一种基于MOEAD的比例区间偏好引导多目标决策优化方法与流程
本发明涉及飞机结构维修决策领域,具体涉及基于moead的比例区间偏好引导多目标决策优化方法。
背景技术:
带有偏好信息的多目标决策问题作为多目标问题的一个分支,在最近的30年来被广泛的研究(liu,p.;teng,f.anextendedtodimmethodformultipleattributegroupdecision-makingbasedon2-dimensionuncertainlinguisticvariable.complexity2016,21,20-30.liu,p.;teng,f.multiplecriteriadecisionmakingmethodbasedonnormalinterval-valuedintuitionisticfuzzygeneralizedaggregationoperator.complexity2016,21,277-290.xu,j.p.;liu,y.g.multi-objectivedecisionmakingmodelunderfuzzyrandomenvironmentanditsapplicationtoinventoryproblems.informationsciences2008,178,675-684.)。由于决策者经常无法准确的阐述自己对于决策模型中各目标值的偏好,反映各目标之间偏好信息的关系是模糊的。多目标决策问题中存在的目标之间具有相对重要性的偏好和目标之间存在优先级的两类偏好问题在最近的几年被广泛的研究(zadeh,l.a.fuzzysets.informationandcontrol1965,8,338-353.ghadimi,n.anewhybridalgorithmbasedonoptimalfuzzycontrollerinmultimachinepowersystem.complexity2015,21,78-93.)。然而,在实际的多目标决策优化问题中,存在以上两种偏好关系并不适合的情况。如带有比例关系的区间偏好和带有偏差关系的区间偏好。
假设决策者更偏向于得到满足自己偏好信息的有效解,则整个决策过程可以划分为:(i)获得所有的pareto最优解;(ii)选择满足偏好信息的有效解。上述决策过程的执行顺序主要由决策者表达偏好信息的方式决定。依据决策者表达偏好信息的方式,求解带有偏好信息的多目标决策问题的方法主要分为:先验方法、后验方法和交互式方法(goularta,f.,&campelo,f.preference-guidedevolutionaryalgorithmsformany-objectiveoptimization.informationsciences2016,329,236-255.)。
先验方法:决策者在多目标决策模型的求解之前就定义了自己的偏好信息。因此,执行者(优化方法)可以更专注于求解获得那些最大程度的满足决策者偏好信息的有效解。表达决策者的偏好信息的方法主要包括:功效函数、权重、优先级以及期望值。先验方法由于可以利用决策者的偏好信息,将多目标决策模型转化为单目标优化模型,进一步的利用传统的单目标优化方法进行求解优,因此使整个优化过程得到了很大程度的简化。但是,决策者需要在求解之前就很清晰和精确的定义偏好信息,这往往十分困难,而且先验方法存在求解得到的最优解不能够充分满足决策偏好的情况。
后验方法:在现实的多目标优化问题中,决策者有可能无法提前给出偏好信息。针对这种情况,后验方法先利用某种优化算法对原无偏好的多目标优化问题进行求解,产生包含大量pareto最优解的解集,然后根据这个集合中解的特点,由决策者根据偏好信息挑选有效解。由于不需要决策者提前定义偏好信息,后验方法很大程度的减轻了决策者的负担,但当目标数量增加时,pareto最优解的数量增长十分快,计算量十分庞大。
