原译文对齐的方法及装置与流程
本发明涉及翻译
技术领域:
,特别涉及原译文对齐的方法及装置。
背景技术:
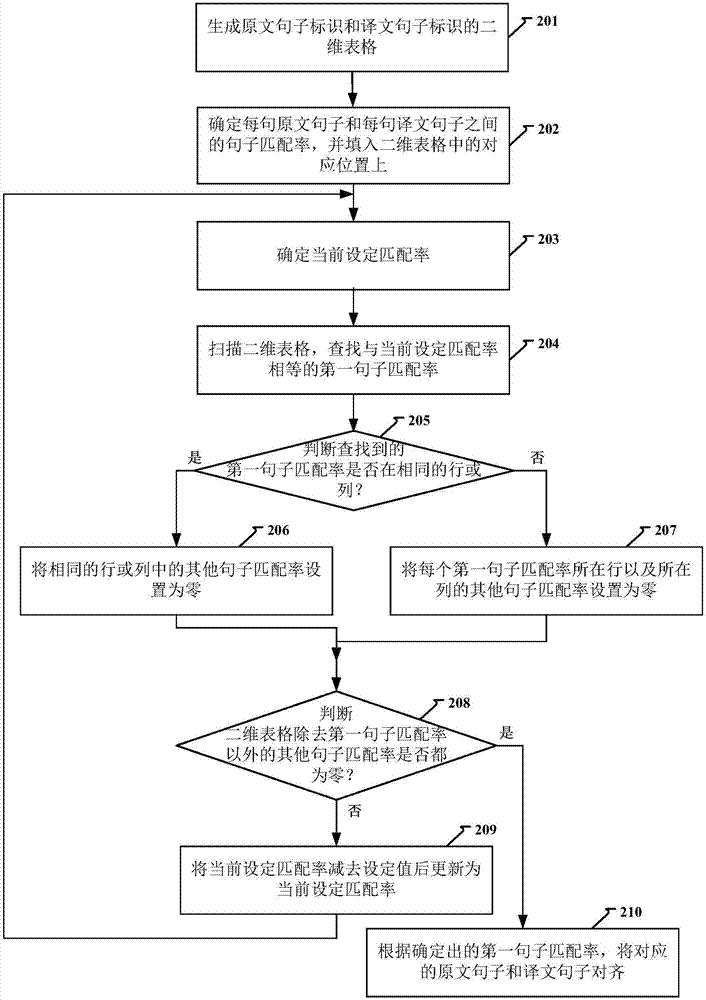
:当前计算机辅助翻译是提高翻译一致性和效率的重要手段,它能够帮助翻译者优质、高效、轻松地完成翻译,使得繁重的手工翻译流程自动化,并大幅度提高了翻译效率和翻译质量。通过计算机辅助翻译对原文文件进行翻译,形成译文文件后,翻译人员可能需要获取译文文件中与原文文件中设定原文句子对应的译文句子,或者,需要获取原文文件中与设定译文句子对应的原文句子,即需要原文句子和译文句子对齐,从而,可进行后续的校对、编辑等。而目前,可通过翻译人员通过将原文文件和译文文件进行对照查看,进行原文和译文的对齐,效率比较低下。技术实现要素:本发明实施例提供了一种原译文对齐的方法及装置。为了对披露的实施例的一些方面有一个基本的理解,下面给出了简单的概括。该概括部分不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围。其唯一目的是用简单的形式呈现一些概念,以此作为后面的详细说明的序言。根据本发明实施例的第一方面,提供了一种原译文对齐的方法,包括:生成原文句子标识和译文句子标识的二维表格;确定每句原文句子和每句译文句子之间的句子匹配率,并填入所述二维表格中的对应位置上;根据至少一个设定匹配率,对所述二维表格进行逐次扫描,在所述二维表格的每一行以及每一列中,最多确定一个与所述设定匹配率匹配的第一句子匹配率;根据确定出的所述第一句子匹配率,将对应的原文句子和译文句子对齐。本发明一实施例中,所述确定每句原文句子和每句译文句子之间的句子匹配率包括:确定当前原文句子和当前译文句子之间的长度匹配率;确定当前原文句子和当前译文句子之间的提取元素匹配率,其中,所述提取元素匹配率包括:标点匹配率、非译元素匹配率、以及单词匹配率中的至少一个;根据所述长度匹配率以及所述匹配率,确定所述当前原文句子和所述当前译文句子之间的句子匹配率。本发明一实施例中,所述在所述二维表格中每一行以及每一列中,最多确定一个与所述设定匹配率匹配的第一句子匹配率包括:扫描所述二维表格,查找与当前设定匹配率相等的第一句子匹配率;将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零;将所述当前设定匹配率减去设定值后更新为所述当前设定匹配率;根据所述当前设定匹配率,对所述二维表格继续进行扫描,直至所述二维表格除去所述第一句子匹配率以外的其他句子匹配率都为零。本发明一实施例中,所述将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零包括:当查找到的所述第一句子匹配率不在相同的行和列时,将每个第一句子匹配率所在行以及所在列的其他句子匹配率设置为零;当所述第一句子匹配率在相同的行或列时,将所述相同的行或列中的其他句子匹配率设置为零。本发明一实施例中,所述根据确定出的所述第一句子匹配率,将对应的原文句子和译文句子对齐包括:将大于第一设定匹配率的所述第一句子匹配率确定为待对齐句子匹配率;确定所述待对齐句子匹配率所在位置对应的待对齐原文句子标识和待对齐译文句子标识;根据所述待对齐原文句子标识和所述待对齐译文句子标识,将对应的原文句子和译文句子对齐。根据本发明实施例的第二方面,提供一种原译文对齐的装置,包括:生成单元,用于生成原文句子标识和译文句子标识的二维表格;匹配率填入单元,用于确定每句原文句子和每句译文句子之间的句子匹配率,并填入所述二维表格中的对应位置上;扫描确定单元,用于根据至少一个设定匹配率,对所述二维表格进行逐次扫描,在所述二维表格的每一行以及每一列中,最多确定一个与所述设定匹配率匹配的第一句子匹配率;对齐单元,用于根据确定出的所述第一句子匹配率,将对应的原文句子和译文句子对齐。