使用无监督机器学习的自动全芯片设计空间采样的制作方法
一般而言,本公开涉及集成电路的制造,更具体地说,本发明涉及用于光刻工艺的光掩模的创建。
背景技术:
集成电路通常包括大量的电路元件,其中具体包括场效应晶体管。可能存在于集成电路中的其它类型的电路元件包括电容器、二极管和电阻器。集成电路中的电路元件可以通过例如借助镶嵌技术在介电材料中形成的导电金属线进行电连接。导电金属线可以设置在多个互连层中,该多个互连层在其中或其上形成有电路元件的衬底上彼此堆叠。不同互连层中的金属线可以通过被金属填充的接触过孔而彼此电连接。
由于现代集成电路的复杂性,在集成电路的设计中,通常采用自动设计技术。
集成电路的设计通常采用多个步骤。这些步骤可以包括限定集成电路的功能的用户规范的创建。用户规范可以是用于寄存器传输级描述的创建的基础,该寄存器传输级描述根据硬件寄存器之间的信号流和在这些信号上执行的逻辑运算来建模集成电路的模型。然后可以将集成电路的寄存器传输级描述用于集成电路的物理设计,其中集成电路的布局被创建。由此创建的布局可以是形成光掩模的基础,该光掩模可用于通过光刻工艺在集成电路的制造中图案化材料。
在光刻工艺中,将光掩模图案投射到设置在半导体结构上的光致抗蚀剂层上。光致抗蚀剂的部分被用于将光掩模图案投射到光致抗蚀剂上的辐射照射。不照射光致抗蚀剂的其它部分,其中光致抗蚀剂被照射的部分和光致抗蚀剂的未被照射的部分的图案取决于设置在光掩模上的印刷特征的图案。
之后,可以对光致抗蚀剂进行显影。取决于使用负性光致抗蚀剂还是正性光致抗蚀剂,在显影过程中,将光致抗蚀剂的未被照射的部分或被照射的部分溶解在显影剂中,从而将其从半导体结构中去除。
之后,可以使用保留在半导体结构上的光致抗蚀剂的部分作为光致抗蚀剂蚀刻掩模来执行用于图案化半导体结构的工艺,其具体地可以包括一个或多个蚀刻工艺。由此,可以在半导体结构上形成根据所创建的集成电路布局的特征。
在半导体结构中形成小的特征时,可以采用分辨率增强技术。这些可以包括光学邻近校正(opc)、离轴照明(oai)、亚分辨率辅助特征(sraf)或相移掩模(psm)。然而,这些技术不能完全消除光刻热点,例如捏挤(pinching)(即,违反最小宽度条件)或桥接(违反最小距离条件)。已经表明,这样的热点可能依赖于图案。
尽管存在这些问题,但是一般地对于制造工艺的开发和维护,具体地对于opc组件和方法,对可能的设计选项的充分的设计采样和理解是基本的。以下列表给出了一些绝对需要充分设计空间采样的领域:(1)用于过程变更验证和监测的位置选择;(2)用于光刻照明优化的位置选择;(3)用于模型构建和验证的位置选择;(4)用于sraf和opc配方优化的位置选择;以及(5)发现与其它项非常不同的设计点,即,发现异常。
用于分辨率增强技术(ret)和/或opc开发或制造过程监测的公知的位置选择策略可能依赖于:
(i)人工分析设计。然而,这种方法可能不全面,太泛泛,并且远离当今制造工艺的需要的现实。
(ii)设计规则检查(drc)和/或光学规则检查(orc)的结果。然而,这种方法很难适用于采样。这种方法通常只解决最坏情况方案。它通常与模型精度进行卷积。此外,需要许多所使用的基础模型的现有知识,以及针对drc的假设等。
(iii)个别设计工程师在设计空间方面的经验。然而,这种方法似乎很难重复。引入系统错误的风险相当高。此外,可能不确定是否可以找到最佳选择。