交互式方法:交互式方法通过分析者的求解和决策者的抉择相结合的人机对话方式,采用分析阶段和决策阶段反复交替进行、使对目标结果的偏好逐渐清晰的方法来获得最终的满意解。交互式方法不需要决策者提前给出精确的偏好信息,且避免了后验方法需要求解获得所有pareto最优解的缺点。然而,整个交互过程往往十分耗时和繁杂,且最优获得的有效解很大程度依赖于决策者的主观判断。
技术实现要素:
本发明的目的是为了解决现有技术求解得到的满足决策者比例区间偏好的有效解个数少的缺点,而提出一种基于moead的比例区间偏好引导多目标决策优化方法。
一种基于moead的比例区间偏好引导多目标决策优化方法包括以下步骤:
步骤一:建立带有比例关系区间偏好信息的多目标决策模型;
s.t.gi(x)≥ai,i=1,2,...,m
hj(x)=bj,j=1,2,...,n
x=(x1,...,xq)∈x∈rq
其中x=x1,...,xq是决策向量,x是可行解的集合,f为决策空间rq到目标空间rz的映射关系,q是决策空间维数,即决策变量个数;z是目标空间维数,即目标变量个数;gi(x)和hj(x)分别是第j个不等式约束和等式约束,
步骤二:利用法线边界交叉法对步骤一建立的带有比例关系区间偏好信息的多目标决策模型进行重构得到重构后的分解模型;
步骤三:对步骤二重构后的分解模型进行求解,得到带有比例关系区间偏好信息的多目标决策模型的优化解。
moead为基于分解的多目标进化算法。
本发明的有益效果为:
针对现有方法无法高效处理带有比例关系区间偏好的多目标决策优化问题,本发明提出了一种基于moea/d的偏好引导多目标决策优化算法。通过对法线边界交叉方法进行改进,以离散比例偏好为优化引导向量对多目标优化模型进行了重构。基于moea/d对重构的多目标优化模型进行求解,利用优化引导向量使初始种群沿着偏好信息的方向快速收敛到有效解,避免了传统优化方法通过后验方法获得满足偏好有效解造成的较高的空间复杂度和时间复杂度。实验结果表明本发明提出的算法能够很好的解决决策者的偏好信息为比例的多目标决策优化模型复杂度高,难以获得满足决策者偏好信息的有效解等问题,本发明方法展示出了解决实际工程问题的能力。
附图说明
图1为传统bi方法示意图;
图2为本发明改进的bi方法示意图;
图3为zdt1比例关系区间偏好优化结果图;
图4为zdt2比例关系区间偏好优化结果图;
图5为zdt3比例关系区间偏好优化结果图;
图6为zdt4比例关系区间偏好优化结果图;
图7为zdt6比例关系区间偏好优化结果图;
图8为dtlz1比例关系区间偏好视角1优化结果图;
图9为dtlz1比例关系区间偏好视角2优化结果图;
图10为dtlz1比例关系区间偏好f1-f2视角优化结果图;
图11为dtlz1比例关系区间偏好f1-f3视角优化结果图;
图12为dtlz2比例关系区间偏好视角1优化结果图;
图13为dtlz2比例关系区间偏好视角2优化结果图;
图14为dtlz2比例关系区间偏好f1-f2视角优化结果图;
图15为dtlz2比例关系区间偏好f1-f3视角优化结果图;
图16为偏好向量在区间[2.5,3]内的优化结果图。
图中moea/d为对比实验方法,pga/moead为本发明方法。
具体实施方式
具体实施方式一:一种基于moead的比例区间偏好引导多目标决策优化方法包括以下步骤:
在实际的多目标决策优化问题中,存在以上两种偏好关系并不适合的情况。例如,在某飞机基地中,有三个不同的任务(a、b和c)需要两个机队共同协作进行完成(每个任务都需要两个机队共同协作完成),由于机队中资源配置(飞机种类、后勤人员等)或者任务角色的不同,当任务循序按照abc执行时,机队1、2分别需要5、2小时完成任务;而当任务循序按照bca执行时,机队1、2都需要3小时完成任务。不存在一个任务序列能同时使两个机队的完成时间都达到最小,因此该飞行任务的决策问题存在两个目标,使两个机队的完成时间最小。根据对历史的任务执行数据进行统计分析,当两个机队的完成任务需要的时间之比为一个模糊的比例区间关系时,有利于资源的调度和运营成本的控制,因此决策者对目标之间的偏好可以表示为一个比例关系区间。具体的带有比例关系区间偏好的决策模型如式下式所示。
其中,x表示任务序列;f1、f2分别表示机队1和2完成任务的时间;
针对决策者偏好信息以区间形式表示的多目标决策问题,本发明提出了基于moea/d的偏好引导的多目标决策优化算法(moea/dp),利用离散偏好向量,采用法线边界交叉法(boundaryintersectionmethod,bi)对带有区间偏好的多目标决策优化模型进行了重构,通过离散偏好向量引导初始种群沿着偏好向量的方向收敛,快速获得满足决策者偏好的有效解,降低了求解过程的空间复杂度和时间复杂度。实验结果表明提出的基于离散偏好信息的多目标决策算法能够很好的解决带有比例关系区间偏好信息的多目标决策模型,展示出了解决实际工程问题的能力。
步骤一:建立带有比例关系区间偏好信息的多目标决策模型;
将带有比例关系区间偏好的决策模型中所表示的比例关系区间偏好信息进行推广,如下式所示为一个包含z个目标函数的带有比例关系区间偏好信息的决策优化模型,比例关系区间偏好信息表现在两个目标之间(fk1和fk2)。
s.t.gi(x)≥ai,i=1,2,...,m
hj(x)=bj,j=1,2,...,n
x=(x1,...,xq)∈x∈rq
其中x=x1,...,xq是决策向量,x是可行解的集合,f为决策空间rq到目标空间rz的映射关系,q是决策空间维数,即决策变量个数;z是目标空间维数,即目标变量个数;gi(x)和hj(x)分别是第j个不等式约束和等式约束,
步骤二:利用法线边界交叉法对步骤一建立的带有比例关系区间偏好信息的多目标决策模型进行重构得到重构后的分解模型;
步骤三:对步骤二重构后的分解模型进行求解,得到带有比例关系区间偏好信息的多目标决策模型的优化解。
针对决策者偏好信息以区间形式表示的多目标决策问题,本发明提出了基于moea/d的偏好引导的多目标决策优化算法(moea/dp),利用离散偏好向量,采用法线边界交叉法(boundaryintersectionmethod,bi)对带有区间偏好的多目标决策优化模型进行了重构,通过离散偏好向量引导初始种群沿着偏好向量的方向收敛,快速获得满足决策者偏好的有效解,降低了求解过程的空间复杂度和时间复杂度。实验结果表明提出的基于离散偏好信息的多目标决策算法能够很好的解决带有比例关系区间偏好信息的多目标决策模型,展示出了解决实际工程问题的能力。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤二中法线边界交叉法的数学模型为:
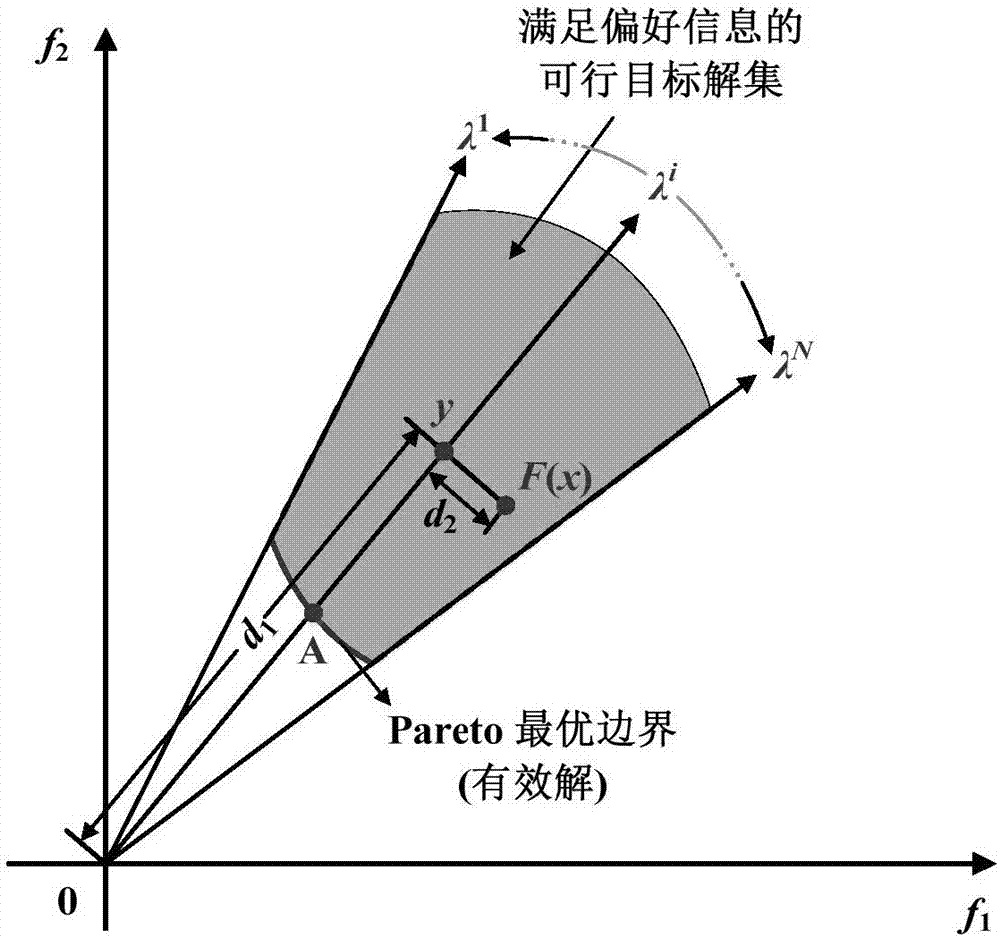
传统bi方法被设计用来获得均匀分布的多目标优化问题非劣边界(paretofront,pf)。如图1所示,多目标优化问题的pf是可行性目标空间中最左下方的部分凸边界。