本发明一实施例中,所述匹配率填入单元,具体用于确定当前原文句子和当前译文句子之间的长度匹配率,确定当前原文句子和当前译文句子之间的提取元素匹配率,其中,所述提取元素匹配率包括:标点匹配率、非译元素匹配率、以及单词匹配率中的至少一个,根据所述长度匹配率以及所述匹配率,确定所述当前原文句子和所述当前译文句子之间的句子匹配率。本发明一实施例中,所述扫描确定单元,具体用于扫描所述二维表格,查找与当前设定匹配率相等的第一句子匹配率,将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零,将所述当前设定匹配率减去设定值后更新为所述当前设定匹配率,根据所述当前设定匹配率,对所述二维表格继续进行扫描,直至所述二维表格除去所述第一句子匹配率以外的其他句子匹配率都为零。本发明一实施例中,所述扫描确定单元,还用于当查找到的所述第一句子匹配率不在相同的行和列时,将每个第一句子匹配率所在行以及所在列的其他句子匹配率设置为零;当所述第一句子匹配率在相同的行或列时,将所述相同的行或列中的其他句子匹配率设置为零。本发明一实施例中,所述对齐单元,具体用于将大于第一设定匹配率的所述第一句子匹配率确定为待对齐句子匹配率;确定所述待对齐句子匹配率所在位置对应的待对齐原文句子标识和待对齐译文句子标识;根据所述待对齐原文句子标识和所述待对齐译文句子标识,将对应的原文句子和译文句子对齐。本发明实施例提供的技术方案可以包括以下有益效果:本发明实施例中,可根据待对齐的原译文件中每句原文句子和每句译文句子之间的句子匹配率,将原译文件中的原文句子和译文句子对齐,这样,实现了原译文对齐自动化,提高了原译文对齐的效率。另外,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。附图说明此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。图1是根据一示例性实施例示出的一种原译文对齐方法的流程图;图2是根据一示例性实施例示出的一种原译文对齐方法的流程图;图3是根据一示例性实施例示出的一种二维表格的第一示意图;图4是根据一示例性实施例示出的一种二维表格的第二示意图;图5是根据一示例性实施例示出的一种二维表格的第三示意图;图6是根据一示例性实施例示出的一种原译文件对齐装置的框图。具体实施方式以下描述和附图充分地示出本发明的具体实施方案,以使本领域的技术人员能够实践它们。实施例仅代表可能的变化。除非明确要求,否则单独的部件和功能是可选的,并且操作的顺序可以变化。一些实施方案的部分和特征可以被包括在或替换其他实施方案的部分和特征。本发明的实施方案的范围包括权利要求书的整个范围,以及权利要求书的所有可获得的等同物。在本文中,各实施方案可以被单独地或总地用术语“发明”来表示,这仅仅是为了方便,并且如果事实上公开了超过一个的发明,不是要自动地限制该应用的范围为任何单个发明或发明构思。本文中,诸如第一和第二等之类的关系术语仅仅用于将一个实体或者操作与另一个实体或操作区分开来,而不要求或者暗示这些实体或操作之间存在任何实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素。本文中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的结构、产品等而言,由于其与实施例公开的部分相对应,所以描述的比较简单,相关之处参见方法部分说明即可。计算机辅助翻译是一种越来越普遍使用的软件应用,通过该应用可以帮助翻译者优质、高效、轻松地完成翻译。一般借助翻译应用,形成原文文件以及对应的译文文件。在进行校验、编辑等后续操作时,都需快速准确地对齐出与设定原文或译文内容对应的译文或原文。而本发明实施例中,可根据待对齐的原译文件中每句原文句子和每句译文句子之间的句子匹配率,将原译文件中的原文句子和译文句子对齐,这样,实现了原译文对齐自动化,提高了原译文对齐的效率。另外,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。