一种基于IMM滤波器主动防御视线策略协同制导律设计方法与流程
本发明涉及基于imm滤波器主动防御视线策略协同制导律。
背景技术:
在飞行器突防问题中,提高飞行器的突防能力,降低被对方防御飞行器拦截的概率是一个具有重大意义的问题。由于按弹道飞行的飞行器在中段飞行时机动能力差,容易被对方拦截,因此研究提高该类飞行器的突防能力十分重要。
为了提高飞行器的突防能力,目前采用了电子干扰,隐身技术,释放诱饵,采用中段和末段制导,多弹头攻击,机动变轨等多种方式。这些方法可归结为被动防御技术。与此相对,飞行器也可以在大气层外释放防御性飞行器。防御飞行器与突防飞行器同速伴飞,当发现对方拦截飞行器时通过末制导律与其碰撞,提高目标的突防概率。这种方式称为主动防御技术,相对于被动防御技术具有更大的优势。
为了描述方便,后续内容统一称突防的飞行器为evader,对方拦截飞行器为pursuer,保护evader的飞行器为defender。
目前对该问题的研究集中在使用mmae滤波方法对pursuer的制导律进行辨识,然后为defender设计拦截pursuer的最优制导律。这类方法存在以下问题。mmae滤波方法属于静态多模型方法,不能很好处理pursuer运动模型变化的情况。而在实际问题中,pursuer有可能会在不同的制导阶段采用不同的导航常数,导致运动模型发生变化;使mmae滤波方法在这种情况下制导精度降低。
技术实现要素:
本发明的目的是为了解决现有技术中对方拦截飞行器pursuer会在不同的制导阶段采用不同的导航常数,导致运动模型发生变化,使mmae滤波方法在这种情况下制导精度降低的问题,而提出基于imm滤波器主动防御视线策略协同制导律设计方法。
一种基于imm滤波器主动防御视线策略协同制导律设计方法具体过程为:
步骤一、建立pursuer运动模型;
pursuer运动模型包括相对于evader的pursuer运动模型以及相对于defender的pursuer运动模型;
所述pursuer为对方拦截飞行器,evader为飞行器,defender为保护evader的飞行器;
步骤一一、建立evader和pursuer的相对运动方程及defender和pursuer的相对运动方程;
步骤一二、基于步骤一一建立相对于evader的pursuer运动模型;
步骤一三、基于步骤一一建立相对于defender的pursuer运动模型;
步骤二、基于步骤一中建立的pursuer运动模型,设计evader上的imm滤波器和defender上的kalmanfilter滤波器;
所述imm滤波器为交互式多模型滤波器;kalmanfilter滤波器为卡尔曼滤波器;
步骤二一、基于步骤一二中建立的相对于evader的pursuer运动模型,设计evader上的imm滤波器;
步骤二二、基于步骤一三中建立的相对于defender的pursuer运动模型,设计defender上的kalmanfilter滤波器;
步骤三、基于步骤一建立的pursuer运动模型,步骤二设计的evader上的imm滤波器,defender上的kalmanfilter滤波器和supertwisting控制器,建立基于imm滤波器的supertwisting视线制导律;
所述supertwisting为鲁棒高阶滑模。
本发明的有益效果为:
本发明提出的方法采用基于imm(交互式多模型)滤波方法,并在此基础上提出基于imm滤波器主动防御视线策略协同制导律,对pursuer采用pn制导律的运动模型进行了更为准确的建模。可以很好的解决pursuer在制导过程中导航常数变化,导致运动模型发生变化的情况。另外本发明采用基于视线策略的制导方法,使用supertwisting滑模控制方法设计主动防御制导律,缓解了抖振问题,进一步提高了制导精度。
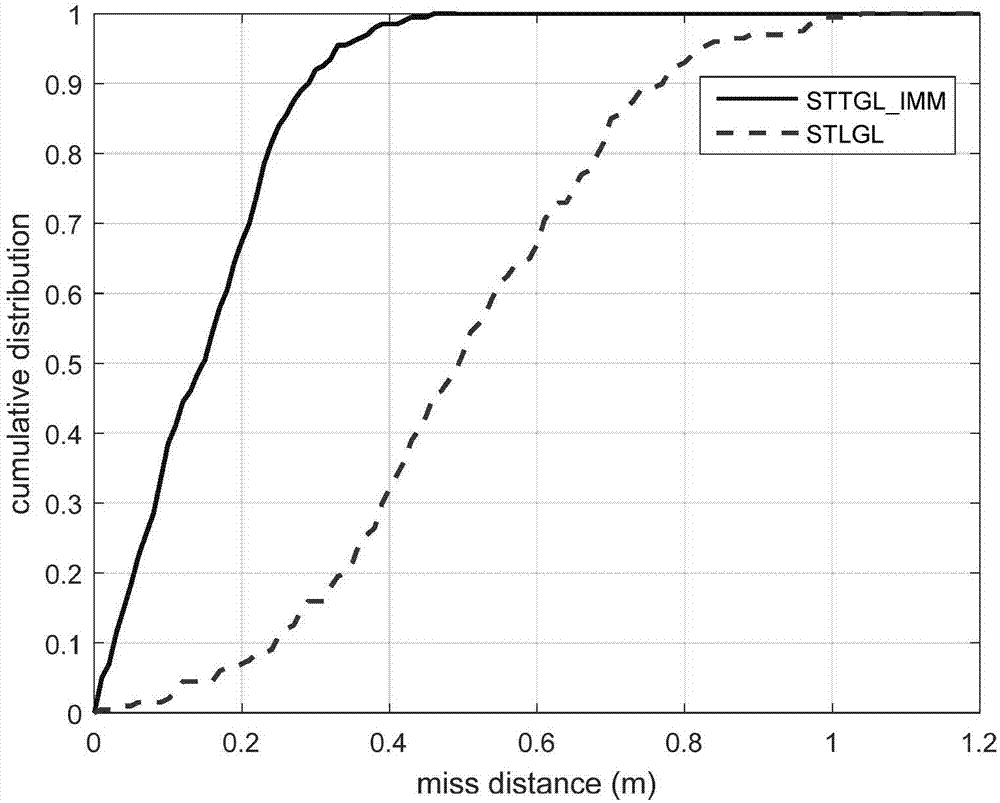
