针对视频数据行人再识别的LOMO3D特征提取方法与流程
本发明属于视觉行人再识别技术领域,尤其是一种针对视频数据行人再识别的lomo3d特征提取方法。
背景技术:
随着监控范围的增大,监控数据呈现爆炸式增长。依靠人眼识别监控画面中的行人身份显然十分低效,行人再识别技术的任务便是依靠计算机视觉技术解决不重叠监控视野中行人身份匹配的问题。
行人再识别技术的传统方法主要包括两个步骤,首先对图像/视频进行特征提取,然后通过度量学习得到不同样本的相似度/距离。在特征提取阶段,常用的基础图像特征包括颜色特征、纹理特征、梯度特征等,将这些特征进行融合往往取得优于单一特征的效果。除这些基础特征以外,针对行人再识别技术采用一些高级特征,例如,局部最大值(lomo)特征、whos特征、elf特征等。这些特征配合不同的度量学习方法,取得了很好的效果。
然而,上述特征的局限性在于仅仅对单张图像进行描述,而没有对监控视频的帧间信息进行利用。
技术实现要素:
本发明的目地在于克服现有技术的不足,提出一种设计合理、匹配效率高且性能稳定的针对视频数据行人再识别的lomo3d特征提取方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种针对视频数据行人再识别的lomo3d特征提取方法,包括以下步骤:
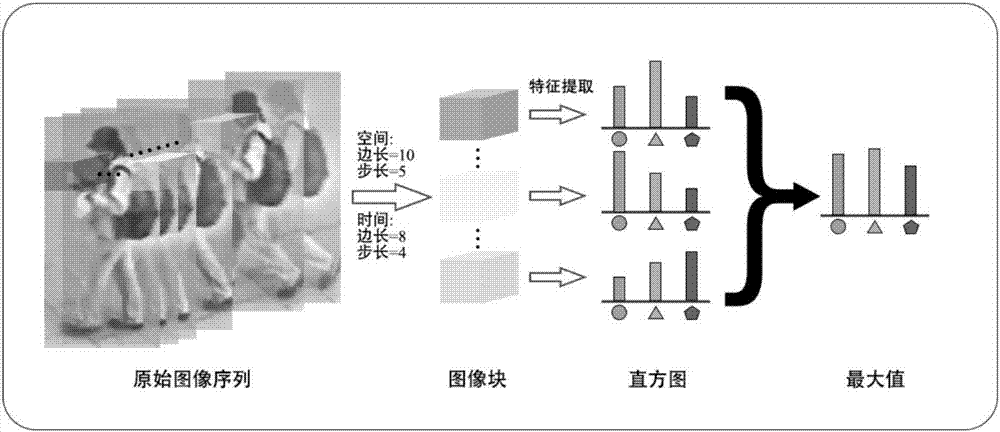
步骤1、将视频数据中的各帧分离出来,组织成图像序列的形式,并分割为一定长度的等长序列;
步骤2、将每个序列水平分割为若干扁平区域,并在这些区域中进一步划分子块,作为直方图统计的最小单位;
步骤3、对于每个子块,根据其中包含的像素点计算siltp3d特征,统计形成纹理直方图特征;
步骤4、对于每个子块,根据其中包含的像素点计算hsv色域下的颜色直方图特征;
步骤5、将每个水平区域中的纹理和颜色直方图特征根据最大化原则进行整合;
步骤6、将整合后的各水平区域的特征进行拼合,得到最终的lomo3d特征描述子。
所述等长序列的长度为20。
所述步骤1的具体实现方法为:针对长度不一致的视频数据,将视频各帧视为连续图像序列,并以20帧为长度划分为子序列,将该序列视为高度、宽度、长度分别为图像高度、图像宽度、帧数的立方体,以此作为lomo3d特征描述子的提取对象。
所述步骤2的具体实现方法为:将每个划分好的视频序列组成的场方体,进一步分割为水平的扁形区域,并进一步将这些区域划分为小的子块,所述子块在高度、宽度、时间长度上的尺寸分别为10像素、10像素、8帧,且这些子块相互重叠,重叠率为0.5。
所述步骤3的具体实现方法包括以下步骤:
⑴给定像素位置(xc,yc),原始siltp的编码规则如下:
其中,ic表示中心像素的灰度值,ik是在当前帧围绕它的半径为r的圆上的n个相邻点,τ是一个尺度参数,sτ定义如下:
⑵在r=1的情况下,将siltp3d特征所覆盖的像素点数从8个增加至26个;
⑶我们取了36个直方,对步骤2中所述的每个子块中所包含的像素点进行统计,形成纹理直方图特征。
所述步骤4的具体实现方法为:首先将每帧图像由rgb颜色空间转换为hsv颜色空间,然后对步骤2中所述的每个子块中所包含的像素点统计直方图特征,hsv颜色特征的直方数为83个。
所述步骤5的具体实现方法为:设图像序列的高度为128像素,宽度为64像素,长度为20帧,所取最小子块的高度为10像素,宽度为10像素,长度为8帧,且在水平方向和时间方向的重叠率均为0.5,则每个扁形区域共有11*4=44个子块,每个子块所提取的特征为83+36=1241个直方,对所有子块相同位置上的直方取最大值,得到每个扁形区域的特征。
所述步骤6的具体实现方法为:将每个原始图像序列分为由上到下的24个不重叠的扁形区域,对原始图像进行了两次2*2的池化处理,从而除原始的128*64*20的序列外,还对64*32*20、32*16*20的序列进行了特征提取操作,将共有24+11+5个扁形区域的特征最终拼合起来,构成最后的lomo3d特征。
本发明的优点和积极效果是:
本发明设计合理,其从图像序列中提取的时-空特征,并在这一过程中加入了时间信息,充分利用了图像序列中相比于单张图像更为丰富的信息,对这两种特征进行综合利用,使得特征的描述能力性能远远高于单纯的空间域特征,试验表明本发明能够使得系统整体匹配率大大提升,优于目前其他的行人再识别算法。