(iv)图像参数空间分析。这种方法通常仅涵盖光学,它需要诸如模型、位置等的输入,其必须在使用某种其它方法被预先选择之后进入分析。
(v)最后,也可以考虑在硬件中发现的故障。然而,这通常来得过迟,并且可能是不可接受的昂贵。
(vi)诸如支持向量机(svm)、神经网络、回归模型、主成分分析等的算法。这些方法通常需要对弱点/热点的先验知识来训练这些算法,另外这些方法通常不适用于大数据库。例如,关于使用这些算法,通常很难(如果不是不可能)对具有109甚至更多图案的大的布局分类。
事实上,以下估计表明这个限制可能会更低。通常,计算复杂度约为:o(n2)-o(n3)。然而,图案布局的数量通常会作为n2增长。因此,在一个点上的大于105的数据集几乎不可行。
鉴于上述问题,本公开提供了一种替代方法。本公开披露了可应用于半导体制造中的采样全芯片物理设计布局的方法。
技术实现要素:
以下给出本发明的简化摘要,以提供对本发明的某些方面的基本理解。此摘要并非本发明的详尽概述。它并非旨在识别本发明的关键或核心要素或描绘本发明的范围。其唯一目的是要以简化的形式呈现一些概念,作为稍后讨论的更详细描述的序言。
此处公开的示例性方法包括以下方法,该方法包括:(i)读取作为要分析的当前布局的布局;(ii)将所述当前布局分割为n个子布局,其中n是大于或等于1的正整数,以使每个子布局适合预定存储器;(iii)对所述子布局中的每一者执行聚类步骤,包括:(a)扫描各个子布局的特征并将每个子布局转换为定义各个图案的特征向量组;(b)搜索每组特征向量的具有预定聚类参数的聚类;以及(c)从每个聚类中选择图案的m个特征表示,其中m是大于或等于1的正整数;(iv)将所述n个子布局中的每一者的所述特征表示合并成新的单个布局;(v)如果步骤(iv)中的所述新的单个布局不适合所述预定存储器,则将所述新的单个布局分配为所述当前布局并继续步骤(ii);(vi)搜索为各个子布局发现的所述特征表示的具有预定聚类参数的聚类;(vii)从每个聚类中选择图案的m个特征表示,其中m是大于或等于1的正整数;以及(viii)输出所述图案的特征表示。
此外,公开了一种在包括多个机器的计算机系统上运行的计算机实现的方法。在一个示例性实施例中,所述计算机实现的方法可以包括:(i)读取来自外部存储存储器的作为要分析的当前布局的布局;(ii)将所述当前布局分割为n个子布局,其中n是大于或等于1的正整数,以使每个子布局适合单个机器的预定存储器;(iii)对所述子布局中的每一者执行聚类步骤,包括:(a)扫描各个子布局的特征并将每个子布局转换成定义各个图案的特征向量组;(b)搜索每组特征向量的具有预定聚类参数的聚类;以及(c)从每个聚类中选择图案的m个特征表示,其中m是大于或等于1的正整数;(iv)将所述n个子布局中的每一者的所述特征表示合并成新的单个布局;(v)如果步骤(iv)中的新的单个布局不适合所述单个机器的所述预定存储器,则将所述新的单个布局分配为所述当前布局并继续步骤(ii);(vi)搜索为各个子布局发现的所述特征表示的具有预定聚类参数的聚类;(vii)从每个聚类中选择图案的m个特征表示,其中m是大于或等于1的正整数;以及(viii)将所述图案的特征表示输出到布局文件。
所公开的方法还可以包括无监督机器学习(uml)方法。因此,可以在具有很少甚至没有先验知识的情况下分析要被探索和被发现的数据集。这些方法能够分析整个芯片的布局。此外,这些方法可以应用于任何层。
附图说明
通过结合附图参考以下描述,可以理解本公开,其中相同的参考标号表示相同的元件,并且其中:
图1示意性地示例出将布局分割为多个子布局;
图2象征性地示出包括布局数据的分割、聚类、合并的迭代序列;
图3示意性地示出使用一个例子提取特征;
图4示意性地示出聚类的表示的例子;
图5示意性地示出聚类的计算;
图6示出方法的步骤流程;以及
图7a-7c示意性地示出结果的库和位置列表。
尽管本文公开的主题允许各种变型和替代的形式,但是其具体实施例已通过附图中的例子的方式而示出,并且在此被详细描述。然而,应当理解,这里对具体实施例的描述并非旨在将本发明限制于所公开的特定形式,相反,其目的在于涵盖落入由所附权利要求限定的本发明的精神和范围内的所有变型、等同物和替代物。
具体实施方式
下面描述本发明的各种示例性实施例。为了清楚起见,在本说明书中未描述实际实施的全部特征。当然,将理解,在任何这样的实际实施例的开发中,必须进行大量的实施特定的决定以实现开发者的特定目标,例如遵循系统相关和业务相关的限制,这些限制将从一个实施到另一个实施而变化。此外,将理解,这样的开发努力可能是复杂且耗时的,但是对于受益于本公开的本领域的普通技术人员来说,这将仍是常规的任务。
现在将参考附图描述本公开。为了说明的目的,仅在附图中示意性地描绘出各种结构、系统和装置,以便不使本领域的技术人员公知的细节混淆本发明。然而,包括附图是为了描述和解释本公开的示例性的例子。本文使用的词和短语应被理解和解释为具有与相关领域的技术人员对这些词和短语的理解一致的含义。没有特定的术语或短语的定义(即,不同于本领域的技术人员所理解的普通或常用意义的定义)旨在通过本文中的术语或短语的一致使用来暗示。就术语或短语旨在具有特殊含义(即,本领域的技术人员所理解的含义以外的含义)而言,这种特殊定义应该以为术语或短语直接且明确地提供特殊定义的定义性方式在说明书中明确地阐述。
图1示例出要分析的布局1。要分析的布局1可以是设计、芯片的布局和/或可以包括这种布局的层。布局1可以从诸如硬盘、光盘等的存储介质(未示出)读取。布局1可以以表格状/元组(tuple)状或矩阵的表示形式给出。元组或矩阵可以是多维的。图1示意性地示例出将布局分割为多个子布局。如箭头所指示,图1进一步示例出将单个布局1分割为多个子布局3。子布局3也可以被称为分块(tile)。仅为了示例性目的,图1示例出将单个布局1分割为n个子布局3.1、3.2、3.3和3.4,其中n=4。然而,应当理解,n可以是大于1的整数,具体而言,子布局/分块的数量可以小于或大于4。随后,分别在相同的基础上分析或处理n个子布局。为了简单起见,应当理解,n个子布局中的每一者,例如图1中的子布局3.1、3.2、3.3、3.4可以具有相同的大小。还应当理解这不是严格的要求,可以具有与其它子布局大小不同的子布局组。然而,这可能还需要单个布局1的某些区域被如何稀疏地填充的某种先验知识。
图1提出了在分割步骤中可能需要多少子布局的问题。这里,需要读取要分析的原始单个布局。这可以在计算系统上完成。计算系统可以是多节点或多机器计算系统。原始单个布局的大小可以从存储介质、硬盘、光盘、云等获知,或者可以在读取时即时(onthefly)确定。例如,单个布局的大小可以是几千兆字节到数十千兆字节。例如,计算系统将知道单个机器/节点的可用存储的大小。通常,单个机器/节点的可用存储小于机器的物理存储,因为单个机器需要一些存储用于其它任务。可用存储的典型大小可以是2千兆字节或4千兆字节的存储,但其它大小的值也是可能的。由此,计算系统能够估计子布局中的一者(即,单个布局1可被分割的分块中的一者)的大小。