如图2和3给出了defender的脱靶量累积分布结果。对于碰撞杀伤拦截问题,脱靶量累积分布函数是一个十分重要的性能指标。如图2evader执行正弦机动时,现有制导律(简称stlgl)脱靶量小于0.4m的概率是0.3,本发明基于supertwisting的视线制导律(简称tstgl_imm)脱靶量小于0.4m的概率是0.99,本发明概率大于现有制导律(简称stlgl)的概率,曲线越陡峭,制导性能就越好,当evader执行正弦机动时,制导律tstgl_imm脱靶量累积分布曲线比tslgl制导律更加陡峭。这说明制导律tstgl_imm平均脱靶量相比tslgl制导律有很大幅度的减少。因此在该情况下,制导律tstgl_imm性能要优于tslgl制导律。而当evader不执行机动时,两种制导律的脱靶量累积分布曲线大致一样。并且两者的脱靶量都小于evader执行正弦机动的情况。这是因为当拦截不执行机动的目标时,pursuer需要的加速度很小。反过来机动很小的pursuer同样也很容易被defender拦截。
附图说明
图1为evader,pursuer和defender的相对运动关系图;
图2为脱靶量累积分布比较(evader执行正弦机动)图,横坐标为脱靶量,纵坐标为概率;
图3为脱靶量累积分布比较(evader不执行机动)图;
图4为defender的加速度比较(evader执行正弦机动)图;
图5为defender加速度比较(evader不机动)图。
具体实施方式
具体实施方式一:本实施方式的一种基于imm滤波器主动防御视线策略协同制导律设计方法具体过程为:
步骤一、建立pursuer运动模型;
pursuer运动模型包括相对于evader的pursuer运动模型以及相对于defender的pursuer运动模型;
所述pursuer为对方拦截飞行器,evader为目标飞行器,defender为保护evader的飞行器;
步骤一一、建立evader和pursuer的相对运动方程及defender和pursuer的相对运动方程;
步骤一二、基于步骤一一建立相对于evader的pursuer运动模型;
步骤一三、基于步骤一一建立相对于defender的pursuer运动模型;
步骤二、基于步骤一中建立的pursuer运动模型,设计evader上的imm滤波器和defender上的kalmanfilter滤波器;
所述imm滤波器为交互式多模型滤波器;kalmanfilter滤波器为卡尔曼滤波器;
步骤二一、基于步骤一二中建立的相对于evader的pursuer运动模型,设计evader上的imm滤波器;
步骤二二、基于步骤一三中建立的相对于defender的pursuer运动模型,设计defender上的kalmanfilter滤波器;
步骤三、基于步骤一建立的pursuer运动模型,步骤二设计的evader上的imm滤波器和defender上的kalmanfilter滤波器和supertwisting控制器,建立基于imm滤波器的supertwisting视线制导律;
所述supertwisting为鲁棒高阶滑模。
一种基于imm滤波器主动防御视线策略协同制导律设计方法最终求的是公式49表达的制导律形式。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一一中建立evader和pursuer的相对运动方程及defender和pursuer的相对运动方程;具体过程为:
定义场景惯性坐标系oxy为飞行器evader的初始视线坐标系;图1显示了evader,pursuer和defender在平面上的相对运动关系。
飞行器evader,对方拦截飞行器pursuer和保护evader的飞行器defender分别用e,p和d表示;