附图说明
图1是siltp3d特征提取的原理图;
图2是lomo3d特征提取的原理图;
图3a至图3f是本发明试验结果给出的不同参数及不同特征的性能对比分析图。
具体实施方式
以下结合附图对本发明实施例做进一步详述。
一种针对视频数据行人再识别的lomo3d特征提取方法,包括以下步骤:
步骤1、将视频数据中的各帧分离出来,组织成图像序列的形式,并分割为长度为20的等长序列。
本步骤的具体处理方法为:针对长度不一致的视频数据,首先将视频各帧视为连续图像序列,并以20帧为长度划分为子序列,将该序列视为高度、宽度、长度分别为图像高度、图像宽度、帧数的立方体,以此作为lomo3d特征描述子的提取对象。
步骤2、将每个序列水平分割为若干扁平区域,并在这些区域中进一步划分子块,作为直方图统计的最小单位。
本步骤的具体处理方法为:将每个划分好的视频序列组成的长方体,进一步分割为水平的扁形区域,并进一步将这些区域划分为小的子块。子块在高度、宽度、时间长度上的尺寸分别为10像素、10像素、8帧,且这些子块相互重叠,重叠率为0.5。
步骤3、对于每个子块,根据其中包含的像素点计算siltp3d特征,统计形成纹理直方图特征。
本步骤的具体处理方法如下:
给定像素位置(xc,yc),原始siltp的编码规则如下式:
其中,ic表示中心像素的灰度值,ik是在当前帧围绕它的半径为r的圆上的n个相邻点,τ是一个尺度参数,sτ定义如下:
如图1所示(左侧为原始siltp特征,右侧为改进后的siltp3d特征),考虑到前后帧相对于当前帧的临近像素,在r=1的情况下,siltp3d特征所覆盖的像素点数从8个增加至26个。
计算siltp3d特征的直方图时,我们取了36个直方,对步骤2中所述的每个子块中所包含的像素点进行统计。
步骤4、对于每个子块,根据其中包含的像素点计算hsv色域下的颜色直方图特征。
本步骤的具体处理方法为:首先将每帧图像由rgb颜色空间转换为hsv颜色空间,然后对步骤2中所述的每个子块中所包含的像素点统计直方图特征。在这里,hsv颜色特征的直方数为83个。
步骤5、将每个水平区域中的纹理和颜色直方图特征根据最大化原则进行整合。
本步骤的具体处理方法为:图像序列的高度为128像素,宽度为64像素,长度为20帧。所取最小子块的高度为10像素,宽度为10像素,长度为8帧,且在水平方向和时间方向的重叠率均为0.5,即每个扁形区域共有11*4=44个子块,每个子块所提取的特征为83+36=1241个直方,对所有子块相同位置上的直方取最大值,得到每个扁形区域的特征。
步骤6、将整合后的各水平区域的特征进行拼合,得到最终的特征描述子。
本步骤的具体处理方法为:每个原始图像序列被由上到下分为24个不重叠的扁形区域。为了增强特征在不同尺度下的描述能力,对原始图像进行了两次2*2的池化处理,即除原始的128*64*20的序列外,还对64*32*20、32*16*20的序列进行了特征提取操作,即共有24+11+5个扁形区域的特征最终拼合起来,构成最后的lomo3d特征。
下面按照本发明方法进行试验,说明本试验的试验效果。
试验环境:matlabr2016a
试验数据:所选数据集是用于行人再识别的图像序列数据集ilids-vid和prid2011。
试验指标:试验使用了cumulatedmatchingcharacteristics(cmc)曲线作为评价指标,该指标表示正确匹配的样本在备选集中相似度的排名。
试验结果如图3所示,曲线越接近100%性能越好。在第三列图像中,本发明将lomo3d特征与原始lomo特征以及另外两种特征进行了比较,从中可以看出,lomo3d特征和原始lomo特征的描述能力明显高于另外两种特征,lomo3d特征相对于原始lomo特征有了明显的性能提升。
表1和表2是本发明与现有算法的性能比较。从中可以看出,本发明使用的算法在相似度排序的性能上高于现有算法。
表1采用ilids-vid图像序列数据集的性能对照表
表2采用prid2011图像序列数据集的性能对照表
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!