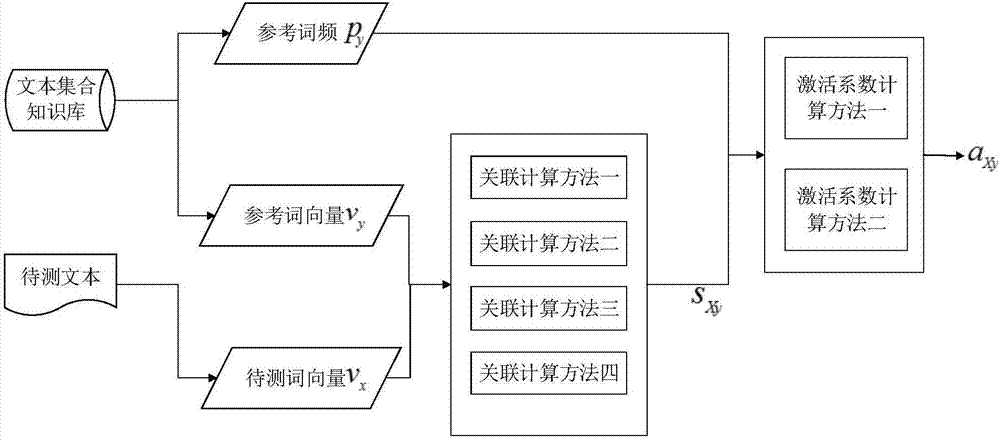
如图2所示,在步骤120中,所述确定所述文本集合知识库的词表中每个参考词项的激活系数,具体包括:
步骤1201:计算所述文本集合知识库的词表中每个参考词项与待测文本的联合关联强度;
步骤1202:根据每个参考词项的词频及其与待测文本的联合关联强度确定各参考词项的激活系数。
在步骤1201中,所述计算所述文本集合知识库的词表中每个参考词项与待测文本的联合关联强度,具体包括以下任意一种:
关联计算方法一:分别计算各参考词项所对应词向量与待测文本中的每个待测词项所对应词向量的相似度,计算各相似度的加权平均值,确定所述联合关联强度;
关联计算方法二:计算待测文本中的各待测词项所对应词向量的加权平均向量,计算所述加权平均向量与各参考词项所对应词向量的相似度,确定所述联合关联强度;
关联计算方法三:将待测文本进行句段划分,计算划分后的各集合中的划分词项所对应词向量的划分加权平均向量,分别计算各划分加权平均向量与各参考词项所对应词向量的相似度,计算各相识度的平均值,确定所述联合关联强度;
关联计算方法四:随机选取待测文本中的多个子片段,计算每个子片段中的片段词项所对应词向量的片段加权平均向量,分别计算各片段加权平均向量与各参考词项所对应词向量的相似度,计算各相似度的平均值,确定所述联合关联强度。
其中,加权平均值的权重可以指词在待测文本中的出现比率,也可以指待测词项的tf(termfrequency,词频)-idf(inversedocumentfrequency,逆文档频率)值。相似度计算可以通过余弦相似度或向量内积实现,也可以通过先计算欧式距离或曼哈顿距离,然后求其倒数等方式实现。
以待测文本“雨一直下”、文本集合知识库中的参考词项“人民”和“金字塔”为例来说明联合关联强度的计算过程。假设从“雨一直下”中提取出的词序列及其对应词向量分别为:
[“雨”:[5.6,9.0,4.1,9.5,4.5];
“气氛”:[7.1,9.9,3.8,2.6,2.1];
“融洽”:[9.0,5.9,7.8,5.3,4.8];
“屋檐”:[8.5,2.5,2.0,3.1,6.6];
“感到”:[1.1,9.5,5.8,1.3,1.1]]
“人民”和“金字塔”的词向量分别为:
“人民”:[5.4,9.4,1.8,6.2,4.2]
“金字塔”:[1.8,9.3,4.0,1.5,0.8]
根据方法一,当相似度采用余弦相似度计算公式时,“人民”与“雨一直下”的联合关联强度sxy为:
“金字塔”与“雨一直下”的联合关联强度为:
在步骤1202中,所述根据每个参考词项与待测文本的联合关联强度确定各参考词项的激活系数,具体包括以下任意一种:
激活系数计算方法一:每个参考词项与待测文本的联合关联强度作为对应各参考词项的激活系数;
激活系数计算方法二:计算各参考词项的参考词频与对应参考词项与待测文本的联合关联强度加权求和,确定各参考词项的激活系数。
根据公式(3)确定激活系数计算方法二中的各参考词项的激活系数:
axy=βpy+(1-β)sxy(3)
其中,py表示参考词项y的参考词频,sxy表示参考词项y与待测文本的联合关联强度。β为比例系数,取值在0到1之间,在使用过程中可以根据实际情况调整。
以当前文本“雨一直下”、知识库中的现有词项“人民”和“金字塔”为例来说明激活系数的计算过程。
“人民”和“金字塔”的词频如下:
“人民”:20
“金字塔”:12
假设待测文本中的词项数为2000,则“人民”的待测词频为0.01,“金字塔”为0.006。由公式(1)和公式(2),“人民”和“金字塔”与“雨一直下”的联合关联强度分别为0.86和0.77。利用方法二计算激活系数,当β等于0.2时,“人民”的激活系数为:
axy=0.2×0.01+0.8×0.86=0.69;
“金字塔”的激活系数为:
axy=0.2×0.006+0.8×0.77=0.62。
步骤130,所述根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合,具体包括:
步骤1301:基于所述待测文本,计算所述隐含语义集合的长度ny;
步骤1302:对各激活系数进行排序,根据排序结果和所述隐含语义集合的长度ny确定隐含语义集合。
在步骤1301中,基于所述待测文本,计算所述隐含语义集合的长度ny,具体包括:
根据以下公式(4)确定所述隐含语义集合的长度ny:
ny=αnx(4);
其中,α表示激活比率,nx表示待测文本中的待测词项。
在步骤1302中,所述根据排序结果和所述隐含语义集合的长度ny确定隐含语义集合,具体包括以下任意一种:
隐含语义集合提取方法一:选取激活系数从大到小排序的前ny个激活系数对应的参考词项构成所述隐含语义集合。所述隐含语义集合,每个词项的权重等于1。
隐含语义集合提取方法二:依次选取激活系数最大的词项添加到所述隐含语义集合中;直到所述隐含语义集合中所有词项对应的激活系数之和大于或等于ny。所述隐含语义集合,每个词项的权重等于其激活系数。
以当前文本“雨一直下”、文本集合知识库中的参考词项“人民”和“金字塔”为例来说明隐含语义集合y的提取过程。
根据激活系数排序,“人民”和“金字塔”的排序结果为:
“人民”:0.69;
“金字塔”:0.62;
当“雨一直下”中的词数量为5,激活比率α=0.2时:根据隐含语义集合提取方法一,提取得到的隐含语义集合为:{“人民”:1};
根据隐含语义集合提取方法二,提取得到的隐含语义集合为:{“人民”:0.69;“金字塔”:0.62}。
本发明对于原始文本集合,训练获得相应的知识库,包括所有参考词项共同构成的词表、训练得到的参考词向量、参考词频等。针对待测文本,在知识库中搜索相应的信息,包括文档中所有词的词向量、词表中的所有词项及其词向量和词频等。利用认知心理学中联合激活的思想,对词表中的每个参考词项,通过参考词向量计算其与待测文本的联合关联强度,同时结合词频信息计算激活系数。这种方式综合考虑了词项本身的信息以及文档与词项的关联信息。之后,对词表中的所有词项根据激活系数由高到低进行排序,并提取激活系数较高的一部分词项构成待测文本的隐含语义集合。最后,将激活的隐含语义集合直接作为隐含语义分析结果,或加入原有文本进行语义扩充,进行后续的文本分析工作,如文本分类、文本检索、主题分析等。由此解决了利用当前文本语料激活文档的隐含语义信息,同时使得隐含语义信息具有可解释性的问题。
此外,本发明还提供一种文本隐含语义激活系统,如图3所示,本发明文本隐含语义激活系统包括:知识库构建单元200、获取单元210、确定单元220、选取单元230及扩充单元240。
其中,所示知识库构建单元200用于对预收集的原始文本集合进行训练,构建文本集合知识库;所述获取单元210用于获取待测文本的待测词项信息;所述确定单元220用于根据文本集合知识库及所述待测文本的待测词项信息,确定所述文本集合知识库的词表中每个参考词项的激活系数;所述文本集合知识库包括多个参考词项共同构成的词表、对应各参考词项的参考词向量及参考词频;所述选取单元230用于根据各激活系数,选取对应的参考词项构成待测文本的隐含语义集合;所述扩充单元240用于将所述隐含语义集合添加到所述待测文本中进行语义扩充。
其中,所述知识库构建单元200包括预处理模块、过滤模块、构建模块、统计模块及训练模块。
