对单词情感值进行自动标定的方法与流程
本发明属于自然语言处理技术领域,涉及一种对单词情感值进行自动标定的方法。
背景技术:
本发明是一种辅助自动情感词典创建的方法,一个优秀的情感词典可以为很多情感分析应用的效果提供保障。由于目前使用人工的方法对情感词典进行创建需要大量的人力物力和时间,因此,使用自动的方法创建情感词典成为了必然的选择。
“情感分析”涉及到许多困难的问题,这些问题之间存在着一定的联系。通常来说,这些问题一般都是需要能自动地检测出文本的情感值,识别出这个文本是积极的还是消极的,或是没有情感倾向的。而且,随着在线网络社交服务的快速发展,任何人在网络上都可以通过一篇微博、推文,或者是一条朋友圈来表达自己对某一件事情的看法,对某一样东西的喜恶。这些情感信息对于服务提供商和广告商来说是非常重要的资源和商机,各大社交网络公司均成立专门的部门分析和挖掘用户发表的微博和推文中的感情倾向信息和用户的观点信息。如何提高情感分析技术,进而提高分析情感信息的准确度和效率,便成一个重要发展方向。对此,不仅需要使用优秀的算法来进行分析,更为关键和基础的是需要有一个公认的可以准确表达出各类情感之间区别的情感表示方法。在情感信息分析中,一般来说有两种情感表示的方法,分别是离散的类别型表示方法和连续的维度型表示方法。前者典型的代表有二元分类表示方法,将情感简单的分为积极的和消极的两种类别;还有robertplutchik提出的八元基础情感分类,八类情感分别是愉快、悲伤、生气、恐惧、厌恶、惊讶、信任和期待。基于这种情感表示方法的情感分析应用有诸如垃圾邮件检测、观点提取和观点识别等具有极高的实际应用价值和发展前景。
连续的维度型情感表示方法近年来同样吸引了大量的关注。较之于类别型的表示方法,维度型的表示方法可以让情感分析更为精准和细致。因为维度型的情感分析可以通过多维度情感值来代表一个单词所表达的情感,这样一个单词的情感便可以使用唯一的一个坐标来表示,即使是表达相近情感的单词。例如,在va(valence-arousal;情绪值-激励值)二维情感空间,如图1所示中,“高兴”和“欣喜若狂”这两个词的v值——代表积极或是消极的程度——便会相差无几,而表示情感强烈程度的a值则会差距很大。
基于这类维度型情感空间的前提下,情感分析的任务一般是对单词、句子或者是文本进行情感值的标定。并且,进行句子和文本的情感值标定通常以单词的情感值为基础。因此,标定优良的情感词典是必不可少的。完成这一任务的方法从大的分类上来说有两种,其中一种方法是通过人工手动标定,一般的流程是让不同的标定人员对某一个单词根据自己的判断标定情感值,之后再根据所有人的标定结果进行一定数学上的处理,从而得出这个单词最终的情感值。这样做的代价是需要大量的人力和时间,成本高昂。另一种方法是通过计算机使用机器学习的方法自动地进行情感值的标定。然而,对于这一任务而言,使用的机器学习算法一般都是有监督的算法,这就需要有提前建立好的情感词典为算法提供训练集。
目前公认度较高的情感词典有:英文的anew(affectivenormsforenglishwords),包含1034个标注了va值的英文单词;中文的caw(chinsesaffectivewords)和cvaw(chinesevalence-arousalwords),分别包含162个和1653个标注了va值的英文单词,其它优秀的情感词典不一一列举。这些情感词典是实现自动标注情感词典的基础。