evader惯性坐标系和defender惯性坐标系与场景惯性坐标系重合;pursuer惯性坐标系原点和y轴与场景坐标系重合,pursuer惯性坐标系x轴方向和场景惯性坐标系x轴方向相反;
ve为evader的速度向量,ae为evader的加速度向量,qep为evader到pursuer的视线角;类似的,vp为pursuer的速度向量,ap为pursuer的加速度向量,qpe为pursuer到evader的视线角;ap1为加速度ap在pursuer对evader的视线坐标系y轴上的投影,ap2为加速度ap在defender对pursuer的视线坐标系y轴上的投影;rpe为pursuer到evader的距离,rdp为defender到pursuer的距离;vd为defender的速度向量,ad为defender的加速度向量,qdp为defender到pursuer的视线角;
建立evader和pursuer的相对运动方程为:
其中
建立defender和pursuer的相对运动方程为:
其中
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤一二中基于步骤一一建立相对于evader的pursuer运动模型;具体过程为:
假设pursuer采用pn制导律拦截evader。我们称在这种情况下pursuer的运动为pn运动模型。设相对于evader的pursuer状态向量为
xe=[rx,e,ry,e,vx,e,vy,e,apx,apy]t(3)
其中rx,e为evader相对于pursuer的相对位置向量在场景惯性坐标系下沿x轴的分量,ry,e为evader相对于pursuer的相对位置向量在场景惯性坐标系下沿y轴的分量;vx,e为evader相对于pursuer的相对速度向量在场景惯性坐标系下沿x轴的分量,vy,e为evader相对于pursuer的相对速度向量在场景惯性坐标系下沿y轴的分量,apx为pursuer在场景惯性坐标系x轴下的加速度,apy为pursuer在场景惯性坐标系y轴下的加速度,t为转置;
即
rx,e=xp-xery,e=yp-ye(4)
vx,e=vpx-vexvy,e=vpy-vey(5)
其中向量[xp,yp]t为pursuer在场景惯性坐标系下的位置,[xe,ye]t为evader在场景惯性坐标系下的位置,向量[vpx,vpy]t为pursuer在场景惯性坐标系下的速度,[vex,vey]t为evader在场景惯性坐标系下的速度;
相对于evader的pursuer运动模型的一般形式为
其中
设ap4y为pursuer的制导指令,当pursuer使用pn制导律时,ap4y的表达式为
其中常数n为导航常数;考虑到在末制导阶段,导弹的推力发动机关闭,因此导弹纵向加速度接近于零,即ap4x=0;
向量[ap4x,ap4y]t和[apx,apy]t的关系为
其中矩阵c40,p为坐标转换矩阵,将pursuer视线坐标系的向量转换为pursuer惯性坐标系下分量,c40p值为
其中矩阵cps为坐标系转换矩阵,将pursuer惯性坐标系转换为场景惯性坐标系;根据之前提到的pursuer惯性坐标系和场景惯性坐标系的关系,cps值为
将式(9)和(10)代入式(8),得
pursuer和evader的视线角速度关系为
其中
将式(12)和(13)代入式(11),得
evader到pursuer的视线角qep和距离为
其中rep为evader到pursuer的距离;
对式(15)取时间的导数,得
另外
将式(16)和(17)代入式(14),得
将式(18)代入式(6),得相对于evader的pursuer运动模型:
式(19)就是从evader角度看关于pursuer的pn运动模型。
假设evader可以能测量pursuer在场景惯性坐标系下相对自己的位置,则式(19)的测量矩阵为
