MISO全格式无模型控制器基于系统误差的参数自整定方法与流程
本发明属于自动化控制领域,尤其是涉及一种MISO全格式无模型控制器基于系统误差 的参数自整定方法。
背景技术:
MISO(Multiple Input and Single Output,多输入单输出)系统的控制问题,一直以来都 是自动化控制领域所面临的重大挑战之一。
MISO控制器的现有实现方法中包括MISO全格式无模型控制器。MISO全格式无模型控 制器是一种新型的数据驱动控制方法,不依赖被控对象的任何数学模型信息,仅依赖于MISO 被控对象实时测量的输入输出数据进行控制器的分析和设计,并且实现简明、计算负担小及 鲁棒性强,对未知非线性时变MISO系统也能够进行很好的控制,具有良好的应用前景。MISO 全格式无模型控制器的理论基础,由侯忠生与金尚泰在其合著的《无模型自适应控制—理论 与应用》(科学出版社,2013年,第118页)中提出,其控制算法如下:
其中,u(k)为k时刻的控制输入向量,u(k)=[u1(k),…,um(k)]T,m为控制输入个数, Δu(k)=u(k)-u(k-1);e(k)为k时刻的系统误差;Δy(k)=y(k)-y(k-1),y(k)为k时刻 的系统输出实际值;为k时刻的MISO系统伪分块梯度估计值的行矩阵,为行矩 阵的第i块行矩阵(i=1,…,Ly+Lu),为行矩阵的2范数;λ为惩罚因子, ρ1,…,ρLy+Lu为步长因子,Ly为控制输出线性化长度常数,Lu为控制输入线性化长度常数。
然而,MISO全格式无模型控制器在实际投用前需要依赖经验知识来事先设定惩罚因子λ 和步长因子ρ1,…,ρLy+Lu等参数的数值,在实际投用过程中也尚未实现惩罚因子λ和步长因子 ρ1,…,ρLy+Lu等参数的在线自整定。参数有效整定手段的缺乏,不仅使MISO全格式无模型控 制器的使用调试过程费时费力,而且有时还会严重影响MISO全格式无模型控制器的控制效 果,制约了MISO全格式无模型控制器的推广应用。也就是说:MISO全格式无模型控制器 在实际投用过程中还需要解决在线自整定参数的难题。
为此,为了打破制约MISO全格式无模型控制器推广应用的瓶颈,本发明提出了一种 MISO全格式无模型控制器基于系统误差的参数自整定方法。
技术实现要素:
为了解决背景技术中存在的问题,本发明的目的在于,提供一种MISO全格式无模型控 制器基于系统误差的参数自整定方法。
为此,本发明的上述目的通过以下技术方案来实现,包括以下步骤:
步骤(1):针对具有m个输入(m为大于或等于2的整数)与1个输出的MISO(Multiple Input and Single Output,多输入单输出)系统,采用MISO全格式无模型控制器进行控制;确 定MISO全格式无模型控制器的控制输出线性化长度常数Ly,Ly为大于或等于1的整数;确 定MISO全格式无模型控制器的控制输入线性化长度常数Lu,Lu为大于或等于1的整数;所 述MISO全格式无模型控制器参数包含惩罚因子λ和步长因子ρ1,…,ρLy+Lu;确定MISO全格 式无模型控制器待整定参数,所述MISO全格式无模型控制器待整定参数,为所述MISO全 格式无模型控制器参数的部分或全部,包含惩罚因子λ和步长因子ρ1,…,ρLy+Lu的任意之一或 任意种组合;确定BP神经网络的输入层节点数、隐含层节点数、输出层节点数,所述输出 层节点数不少于所述MISO全格式无模型控制器待整定参数个数;初始化所述BP神经网络 的隐含层权系数、输出层权系数;
步骤(2):将当前时刻记为k时刻;
步骤(3):基于系统输出期望值与系统输出实际值,采用系统误差计算函数计算得到k 时刻的系统误差,记为e(k);将所述系统误差及其函数组、系统输出期望值、系统输出实际 值的任意之一或任意种组合,放入集合{系统误差集};