wei和malandrakis等人分别于2011年前后使用了几种基于回归的方法进行情感值预测。这些方法一般通过情感词典作为训练集(种子单词;seedwords),训练出相应的模型,之后再通过该模型对未标定情感值的单词(unseenwords)进行情感值标定。该类情感值预测方法,预测结果的准确性低。
技术实现要素:
为实现上述目的,本发明提供一种对单词情感值进行自动标定的方法,避免大量使用人工标定,情感值预测结果的准确性高,解决了现有技术中情感值预测方法的预测结果准确性低,应用范围受到限制的问题。
本发明所采用的技术方案是,一种对单词情感值进行自动标定的方法,具体按照以下步骤进行:
步骤1,训练出词库中所有单词的词向量,通过人工标记的方法初始化少量单词,记作种子单词vj,其余单词为待标定单词vi;被初始化的种子单词vj的情绪值为valvj、激励值为arovj;
步骤2,利用word2vec工具计算每个种子单词vj和每个待标定单词vi的词向量之间的余弦夹角值,得到每个种子单词vj和每个待标定单词vi之间的相似度;
步骤3,以种子单词vj和待标定单词vi作为节点,以种子单词vj和待标定单词vi之间的相似度作为连边权重,构建权重图模型;
步骤4,预测待标定单词vi的情绪值valvi和激励值arovi。
本发明的特征还在于,进一步的,所述步骤4中,预测待标定单词vi的情绪值valvi,通过式(3)进行不断迭代更新至收敛:
其中,α是衰变因子或置信水平,取值在0-1之间,随机数取值在1-9之间,sim(vi,vj)代表待标定单词vi和种子单词vj之间的相似度,valvj代表被初始化的种子单词的情绪值,t代表迭代的步数,
进一步的,所述步骤4中,预测待标定单词的激励值arovi的方法,通过式(4)进行不断迭代更新至收敛:
其中,α是衰变因子或置信水平,取值在0-1之间;随机数取值在1-9之间,sim(vi,vj)代表待标定单词vi和种子单词vj之间的相似度,arovj代表被初始化的种子单词的激励值,t代表迭代的步数,
进一步的,所述步骤4中,预测待标定单词vi的情绪值valvi和激励值arovi采用矩阵运算方法,具体为:将所有待标定单词、种子单词的情绪值用向量v表示,将所有待标定单词、种子单词的激励值用向量a表示,
其中,sim(vi,vj)表示待标定单词vi和种子单词vj之间的相似度,1≤i<n,1≤j<n;
设定向量i=(1,1t,向量d,=(d1,d2,...,dn)t,其中,
利用式(5)计算第t步迭代包含种子单词和待标定单词在内所有词汇的情绪值向量vt和激励值向量at;
vt=m[(i-d)t,vt-1]+m[dt,u(svt-1,s×i)],
at=m[(i-d)t,at-1]+m[dt,u(sat-1,s×i)](5)
其中,vt-1代表第t-1步迭代包含种子单词vj和待标定单词vi在内所有词汇的情绪值向量,at-1代表第t-1步迭代包含种子单词vj和待标定单词vi在内所有词汇的激励值向量;
待多次迭代收敛后,待标定单词vi的情绪值valvi为情绪值向量vt的第i维相应数值;待标定单词vi的激励值arovi为激励值向量at的第i维相应数值。
本发明的有益效果是:本发明考虑到语言中单词与单词之间的联系,提出了权重图模型用以对单词的情感值va进行预测,对pagerank算法进行改良,将pagerank算法进行改良后运用到连续型的情感值va预测的应用中;本发明和pagerank算法的区别在于它将每个种子单词和每个待标定单词之间的相似度作为权重图模型中两个结点之间边的权重值,如此一来,相似度越高的单词就会在待标定单词的情感值标定中做出更多的贡献,从而得到一个更适合单词情感值标注的算法和模型,提高情感值预测结果的准确性。此外,还能利用本发明的权重图模型创建出更为优质的情感词典。
