一种基于Spark框架的支持向量机训练方法与流程
本发明涉及计算机技术领域,更具体地,涉及一种基于Spark框架的支持向量机训练方法。
背景技术:
支持向量机(Support Vector Machine,SVM)自出现以来,被大量地运用于信息安全、图像处理、模式识别,故障诊断、异常检测等领域。1999年,Tax,Scholkopf和Duin等人,提出2种One Class SVM算法,分别是基于超平面和基于超球体的One Class SVM。其中支持向量数据描述(support vector data description,SVDD)是用超球体进单类分类方法,其目标在于用训练数据来描述一个超球体作为分类的判别模型。
目前的常用的SVM模式识别与回归的软件包是python的scikit-learn和台湾林智仁教授的LIBSVM。其中,Scikit-Learn是基于python的机器学习模块,基于BSD开源许可证,这个项目最早由David Cournapeau在2007年发起的,目前也是由社区自愿者进行维护;LIBSVM是台湾大学林智仁教授等人开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,它不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验的功能。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
但随着数据量的指数级的增长,单机版内存和CPU的要求已经无法满足需求,对算法并行化的求解方法的需求越来越迫切。SMO算法求解支持向量数据描述(support vector data description,SVDD)需要计算多个二次规划问题而具有较高的运算复杂度,SVDD运行时间会随训练样本数量增加而急剧增大。存储核矩阵Kii所需要的内存是随着训练集中训练点数N的快速增长的,核矩阵的规模是样本数平方关系,直接将SVDD应用于数据异常检测会导致计算量过大和内存溢出问题。
技术实现要素:
为解决现有技术中,SMO算法求解SVDD需要计算多个二次规划问题而具有较高的运算复杂度,SVDD运行时间会随训练样本数量增加而急剧增大。直接将SVDD应用于数据异常检测会导致计算量过大和内存溢出问题,提出一种基于Spark框架的支持向量机训练方法。
本发明提供的方法包括:
S1,获取训练样本集,将所述训练样本集中的所有样本向量分布式储存在Spark框架的数据节点中;
S2,从所述训练样本集中抽取违反KKT条件最大的样本向量V2,同时选取与样本向量V2的球心距相差最大的样本向量V1;
S3,对所述样本向量V1和V2进行迭代优化计算,获得更新后的样本向量V1new和V2new;
S4,将所述更新后的样本向量V1new和V2new广播到所述Spark的数据节点中,在每个数据节点中计算所述样本向量V1和V2产生的差分,根据所述每个数据节点中计算的差分,计算获得更新后的球心anew;
S5,根据所述更新后的球心anew,更新所述Spark的数据节点中各个样本向量的球心距,同时更新球体半径R。
其中,所述步骤S1还包括:向每个所述数据节点读入对应的该数据节点中所述训练样本中的样本向量,对每一个所述样本向量生成一个唯一数据标识。
优选的,所述唯一数据标识由所述数据节点的分片区号和数据节点本地的时间戳组合而成。
其中,所述步骤S1中还包括初始化所述迭代优化计算所需的计算参数;其中,所述计算参数包括所有样本向量的拉格朗日乘子α、球心a和每个样本向量的球心距d2。
其中,所述初始化所述迭代优化计算的计算参数具体包括:
初始化所有样本向量的拉格朗日乘子α值为1/N;其中,N为所述训练样本集中所述样本向量的个数;