步骤(4):将步骤(3)得到的所述集合{系统误差集}作为BP神经网络的输入,所述 BP神经网络进行前向计算,计算结果通过所述BP神经网络的输出层输出,得到所述MISO 全格式无模型控制器待整定参数的值;
步骤(5):基于步骤(3)得到的所述系统误差e(k)、步骤(4)得到的所述MISO全格 式无模型控制器待整定参数的值,采用MISO全格式无模型控制器的控制算法,计算得到 MISO全格式无模型控制器针对被控对象在k时刻的控制输入向量u(k)=[u1(k),…,um(k)]T;
步骤(6):针对步骤(5)得到的所述控制输入向量u(k)中的第j个控制输入uj(k) (1≤j≤m),计算所述第j个控制输入uj(k)分别针对各个所述MISO全格式无模型控制器待 整定参数在k时刻的梯度信息,具体计算公式如下:
当所述MISO全格式无模型控制器待整定参数中包含惩罚因子λ且Lu=1时,所述第j个 控制输入uj(k)针对所述惩罚因子λ在k时刻的梯度信息为:
当所述MISO全格式无模型控制器待整定参数中包含惩罚因子λ且Lu>1时,所述第j个 控制输入uj(k)针对所述惩罚因子λ在k时刻的梯度信息为:
当所述MISO全格式无模型控制器待整定参数中包含步长因子ρi且1≤i≤Ly时,所述第 j个控制输入uj(k)针对所述步长因子ρi在k时刻的梯度信息为:
当所述MISO全格式无模型控制器待整定参数中包含步长因子ρLy+1时,所述第j个控制 输入uj(k)针对所述步长因子ρLy+1在k时刻的梯度信息为:
当所述MISO全格式无模型控制器待整定参数中包含步长因子ρi且Ly+2≤i≤Ly+Lu且 Lu>1时,所述第j个控制输入uj(k)针对所述步长因子ρi在k时刻的梯度信息为:
其中,Δuj(k)=uj(k)-uj(k-1),Δy(k)=y(k)-y(k-1),y(k)为k时刻的系统输出实际值, 为k时刻的MISO系统伪分块梯度估计值的行矩阵,为行矩阵的第i块行矩 阵(i=1,…,Ly+Lu),为行矩阵的第j个梯度分量估计值,为行矩阵 的2范数;
上述全部所述梯度信息的集合记为{梯度信息j},放入集合{梯度信息集};
针对步骤(5)得到的所述控制输入向量u(k)中的其他m-1个控制输入,重复执行本步 骤,直至所述集合{梯度信息集}包含全部{{梯度信息1},…,{梯度信息m}}的集合,然后进入 步骤(7);
步骤(7):以系统误差函数的值最小化为目标,采用梯度下降法,结合步骤(6)得到 的所述集合{梯度信息集},进行系统误差反向传播计算,更新BP神经网络的隐含层权系数、 输出层权系数,作为后一时刻BP神经网络进行前向计算时的隐含层权系数、输出层权系数;
步骤(8):所述控制输入向量u(k)作用于被控对象后,得到被控对象在后一时刻的系 统输出实际值,返回到步骤(2),重复步骤(2)到步骤(8)。
在采用上述技术方案的同时,本发明还可以采用或者组合采用以下进一步的技术方案:
所述步骤(3)中的所述系统误差计算函数的自变量包含系统输出期望值与系统输出实际 值。
所述步骤(3)中的所述系统误差计算函数采用e(k)=y*(k)-y(k),其中y*(k)为k时刻 设定的系统输出期望值,y(k)为k时刻采样得到的系统输出实际值;或者采用 e(k)=y*(k+1)-y(k),其中y*(k+1)为k+1时刻的系统输出期望值,y(k)为k时刻采样得 到的系统输出实际值。
所述步骤(3)中的所述系统误差及其函数组,包含k时刻的系统误差e(k)、k时刻及之 前所有时刻的系统误差的累积即k时刻系统误差e(k)的一阶后向差分e(k)-e(k-1)、 k时刻系统误差e(k)的二阶后向差分e(k)-2e(k-1)+e(k-2)、k时刻系统误差e(k)的高阶 后向差分的任意之一或任意种组合。
所述步骤(7)中的所述系统误差函数的自变量包含系统误差、系统输出期望值、系统输 出实际值的任意之一或任意种组合。