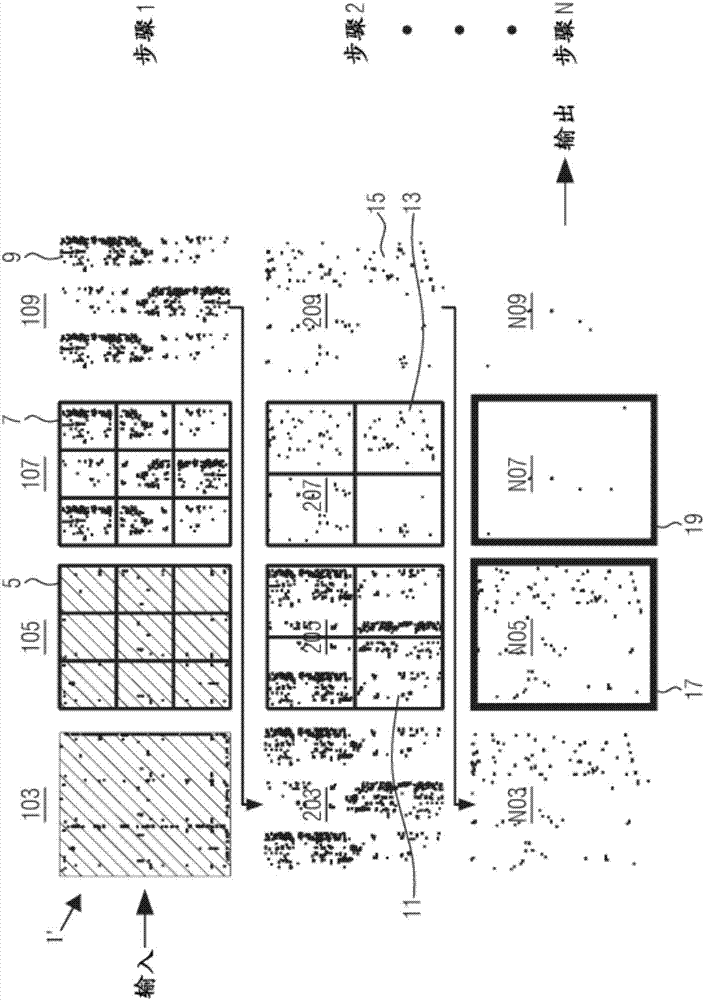
图2象征性地示出用于分析单个布局1'的迭代序列。单个布局1'可以类似于图1中的布局1。图2象征性地表示从输入源“in”读取单个布局。图2然后示意性地示出了从左到右水平描绘的四个步骤,被称为i03、i05、i07、i09,其中i=1、2、...n,以及示出了从顶部到底部示出的步骤i,i=1、2、...、n。仅为了示例性目的,只示出了i=1、i=2和i=n的步骤。以下说明水平方向上的步骤。在步骤103中,布局1'被示出为从输入源“in”读取。例如,输入源可以是数据库、存储介质、云等。步骤105指示将初始单个布局分割为由5表示的多个子布局。这里,仅为了示例性目的,示出了九个子布局/分块。如图1所示,子布局5可以具有或可以不具有相同的大小。步骤107指示在九个子布局5的每个子布局内执行聚类。将参考图3-6进一步讨论聚类的细节。这里为了示例的目的,聚类107象征性地且可视地表示同样存在于步骤105的子布局5中的单个布局1'的非常精细的结构化数据现在将通过识别由7表示的聚类和图案而变得更加稀疏。这里,聚类和图案7由每个聚类的某些表示表示,以便不需要保留聚类的整个数据。这样,来源于单个布局1'的数据量现在被减少。步骤109示例出合并来自子布局/分块7的表示,以便再次获得新的单个布局9,该新的单个布局9现在比原始布局1'稀疏。
图2进一步示例出步骤109的新的单个布局9被转移到图2的第二行,即,在向下垂直方向上的步骤2。由此,步骤203示例出与步骤109相同的新的单个布局9。根据顺序步骤或以递归的方式,步骤205指示将新的单个布局9分割为由11表示的多个子布局。仅为了示例性目的,示例出四个子布局11,但是应当理解,可以选择不同数量的子布局11。与步骤107类似,步骤207指示在步骤205的每个子布局/分块11(现在由13表示)中执行的聚类。最终,步骤209示例出合并来自子布局/分块13的表示,以便再次获得第二行步骤(即步骤2)的新的单个布局15。
如图2所示,对于第n行,继续进行迭代,其中为了示例和简单起见,新的单个布局15被复制到步骤n03,或者换言之,n=3。这里,步骤n05表示分割为仅一个子布局17。步骤n07表示子布局17的聚类,以便成为由19表示的子布局17的聚类和图案。最后,合并步骤n09提供迭代结果,该结果然后可以被输出到由“out”表示的输出装置,该输出装置可以是数据库、存储介质、云等。
如已关于图1所示,执行迭代或递归的另一步骤的标准是判定步骤109、209...n09中的合并结果是否适合单个机器/节点的存储器。然后,在输出结果之前执行最终的聚类步骤。将参考图3-6讨论聚类的细节。
图3示意性地示出从子布局/分块的数据中提取特征。这里,使用一个例子,子布局31的至少一部分的数据的细节由32表示。具有可被解释为圆31的半径的长度/范数r的特征向量v在图3中示例出。换言之,图3示例出被认为要通过此处描述的各种方法分析的结构元素的物理布局图案的例子/类型。为了执行这种分析,这些图案应该被转换成被称为特征向量的向量形式。一个特征向量描述一个图案。特征向量可以以不同的方式构建。例子的非穷举性列表包括:(i)尺寸/表面积在半径r内的所有多边形与图案中心的距离的列表,(ii)尺寸/表面积在半径r内的所有多边形的坐标的列表,(iii)多边形的边的列表,或(iv)最一般情况下所有顶点的坐标列表。可能存在特征向量v的其它构造。作为示例,对于过孔类层,图3的子布局31将四个多边形(例如,正方形)的坐标表示为(a0,0,0)、(a1,x1,y1)、(a2,x2,y2)、(a3,x3,y3)。然后,可以如下给出特征向量v:
v=(a0,a1,x1,y1,a2,x2,y2,a3,x3,y3)或
v=(a0,a1,d1,a2,d2,a3,d3),其中dn2=xn2+yn2,其中n=1、2、3。
在33中,由于32的表示的聚类和选择,示例出较大的结构34,并且还示出长度为r'的矢量v'。在迭代工艺中更进一步地,35示例出在向量v”的半径r”内的更大的聚类和图案36。由此,通过查找聚类并选择聚类的一个或多个表示,可以呈现较大的结构。
图4示意性地示出聚类的表示的例子。这里,仅为了示例性目的,示例出三个聚类41、43、45。三个聚类可能彼此不同。如箭头所示,在右手侧,分别确定每个聚类的表示41r、43r和45r。这些表示可能与相应聚类的重心相吻合。改变(即,移位)各个表示的位置/坐标可以支持找到表示的最佳位置。而在这种情况下,每个聚类具有一个表示,可能需要对每个聚类选择一个以上的表示。
图5示意性地示出根据例子的聚类的计算。图5示例出由53、55和57表示的三个聚类。聚类53包括元素/数据q1...qn,其中n是正整数。类似地,聚类55包括元素c1...cn,聚类57包括元素t1...tn。应当理解,聚类53、55和57中的每个聚类可以具有不同数量的元素。图5示例出关于聚类53的qn个元素中的一个元素qi,计算元素qi到聚类53的每个其它元素的距离以及还计算元素qi到其它聚类55和57中的每个元素的距离。将结果存储在存储器中。对所有聚类的所有元素重复此过程。这表明在计算上相当昂贵。然而,有益的是,一旦计算出距离,它们可以作为用于选择特征向量和表示的指标(参见图3和图4)。
图6示出在此公开的示例性方法的一个示例性实施例的步骤流程。关于图1-5的讨论,此方法可以在计算机系统上实现。这也可以与图2的象征性的示例进行比较。
该方法的开始由s801表示。在步骤s803中,读取预定的布局以使其变为要分析的布局。该布局可以从数据库、存储介质、云等读取。该布局也可以由特定的第三方布局设计者提供。在步骤s805中,将布局分割为多个子布局或分块(参见图1和图2)。例如,布局可以被分割为n个子布局/分块,其中n是大于1的正整数。该步骤可以包括在读取初始布局期间确定布局的大小并估计或预先确定单个机器/节点的有效可用的存储。通常,机器的数量将至少与子布局的数量一样大。
步骤s805之后是所谓的数据挖掘步骤s807。在此步骤中,每个子布局被单独处理。应当理解,为了速度起见,n个机器可以基本上并行地运行。数据挖掘应该被理解为搜索和提取特征。布局的数据被扫描并转换成特征向量组(图4和图5)。特征向量例如可以由x=(x1,x2...x1)表示,其中l是正整数,x1...x1是特征向量的元素或坐标。例如,这些坐标可以是距离、角度、半径、各个图案子组件的面积、覆盖(overlay)、包围(enclosure)或任何其它度量。特征向量可以具有20-30个坐标,即,l=20-30,但是其它值也是可以的。作为示例,对于布局的过孔类层,所提取的图案可以以过孔为中心,并且可以使用以下格式的特征向量:x=(a0,{a1,d1},{a2,d2}...{an,dn}),其中a0表示过孔/接触本身的面积,并且{ax,dx}对是相邻过孔的/到相邻过孔的面积和距离,按升序排列。