初始化球体半径的平方R2,使得R2=0;
根据以下公式初始化球心:
式中a为球心,αi和αj为所述训练样本集中任意两个样本向量,Kij为核函数;
根据公式计算出所述样本向量的球心距d2。
优选的,所述步骤S2中,从所述训练样本集中抽取违反KKT条件最大的样本向量V2的抽取类型为无放回抽取。
其中,所述步骤S2中选取与样本向量V2的球心距相差最大的样本向量V1具体包括:
对于任意一个所述数据节点,获取该数据节点中与所述样本向量V2的球心距相差最大的样本向量;
在Spark框架的Driver Program中根据每个所述数据节点中与所述样本向量V2的球心距相差最大的样本向量,获得与样本向量V2的球心距相差最大的样本向量V1。
其中,所述步骤S4中,计算获得更新后的球心anew的步骤,具体包括:在Spark框架的Driver Program中对所有数据节点中的计算得到的差分进行加总,计算获得新的球心anew。
其中,所述步骤S5之后还包括:根据更新后的所述各个向量的球心距和求半径R,去除界上样本向量,保留所有无界样例的样本向返回执行S1。
其中,所述步骤S5之后还包括,根据判断当所述训练样本集中所有样本向量的拉格朗日乘子都满足KKT条件或所述样本向量V1和V2的目标损失函数loss小于预设阈值时,停止训练。
本发明提供的方法,通过应用Spark分布式计算框架将单机计算密集工作分散到各个工作节点;将单机大量存储核矩阵Kii分散到各个数据节点,数据增加时,可以进行横向扩展,而计算时间由于工作点独立,不会明显增加;存储空间不受单机限制。另一方面,应用增量计算的方式将避免了每次迭代都要进行的全量计算方式节省大量计算指令周期,加快求解计算过程。
附图说明
图1为本发明一实施例提供的一种基于Spark框架的支持向量机训练方法的流程图;
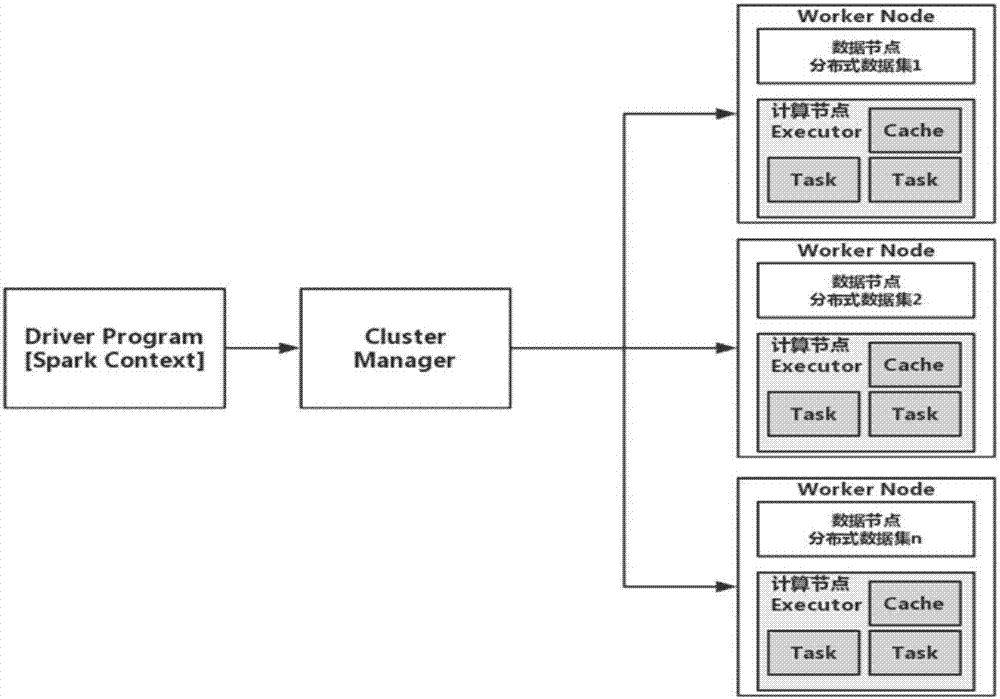
图2为本发明一实施例提供的一种基于Spark框架的支持向量机训练方法中Spark框架的结构图;
图3为本发明又一实施例提供的一种基于Spark框架的支持向量机训练方法的流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
参考图1,图1为本发明一实施例提供的一种基于Spark框架的支持向量机训练方法的流程图,所述方法包括:
S1,获取训练样本集,将所述训练样本集中的所有样本向量分布式储存在Spark框架的数据节点中。
具体的,在接收到训练样本集后,通过分布式存储,将样本集中的样本向量分布式存储在Spark框架下的数据节点中。
如图2所示,Apache Spark是专为大规模分布式数据分布式内存计算而设计的快速通用的引擎。是由加州大学伯克利分校的AMP实验室提供的开源的类Hadoop MapReduce的通用并行框架。Spark由于MapReduce Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。很多并行化算法都在Spark上有了实现。
通过此方法,将训练集中的样本向量分布式存储在多个数据节点中,数据增加时,可以进行横向扩展。
S2,从所述训练样本集中抽取违反KKT条件最大的样本向量V2,同时选取与样本向量V2的球心距相差最大的样本向量V1。
具体的,优化迭代过程采用SMO算法,即一次选择两个样本向量进行优化。一般标识两个进行优化的样本向量为V1和V2,根据选择的停止条件可以确定怎么样选择点能对算法收敛贡献最大,例如使用监视可行间隙的方法,首先优化那些最违反KKT条件的点作为V2,根据KKT条件,V1,V2的迭代关系可以确定为公式:
λ1=α1+α2-λ2
式中,K为核函数,α为拉格朗日乘子,d2为球心距。