图1是根据一示例性实施例示出的一种原译文对齐方法的流程图。如图1所示,原译文对齐的过程包括:步骤101:生成原文句子标识和译文句子标识的二维表格。待对齐的原文可包括一个,两个或多个句子,对应的,待对齐的译文也可包括一个,两个或多个句子。并且,每个句子都可有对应的标号,该标号在待对齐的原文或译文中都是唯一的。例如:待对齐的原文s包括5个句子,对应的标号可为s1,s2,s3,s4,s5。待对齐的译文t也包括5个句子,对应的标号可为t1,t2,t,t4,t5。其中,可根据原文s中句子的先后顺序将其对应的句子进行标识,或者,随机将原文中的句子进行标识。同样,可根据译文t中句子的先后顺序将其对应的句子进行标识,或者,随机将译文中的句子进行标识。并且,原文中包括的句子数量可与译文中包括的句子数量一样多或者不一样多。待对齐的原文和译文中每个句子都有对应的标识后,可生成对应的原文句子标识和译文句子标识的二维表格。例如:若原文中包括5个句子,且译文中包括5句子,则生成的二位表格如表1所示。s1s2s3s4s5t1t2t3t4t5表1步骤102:确定每句原文句子和每句译文句子之间的句子匹配率,并填入二维表格中的对应位置上。生成了二位表格后,即确定了每句原文句子和每句译文句子的一一对应关系后,可确定每句原文句子和每句译文句子之间的句子匹配率。可由多种方式确定原文句子和译文句子之间的句子匹配率。例如:确定当前原文句子和当前译文句子之间的长度匹配率,然后,将长度匹配率确定为句子匹配率。或者,确定当前原文句子和当前译文句子之间的提取元素匹配率,然后,将提取元素匹配率确定为句子匹配率,其中,提取元素匹配率包括:标点匹配率、非译元素匹配率、以及单词匹配率中的至少一个。或者,确定当前原文句子和当前译文句子之间的长度匹配率;确定当前原文句子和当前译文句子之间的提取元素匹配率;最后,根据长度匹配率以及匹配率,确定当前原文句子和当前译文句子之间的句子匹配率。例如:ml为原文句子和译文句子之间的长度匹配率,mt为提取元素匹配率。那么,句子匹配率可为ml或mt,或者,为mt*ml。其中,提取元素匹配率包括:标点匹配率、非译元素匹配率、以及单词匹配率中的至少一个,因此,mp为标点匹配率,mf为非译元素匹配率,而mw为单词匹配率,这样,可确定mp、mf、mw中的一个、两个或三个,然后确定mt。例如:确定了mp,则mt=mp。或者,确定了mp、mf,则mt=(mp+mf)/2。或者,确定了mp、mf、mw,则mt=(mp+mf+mw)/3。根据上述过程,可依次确定每句原文句子和每句译文句子之间的句子匹配率,并填入二维表格中的对应位置上。例如:确定s1与t1之间的句子匹配率为90%,则可将90填入二维表格中的对应位置上。将句子匹配率填入二位表格中后,二位表格中每个格中都有对应的句子匹配率。步骤103:根据至少一个设定匹配率,对二维表格进行逐次扫描,在二维表格的每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率。句子匹配率可是一个百分数,一般,原文句子和译文句子之间最大的句子匹配率可为100%,本实施例中,可确定句子匹配率为百分数之前的数字。从而,二维表格中的最大数可为100。当然,为减少扫描的次数,可将二维表格中的数设置为整数。即填入的句子匹配率若有小数,可转换为对应的整数,例如,四舍五入。确定二维表格中的最大数为100后,可从100开始依次递减,对二维表格进行逐次扫描,在二维表格的每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率。或者,从二维表格中的最大数,例如95开始依次递减,对二维表格进行逐次扫描,在二维表格的每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率。