一种面向海量高维数据的电站锅炉燃烧建模及优化的方法与流程
本发明属于电站锅炉的建模及优化运行领域,具体涉及一种针对海量高维数据的燃烧模型的建立和多目标优化控制的方法。
背景技术:
近年来,由于人工智能技术具有良好的非线性处理能力,已在电站锅炉的建模及优化领域得到了广泛的运用。该方法只需要从电厂分散控制系统(dcs)提取数据或根据锅炉燃烧调整优化试验的数据建立燃烧系统输入、输出模型,然后利用优化算法对锅炉效率和污染物排放进行优化,得到锅炉效率和污染物排放综合最优的运行参数,以指导电厂安全经济运行。目前,采用较多的是支持向量机(svm)和神经网络(ann)等智能算法,优化算法主要有遗传算法、粒子群算法、蚁群算法等。
文献“谷丽景,李永华,李路.电站锅炉燃烧优化混合模型预测[j].中国电机工程学报,2015,35(9):2231-2237”将人工神经网络引入到锅炉燃烧优化混合模型中,并将飞灰含碳、排烟温度以及nox排放量作为模型的输出,实验结果表明混合模型的性能明显优于单因素模型;文献“standerj,waltcvd,heynsc.newimmunemultiobjectiveoptimizationalgorithmanditsapplicationinboilercombustionoptimization[j].journalofsoutheastuniversity,2010,26(4):563-568”首先建立锅炉燃烧多目标模型,并以锅炉效率和nox排放量作为模型的输出,然后采用一种新颖的免疫细胞亚群的多目标优化算法(icsmoa)来优化模型,实验证明此多目标优化算法的优化结果优于传统的加权法优化结果;文献“zhao-xinm,chao-meiz,xiao-gangl,etal.researchonunburnedcombustibleforecastinflyashofthecoal-firedboilerbasedongeneticalgorithmandartificialneuralnetwork[c]//strategictechnology(ifost),20116thinternationalforumon.ieee,2011,2:1149-1152”则是采用遗传算法(ga)来优化锅炉燃烧多目标优化模型。然而上面的智能算法处理的都是电站锅炉的小样本数据,当处理海量高维数据时可能出现单机计算机资源不足的问题。
技术实现要素:
本发明的目的在于提供一种针对海量高维数据的燃烧建模及优化的方法,以解决在处理电站锅炉燃烧过程中产生的海量高维数据时,出现的单机计算机资源不足的问题。
本发明的技术方案为:
一种面向海量高维数据的电站锅炉燃烧建模及优化的方法,其特征在于,包括如下步骤:
1、从电厂分散控制系统的历史运行数据中提取输入数据和输出数据,并对输入数据、输出数据进行数据处理;
2、使用改进的分布式极限学习机对nox排放量建模为锅炉燃烧排放模型,对锅炉效率建模为锅炉燃烧效率模型;
锅炉燃烧排放模型为:
其中,wi=(ωi1,ωi2,...,ωin)t为锅炉燃烧排放模型的网络输入节点与第i个隐层节点间的输入权值向量,xj为锅炉燃烧排放模型的输入数据的第j维参量,bi为锅炉燃烧排放模型第i个隐层节点阈值,βi=(βi1,βi2,...,βin)t为连接锅炉燃烧排放模型第i个隐层节点与输出层节点间的输出权值向量,yj=(yj1,yj2,...,yjn)t表示锅炉燃烧排放模型网络输出值,l为锅炉燃烧排放模型的隐含节点数,g(·)为锅炉燃烧排放模型的隐层神经元激活函数,gi(·)为锅炉燃烧排放模型的第i个隐层节点的隐层神经元激活函数值,激活函数采用sigmoid函数;