几何上,bi通过找到可行性目标空间中最左下方边界和一系列由参考点z*(z*=(minf1(x),minf2(x),…,minfz(x)),z表示目标函数的个数)均匀发散出的射线的交点来逼近pf。如图1,从参考点z*发射出一条方向为λ的射线l,其中λ为权重求和方法中的权重向量λ=(λ1,…,λz)t,其中λi≥0(i=1,…,z)且
minimizeg(x|λ,z*)=d1+θd2
其中minimize表示最小化,subjectto表示满足,g(·)为最小化函数,z*为参考点,λ为从参考点发出的法线,d1为参考点到目标点在法线上投影点的距离,d2目标点到法线的垂直距离,θ是惩罚系数。
其中,θ>0是惩罚系数,确保f(x)沿着l收敛到a点。优化目标是最小化d1和d2。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述对步骤一建立的带有比例关系区间偏好信息的多目标决策模型进行重构得到重构后的分解模型的具体过程为:
由于决策者的偏好信息由l个比例关系区间组成,而比例关系区间可以离散为比例偏好集合,在l个比例偏好集合内各取1个偏好值构成了一个偏好向量。因此决策者的偏好信息表示成一个由n个偏好向量构成的集合,具体为:
其中pi表示决策者对于目标之间的偏好关系的集合,l表示决策模型中,各目标之间存在偏好关系(区间)的个数,λi表示偏好集合中的第i个偏好向量,i=1,...,n,n→∞;
以式带有比例关系区间偏好信息的多目标决策模型中的目标函数个数为2为例,决策者的偏好表示为
其中
本发明对bi进行了如下改进:
本发明以原点替代z*作为参考点来产生射线,在传统的bi方法中,确定z*是需要通过单目标优化问题求解获得的,过程耗时;
射线l的方向不再由权重求和方法中的权重向量λ决定,而是由离散得到的决策者偏好向量决定。射线l的方向携带了决策者对目标函数的比例偏好信息。
由上可知,决策者的比例关系区间偏好向量集合pi所对应的有效解集可以通过求解n个优化模型所示的标量优化问题得到。因此,通过优化模型,对带有比例关系区间偏好信息的多目标决策模型所示的带有区间比例偏好的多目标决策优化进行了分解和重构,更重要的是将决策者的偏好信息引入到优化模型中,来引导并收敛到有效解。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤三中对步骤二重构后的分解模型进行求解,得到带有比例关系区间偏好信息的多目标决策模型的优化解的具体过称为:
本发明对zhang提出的moea/d进行改进,将上述重构模型中分解得到的偏好信息引入到整个算法的优化过程中,提出了基于moea/d的偏好引导多目标决策算法,求解重构后的优化模型。
对moea/d的改进如下所示:
moea/d中,权重向量λ是随机产生且不携带本发明介绍的两种区间偏好,它不能够引导优化过程收敛到满足决策者偏好的有效解。因此通过优化模型,将重构模型中离散得到的偏好向量引入到优化过程中,来引导整个优化过程收敛到满足决策者偏好的有效解,从而避免由后验方法带来的不足,简化整个决策过程;
moea/d中,射线l是从参考点z*产生的,对于z*的确定常常是十分耗时的,且z*的位置对求解获得的pf有很大的影响(射线l是从z*产生的,射线之间的最大夹角为90度)。通过式优化模型,将原点作为参考点,来产生满足决策者偏好的射线l,它减少了整个算法对于需要确定参考点的计算量,更重要的是它的位置对于需要求解获得的有效解没有影响。
差值关系区间偏好可以转化为比例关系(单位比例)区间偏好,因此以带有比例关系区间偏好的多目标决策模型的求解为例,介绍整个算法。
