一种针对光场阵列相机的盲深度超分辨率计算成像方法与流程
本发明涉及图像处理、超分辨重建、光场计算成像领域,特别是一种针对光场阵列相机的盲深度超分辨率计算成像方法。
背景技术:
近几年来,基于光场和计算成像理论的光场相机成为了研究的热点。它通过采集现实世界的光场,在单次曝光中就可以获得当前场景的三维信息,通过对采集到的数据进行处理,可以实现拍照后重聚焦、场景深度估计以及三维重建等诸多传统相机无法实现的功能。光场相机有多种结构,其中阵列相机每一个成像单元相对独立而且分辨率较高,如果能够进一步采取其他方法继续提高其分辨率,便可以很大程度上提升光场成像的应用价值,促进光场相机的进一步发展。
为提高成像分辨率,主要有两个思路。从硬件角度提高分辨率难度较大,成本较高。光场阵列相机通过从不同视角对当前同一场景进行拍摄,可以获得当前场景的冗余信息,更适合于采用超分辨技术等软件方法来提高合成图像的分辨率。
传统的图像超分辨方法往往基于全图的一致性位移。在光场图像中,不同深度的物体对应阵列相机子图像中的位移是不同的。对于距离相机较近的物体,其视差较大,聚焦到此物体时需要对子图像的位移量也较大;而对于距离相机较远的物体,聚焦时所需要的位移也较小。针对光场图像这一特殊性质,学者们对传统超分辨方法做出了一些改进,形成了光场超分辨这一领域。
在光场超分辨中,绝大部分方法都需要基于场景的先验深度信息,并基于深度信息来获取子图像不同位置的位移值。计算较为复杂而且在一些深度信息复杂的场景中,超分辨的精度无法得到保证。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种针对光场阵列相机的盲深度超分辨率计算成像方法,针对光场阵列相机子图像的深度性质,改进传统超分辨全局一致性位移的约束,在当前场景深度信息未知的前提下,对场景进行超分辨率计算成像。
为解决上述技术问题,本发明所采用的技术方案是:一种针对光场阵列相机的盲深度超分辨率计算成像方法,其特征在于,包括以下步骤:
1)将阵列相机获得的子图像进行计算聚焦,并且在计算聚焦的同时提高目标图像网格的分辨率,获得聚焦到某一深度的高分辨率图像的初始值;通过改变阵列相机子图像之间的位移值,获得聚焦到不同深度的当前场景的图像;
2)对应某个位移值,判断子图像之间相同位置像素的方差值,通过映射θ=exp{-0.1×v0.9},将方差值v转化为迭代过程中修正矩阵中对应位置的权值θ;
3)建立如下目标函数,采用最小化l2范数和tv正则:
xi=xi+pi
其中k=1,2,3,...,p代表图像帧数;xi为原始场景中第i层深度聚焦部分对应的向量;pi为原始场景中第i层深度非聚焦部分对应的向量;xi为xi与pi的组合,对应着高分辨率的聚焦区域以及均匀模糊的非聚焦区域;yk代表低分辨率图像序列中第k帧图像向量;d表示下采样矩阵;h表示对应的模糊矩阵;fi,k为对应于第k帧、第i层深度的位移矩阵;其中j(xi)为正则化项,λ为正则化系数,有
式中ω为图像空间,
采用以下公式,使用梯度下降法求解超分辨问题:
式中,
式中,θ为步骤2)中各个像素点修正权值θ组成的修正向量,符号
通过计算当前点的梯度,沿梯度的反方向更新高分辨率图像的估计值,再计算新的估计值处的梯度,如此迭代,得到在聚焦区域具有超分辨效果,在非聚焦区域均匀模糊的一系列聚焦到不同深度的多聚焦高分辨率图像;
4)采用基于静态小波(swt)分解的多聚焦图像融合方法对步骤3)得到的聚焦到不同深度的高分辨率图像进行融合。