锅炉燃烧效率模型为:
其中,w'i'=(ω'i'1,ω'i'2,...,ω'i'n)t为锅炉燃烧效率模型网络输入节点与第i'个隐层节点间的输入权值向量,x'j'为锅炉燃烧效率模型的输入数据的第j'维参量,b'i'为锅炉燃烧效率模型第i'个隐层节点阈值,β'i'=(β'i'1,β'i'2,...,β'i'n)t为连接锅炉燃烧效率模型第i'个隐层节点与输出层节点间的输出权值向量,y'j'=(y'j'1,y'j'2,...,y'j'n)t表示锅炉燃烧效率模型的网络输出值,l'为锅炉燃烧效率模型的隐含节点数,g'(·)为锅炉燃烧效率模型的隐层神经元激活函数,g'i'(·)为锅炉燃烧效率模型第i'个隐层节点的隐层神经元激活函数值,激活函数采用sigmoid函数;
3、将锅炉燃烧排放模型和锅炉燃烧效率模型合并建立多目标锅炉燃烧模型;
其中f(x(i))为优化目标,x(i)为第i个优化参数,
4、采用权重系数法将多目标锅炉燃烧模型转换成单目标锅炉燃烧模型;
其中
5、使用分布式粒子群算法对单目标锅炉燃烧模型进行参数寻优,实现对锅炉燃烧过程的优化控制。
步骤1中,所述输入数据为锅炉运行操控参数,所述输出数据为锅炉效率以及nox排放量。
所述的锅炉运行操控参数包括含氧量、一次风风速、二次风风速、二次风量、磨煤机给粉量、燃尽风挡板开度以及锅炉负荷。
步骤1中,所述数据处理是先将空的或者采集数据少于测点应有数据量的3%的电站锅炉测点剔除掉,然后将每个测点对应的数据中的空值采用线性插值的方法根据前后的值对数据进行补齐,并将异常值替换掉;最后把处理好的数据存储到分布式计算框架中的分布式文件系统中。
步骤2中,所述的使用改进的分布式极限学习机(idelm)建模模型为:
其中,wi=(ωi1,ωi2,...,ωin)t为网络输入节点与第i个隐层节点间的输入权值向量,xj为输入数据的第j维参量,bi为第i个隐层节点阈值,βi=(βi1,βi2,...,βin)t为连接第i个隐层节点与输出层节点间的输出权值向量,yj=(yj1,yj2,...,yjn)t表示网络输出值,l为的隐含节点数,g(·)为隐层神经元激活函数,gi(·)为第i个隐层节点的隐层神经元激活函数值,激活函数采用sigmoid函数;
若网络实际输出等于期望输出,则
式中tj表示网络期望输出的第j维输出值。
公式(6)中n个等式对应的矩阵表示为:
hβ=t(7)
其中
其中h为网络的隐含层输出矩阵,β为输出权值矩阵,t为目标输出矩阵。输出权值可通过公式(10)求解β的最小二乘解获得。
β=h+t(10)
其中h+表示隐含层输出矩阵h的穆尔-彭罗斯(moore-penrose)广义逆。
将正交投影法与岭回归理论应用于公式(10)中,对h+进行分解。若hth可逆,则h+=(hth)-1ht。
当训练样本很大的情况下,β可用如下公式表示:
在这种情况下,idelm的输出函数为:
式中h(x)为隐含层输出矩阵h的函数表达式,
通过在分布式计算框架(mapreduce)上实现idelm算法。
令s=hth,d=htt,可得:
利用分布式计算框架(mapreduce)的并行框架来实现s和d的计算。从而可摆脱单机环境里的计算和存储能力的束缚,实现对大规模训练数据的高效训练。
步骤2中,所述的建模过程为:
使用改进的分布式极限学习机(idelm)建立锅炉燃烧排放模型,根据电站实际测点数据,选取锅炉负荷(1项)、烟气含氧量(5项)、一次风风速(6项)、二次风风速(17项)、二次风量(10项)、排烟温度(1项)及煤质数据(3项)、磨煤机给粉量(6项)、燃尽风挡板开度参数(8项)共计57维参数作为模型的输入量,而以nox排放量作为模型的输出量。
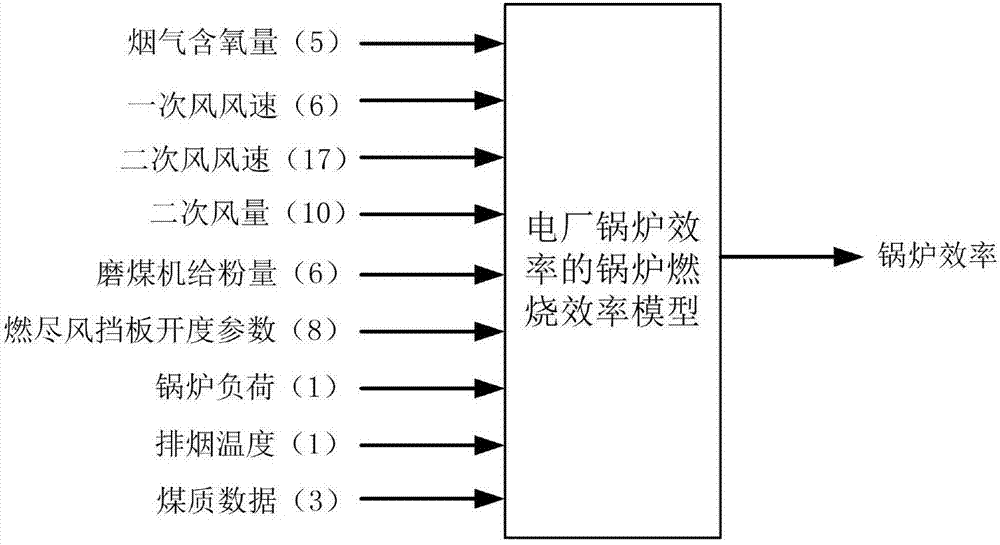
使用改进的极限学习机(idelm)建立锅炉燃烧效率模型。根据电站实际测点数据,选取锅炉负荷(1项)、烟气含氧量(5项)、一次风风速(6项)、二次风风速(17项)、二次风量(10项)、排烟温度(1项)及煤质数据(3项)、磨煤机给粉量(6项)、燃尽风挡板开度参数(8项)共计57维参数作为模型的输入量,而以锅炉效率作为模型的输出量。
步骤3中,所述的多目标锅炉燃烧模型的建模方式为:
建立好锅炉燃烧排放模型和锅炉燃烧效率模型两个模型之后,以最大化锅炉效率和最低化nox生成量作为锅炉燃烧多目标优化的两个目标函数。此时,锅炉燃烧的多目标优化问题可描述如下:
其中f(x(i))为优化目标,x(i)为第i个优化参数,
步骤4中,所述的单目标锅炉燃烧模型建立方式如下:
由于本发明优化的目标是找到nox排放量的最低值和燃烧效率的最高值,因此本发明采用nox排放量的优化目标与燃烧效率的优化目标相减的方式作为目标函数,使其实现目标优化的同向化。最后将两个目标函数按照一定权值比合并成一个综合目标函数,合并后的目标函数如下:
其中
步骤5中,所述的分布式粒子群(mr-pso)算法对单目标锅炉燃烧模型进行参数寻优的具体步骤如下:
(1)初始化阶段:初始种群的初始化范围,要根据采集的锅炉燃烧系统的实际运行数据进行确定,然后根据均匀分布函数在约束范围内随机产生n个粒子,将每个粒子依次代入适应度函数进行评估,等所有粒子都评估完以后,比较适应度值的大小选取所有粒子中最好的适应度值,并将其对应的粒子位置设置为全局最优位置。然后将全局最优粒子按照键值对的形式存储到分布式文件系统中。
(2)编程模型mapreduce阶段:根据上一代信息更新本代粒子群中位置、速度,然后作为下一次编程模型mapreduce任务的输入。
(3)条件判断阶段:这一阶段的主要任务是判断编程模型mapreduce的迭代次数是否满足最大迭代次数或其它约束条件,如果不满足则继续循环执行编程模型mapreduce任务,如果达到最大迭代次数或其它约束条件,则退出循环输出全局最优位置。
与现有技术相比,本发明具有以下优点,随着电厂智能化程度的加深,电厂系统数据的海量化、高维化趋势不可阻挡,本发明针对在处理海量高维电站锅炉燃烧系统数据上单机计算资源不足的问题,采用了当前处理大数据的hadoop并行计算技术,并使用hadoop中的mapreduce编程框架实现了极限学习机的分布式计算。并且提出了一种改进的分布式极限学习机(idelm)算法,对锅炉燃烧优化具有较好的控制效果。
附图说明
图1为本发明的电厂锅炉nox排放量的锅炉燃烧排放模型。
图2为本发明的电厂锅炉效率的锅炉燃烧效率模型。
图3为本发明的利用分布式粒子群(mr-pso)算法进行寻优的流程图。
具体实施方式
下面结合附图,进一步阐明本发明。
一种面向海量高维数据的电站锅炉燃烧建模及优化的方法,其具体步骤如下:
1、从电厂分散控制系统的历史运行数据中提取输入数据和输出数据,并对输入数据、输出数据进行数据处理;
2、使用改进的分布式极限学习机对nox排放量建模为锅炉燃烧排放模型,对锅炉效率建模为锅炉燃烧效率模型;
锅炉燃烧排放模型为:
其中,wi=(ωi1,ωi2,...,ωin)t为锅炉燃烧排放模型的网络输入节点与第i个隐层节点间的输入权值向量,xj为锅炉燃烧排放模型的输入数据的第j维参量,bi为锅炉燃烧排放模型第i个隐层节点阈值,βi=(βi1,βi2,...,βin)t为连接锅炉燃烧排放模型第i个隐层节点与输出层节点间的输出权值向量,yj=(yj1,yj2,...,yjn)t表示锅炉燃烧排放模型网络输出值,l为锅炉燃烧排放模型的隐含节点数,g(·)为锅炉燃烧排放模型的隐层神经元激活函数,gi(·)为锅炉燃烧排放模型的第i个隐层节点的隐层神经元激活函数值,激活函数采用sigmoid函数;
锅炉燃烧效率模型为:
其中,w'i'=(ω'i'1,ω'i'2,...,ω'i'n)t为锅炉燃烧效率模型网络输入节点与第i'个隐层节点间的输入权值向量,x'j'为锅炉燃烧效率模型的输入数据的第j'维参量,b'i'为锅炉燃烧效率模型第i'个隐层节点阈值,β'i'=(β'i'1,β'i'2,...,β'i'n)t为连接锅炉燃烧效率模型第i'个隐层节点与输出层节点间的输出权值向量,y'j'=(y'j'1,y'j'2,...,y'j'n)t表示锅炉燃烧效率模型的网络输出值,l'为锅炉燃烧效率模型的隐含节点数,g'(·)为锅炉燃烧效率模型的隐层神经元激活函数,g'i'(·)为锅炉燃烧效率模型第i'个隐层节点的隐层神经元激活函数值,激活函数采用sigmoid函数;
3、将锅炉燃烧排放模型和锅炉燃烧效率模型合并建立多目标锅炉燃烧模型;
其中f(x(i))为优化目标,x(i)为第i个优化参数,
4、采用权重系数法将多目标锅炉燃烧模型转换成单目标锅炉燃烧模型;
其中
5、使用分布式粒子群算法对单目标锅炉燃烧模型进行参数寻优,实现对锅炉燃烧过程的优化控制。
针对所应用锅炉的结构、燃烧器布置形式等特点选取合适的锅炉运行操控参数作为燃烧模型的输入量,锅炉nox排放量及锅炉效率为优化目标输出量,从而得到锅炉燃烧系统模型输入/输出数据。
所述的锅炉运行操控参数包括含氧量、一次风风速、二次风风速、二次风量、磨煤机给粉量、燃尽风挡板开度以及锅炉负荷等。
本发明具体实施的实验数据是从国电集团旗下某电站的pi实时数据库系统中采集的真实数据。数据处理方式为:首先将空的或者采集数据少于测点应有数据量的3%的电站锅炉测点剔除掉,然后将每个测点对应的数据中的空值采用线性插值的方法根据前后的值对数据进行补齐,并将异常值替换掉;采用线性插值的方法对数据进行补齐;最后把处理好的数据存储到分布式计算框架中的分布式文件系统中。
为保证模型的性能,在模型训练之前需要对样本进行归一化处理,具体归一化公式如下:
其中x是归一化前的原始样本,x*是归一化后的样本,xmax、xmin分别为原始样本中的最大值与最小值。
采用一种改进的分布式极限学习机(idelm)分别建立锅炉燃烧排放模型和锅炉燃烧效率模型。
如图1为电厂锅炉nox排放量的锅炉燃烧排放模型,调用数据库中必要的参数作为锅炉燃烧排放模型的输入。根据电站实际测点数据,选取锅炉负荷(1项)、烟气含氧量(5项)、一次风风速(6项)、二次风风速(17项)、二次风量(10项)、排烟温度(1项)及煤质数据(3项)、磨煤机给粉量(6项)、燃尽风挡板开度参数(8项)共计57维参数作为模型的输入量,而以锅炉效率作为模型的输出量。
用于建模的输入参数及表征nox排放量的输出参数表示为{(xi,ti)|i=1,2,…,n},其中xi=(xi1,xi2,…,xin)t∈rn,表示建模的输入参数;ti=(ti1,ti2,…,tim)∈rm,表示建模的输出参数。其中t表示转置,r为实数集合,m和n表示样本的特征维数;采用l个隐节点,隐含层节点的激活函数为g(·),其中激活函数采用“sigmoid”。锅炉燃烧排放模型的网络数学模型可描述为