本发明对单词情感值进行自动标定的方法,人工成本低,情感值预测结果准确性高,能够应用于更多领域。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是单词情绪值-激励值的二维情感空间。
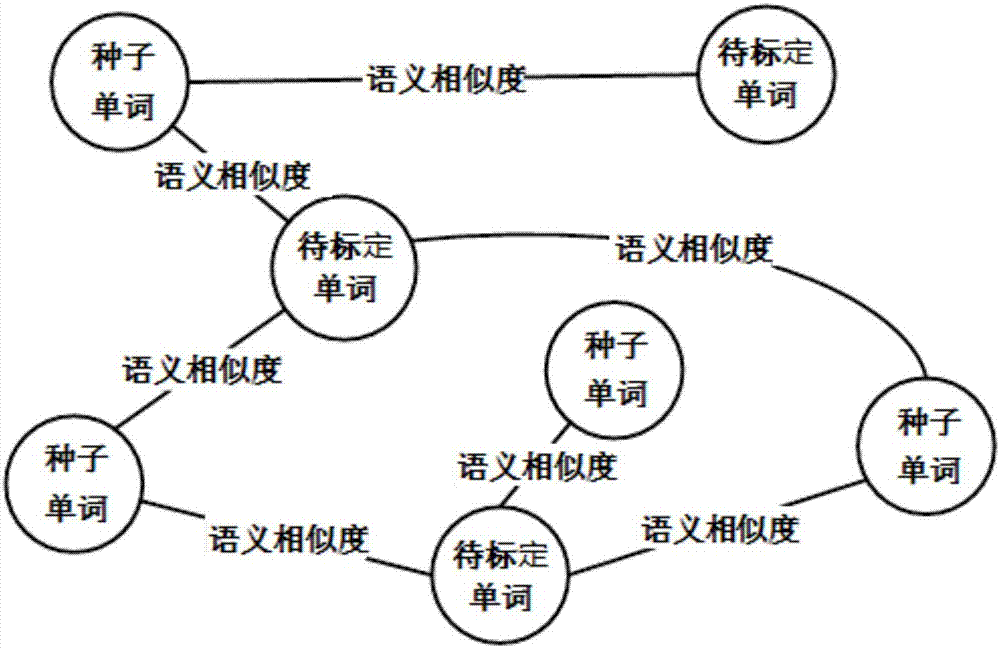
图2是种子单词和待标定单词的关系模型图。
图3是pagerank算法和本发明权重图模型迭代结果对比图。
具体实施方式
下面将结合本发明实施例中,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
google的pagerank算法是计算网页重要性并据此对网页进行排名的算法,该算法的目的是为用户推荐与用户搜索结果最为相似的网页。pagerank算法的核心思想有以下两条:第一,如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是pagerank值会相对较高;第二,如果一个pagerank值很高的网页链接到其它的网页,那么被链接到的网页的pagerank值会相应地因此而提高。
根据pagerank算法的原理,另外一种情感分类的方法也被提出,该类方法是通过判定待标定情感值单词与种子单词之间“关系”的远近来标定情感值,当两个单词具有相近的“关系”时,它们的情感类别也应当是相似的,通过这样的方法来对未标定情感类别的单词进行情感分类。这种方法的核心是在一个图上使用标签传播(raoandravichandran,2009;hassan,2011)和pagerank算法(esuli,2007)。但是这种方法目前主要是运用在情感的类别划分上。
本发明对pagerank算法进行了以下两个方面的改进,使得它可以被应用在情感值(va)预测上;第一个方面是将排名得分转化为具体的va值,va值包括情绪值和激励值,见图1;第二个方面,将pagerank算法中待标定单词和其邻接的种子单词之间的边的权重视作相同,将待标定单词和邻接的种子单词之间的相似度作为权重图模型中两个结点之间的边的权重值,如此一来,与待标定单词相似度越高的邻接种子单词在待标定单词的情感值标定中贡献多大,所占权重越大,即同时考虑待标定单词与各个邻接种子单词之间的关系及与各个邻接种子单词之间的相似度。
对单词情感值进行自动标定的方法,具体按照以下步骤进行:
步骤1,训练出词库中所有单词的词向量,通过人工标记的方法初始化少量单词,记作种子单词vj,其余单词为待标定单词vi;被初始化的种子单词vj的情绪值为valvj、激励值为arovj;
步骤2,利用word2vec工具计算每个种子单词vj和每个待标定单词vi的词向量之间的余弦夹角值,得到每个种子单词vj和每个待标定单词vi之间的相似度;
步骤3,以种子单词vj和待标定单词vi作为节点,以种子单词vj和待标定单词vi之间的相似度作为连边权重,构建权重图模型;
步骤4,预测待标定单词vi的情绪值valvi和激励值arovi。
根据链接分析理论,种子单词和待标定单词的关系模型,如图2所示。待标定单词的情感值可以根据邻接种子单词中相似度最高的单词的va值进行标定。待标定单词和其邻接种子单词之间的边的权重值(即相似度)通过google提供的word2vec工具进行计算;计算两个单词的词向量之间的余弦夹角值,即为两个单词之间的相似度。图模型的数学表达如下:无向图g=(v,e),其中,v表示单词的集合,即图的结点,e表示结点之间无向连接的边的集合。e中的每一条边e代表待标定单词vi和种子单词vj之间的相似度(vi,vj∈v(1≤i,j≤n;i≠j))。对于每一个待标定单词vi,它的邻接种子单词集合表示为n(vi)={vj|(vi,vj)∈e}。待标定单词vi的valence值(情绪值)和arousal(激励值)分别使用