步骤1)中,采用三次样条插值的方法获得聚焦到某一深度的高分辨率图像的初始值。与现有技术相比,本发明所具有的有益效果为:本发明可以使光场阵列相机在实现其特有的诸多功能的基础上,在不改变其硬件结构与增加硬件成本的条件下,显著提高其成像的空间分辨率。随着光场相机的不断推广与普及,本发明方法有着较大的意义与实用价值。
附图说明
图1为光场相机盲深度超分辨率计算成像算法结构框图;
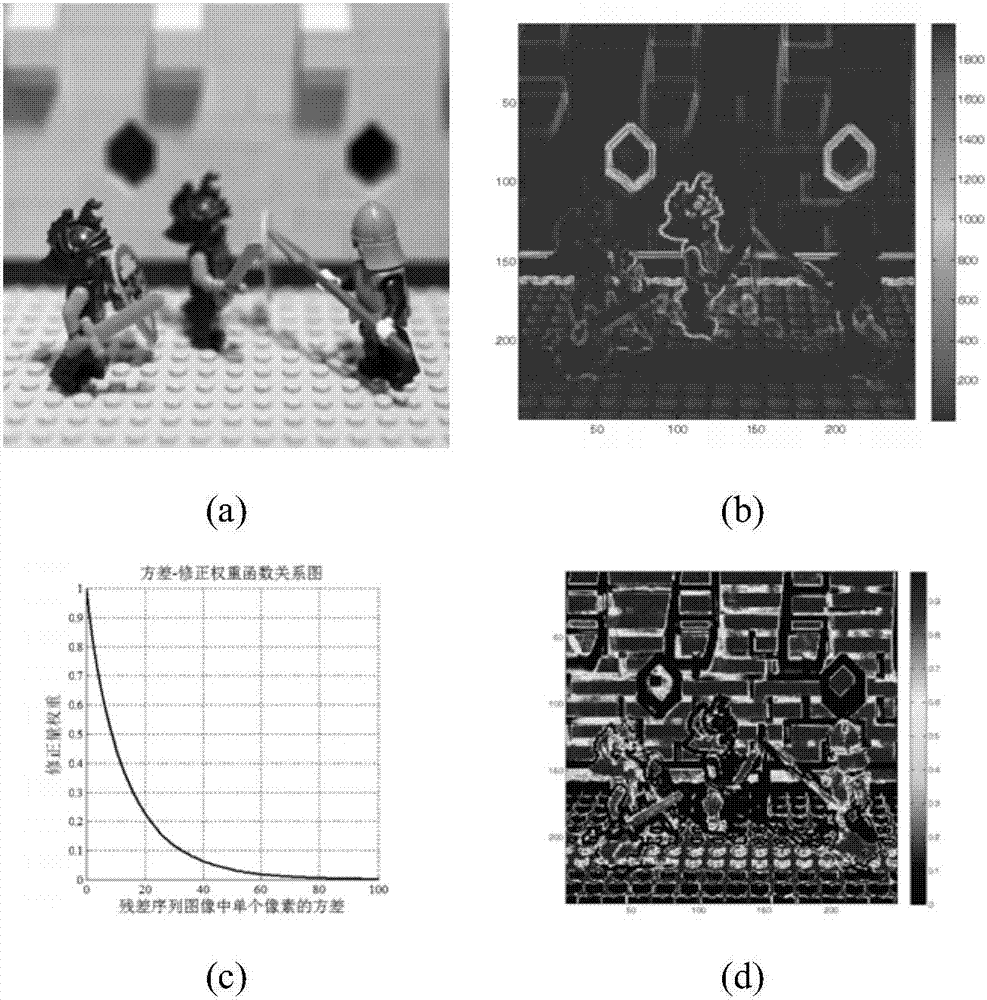
图2中,(a)聚焦到某一深度(两边的人)的插值重聚焦图像;(b)利用像素方差得出的当前场景各个像素重聚焦方差图;(c)像素方差与修正权值之间函数关系图;(d)当前场景各个像素修正权值图;
图3为基于静态小波分解的多聚焦图像融合框架图。设待分解的多聚焦源图像为in(n=1,2,...,n),经过静态小波分解为k层,每层均包含有近似系数a,水平细节系数h,垂直细节系数v和对角细节系数d。假定多帧源图像in的尺寸均为p×q,由于静态小波变换中没有下采样过程,故每一层的分解系数的尺寸也均为p×q。不同的分解系数采用不同的规则进行整合,将整合过后的系数进行静态小波逆变换,最终得到输出的融合图像;
图4为本发明实验效果图:(a)为斯坦福大学光场数据集“legoknights”图片的实验结果;(b)为斯坦福大学光场数据集“tarotcards”图片的实验结果;(c)为使用leica相机在实验室拍摄得到的实验结果;(d)为使用手机自带相机在实验室拍摄得到的实验结果;每一个场景分为两行两列,第一行为全图,第二行为第一行中标出的细节放大图,第一列为单帧低分辨率图像,第二列为通过本方法得到的超分辨重建结果。
具体实施方式
本发明利用正则化超分辨方法,误差项采用最小l2范数,正则项采用全变分正则,在重聚焦的同时进行超分辨率计算成像。由于一次重聚焦只能使得某一深度附近的物体处于聚焦状态,本方法能够通过比较聚焦时不同子图像同一位置的像素的方差来判断该像素是否处在聚焦区域,从而在迭代时赋予聚焦区域与非聚焦区域的修正量以不同的权值,在保证聚焦区域达到超分辨成像的效果下,防止非聚焦区域因位移不对应而产生病态结果。最后利用多聚焦图像融合技术将聚焦到不同深度的超分辨图像进行融合,最终得到当前场景的全景深高分辨率的图像。如图1所示,具体包括以下步骤:
1.将阵列相机获得的子图像进行计算聚焦,并且在计算聚焦的同时提高目标图像网格的分辨率,采用三次样条插值的方法获得聚焦到某一深度的高分辨率图像的初始值。通过改变阵列相机子图像之间的位移值,采用相同的方法,可以获得聚焦到不同深度的当前场景的图像。
2.在聚焦的过程中,对应某个位移值,判断子图像之间相同位置像素的方差值,通过映射θ=exp{-0.1×v0.9},将方差值v转化为迭代过程中修正矩阵中对应位置的权值θ,使得方差较小的聚焦区域能够获得比较大的权值,从而尽快收敛到高分辨率的结果,同时使方差较大的非聚焦区域获得比较小的权值,防止其收敛到病态的结果。
3.建立如下目标函数,采用最小化l2范数和tv正则
采用以下公式,使用梯度下降法求解超分辨问题,并将第2步中的修正权值体现在迭代过程中,
经过迭代可以得到在聚焦区域具有超分辨效果,在非聚焦区域均匀模糊的一系列聚焦到不同深度的多聚焦高分辨率图像。
4.采用基于静态小波分解的多聚焦图像融合算法对第3步得到的聚焦到不同深度的高分辨率图像进行融合,如图3所示。
经过以上算法,得到超分辨重建前后效果对比图如图4所示。
- 还没有人留言评论。精彩留言会获得点赞!