设λ1,...,λn为由决策者的偏好信息均匀分解得到的n个决策者偏好向量。对于带有比例关系区间偏好信息的多目标决策模型的求解,可以通过将其分解为n个如下式所示的标量优化模型来解决,其中第i个偏好向量λi对应的标量优化模型如下:
其中,λi是决策者的第i个偏好向量。
由上式可知
在moea/dp中,每一个偏好向量λi都会从pi={λ1,λ2,...,λn}中根据偏好向量之间的euclidean距离选择相邻的几个偏好向量作为邻域偏好向量集bi。当前种群包含n个偏好信息所对应的标量(子)优化问题目前为止找到的最优值。
输入:
多目标决策优化模型f(x);
终止条件:最大迭代次数m;
n个均匀分布的分解偏好信息pi={λ1,λ2,...,λn};
bi中偏好向量的个数t;
步骤三一:初始解生成:
步骤三一一:清空输出数据集ep;
步骤三一二:计算pi中任意两个偏好向量的欧几里得(euclidean)距离,确定b(i)={i1,...,it}(i=1,...,n),其中
步骤三一三:随机产生n个初始解:x1,x2,...,xn,并计算每个初始解对应的f值;
步骤三二:更新n个初始解:
步骤三二一:复制:随机从b(i)中选择两个指数k、l,则xk和xl确定为父解,对两个父解进行交叉和变异,产生一个新的解y;
步骤三二二:更新邻域偏好集对应的解:对于bi中所有的指数j,若
步骤三二三:更新ep:移除ep中被f(y)控制的劣解;如果ep中没有个体优于f(y),则将f(y)添加进ep;否则不进行添加操作;f(y)为y对应的目标函数值(把y带入多目标决策优化模型中得到的值);
步骤三二四:迭代执行步骤步骤三二一至步骤三二三,直至n个偏好向量求解完毕;
步骤三三:迭代执行步骤三一至步骤三二,直至达到最大迭代次数m后,输出ep。
由上可知,moea/dp将分解的决策者偏好信息λi(i=1,...,n)引入到整个优化过程中,使解集沿着各个偏好向量λi(i=1,...,n)收敛到决策者需要的有效解(满意解),避免了采用传统多目标优化方法需要采用后验方法从大量的pareto非劣解集中选择出有效解的不足。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:步骤三中每一次迭代中保存以下数据:
初始种群:x1,x2,...,xn,其中xi是子优化问题
fs1,fs2,...,fsn:其中fsi是解xi的f值,即fsi=f(xi)(i=1,...,n);
输出数据集ep:用来存储优化过程中发现的非劣解。
其它步骤及参数与具体实施方式一至四之一相同。
实施例一:
选取被广泛使用的5个2目标zdt测试函数集和2个3目标dtlz测试函数集对moea/dp进行测试。为了验证moea/dp求解的结果不仅是带有偏好的多目标决策问题的非劣解而且是满足决策者偏好的有效解,运用moea/d并结合一个后验方法对选取的测试函数进行了求解,并将两者求解的结果进行了比较。
(a)多目标测试函数集
zdt1
x=(x1,...,xn)t∈[0,1]n,n=30
zdt2
x=(x1,...,xn)t∈[0,1]n,n=30
zdt3
x=(x1,...,xn)t∈[0,1]n,n=30
zdt4
x=(x1,...,xn)t∈[0,1]×[-5,5]n-1,n=10
zdt6
x=(x1,...,xn)t∈[0,1]n,n=10
dtlz1
minimize{f1(x)=(1+g(x))x1x2,f2(x)=(1+g(x))x1(1-x2),f3(x)=(1+g(x))(1-x1)}
x=(x1,...,xn)t∈[0,1]n,n=10
fi≥0,i=1,2,3.
dtlz2
x=(x1,...,xn)∈[0,1]×[-1,1],n=10
fi≥0,i=1,2,3.