待标定单词vi的激励值arovi根据式(2)计算:
其中,valvj代表种子单词vj的情绪值,sim(vi,vj)代表待标定单词vi和种子单词vj之间的相似度。α是衰变因子或是置信水平,取值在0-1之间,可以限制pagerank算法中的排名下沉现象所产生的影响,该现象会导致结果无法收敛成唯一值;一开始时,待标定单词vi的va值为随机数,初始化为1至9之间的任意数值,之后则通过式(3)和式(4)不断迭代更新至收敛。
其中,t代表迭代的步数;
值得注意的是,种子单词的va值在每一步的迭代中都是一个常量,并不改变。基于此,每一个待标定单词的va值均在图2中经过多次迭代传播直至收敛而得来的。
为了提高迭代的效率,式(3)和式(4)可以改良成为矩阵运算。将所有待标定单词和种子单词的情绪值valence和激励值arousal合并为以下两个向量表示:
其中,sim(vi,vj)代表待标定单词vi和种子单词vj之间的相似度,i≠j,1≤i<n,1≤j<n。同时再给定两个向量i=(1,1,1,...,1)t和d=(d1,d2,...,dn)t,其中,
利用式(5)计算第t步迭代包含种子单词和待标定单词在内所有词汇的情绪值向量vt和激励值向量at;
vt=m[(i-d)t,vt-1]+m[dt,u(svt-1,s×i)],
at=m[(i-d)t,at-1]+m[dt,u(sat-1,s×i)](5)
其中,vt-1代表第t-1步迭代包含种子单词vj和待标定单词vi在内所有词汇的情绪值向量,at-1代表第t-1步迭代包含种子单词vj和待标定单词vi在内所有词汇的激励值向量;待多次迭代收敛后,根据情绪值向量vt的索引获得待标定单词vi的情绪值valvi,根据激励值向量at的索引获得待标定单词vi的激励值arovi;即待标定单词vi的情绪值valvi为情绪值向量vt的第i维相应数值;待标定单词vi的激励值arovi为激励值向量at的第i维相应数值;如待标定单词v2的情绪值为情绪值向量vt的第二维相应数值;如待标定单词v3的激励值为激励值向量at的第三维相应数值。
通过式(5),va值的预测可以更高效的迭代收敛。
使用anew英文情感词典和caw中文情感词典对本发明的标定结果进行测试;在实验过程中,我们采用交叉验证进行实验。具体的操作是将数据集平均分为若干份,实验中分为5份;每进行一次实验,将其中的4份作为种子单词,余下的一份作为待标定单词,如此循环实验5次,最终结果取每次实验结果的平均值。
同时,我们设置了两组对比实验;第一组使用回归方法的va值预测的方法,包括线性回归算法和核函数回归算法。对于第一组的两种方法,种子单词之间的相似度和它们的va值将作为训练集数据进行训练,余下的单词则作为测试数据。第二组是两种基于图模型的方法,分别是pagerank算法和本发明提出的权重图模型算法。
评价指标:
对于不同方法的性能主要通过以下三个指标来衡量:
均方误差(rootmeansquareerror,rmse):
平均绝对误差(meanabsoluteerror,mae):
平均绝对百分误差(meanabsolutepercentageerror,mape):