所述预处理模用于对原始文本集合进行训练进行预处理,确定包含全部参考词项的原始词项集合;所述过滤模块用于过滤掉所述原始词项集合中的停用词,获得参考词项集合;所述构建模块用于根据所述参考词项集合中的各参考词项,构建词表;所述统计模块用于统计各参考词项出现的次数,确定对应的参考词频;所述训练模块用于通过词向量训练工具对文本集合进行训练,确定各参考词项对应的参考词向量。
所述获取单元310获取待测文本的待测词项信息,具体包括:对所述待测文本进行句段划分和分词,获得所述待测文本的待测词项;基于所述文本集合知识库,确定所述各待测词项的待测词向量及待测词频。
所述确定所述各待测词项的待测词向量及待测词频,具体包括以下任意一种:
根据所述待测词项,对所述文本集合知识库中的各参考词向量进行检索,确定各待测词项对应的待测词向量;根据所述文本集合知识库中各参考词频,确定各待测词项对应的待测词频;
通过词向量训练工具,对所述待测词项进行训练,获得所述待测词项对应的增量式的待测词向量;统计所述待测文本中各待测词项出现的频率,并结合所述文本集合知识库中各参考词频,确定各待测词项的待测词频。
基于增量式的待测词向量和词频,本发明文本隐含语义激活系统还包括更新单元,用于将所述待测文本更新的待测词项、待测词向量及待测词频添加到所述文本集合知识库中进行扩充,更新所述文本集合知识库的词表、参考了词向量及参考词频。
所述确定单元230包括计算子单元,用于计算所述文本集合知识库的词表中每个参考词项与待测文本的联合关联强度;确定子单元,用于根据每个参考词项与待测文本的联合关联强度确定各参考词项的激活系数。
所述计算子单元包括第一计算模块、第二计算模块、第三计算模块及第四计算模块中任意一种:
所述第一计算模块用于分别计算各参考词项所对应词向量与待测文本中的每个待测词项所对应词向量的相似度,计算各相似度的加权平均值,确定所述联合关联强度;
所述第二计算模块用于计算待测文本中的各待测词项所对应词向量的加权平均向量,计算所述加权平均向量与各参考词项所对应词向量的相似度,确定所述联合关联强度;
所述第三计算模块用于将待测文本进行句段划分,计算划分后的各集合中的划分词项所对应词向量的划分加权平均向量,分别计算各划分加权平均向量与各参考词项所对应词向量的相似度,计算各相识度的平均值,确定所述联合关联强度;
所述第四计算模块用于随机选取待测文本中的多个子片段,计算每个子片段中的片段词项所对应词向量的片段加权平均向量,分别计算各片段加权平均向量与各参考词项所对应词向量的相似度,计算各相似度的平均值,确定所述联合关联强度。
所述确定子单元包括第一确定模块或第二确定模块:
所述第一确定模块用于确定每个参考词项与待测文本的联合关联强度作为对应各参考词项的激活系数;
所述第二确定模块用于计算各参考词项的参考词频与对应参考词项与待测文本的联合关联强度加权求和,确定各参考词项的激活系数。
所述选取单元230包括:长度计算模块,用于基于所述待测文本,计算所述隐含语义集合的长度ny;选取模块,用于对各激活系数进行排序,根据排序结果和所述隐含语义集合的长度ny确定隐含语义集合。
所述长度计算模块根据以下公式(4),计算所述隐含语义集合的长度ny,具体包括:
ny=αnx(4);
其中,α表示激活比率,nx表示待测文本中的待测词项。
所述选取模块包括第一抽取子模块或第二抽取子模块,所述第一抽取子模块用于选取从大到小排序的前ny个激活系数对应的参考词项构成所述隐含语义集合。所述第二抽取子模块用于依次选取最大的激活系数及对应的词项添加到所述隐含语义集合中;直到所述隐含语义集合中所有词项对应的激活系数之和大于或等于ny。
相对于现有技术,本发明文本隐含语义激活系统与上述文本隐含语义激活方法的有益效果相同,在此不再赘述。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!