由上可知,选择的原始测试函数是不带有区间偏好信息的,因此对于选择的5个zdt测试函数分别引入比例关系区间偏好0.5≤f2/f1≤1,对于选择的2个dtlz测试函数分别引入比例关系区间偏好0.5≤f2/f1≤1,0.5≤f3/f1≤1。
(b)算法参数设置
moea/dp和moea/d的参数设置为:初始种群规模:n=100;终止条件:对于zdt测试函数最大迭代次数500,dtlz测试函数最大迭代次数1500;步骤三二一中采用的是二进制交叉和多项式变异的方法,交叉和变异分布指数都设置为20,交叉因子设置为1.0,变异因子设置为1/v,其中v表示多目标决策模型中的变量个数;邻域偏好向量集的大小t设置为20;式(15)中的惩罚系数θ设置为20。
(c)实验结果
图3-图15分别表示的是上述测试函数在带有比例关系区间偏好下的优化结果。
由图3-图15可知,moea/d和moea/dp在zdt1和zdt2上的收敛效果相似,但在zdt3、zdt4、zdt6、dtlz1和dtlz2上,moea/d的表现效果不如moea/dp,这主要由于moea/dp将原点替代为moea/d中的z*。表1为moea/d和moea/dp求解带有比例关系偏好测试函数的有效解个数对比。
表1moea/d和moea/dp求解带有比例关系偏好测试函数的有效解个数对比
由表1可知,在相同的初始种群下,moea/d获得的满足决策者的有效解远不如moea/dp。这意味着为了得到更多的有效解,moea/d需要加大初始种群的大小,而这将加大算法的计算量。
由表1可知,在相同的初始种群下,moea/d获得的满足决策者的有效解远不如moea/dp,特别是在dtlz1和dtlz2上。这意味着为了得到更多的有效解,moea/d需要加大初始种群的大小,而这将加大算法的计算量。
由上述结果可知,moea/dp获得的解不仅是带有比例区间偏好的多目标决策问题的非劣解而且是满足决策者偏好的有效解,它避免了采用后验方法在解决多目标决策问题时的不足。更重要的是,当决策者的比例区间偏好信息可以具体的表达为有限个偏好向量时,moea/dp通过单次运行就可以直接获得所有的满足决策者偏好的有效解。
以带有差值偏好的两个机队剩余寿命决策优化模型作为实例来对本发明提出的算法进行验证。实例中,两个机队的剩余寿命分别为160和190小时,两个机队的剩余寿命都接近耗尽需要进行检修。由于需要机队进行常规执勤以及维修资源的限制,因此通常需要通过任务的安排使两个机队的剩余寿命之比为一个模糊的比例区间关系,以有利于资源的调度和运营成本的控制。两个机队需要协同完成4项训练任务,每项训练任务由不同的训练科目组成,且完成各单位训练科目需要的时间不同。如表2所示为任务1、2、3和4下执行各科目每次训练需要的时间。
表2
其中,任务1包括:ts1、ts2和ts3三个科目;任务2包括:ts4和ts5两个科目;任务3包括:ts6、ts7和ts8三个科目;任务4包括:ts9和ts10两个科目。两个机队分别需要执行任务1、2、3和4各10次。10次任务可以通过选择不同组合和不同量的训练科目来完成。决策者对于两个机队剩余寿命的偏好表现为:2.5≤f2/f1≤3。两个机队剩余寿命决策优化模型表示如下
maximize{f1(ts)=160-5ts1-4ts2-3.2ts3-3.9ts4-2.7ts5-2.5ts6-3.5ts7-4ts8-4.2ts9-2.8ts10,
f2(ts)=190-3ts1-3.5ts2-4.1ts3-3ts4-4ts5-4.2ts6-3.7ts7-2.8ts8-3ts9-3.7ts10}
s.t.ts={ts1,ts2,ts3,ts4,ts5,ts6,ts7,ts8,ts9,ts10}
ts1+ts2+ts3=10,ts4+ts5=10,ts6+ts7+ts8=10,ts9+ts10=10
2≤ts1,1≤ts2,2≤ts3,3≤ts4,5≤ts5
4≤ts6,3≤ts7,2≤ts8,1≤ts9,2≤ts10
35≤f2-f1≤45
其中,ts表示各训练科目的训练量,是模型的变量;f1、f2分别表示机队1和2的剩余寿命。
如图16为上述模型偏好向量在区间[2.5,3]内均匀的取100个下的优化结果。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!