其中,wi=(ωi1,ωi2,...,ωin)t为锅炉燃烧排放模型的网络输入节点与第i个隐层节点间的输入权值向量,xj为锅炉燃烧排放模型的输入数据的第j维参量,bi为锅炉燃烧排放模型第i个隐层节点阈值,βi=(βi1,βi2,...,βin)t为连接锅炉燃烧排放模型第i个隐层节点与输出层节点间的输出权值向量,yj=(yj1,yj2,...,yjn)t表示锅炉燃烧排放模型网络输出值,l为锅炉燃烧排放模型的隐含节点数,g(·)为锅炉燃烧排放模型的隐层神经元激活函数,gi(·)为锅炉燃烧排放模型的第i个层隐节点的隐层神经元激活函数值。
若网络实际输出等于期望输出,则
式中tj表示网络期望输出的第j维输出值。
公式(22)中n个等式对应的矩阵表示为:
hβ=t(23)
其中
其中h为网络的隐含层输出矩阵,β为输出权值矩阵,t为目标输出矩阵。输出权值可通过公式(26)求解β的最小二乘解获得。
β=h+t(26)
其中h+表示隐含层输出矩阵h的穆尔-彭罗斯(moore-penrose)广义逆。
将正交投影法与岭回归理论应用于公式(26)中,对h+进行分解。若hth可逆,则h+=(hth)-1ht。
当训练样本很大的情况下,β可用如下公式表示:
在这种情况下,idelm的输出函数为:
式中h(x)为隐含层输出矩阵h的函数表达式,
通过在分布式计算框架(mapreduce)上实现idelm算法。
令s=hth,d=htt,可得:
利用分布式计算框架(mapreduce)的并行框架来实现s和d的计算。从而可摆脱单机环境里的计算和存储能力的束缚,实现对大规模训练数据的高效训练。根据公式(24)有hij=g(wj·xi+bj)和
在公式(30)中,矩阵s中的元素sij可用hri和hrj乘积之和表示。其中hri是矩阵h的第r行的第i个元素,hrj是矩阵h的第r行的第j个元素。它们都来自矩阵h的第r行,hr·是同一组训练输入数据xr所计算出的隐藏层输出矩阵,与其它组训练数据无关。同理,公式(31)中hr·与tr·也与其它组训练数据无关。
由上面两式(30)和(31)可知s和d的计算过程是可分解的,因此我们可以充分利用mapreduce的并行框架来实现s和d的计算。从而可摆脱单机环境里的计算和存储能力的束缚,实现idelm对大规模训练数据的高效训练。
在训练模型前,需要先确定参数正则项1/a和隐含层节点l的值。这2个参数对模型的性能具有很大的影响,它们的确定属于最佳模型选择问题。本发明采用交叉验证法,通过不断调整1/a和l的值,选择使交叉验证误差最小的组合作为参数的最佳组合值。经计算,确定nox排放量模型和锅炉效率模型的参数1/a和l如表1所示。
表1锅炉燃烧模型参数选取
改进的分布式极限学习机的运算过程如下:首先随机生成l对隐含层节点参数(wi,bi),然后将输入的样本和随机生成的隐含层节点参数代入到分布式计算框架(mapreduce)中,计算出矩阵s和d。将s和d代入公式得到输出权值向量β,最后将β带入公式(28)预测新数据集的输出结果。
同样,我们可以建立电站锅炉效率的锅炉燃烧效率模型,如图2所示。调用数据库中必要的参数作为锅炉燃烧效率模型的输入,通过对数据进行预处理作为模型的训练和测试数据。根据电站实际测点数据,选取锅炉负荷(1项)、烟气含氧量(5项)、一次风风速(6项)、二次风风速(17项)、二次风量(10项)、排烟温度(1项)及煤质数据(3项)、磨煤机给粉量(6项)、燃尽风挡板开度参数(8项)共计57维参数作为模型的输入量,而以锅炉效率作为模型的输出量。