具体可包括:扫描二维表格,查找与当前设定匹配率相等的第一句子匹配率;将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零;将当前设定匹配率减去设定值后更新为当前设定匹配率;根据当前设定匹配率,对二维表格继续进行扫描,直至二维表格除去第一句子匹配率以外的其他句子匹配率都为零。其中,将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零包括:当查找到的第一句子匹配率不在相同的行和列时,将每个第一句子匹配率所在行以及所在列的其他句子匹配率设置为零;当第一句子匹配率在相同的行或列时,将相同的行或列中的其他句子匹配率设置为零。例如:二维表格中最大数为97,则当前设定匹配率为97,从而,在二维表格中查找与97相等的第一句子匹配率。若与97相等的第一句子匹配率只有一个,则可确定查找到的第一句子匹配率不在相同的行和列,则可将查找到的第一句子匹配率所在行以及所在列的其他句子匹配率设置为零。然后,将96更新为当前设定匹配率,在二维表格中查找与96相等的第一句子匹配率。若与96相等的第一句子匹配率有两个,且两个第一句子匹配率不在相同的行和列,则可将查找到的第一句子匹配率所在行以及所在列的其他句子匹配率设置为零。然后,将95更新为当前设定匹配率,在二维表格中查找与95相等的第一句子匹配率。若与95相等的第一句子匹配率有两个,且两个第一句子匹配率在相同的行,则将该行中其他的句子匹配率设置为零。然后,将94更新为当前设定匹配率,继续在二维表格中查找与94相等的第一句子匹配率,直至二维表格除去第一句子匹配率以外的其他句子匹配率都为零。这样,二维表格中每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率。这样,一个原文句子仅与一个译文句子之间的句子匹配率还存在。当然,句子匹配率也不仅仅限于整数,也可以有小数,例如:98.5。即可以0.5为递减差距,或者,以0.1为递减差距。具体就一一例举了。可见,设定匹配率的个数,以及配置的规律可根据应用场景不同进行不同的设定。例如:原文包括一个或两个句子,译文包括一个或两个句子时,可能只需设定一个设定匹配率。若文包括两个或多个句子,译文包括两个或多个句子时,可能需要设定两个或多个设定匹配率,设定匹配率之间可以按设定差距进行递减,例如上述的递减差距1、0.1、0.5等等。或者,根据二维表格中的句子匹配率的大小顺序直接进行设定。例如第一扫描时,当前设定匹配率为99,第二次扫描时,当前设定匹配率为96,第二次扫描时,当前设定匹配率为94,第三次扫描时,当前设定匹配率为88。因此,可根据一个、两个或多个设定匹配率,对所述二维表格进行逐次扫描,在所述二维表格的每一行以及每一列中,最多确定一个与所述设定匹配率匹配的第一句子匹配率。步骤104:根据确定出的第一句子匹配率,将对应的原文句子和译文句子对齐。在二维表格的每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率,这样,二维表格中,一个原文句子最多与一个译文句子之间的句子匹配率还存在。因此,确定句子匹配率所在位置对应的待对齐原文句子标识和待对齐译文句子标识;根据待对齐原文句子标识和待对齐译文句子标识,将对应的原文句子和译文句子对齐。当然,为进一步提高对齐的准确率,可设置一个第一设定匹配率,这样,可将大于第一设定匹配率的第一句子匹配率确定为待对齐句子匹配率;确定待对齐句子匹配率所在位置对应的待对齐原文句子标识和待对齐译文句子标识;根据待对齐原文句子标识和待对齐译文句子标识,将对应的原文句子和译文句子对齐。可见,本实施例中,可根据待对齐的原译文件中每句原文句子和每句译文句子之间的句子匹配率,将原译文件中的原文句子和译文句子对齐,这样,实现了原译文对齐自动化,提高了原译文对齐的效率。另外,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。并且,原文或译文中句子顺序以及完整性也不影响原译文对齐。