所述步骤(7)中的所述系统误差函数为其中,e(k)为系统误差, Δuj(k)=uj(k)-uj(k-1),bj为大于或等于0的常数,1≤j≤m。
本发明提供的MISO全格式无模型控制器基于系统误差的参数自整定方法,能够实现良 好的控制效果,并有效克服惩罚因子λ和步长因子ρ1,…,ρL需要费时费力进行整定的难题。
附图说明
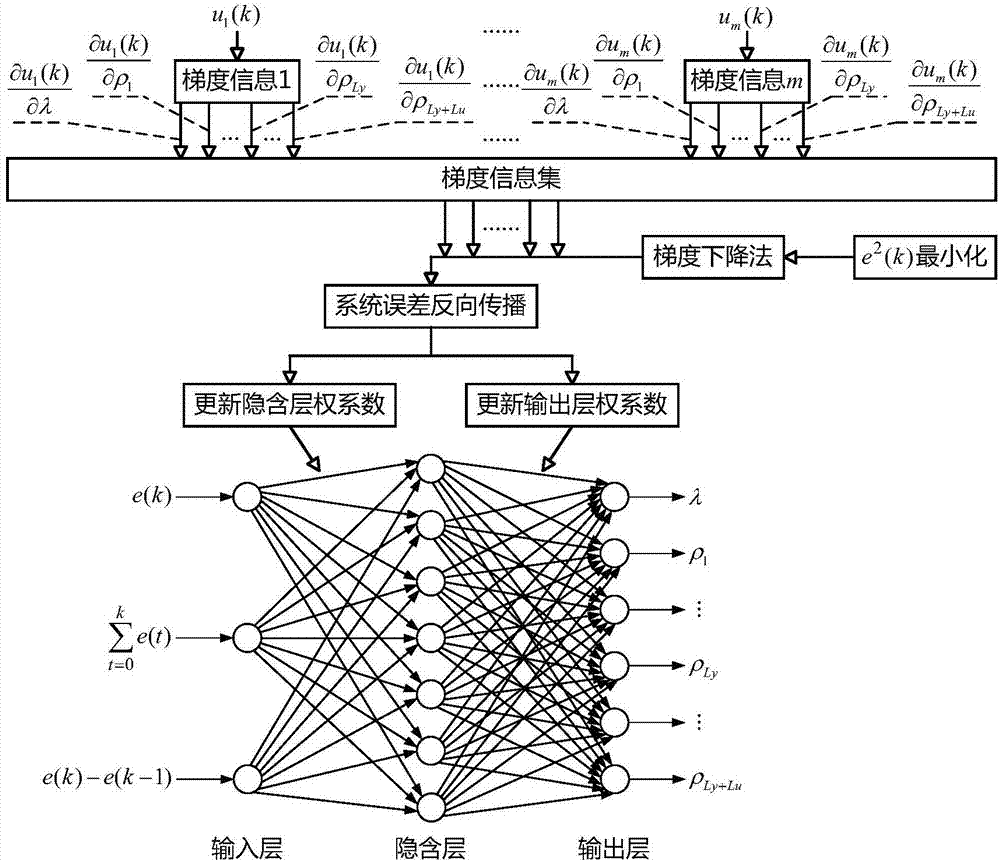
图1为本发明的原理框图;
图2为本发明采用的BP神经网络结构示意图;
图3为两输入单输出MISO系统在惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4同时自整定时的 控制效果图;
图4为两输入单输出MISO系统在惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4同时自整定时的 控制输入图;
图5为两输入单输出MISO系统在惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4同时自整定时的 惩罚因子λ变化曲线;
图6为两输入单输出MISO系统在惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4同时自整定时的 步长因子ρ1,ρ2,ρ3,ρ4变化曲线;
图7为两输入单输出MISO系统在惩罚因子λ固定而步长因子ρ1,ρ2,ρ3,ρ4自整定时的 控制效果图;
图8为两输入单输出MISO系统在惩罚因子λ固定而步长因子ρ1,ρ2,ρ3,ρ4自整定时的 控制输入图;
图9为两输入单输出MISO系统在惩罚因子λ固定而步长因子ρ1,ρ2,ρ3,ρ4自整定时的 步长因子ρ1,ρ2,ρ3,ρ4变化曲线。
具体实施方式
下面结合附图和具体实施例对本发明进一步说明。
图1给出了本发明的原理框图。针对具有m个输入(m为大于或等于2的整数)与1个 输出的MISO系统,采用MISO全格式无模型控制器进行控制;确定MISO全格式无模型控 制器的控制输出线性化长度常数Ly,Ly为大于或等于1的整数;确定MISO全格式无模型控 制器的控制输入线性化长度常数Lu,Lu为大于或等于1的整数;MISO全格式无模型控制器 参数包含惩罚因子λ和步长因子ρ1,…,ρLy+Lu;确定MISO全格式无模型控制器待整定参数, 其为所述MISO全格式无模型控制器参数的部分或全部,包含惩罚因子λ和步长因子 ρ1,…,ρLy+Lu的任意之一或任意种组合;在图1中,MISO全格式无模型控制器待整定参数为 惩罚因子λ和步长因子ρ1,…,ρLy+Lu;确定BP神经网络的输入层节点数、隐含层节点数、输 出层节点数,其中输出层节点数不少于MISO全格式无模型控制器待整定参数个数;初始化 所述BP神经网络的隐含层权系数、输出层权系数。
将当前时刻记为k时刻;将系统输出期望值y*(k)与系统输出实际值y(k)之差作为k时 刻的系统误差e(k),然后将k时刻的系统误差e(k)、k时刻及之前所有时刻的系统误差的累 积即k时刻系统误差e(k)的一阶后向差分e(k)-e(k-1)的组合,放入集合{系统误 差集};将集合{系统误差集}作为BP神经网络的输入,BP神经网络进行前向计算,计算结果 通过BP神经网络的输出层输出,得到MISO全格式无模型控制器待整定参数的值;基于所 述系统误差e(k)、所述MISO全格式无模型控制器待整定参数的值,采用MISO全格式无模 型控制器的控制算法,计算得到MISO全格式无模型控制器针对被控对象在k时刻的控制输 入向量u(k)=[u1(k),…,um(k)]T;针对控制输入向量u(k)中的第j个控制输入uj(k) (1≤j≤m),计算所述第j个控制输入uj(k)分别针对各个所述MISO全格式无模型控制器待 