其中,ai表示待标定单词情感va值的真实值,pi表示待标定单词情感va值的预测值。如果某方法的三个指标都比较低,则表示该方法的预测值与真实值越接近,该方法效果良好。
实验结果及分析:
pagerank算法和权重图算法均需要进行迭代操作,我们为两个算法设定了相同的迭代步数来进行对比,并探索了在当前数据集下不同迭代步数的效果,我们以均方误差值作为参照,两个算法的迭代效果如图3所示。
从图3可以看出,两个算法都基本是在第10次迭代附近趋于稳定的;本发明权重图算法预测的-情感值valence和激励值arousal的均方误差值较低,预测值与真实值比较接近;每个单词的最终收敛结果与初始分配值及衰减因子无关。
分别采用线性回归、核函数回归、pagerank算法、本发明权重图算法进行实验的各个指标的结果见表1,其中pagerank算法和本发明权重图模型的迭代次数均设置50次。
表1四种算法的各个指标结果
从表1中可以看出,基于pagerank算法和本发明权重图算法总体上优于线性回归算法和核函数算法。本发明权重图算法在mape(平均绝对百分误差)这项指标上的表现要优于其它三种算法,比pagerank算法平均低大约4%,比核函数回归法低8%左右,比线性回归法低7%。权重图算法比其它几个算法表现好的原因是它同时考虑了多个结点之间的关系和它们之间的权重值。此外,我们也可以从结果中看出,对于arousal值预测要比valence值预测的难度大。
线性回归算法:
使用自动或半自动的方法进行待标定单词的va值预测时,通常以人工的方式标记少量情感单词作为种子单词,再利用计算单词间语义相似度的方法自动从大量文本标记与种子单词相似的待标定单词。
因此,通常可以采用线性回归来建立单词“相似度-va值”的对应关系,接着再利用待标注单词与种子单词之间的相似度来预测待标注单词的va值。由于每个种子单词均有标记好的va值,因此只需要计算每个种子单词与其他种子单词的相似度,便可为每个种子单词建立“相似度-valence(或arousal)值”的回归模型,下式为种子单词seedj的valence回归模型,
其中,b为回归系数,a为截距。其中sim(seedi,seedj)代表种子单词seedi和seedj的语义相似度,
如果要利用此回归模型来预测通过验证的待标注单词va值,仅需将这些单词与seedj的相似度输入即可,例如:假设某待标注单词unseeni与seedj的相似度超过阀值且通过验证时,unseeni将被选为情感词汇,此时便可将unseeni与seedj的相似度输入seedj的回归模型来预测candi的va值,如下式所示,
如果待标注单词与种子单词的相似度不只超过一个种子单词的阀值,可使用两者相似度最大的种子单词训练产生的回归模型。
核函数回归算法:
基于此,另一种方法可在常规的线性回归模型中引入核函数,用于对相似度进行线性或非线性的变换,回归模型定义为:
其中f表示核函数,可以是线性函数,也可以是平方根,对数等非线性函数。基于这个模型,待标注单词的va值
pagerank算法:
也有一些文献提出使用pagerank算法进行词汇的va值预测。这类方法通常将种子单词、待标注单词作为节点,词汇间的关系作为边,将词汇与相似度描述成图模型,并引入pagerank算法进行求解。在该方法中,每个待标注节点(单词)的va值均按照下式进行更新:
其中,wi和wj分别表示待标注单词和种子单词,nei(wi)表示与节点(单词)wi有边相连的所有邻接节点(单词)的集合。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!