在上述步骤102中,需确定原文句子和译文句子之间的句子匹配率。具体的方式可以有多种,例如:确定原文句子和译文句子之间的长度匹配率ml,或者,确定原文句子和译文句子之间的提取元素匹配率mt,或者,确定原文句子和译文句子之间的长度匹配率ml和提取元素匹配率mt。而确定提取元素匹配率mt还包括确定标点匹配率mp、非译元素匹配率mf、以及单词匹配率mw中的至少一个。下面描述各个匹配率的确定过程。其中,确定长度匹配率ml的过程包括:分别将原文句子s和译文句子t转换成对应的设定语种的原文对等句se和译文对等句te。转换方法为通过一个与原文、译文语种对应的设定语种的字典进行转换。如原文、译文语种分别是中文和英文。而设定语种为英文。则需要将原文句子根据一个通用的中英词典转换成英文的句子,这个句子就叫原文对等句。由于译文是英文,因此就无需转换,直接将译文作为译文对等句。然后,根据原文对等句的长度和译文对等句长度,确定长度匹配率ml。确定标点匹配率mp的过程包括:分别提取原文句子、译文句子中的标点。统计得到原文句子标点数量ps,译文句子标点数量pt;然后,根据语种标点对照表进行标点对应。统计得到对应上的标点数量pdq;这样,标点匹配率mp=pdq*2/(ps+pt)*100%,其中,如果(ps+pt)=0,则mp=1。确定非译元素匹配率mf的过程包括:分别提取原文、译文中的非译元素fs、ft,以及非译元素的数量fsq、ftq;其中,非译元素为句子中无需翻译的内容,如:邮箱地址、电话、ip、网址、数字等(包括不限于),然后,根据对fs,ft进行对齐,统计得到对齐的非译元素数量fdq;这样,mf=fdq*2/(fsq+ftq)*100%。确定单词匹配率mw的过程包括:根据设定的字典,分别将原文句子s和译文句子t转换成对应的设定语种的原文单词原型ss和译文单词原型ts,然后,对比ss和ts中相同的单词,并统计相同的数量cdq;这样,可确定mw=cdq*2/(ss单词数+ts单词数)*100%。可根据设定的应用场景,确定对应的原文句子和译文句子之间的句子匹配率。例如:句子匹配率=(mp+mf)/2*ml。下面将操作流程集合到具体实施例中,举例说明本公开实施例提供的方法。图2是根据一示例性实施例示出的一种原译文对齐方法的流程图,如图2所示,原译文对齐过程包括:步骤201生成原文句子标识和译文句子标识的二维表格。本实施例中,生成的二维表格可如图3所示。图3是根据一示例性实施例示出的一种二维表格的第一示意图。可见,原文s中包括了10个句子,而译文中包括了12个句子。步骤202:确定每句原文句子和每句译文句子之间的句子匹配率,并填入二维表格中的对应位置上。可根据句子匹配率=(mp+mf+mw)/3*ml,确定每句原文句子和每句译文句子之间的句子匹配率,并填入二维表格中的对应位置上,句子匹配率可配置为整数。图4是根据一示例性实施例示出的一种二维表格的第二示意图。如图4所示,表格中每个格中都有句子匹配率。步骤203:确定当前设定匹配率。启动时,可将最大句子匹配率确定为当前设定匹配率。例如:100,或者,图4所示表格中的最大值99。步骤204:扫描二维表格,查找与当前设定匹配率相等的第一句子匹配率。步骤205:判断查找到的第一句子匹配率是否在相同的行或列?若是,执行步骤206,否则,执行步骤207。步骤206:将相同的行或列中的其他句子匹配率设置为零,执行步骤208。步骤207:将每个第一句子匹配率所在行以及所在列的其他句子匹配率设置为零,执行步骤208。步骤208:判断二维表格除去第一句子匹配率以外的其他句子匹配率是否都为零?若否,执行步骤209,若是,执行210。步骤209:将当前设定匹配率减去设定值后更新为当前设定匹配率,并返回步骤203。步骤210:根据确定出的第一句子匹配率,将对应的原文句子和译文句子对齐。可见,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。