整定参数在k时刻的梯度信息,并将全部所述梯度信息的集合记为{梯度信息j},放入集合{梯 度信息集};针对控制输入向量u(k)中的其他m-1个控制输入,重复执行直至集合{梯度信 息集}包含全部{{梯度信息1},…,{梯度信息m}}的集合;随后,结合所述集合{梯度信息集}, 以系统误差函数的值最小化为目标,图1中以e2(k)最小化为目标,采用梯度下降法,进行系 统误差反向传播计算,更新BP神经网络的隐含层权系数、输出层权系数,作为后一时刻BP 神经网络进行前向计算时的隐含层权系数、输出层权系数;控制输入向量u(k)作用于被控对 象后,得到被控对象在后一时刻的系统输出实际值,然后重复执行本段落所述的工作,进行 后一时刻的MISO全格式无模型控制器基于系统误差的参数自整定过程。
图2给出了本发明采用的BP神经网络结构示意图。BP神经网络可以采用隐含层为单层 的结构,也可以采用隐含层为多层的结构。在图2的示意图中,为简明起见,BP神经网络采 用了隐含层为单层的结构,即采用由输入层、单层隐含层、输出层组成的三层网络结构,输 入层节点数设为3个,隐含层节点数设为7个,输出层节点数设为待整定参数个数(图2中 待整定参数个数为Ly+Lu+1个)。输入层的3个节点,与系统误差e(k)、系统误差的累积 系统误差e(k)的一阶后向差分e(k)-e(k-1)分别对应。输出层的节点,与惩罚因子 λ和步长因子ρ1,…,ρLy+Lu。BP神经网络的隐含层权系数、输出层权系数的更新过程具体为: 以系统误差函数的值最小化为目标,图2中以e2(k)最小化为目标,采用梯度下降法,结合所 述集合{梯度信息集},进行系统误差反向传播计算,从而更新BP神经网络的隐含层权系数、 输出层权系数。
以下是本发明的一个具体实施例。
被控对象为典型非线性的两输入单输出MISO系统:
系统输出期望值y*(k)如下:
y*(k)=(-1)round((k-1)/100)
在本具体实施例中,m=2。
MISO全格式无模型控制器的控制输出线性化长度常数Ly的数值通常根据被控对象的复 杂程度和实际的控制效果进行设定,一般在1到5之间,过大会导致计算量大,所以一般常 取1或3,在本具体实施例中Ly取为1;MISO全格式无模型控制器的控制输入线性化长度 常数Lu的数值也通常根据被控对象的复杂程度和实际的控制效果进行设定,一般在1到10 之间,过小会影响控制效果,过大会导致计算量大,所以一般常取3或5,在本具体实施例 中Lu取为3。
BP神经网络采用由输入层、单层隐含层、输出层组成的三层网络结构,输入层节点数设 为3个,隐含层节点数设为7个,输出层节点数设为待整定参数个数。
针对上述具体实施例,共进行了两组试验验证。
第一组试验验证时,图2中BP神经网络的输出层节点数预设为5个,对惩罚因子λ和 步长因子ρ1,ρ2,ρ3,ρ4进行同时自整定,图3为控制效果图,图4为控制输入图,图5为惩 罚因子λ变化曲线,图6为步长因子ρ1,ρ2,ρ3,ρ4变化曲线。结果表明,本发明的方法通过 对惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4进行同时自整定,能够实现良好的控制效果,并且可 以有效克服惩罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4需要费时费力进行整定的难题。
第二组试验验证时,图2中BP神经网络的输出层节点数为4个,首先将惩罚因子λ固 定取值为第一组试验验证时惩罚因子λ的平均值,然后对步长因子ρ1,ρ2,ρ3,ρ4进行自整定, 图7为控制效果图,图8为控制输入图,图9为步长因子ρ1,ρ2,ρ3,ρ4变化曲线。结果同样 表明,本发明的方法在惩罚因子λ固定时通过对步长因子ρ1,ρ2,ρ3,ρ4进行自整定,能够实 现良好的控制效果,并且可以有效克服步长因子ρ1,ρ2,ρ3,ρ4需要费时费力进行整定的难题。