滤波器需要系统模型(即运动模型)和测量模型(即测量矩阵)。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述参数τ取值为0.1。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤一三中基于步骤一一建立相对于defender的pursuer运动模型;具体过程为:
defender的制导律需要的一些参数无法直接测量,因此滤波器设计是制导律设计的重要一环。假定pursuer的加速度估计值可以通过通信链路从evader的滤波器得到,因此defender只需要估计相对位置和相对速度向量;
设相对于defender的pursuer的状态向量为
xd=[rx,d,ry,d,vx,d,vy,d,apx,apy]t(21)
其中rx,d和ry,d分别为defender相对于pursuer的距离在场景惯性坐标系沿x轴和y轴的分量;vx,d和vy,d分别是defender相对于pursuer的速度在场景惯性坐标系沿x轴和y轴的分量,即
xx,d=xp-xdry,d=yp-yd(22)
vx,d=vpx-vdxvy,d=vpy-vdy(23)
其中向量[xp,yp]t为pursuer在场景惯性坐标系下的位置;[xd,yd]t为defender在场景惯性坐标系下的位置;向量[vpx,vpy]t为pursuer在场景惯性坐标系下的速度;[vdx,vdy]t为defender在场景惯性坐标系下的速度;
相对于defender的pursuer运动模型为:
向量[adx,ady]t为defender在场景惯性坐标系下的加速度;
向量[apx,apy]t由evader滤波器提供的估计值
上述系统为线性时不变系统,适合采用线性kalman滤波器估计。
类似的,假定defender也可以测量pursuer在场景惯性坐标系下相对自己的位置,则式(25)的测量矩阵为
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是:所述步骤二一中基于步骤一二中建立的相对于evader的pursuer运动模型,设计evader上的imm滤波器;具体过程为:
类似于其他多模型滤波器,imm滤波器有一个模型集,包含了被跟踪目标所有可能的运动模型。每个pursuer运动模型对应于一个滤波器(例如kf,ukf或ukf等),该滤波器称为元滤波器。因此滤波器的模型集对应一组元滤波器。imm滤波器的估计为其元滤波器估计值的模型概率加权和。模型概率表征各个模型和目标实际运动模型的匹配程度。
假设imm滤波器的模型集为m={m1,…,mn},其中mj代表第j个pursuer运动模型;在我们的问题中,模型集中的模型都是pn运动模型,其导航常数各不相同(见式(19));模型mj的先验概率为
设
其中fj(k,xk-1),hj(k,xk),
imm滤波算法是一个迭代式的算法,每次迭代处理可以分为三个步骤:混合,滤波和融合。
现对k时刻的迭代处理描述如下
1)、求解k时刻imm滤波算法混合输入和混合协方差矩阵;
混合是指在一次迭代中每个元滤波器根据上一次迭代的估计状态和协方差矩阵来计算当前的元滤波器的初始状态和协方差矩阵。
其中
最终k时刻imm滤波算法混合输入和混合协方差矩阵计算公式为
其中
2)、对1)得到的
采用1)得到的混合输入和混合协方差矩阵作为输入,每个ukf元滤波器都执行一次滤波迭代。滤波处理又分为两个子步骤:状态预测和状态更新
其中函数ukfp(·)为状态预测函数,ukfu(·)为状态更新函数;
其中
3)、基于2)得到k时刻imm滤波算法最终状态估计和协方差矩阵(融合);
最终状态估计和协方差矩阵为
c为归一化常数。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是:所述步骤二二中基于步骤一三中建立的相对于defender的pursuer运动模型,设计defender上的kalmanfilter滤波器;过程为:
由于从defender的角度来看,pursuer的运动模型是一个线性时不变系统,因此采用线性kalman滤波器就可以很好的解决系统状态估计问题。
将式(25)重新写成矩阵形式
式(34)状态转移矩阵为
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是:所述步骤三中基于步骤一建立的pursuer运动模型,步骤二设计的evader上的imm滤波器,defender上的kalmanfilter滤波器和supertwisting控制器,建立基于imm滤波器的supertwisting视线制导律;具体过程为:
supertwisting滑模控制器优势在于可以很好的缓解控制抖振,该控制方法在很多应用中得到了应用。本节首先介绍supertwisting滑模控制理论。然后推导一种使用基于视线制导策略的基于supertwisting滑模控制的制导律。所谓基于视线制导策略是指defender保持在evader和pursuer的视线上。这样可以保证pursuer在拦截evader之前先和defender相撞,从而达到保护evader的目的。
步骤三一、建立supertwisting控制器(公式40);
考虑如下单输入单输出系统为:
其中
设σ为一指定的滑模变量,使得单输入单输出系统的输入u输出σ动态的相对阶为1;
则
其中对任意x,t有b(x,t)≠0;
设
假定函数
其中δ为一已知正常数;
目标是在存在有界的外部不确定情况下,设计一个滑模控制律使得滑模变量σ在有限时间内趋于0并尽可能消除抖振。supertwisting控制就是一种可选的方法,定义
其中α>0,β=2εα+λ+4ε2,且ε>0,λ>0.
据式(40),滑模变量的动态为
步骤三二、基于步骤一建立的pursuer运动模型,步骤二设计的evader上的imm滤波器和defender上的kalmanfilter滤波器和步骤三一建立的supertwisting控制器,建立基于imm滤波器的supertwisting视线制导律;(公式49)
所述supertwisting为鲁棒高阶滑模;
本发明所提出的基于supertwisting的视线制导律简称tstgl_imm。在该制导律中,defender保持在evader和pursuer的视线上。
defender为了保持处于evader和pursuer的视线上,视线角qpe和qdp应该满足如下关系
qpe+qdp=0(42)
设e=qpe+qdp,并设滑模变量为
e为视线角qpe和qdp的加和;
对σ1取时间的导数,得
将式(1)和(2)代入式(44),得
其中
defender的制导策略是努力处于evader和pursuer的视线上,这使得evader和pursuer的视线坐标系接近平行。上述两个视线坐标系近似平行,使得加速度up1和up2这两个加速度值很接近,因此参数up2可由up1替换。因此,式(45)写为
其中
imm滤波器的估计误差为
kalman滤波器的估计误差为
上述两个误差就是式(46)的不确定性;由于imm滤波器和kalman滤波器的有效性,上述不确定性十分小,因此可以使用一个很小的不确定性界。进一步,小的不确定性界的使用使得抖振可以有效的缓解。因此,这种不确定性估计和补偿可以有效的缓解抖振。
设f=δe1+δd1和
其中
f为imm滤波器的估计误差;
常数c1大于零,常数α1和β1的选择与式(40)中参数α,β选择相同;将等式
其它步骤及参数与具体实施方式一至七之一相同。
实施例一:
本实施例一种基于imm滤波器主动防御视线策略协同制导律具体是按照以下步骤制备的:
仿真结果及讨论