并且,原文或译文中句子顺序以及完整性也不影响原译文对齐。图4是根据一示例性实施例示出的一种二维表格的示意图。针对该二维表格,具体的扫描对齐过程如下:若当前设定匹配率为99时,在二维表格中查找当前设定匹配率m=99的格子,找到唯一一个第一句子匹配率,对位位置s3t2,保留这个第一句子匹配率99,并将s3行除t2列的其他句子匹配率设置为0;将t2列除s3行的其他句子匹配率设置为0。然后,由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,可将当前设定匹配率-1,即当前设定匹配率更新为98。在二维表格中查找当前设定匹配率m=98的第一句子匹配率,找到2个第一句子匹配率,对位位置为s10t1、s10t7。由于在同一行,因此,保留这2个第一句子匹配率,然后,将s10行除t1、t7列的其他句子匹配率设置为0。同样,由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,可将当前设定匹配率-1,即当前设定匹配率更新为m=97。在二维表格中查找当前设定匹配率m=97的第一句子匹配率,找到2个第一句子匹配率,对位位置为s7t4、s8t8,由于不在相同的行和列,因此,保留这2个第一句子匹配率97,并将s7行除t4列的其他句子匹配率设置为0;将t4列除s7行的其他句子匹配率设置为0。将s8行除t8列的其他句子匹配率设置为0;将t8列除s8行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,可将当前设定匹配率-1,即当前设定匹配率更新为m=96。在二维表格中查找m=96的格子,没有找到。m-1后继续找,直到找到为止,这时当前设定匹配率m=94。在二维表格中查找当前设定匹配率m=94的格子,找到唯一一个第一句子匹配率,对位位置s5t6,保留这个第一句子匹配率94,并将s5行除t6列的其他句子匹配率设置为0;将t6列除s5行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,m-1后继续找,直到找到为止,这时当前设定匹配率m=90。在二维表格中查找当前设定匹配率m=90的第一句子匹配率,找到唯一一个第一句子匹配率90,对应位置s2t12,保留这个第一句子匹配率90,并将s2行除t12列的其他句子匹配率设置为0;将t12列除s2行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,m-1后继续找,直到找到为止,这时当前设定匹配率m=89。在二维表格中查找当前设定匹配率m=89的格子,找到唯一一个第一句子匹配率s9t9,保留这个第一句子匹配率89,并将s9行除t9列的其他句子匹配率设置为0;将t9列除s9行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,m-1后继续找,直到找到为止,这时当前设定匹配率m=83。在二维表格中查找当前设定匹配率m=83的格子,找到唯一一个第一句子匹配率83,对位位置s6t10,保留这个第一句子匹配率83,并将s6行除t10列的其他句子匹配率设置为0;将t10列除s6行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,m-1后继续找,直到找到为止,这时当前设定匹配率m=73。在二维表格中查找当前设定匹配率m=73的格子,找到唯一一个第一句子匹配率,对位位置s1t11,保留这个第一句子匹配率73,并将s1行除t11列的其他句子匹配率设置为0;将t11列除s1行的其他句子匹配率设置为0。由于二维表格除去第一句子匹配率以外的其他句子匹配率不都为零,m-1后继续找,直到找到为止,这时当前设定匹配率m=55。在二维表格中查找当前设定匹配率m=55的格子,找到唯一一个第一句子匹配率,对位位置s4t1,保留这个第一句子匹配率55。