为了使每次最大优化的更新步长最大,可见需要找到的最大值,即的最小值,从而找到V1。
S3,对所述样本向量V1和V2进行迭代优化计算,获得更新后的样本向量V1new和V2new。
S4,将所述更新后的样本向量V1new和V2new广播到所述多个Spark的数据节点中,在每个数据节点中计算所述样本向量V1和V2产生的差分,根据所述每个数据节点中计算的差分,计算获得更新后的球心anew。
S5,根据所述更新后的球心anew,更新所述Spark的数据节点中各个样本向量的球心距,同时更新球体半径R。
具体的,优化迭代过程采用SMO算法,根据One Class SVM模型最小超球体模型,目标函数公式为:
s.t.||Φ(xi)-a||2≤R2+ζ
ζi≥0
式中,中R为球体半径,a为球心,ζ为松弛变量。
求解以下公式二次规划问题,即可求得球心和半径。
根据图3的步骤更新所有参数,其中更新的参数包括V1,V2的拉格朗日乘子α参数;球心a,更新各个样本点向量的球心距球体半径R,具体步骤包括:根据以下公式跟新V1和V2的拉格朗日乘子α。
λ1=α1+α2-λ2
更新完V1和V2后,获得更新后的样本向量V1new和V2new,将V1、V2、V1new和V2new以及原球心a广播到Spark的每一个数据节点中,更新球心a,更新公式为:
式中,αi和αj为所述训练样本集中任意两个样本向量,Kij为核函数,由于只有V1,V2样本向量的参数α有变化,所以只有与特征向量V1和V2有关的特征向量的数据会有所变化,所以可以应用差分对a进行计算,具体公式如下:
式中,aold为原球心,anew为更新后的球心K为核函数。差分计算的过程在各个Spark的数据分片上进行分布式计算,并在Spark的Driver Program上进行加总。
在跟新了球心参数后,会对每个样本向量的球心距进行更新,通过应用差分公式:
可以实现对每个样本向量的球心距进行更新,式中为新的球心距,为原球心距,a为球心,K为核函数。此步骤在Spark的数据节点中进行分布式计算。
最后,还包括对球体半径R的更新,具体为,当V1和V2都为无界样例的时候,即ξ<αi<C时,ξ为接近0的小数,C为惩罚因子,则R的更新公式为:
当V1和V2都为界上样例的时候,即αi≤ξ,或者αi≥C的时候,则更新公式为:
通过此方法,应用Spark分布式计算框架将单机计算密集工作分散到各个工作节点;将单机大量存储核矩阵Kii分散到各个工作节点。数据增加时,可以进行横向扩展,计算时间由于工作点独立,不会明显增加;存储空间不受单机限制。另一方面,应用增量计算的方式将避免了每次迭代都要进行的全量计算方式节省大量计算指令周期,加快求解计算过程。
在上述实施例的基础上,所述步骤S1还包括:向每个所述数据节点读入对应的该数据节点中所述训练样本中的样本向量,对每一个所述样本向量生成一个唯一数据标识。
优选的,所述唯一数据标识由所述数据节点的分片区号和数据节点本地的时间戳组合而成。
具体的,在开始优化计算之前,当训练样本集中的所有样本向量分布式储存在Spark框架的数据节点中后,在各个数据节点上,会读入对应本地的数据块中的数据,每个样本向量会生成一个不重复随机数形成唯一数据标识id。由于一个训练样本集中的样本向量可能存在参数相同的情况,因此此处通过唯一数据标识id可对所有的样本向量进行区分。
优选的,id可以通过分片序号和本地的时间戳组合而成。数据唯一id可以用来区分中不同Executor上的具有相同的内存地址的样本向量。
在上述各实施例的基础上,所述步骤S1中还包括初始化所述迭代优化计算所需的计算参数;其中,所述计算参数包括所有样本向量的拉格朗日乘子α、球心a和每个样本向量的球心距d2。
优选的,所述初始化所述迭代优化计算的计算参数具体包括:
初始化所有样本向量的拉格朗日乘子α值为1/N;其中,N为所述训练样本集中所述样本向量的个数;
初始化球体半径的平方R2,使得R2=0;
根据以下公式初始化球心:
式中a为球心,αi和αj为所述训练样本集中任意两个样本向量,Kij为核函数;
根据公式计算出所述样本向量的球心距d2。
具体的,在迭代优化计算之前,首先对支持向量机的迭代计算参数进行初始化,首先初始化每个样本向量的拉格朗日乘子α,优选的,将初始值设置为1/N,其中,N为所述训练样本集中所有样本向量的个数。此过程为分布式计算,分别在各个数据节点上进行计算。
然后,初始化球体半径的平方R2,优选的,将球体半径的平方设置为0,即R2=0。
接着,根据以下公式初始化球心:
式中,a为球心,αi和αj为所述训练样本集中任意两个样本向量,为高斯核函数。
最后,根据公式:
计算出各个样本向量到球心a的距离d2,该步骤需要在数据集上进行全量计算,得出的结果储存在以样本向量为key的HashMap中。
在上述实施例的基础上,所述步骤S2中,从所述训练样本集中抽取违反KKT条件最大的样本向量V2的抽取类型为无放回抽取。
具体的,当抽取违反KKT条件最大的样本向量V2的时候,选择的是无放回抽取,使得在整个大的迭代周期内,所有样本被遍历。
在上述各实施例的基础上,所述步骤S2中选取与样本向量V2的球心距相差最大的样本向量V1具体包括:
对于任意一个所述数据节点,获取该数据节点中与所述样本向量V2的球心距相差最大的样本向量;
在Spark框架的Driver Program中根据每个所述数据节点中与所述样本向量V2的球心距相差最大的样本向量,获得与样本向量V2的球心距相差最大的样本向量V1。
具体的,如图3所示,在抽取了样本向量V2后,在Spark的每个数据节点中,分别找出在该数据节点中与样本向量V2的球心距相差最大的样本向量;其后,在Spark框架下的Driver Program中选取全局球心距相差最大的样本向量作为V1。
在上述各实施例的基础上,所述步骤S4中,计算获得更新后的球心anew的步骤,具体包括:在Spark框架的Driver Program中对所有数据节点中的计算得到的差分进行加总,计算获得新的球心anew。
具体的,如图3所示,当对所述样本向量V1和V2进行迭代优化计算,获得更新后的样本向量V1new和V2new后,将更新过后的V1和V2广播到Spark的每个数据节点后,会在每个数据节点中计算V1和V2变化后产生的差分,随后,在Spark框架的Driver Program中对所有数据节点中的计算得到的差分进行加总,计算获得新的球心anew。
在上述各实施例的基础上,所述步骤S5之后还包括:根据更新后的所述各个向量的球心距和球体半径R,去除界上样本向量,保留所有无界样例的样本向返回执行S1。
具体的,当一次迭代优化计算完成以后,重新选择下一组V1和V2,进行下一轮迭代计算,应用启发式选择方法,优先选择无界样例进行计算,其次优化界上样例。优选的,可以去除界上样例的所有样本向量,后续判别计算值需要用到无界样例的样本向量。
在上述各实施例的基础上,根据判断当所述训练样本集中所有样本向量的拉格朗日乘子都满足KKT条件或所述样本向量V1和V2的目标损失函数loss小于预设阈值时,停止训练。
具体的,所有点拉格朗日乘子ɑ都满足KKT条件或者到达一定迭代次数后优化目标损失函数loss小于一个预设阈值的时候,则认为优化近似达到KKT条件。此时可以停止训练。
通过此方法,当目标损失函数loss小于一个预设阈值的时候,则可以表明后续优化的效果已经不够明显了,此时停止训练,以减少整体的计算量。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!