一种多音频数据的处理方法与流程
本发明涉及一种多音频数据的处理方法,属于电子设备技术领域。
背景技术:
音频数据作为一种波形数据在其传统的采集过程中主要存在两个重要的参数:音频和音量。其中,音频往往作为识别声源特征的主要参数,而音量则是表现声音强度的重要特征。
在声音采集与编码的过程中,不同发音源的声波数据会在采集设备上交互重叠,最终产生混合各种音源的单一音频文件,而在之后的处理过程中,相关的处理算法往往要针对特定的频率特征过滤杂波数据后才能查找到所要检索的数据,而在此过程中,识别的难度与准确率往往较低。这是因为,在音频采集和存储的过程中,往往都存在一种多种音源的交叠,而不同音源的数据因为频率不同,很一种多时候都会交叠在一起,如何在这些交叠的频率中过滤出特定的信息是十分困难的事。特别是当其他音源的音量高于检索目标音量时,所检索的目标音量通常都会被背景音量所覆盖,无法检出。
因而,在对批量录音文件的检索过程中,往往需要投入大量的人力成本与时间成本才能找到所要检索的目标,而始终难以找到有效的自动化快速检索方式予以替代。
技术实现要素:
本发明的目的就是为了解决现有技术中存在的上述问题,提供一种多音频数据的处理方法。
本发明的上述目的,其得以实现的技术解决方案:一种多音频数据的处理方法,其特征在于:在单一音频文件中存储一种多音频数据。
优选地,该方法包括以下步骤:
s1:选取音源设备,并为不同的音源设备设置独立的采集通道;
s2:为所采集的音频数据设置音源信息、频率相关数据;
s3:在音频文件头中设置音源数量及不同音源的基本信息;
s4:为每一个音源设置出现次数、频率,以及音源每次出现的位置和持续长度;
s5:保存音源文件头信息,开始编码并写入音频数据流;
s6:在音频文件的编码器所设定频率上写入相关的音源数据,当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3。
优选地,在步骤s3中,不同频率的音频无论是否采集设备相同,都视为不同的音源。
优选地,在步骤s4中,音源次数为该频率音频有效出现的时间段,忽略该频率之外的背景数据。
优选地,在步骤s4中,音源频率为该音源的唯一性标识,以便于创建索引。
优选地,在步骤s6中,当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3。
优选地,在步骤s6中,当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3。
优选地,一种多音频数据的处理方法,在单一音频文件中能够存储一种多音频数据;该方法包括以下步骤:
s1:选取音源设备,并为不同的音源设备设置独立的采集通道;
s2:为所采集的音频数据设置音源信息、频率相关数据;
s3:在音频文件头中设置音源数量及不同音源的基本信息;
s4:为每一个音源设置出现次数、频率,以及音源每次出现的位置和持续长度;
s5:保存音源文件头信息,开始编码并写入音频数据流;
s6:在音频文件的编码器所设定频率上写入相关的音源数据,当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3;在步骤s3中,不同频率的音频无论是否采集设备相同,都视为不同的音源;在步骤s4中,音源次数为该频率音频有效出现的时间段,忽略该频率之外的背景数据;在步骤s4中,音源频率为该音源的唯一性标识,以便于创建索引;当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3;当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3。
本发明技术方案的优点主要体现在:该多音频数据的处理方法是一种在单一音频文件中同时存储多音源数据的方法,通过该方法不但可以任意整合多种音源的音频数据,在同一个音频文件中同时存储多音源、多频率的音频数据,更可以在回放的过程中自由切换音源,任意切换音源数据或混合、抛离任意一个音源,实现实时混声操作,也可以针对不同的音源数据设定音纹特征检索索引,使得音频数据的检索过程更加高效。通过该方法所存储的多音源文件不但比传统的多文件独立存储方式体积更小,也更容易建立音频数据索引,在音频录像、管理等相关的领域中都具有重要的作用,适合在产业上推广使用。