在将布局的数据转换为特征向量之后,在步骤s809中执行聚类。数据聚类是无监督机器学习问题的类型之一。它的目标是发现数据内的数据结构。在特征向量:x=(x1,x2...x1)的空间中/上操作聚类。它可以用于将各个特征向量分配给聚类。因此,可以通过选择每个聚类的特征表示来对每个分块的设计空间进行采样(图4和图5)。聚类可能在计算量和存储上是非常昂贵的,因为它通常计算并存储数据集中的所有对象之间的不相似性。
如图6所示,聚类之后是步骤s811,该步骤指示选择某一数字m,其中m是来自步骤s809的所发现的每个聚类的表示的正整数。如图4所示,每个聚类存在至少一个表示。每个聚类也可能有一个以上的表示。
步骤s813包括将在步骤s811中发现和分配的表示合并成一个单个布局。可以理解,该单个布局不同于步骤s803的初始布局。步骤s813中的布局较稀疏或较粗糙。
步骤s815检查步骤s813的单个布局是否适合计算机系统的单个机器/节点,这意味着它应该适合机器的有效可用的存储器。如果不适合,则该工艺开始另一次迭代,并且使用步骤s813的单个布局作为步骤s805的新输入布局。然后,再次将该新的输入布局分割为多个子布局。
如果步骤s815的检查是肯定的,则该方法继续步骤s817。再一次运行关于表示的聚类。此外,选择m个表示,其中m是正整数。这些表示表示所发现的聚类或图案(步骤s819)。
最后,在步骤s8212中,将被发现并由它们的表示指示的图案输出到布局文件和/或位置列表。该方法在步骤s823结束。
图7a-7c示意性地示出在步骤s823中输出的结果的库和位置列表。在表格类图示中,图7a示例出给出位置的邻居数目n的轴,以及指示实例化的各个图案的频率的轴y。图案由“位置_n_y”表示,其中n和y是相应的坐标。由此,在该示例中,位置“位置_1_1”、“位置_2_1”...“位置_7_1”是最少被实例化的图案,另外在该示例中,“位置_3_10”最常被实例化。图7b以全芯片的角度示例出要分析的布局的图案位置。图7c将结果输出为文本格式的位置列表。由此,可以直接读取图案和最终有问题的区域。
上述方法已成功应用于图案化工艺筛选的22nm设计空间采样。该方法用以确认工艺具有足够的余量。它也已经成功应用于22nm设计空间采样以用于抗蚀基准以及比较各种模型性能,从而发现具有不足的余量后蚀刻步骤的位置。
此方法可以用于从输入设计中选择表示设计位置,并且将所述图案特征表示的输出用于确定工艺变化、监视光学邻近校正性能监视以及控制光学邻近校正开发中的至少一者。
上述方法可以通过使用任何适当的编程环境(例如,
上面公开的特定实施例仅是示例性的,因为本发明可以通过对于获益于此处的教导的本领域的技术人员显而易见的不同但等效的方式进行变型和实践。例如,上面提出的工艺步骤可以以不同的顺序执行。此外,除了以下权利要求中所述以外,本文所示的结构或设计的细节不受任何限制。因此,显而易见的是,上述公开的特定实施例可以被改变或变型,并且所有这些变化都被认为在本发明的范围和精神内。需要指出,本说明书和所附权利要求中使用诸如“第一”、“第二”、“第三”或“第四”的术语来描述各种工艺或结构只是用作对这些步骤/结构的简略参考,并不一定暗示以该有序的顺序执行/形成这样的步骤/结构。当然,取决于准确的权利要求语言,可能需要也可能不需要这些工艺的有序的顺序。因此,本文寻求的保护在下面的权利要求中提出。
- 还没有人留言评论。精彩留言会获得点赞!