应该特别指出的是,在上述具体实施例中,将系统输出期望值y*(k)与系统输出实际值 y(k)之差作为系统误差e(k),也就是e(k)=y*(k)-y(k),仅为所述系统误差计算函数中的一 种方法;也可以将k+1时刻的系统输出期望值y*(k+1)与k时刻的系统输出实际值y(k)之差 作为系统误差e(k),也就是e(k)=y*(k+1)-y(k);所述系统误差计算函数还可以采用自变量 包含系统输出期望值与系统输出实际值的其它计算方法,举例来说, -y(k);对上述具体实施例的被控对象而言,采用上述不同的系统误差计算函数,都能够实 现良好的控制效果。
还应该特别指出的是,在上述具体实施例中,作为BP神经网络输入的集合{系统误差集} 选择了系统误差e(k)、系统误差的累积系统误差e(k)的一阶后向差分e(k)-e(k-1) 的组合,仅为其中一种组合;所述集合{系统误差集}还可以采用其他组合,举例来说,为系 统误差e(k)、系统误差的累积即系统误差e(k)的一阶后向差分e(k)-e(k-1)、系统 误差e(k)的二阶后向差分e(k)-2e(k-1)+e(k-2)、系统误差e(k)的三阶或四阶或更高阶的 后向差分等函数的任意之一或任意种组合。对上述具体实施例的被控对象而言,采用上述不 同的集合{系统误差集},都能够实现良好的控制效果。
更应该特别指出的是,在上述具体实施例中,在以系统误差函数的值最小化为目标来更 新BP神经网络的隐含层权系数、输出层权系数时,所述系统误差函数采用e2(k),仅为所述 系统误差函数中的一种函数;所述系统误差函数还可以采用自变量包含系统误差、系统输出 期望值、系统输出实际值的任意之一或任意种组合的其他函数,举例来说,系统误差函数采 用(y*(k)-y(k))2或(y*(k+1)-y(k))2,也就是采用e2(k)的另一种函数形式;再举例来说, 系统误差函数采用其中,Δuj(k)=uj(k)-uj(k-1),bj为大于或等于 0的常数,1≤j≤m;显然,当bj均等于0时,系统误差函数仅考虑了e2(k)的贡献,表明最 小化的目标是系统误差最小,也就是追求精度高;而当bj大于0时,系统误差函数同时考虑 e2(k)的贡献和的贡献,表明最小化的目标在追求系统误差小的同时,还追求控制输 入变化小,也就是既追求精度高又追求操纵稳。对上述具体实施例的被控对象而言,采用上 述不同的系统误差函数,都能够实现良好的控制效果;与系统误差函数仅考虑e2(k)贡献时的 控制效果相比,在系统误差函数同时考虑e2(k)的贡献和的贡献时其控制精度略有降 低而其操纵平稳性则有提高。
最后应该特别指出的是,所述MISO全格式无模型控制器待整定参数,包含惩罚因子λ和 步长因子ρ1,…,ρLy+Lu的任意之一或任意种组合;在上述具体实施例中,第一组试验验证时惩 罚因子λ和步长因子ρ1,ρ2,ρ3,ρ4实现了同时自整定,第二组试验验证时惩罚因子λ固定而 步长因子ρ1,ρ2,ρ3,ρ4实现了自整定;在实际应用时,还可以根据具体情况,选择待整定参 数的任意种组合,举例来说,步长因子ρ1,ρ2固定而惩罚因子λ、步长因子ρ3,ρ4实现自整定; 此外,MISO全格式无模型控制器待整定参数,包括但不限于惩罚因子λ和步长因子 ρ1,…,ρLy+Lu,举例来说,根据具体情况,还可以包括MISO系统伪分块梯度估计值的行矩阵 等参数。
上述具体实施方式用来解释说明本发明,仅为本发明的优选实施例,而不是对本发明进 行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改、等同替换、 改进等,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!