并将s4行除t1列的其他句子匹配率设置为0;将t1列除s4行的其他句子匹配率设置为0。图5是是根据一示例性实施例示出的一种二维表格的第三示意图。如图5所示,上述两个第一句子匹配率98对应位置的s10t1、s10t7冲突解决。确定s10t7位置上的第一句子匹配率为98。此时,由于二维表格除去第一句子匹配率以外的其他句子匹配率都为零,至此,一个原文句子最多与一个译文句子之间的句子匹配率还存在。然后,可根据确定出的第一句子匹配率,将对应的原文句子和译文句子对齐,包括:s1=t11(73),s2=t12(90),s3=t2(99),s4=t1(55),s5=t6(94),s6=t10(83),s7=t4(97),s8=t8(97),s9=t9(89),s10=t7(98)。当然,还可根据图4中的句子匹配率计算平均匹配率为87.5,这样,将第一设定匹配率确定为87.5,从而,优选高于第一设定匹配率的句子为共7对。分别为:s2=t12(90),s3=t2(99),s5=t6(94),s7=t4(97),s8=t8(97),s9=t9(89),s10=t7(98)。可见,本发明实施例中,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。下述为本公开装置实施例,可以用于执行本公开方法实施例。根据上述原译文对齐的过程,可构建一种原译文对齐的装置。图6是根据一示例性实施例示出的一种原译文对齐装置的框图。如图6所示,该装置包括:生成单元100、匹配填入单元200、扫描确定单元300以及对齐单元400,其中,生成单元100,用于生成原文句子标识和译文句子标识的二维表格。匹配率填入单元200,用于确定每句原文句子和每句译文句子之间的句子匹配率,并填入二维表格中的对应位置上。扫描确定单元300,用于根据至少一个设定匹配率,对二维表格进行逐次扫描,在二维表格的每一行以及每一列中,最多确定一个与设定匹配率匹配的第一句子匹配率。对齐单元400,用于根据确定出的第一句子匹配率,将对应的原文句子和译文句子对齐。本发明一实施例中,匹配率填入单元200,具体用于确定当前原文句子和当前译文句子之间的长度匹配率,确定当前原文句子和当前译文句子之间的提取元素匹配率,其中,提取元素匹配率包括:标点匹配率、非译元素匹配率、以及单词匹配率中的至少一个,根据长度匹配率以及匹配率,确定当前原文句子和当前译文句子之间的句子匹配率。本发明一实施例中,扫描确定单元300,具体用于扫描二维表格,查找与当前设定匹配率相等的第一句子匹配率,将查找到的每个第一句子匹配率所在行和/或所在列的其他句子匹配率设置为零,将当前设定匹配率减去设定值后更新为当前设定匹配率,根据当前设定匹配率,对二维表格继续进行扫描,直至二维表格除去第一句子匹配率以外的其他句子匹配率都为零。本发明一实施例中,扫描确定单元300,还用于当查找到的第一句子匹配率不在相同的行和列时,将每个第一句子匹配率所在行以及所在列的其他句子匹配率设置为零;当第一句子匹配率在相同的行或列时,将相同的行或列中的其他句子匹配率设置为零。本发明一实施例中,对齐单元400,具体用于将大于第一设定匹配率的第一句子匹配率确定为待对齐句子匹配率;确定待对齐句子匹配率所在位置对应的待对齐原文句子标识和待对齐译文句子标识;根据待对齐原文句子标识和待对齐译文句子标识,将对应的原文句子和译文句子对齐。可见,本实施例中,可根据待对齐的原译文件中每句原文句子和每句译文句子之间的句子匹配率,将原译文件中的原文句子和译文句子对齐,这样,实现了原译文对齐自动化,提高了原译文对齐的效率。另外,基于所有参与对齐的句子之间的句子匹配率,来进行原译文对齐,提高了原译文对齐的准确率。本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。应当理解的是,本发明并不局限于上面已经描述并在附图中示出的流程及结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1