参照锅炉燃烧排放模型的建立方式建立锅炉燃烧效率模型。
使用改进的极限学习机(idelm)建立锅炉燃烧排放模型和锅炉燃烧效率模型后,以最大化锅炉效率和最低化nox生成量作为锅炉燃烧多目标优化的两个目标函数。最后采用优化算法对锅炉燃烧系统的可调输入参数进行优化。
此时,锅炉燃烧的多目标优化问题可描述如下:
其中f(x(i))为优化目标,x(i)为第i个优化参数,
在进行优化之前需要将这两个优化目标采用归一化的方式使其量纲达到同一数量级。在现实生活中各个电站对nox排放量和锅炉燃烧效率有不同的要求,故可将多目标函数中相关目标函数进行加权处理。由于本发明优化的目标是找到nox排放量的最低值和锅炉燃烧效率的最高值,因此本发明采用nox排放量与锅炉燃烧效率相减的方式作为目标函数,使其实现目标优化的同向化。最后将两个目标函数按照一定权值比合并成一个综合目标函数,合并后的目标函数如下:
其中
使用分布式粒子群(mr-pso)算法来优化锅炉燃烧模型输入参数,
设搜索空间ω中有d维解,粒子群中粒子个数为n,每个粒子都具有速度和位置两个向量。第i个粒子的位置为xi=(xi1,xi2,…,xid),速度为vi=(vi1,vi2,…,vid),经过迭代后知道目前第i个粒子的最好位置为
其中,速度和位置都是向量,公式中的i=1,2,…,n;
公式中的w采用一种线性减小的方案,具体公式如下:
式中,
利用分布式粒子群(mr-pso)算法进行寻优的流程图如图3所示,其具体操作步骤如下:
(1)在实际操作过程中,初始种群的初始化范围要根据本次采集的锅炉燃烧系统的实际运行数据进行确定,然后根据均匀分布函数在约束范围内随机产生n个粒子,并将其存储到分布式文件系统(hdfs)中;
(2)master主节点将分布式文件系统(hdfs)中的输入文件进行分片处理,将分片后的数据分配给映射(map)任务;
(3)映射(map)任务将输入的文件中的粒子信息进行分离提取,分别分离出粒子对应的速度与位置信息,并根据速度公式(34)和位置公式(35)对粒子的速度和位置进行更新,然后将更新粒子的位置信息带入锅炉燃烧的idelm模型中得到的预测结果再结合公式(33)得出适应度值。根据适应度评价值大小决定是否替换原有粒子速度、位置,并将其按一定顺序存储到分布式文件系统(hdfs)。将所有粒子与全局最优粒子进行比较,优于原值则替换它的值,并将其存储到分布式文件系统(hdfs)中,由此可得到映射(map)任务中的全局最优粒子;
(4)归约(reduce)的主要任务就是将之前每个映射(map)任务得出的局部全局最优粒子进行比较,得出整个粒子群的全局最优位置,并将其按键值对的形式存储到分布式文件系统(hdfs)中;
(5)归约(reduce)任务完成后,判断是否满足最大迭代次数,如果未满足最大迭代则重新返回步骤(3)的映射(map)任务,继续映射(map)任务直至满足最大迭代次数。
将迭代完成后最优结果所对应的各锅炉运行操控参数应用到实际电站锅炉运行过程中。
以上所述的仅是本发明的优选实施方式,本发明不限于以上实例。可以理解,本领域技术人员在不脱离本发明的精神和构思的前提下直接导出或联想到的其他改进和变化,均应认为包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!