附图说明
图1是本发明中不同音源数据在维度上的空间示意图。
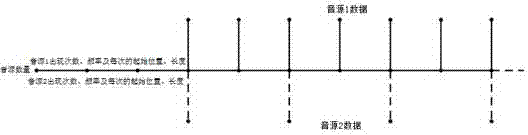
图2是本发明中两组不同音频、不同频率的音频数据在一种多维化数据空间中的数据流表现形式。
具体实施方式
本发明的目的、优点和特点,将通过下面优选实施例的非限制性说明进行图示和解释。这些实施例仅是应用本发明技术方案的典型范例,凡采取等同替换或者等效变换而形成的技术方案,均落在本发明要求保护的范围之内。
本发明揭示了一种多音频数据的处理方法,该处理方法在单一音频文件中存储一种多音频数据。
具体地,该多音频数据的处理方法包括以下步骤:
s1:选取音源设备,并为不同的音源设备设置独立的采集通道;
s2:为所采集的音频数据设置音源信息、频率等相关数据;
s3:在音频文件头中设置音源数量及不同音源的基本信息;
s4:为每一个音源设置出现次数、频率,以及音源每次出现的位置和持续长度等。其中,不同频率的音频无论是否采集设备相同,都视为不同的音源。音源次数即该频率音频有效出现的时间段,忽略该频率之外的背景数据,音源频率为该音源的唯一性标识,以便于创建索引;具体地,在本实施例中,次数、位置和持续长度在具体的采集过程中获取,频率的范围就是正常的频率范围,频率用来区别人声,人声的频率范围为300hz--3400hz。
s5:保存音源文件头信息,开始编码并写入音频数据流;
s6:在音频文件的编码器所设定频率上写入相关的音源数据,当某一个频段上存在多组音源数据时,按照音源顺序依次写入,音源1|音源2|音源3。
在本实施例中,多组音源数据的选取无限制,在工作过程中,根据实际需要的具体情况进行选取。某一个频段指的同一个人的声音,频率是一样的,除非刻意发出高低音,不然的话,同一个人说话声音的频率一般都维持在一个频段上,当然这里的频率不止是音频本身的频率,也包括语速这个概念,也就是说话的快慢。
不同于一般的音频数据存储方式,在同一个时间节点上总是会采集音量最高者为有效数据,而音量较低的音源时常会被淹没其中,又或者只能混杂在不同频率的间隙中变为背景音。该多音频数据的处理方法所提出的音源数据存储方式可以使用多维度的手段自由搭配多音源、多频率的音频数据,不同的音源或相同的音源音频都可以在不同维度上都可以实现分离,在回放时实时混合,具有极大的灵活性。图1为不同音源数据在维度上的空间示意图,如图1所示,x为音频数据流也可理解为时间,y为音频,z为不同音频,依据音频单独采集不同时刻的音量,在y维上分离,分别采集各自的音频数据流和音量。不同频率的音频视为不同音源,不同的音源或相同的音源音频都可以在不同维度上进行分离。
两组不同音源、不同频率的音频数据在多维化的数据空间中以独立的数据流形式存在,当编码为一个独立的音频文件时,其存储方式如图2所示:音频1和音频2的频率、音源不一样,具体地,音频1出现次数、频率及每次的起始位置、长度与音频2出现次数、频率及每次的起始位置、长度不一样。
不同于现存的音频数据存储方法为音频格式文件头+音频数据的组合,如以这种方式存储多音源音频,会使得混合后的音频数据很难分离。多音频数据的处理方法所提出的多维化音频编码与存储方式以音源和频率为基础,在同一条音频数据流中分散存储各个音源、频率的音频信息,因而在创建音频数据索引时具有极高的效率。
通过该方法不但可以在同一个音频文件中同时存储多音源、多频率的音频数据,更可以在回放的过程中自由切换音源,实现实时混声操作,也可以针对不同的音源数据设定音纹特征检索索引,使得音频数据的检索过程更加高效。
本发明尚有一种多种实施方式,凡采用等同变换或者等效变换而形成的所有技术方案,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!