仿真场景中包含三个飞行器分别为:evader,pursuer和defender。首先给出了仿真环境配置和初始条件。接着将本发明提出的sttgl_imm制导律和不含imm滤波器的标准supertwisting滑模制导律进行了比较。在evader不执行机动或执行正弦机动两种场景下进行仿真;每种场景均执行了一个200次的montecarlo仿真。
仿真环境配置及初始条件
evader和pursuer的初始距离为100km。将evader的初始视线坐标系作为场景惯性坐标系。在场景惯性系下,evader初始位置为[0,0]tm,pursuer的初始位置为[105,0]tm。在montecarlo仿真中,pursuer每次仿真中具体的初始位置设置为上述位置加上一个在[-1000,1000]tm范围均匀分布的随机偏移。defender的初始位置在evader的附近,设置为[5000,0]tm。evader和defender的初始速度均为6000m/s,pursuer的初始速度为2500m/s。evader的初始飞行角γe为-5deg。pursuer和defender的初始飞行角设置为满足初始瞄准误差为3deg。evader和pursuer的最大加速度分别为2g和6g。
考虑到需要比较不同制导律对defender机动能力的需求,在仿真中defender的机动能力是一个很大的值,以保证defender不饱和。假设evader和defender均能测量pursuer的相对位置。采样周期为0.015秒。测量噪声为零均值高斯白噪声,方差为25m2。
pursuer采用pn制导律拦截evader,由于之前提到的原因,导航常数会随着距离而切换。初始的导航函数设置为3,当pursuer和evader的相对距离小于初始距离的一半时,导航函数切换为5。
制导律性能比较
为了评价提出的制导律的性能,使用了一个不含不确定性估计和补偿的标准制导律与所提制导律进行比较。该制导律(简称stlgl)采用零化对pursuer的视线角速度,因此设滑模变量为视线角速度,即
其中
设
其中
图2和图3给出了defender的脱靶量累积分布结果。对于碰撞杀伤拦截问题,脱靶量累积分布函数是一个十分重要的性能指标。如图2evader执行正弦机动时,现有制导律(简称stlgl)脱靶量小于0.4m的概率是0.3,本发明基于supertwisting的视线制导律(简称tstgl_imm)脱靶量小于0.4m的概率是0.99,本发明概率大于现有制导律(简称stlgl)的概率,曲线越陡峭,制导性能就越好,当evader执行正弦机动时,制导律tstgl_imm脱靶量累积分布曲线比tslgl制导律更加陡峭。这说明制导律tstgl_imm平均脱靶量相比tslgl制导律有很大幅度的减少。因此在该情况下,制导律tstgl_imm性能要优于tslgl制导律。而当evader不执行机动时,两种制导律的脱靶量累积分布曲线大致一样。并且两者的脱靶量都小于evader执行正弦机动的情况。这是因为当拦截不执行机动的目标时,pursuer需要的加速度很小。反过来机动很小的pursuer同样也很容易被defender拦截。
图4和5显示了defender加速度在场景惯性坐标系下的分量。图4中,在制导的早期(大约第1秒),stlgl制导律的制导指令远大于tstgl_imm制导律的制导指令,这是因为stlgl制导律没有对不确定性进行估计和补偿。当然大的制导指令同时也能快速零化视线角速度,因此stlgl在成功零化视线角速度之后其制导指令保持小于tstgl_imm和stlgl_imm制导律的制导指令。另一方面,stlgl制导指令的抖振相比tstgl_imm和stlgl_imm制导律更加明显,这是因为不确定的界越大则滑模控制的切换项增益α2和β2越大,这就导致了更大的抖振。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!