基于海量数据分析挖掘CDN域名的方法与流程
本发明属于网络信技术领域,涉及一种基于海量数据分析挖掘cdn域名的可靠有效的方法。
背景技术:
随着互联网的高速发展,人们对网络的反应速度和品质要求也同步提高,为解决互联网响应速度等问题,cdn技术这个概念被提出,并且现如今得到了广泛的使用。cdn(contentdeliverynetwork),又名内容分发网络,基于现有的互联网基础之上构建一层虚拟网络架构,以实现用户可就近获取网站内容,从而规避了网络拥挤的情况,提高了互联网响应的速度,为使用cdn服务的网站提供了稳定、安全、高效的加速服务。
对于cdn技术被广泛普及和利用的当下,对于cdn技术相关问题的分析也成为了趋势所向。对于使用cdn服务的域名的发现技术、以及提供cdn服务的服务ip的发现技术,对于后续相关领域应用的分析将提供可靠的数据支持。且由于现如今数据爆炸式增长,数据存储周期变短,如何及时地从海量数据中提取出有分析和使用价值的数据,也成为了我们需要探究的问题。因此,本发明提供的一种基于海量的数据进行cdn域名的分析挖掘方法具有极高的探究和使用价值。
技术实现要素:
本发明的目的是提供一种基于海量数据分析挖掘cdn域名的可靠有效的方法,用于挖掘出数据中隐含的价值信息,分析出使用cdn服务的域名,以为后续网络安全应用和分析提供坚实的基础数据支持。
本发明提供的一种基于海量数据分析挖掘cdn域名的方法,包括:
步骤1,对获取的数据进行host域名提取,过滤掉无法提取host域名的脏数据和数值型host域名;
步骤2,设置cdn服务ip个数的阈值m和host域名对应不重复的服务ip个数的阈值n;m,n为正整数;
步骤3,对成功提取host域名的数据,基于服务ip个数、不同地理位置区域以及是否使用提供cdn服务ip三个维度进行cdn域名分析发现;包括:
步骤301,对成功提取host域名的数据,按照{host域名,服务ip}进行重复数据删除;
步骤302,以host域名作为key值进行分组,在组内统计对应不重复的服务ip及ip总数;然后执行步骤304;
步骤303,利用去重后的数据,根据阈值m提取出疑似度较高的提供cdn服务的服务ip;
步骤304,判断host域名对应不重复的服务ip总数是否通过阈值n的限制,如果通过则执行步骤305,否则判定host域名为未使用cdn服务;n为正整数;
步骤305,将步骤304中通过判断的{host域名,服务ip}数据,和步骤303中提取的疑似度较高的提供cdn服务的服务ip及对应host域名数据进行融合;
步骤306,将融合后的数据按照host域名为key值进行分组,组内统计不重复的服务ip及ip总数;
步骤307,判断host域名对应不重复的服务ip总数是否通过阈值m限制,如果通过检验则执行步骤308,否则判定host域名为未使用cdn服务;
步骤308,对通过步骤307检验的数据的服务ip,采用离线定位获取位置信息;
步骤309,以host域名为key值分组,组内统计不重复的服务ip的位置及位置数目;
步骤310:判断host域名对应的服务ip不重复位置的总数是否通过阈值m限制,如果通过检验则判定为cdn域名,否则判定为非cdn域名。
本发明提供了一种使用离散型随机变量数学期望的方法获取cdn服务ip个数阈值m的判断方法,具体是:将cdn服务的ip个数作为离散型随机变量,选取一定时间段内的网络数据,基于所有cdn域名对应的服务ip总数统计出该ip总数出现的次数,并计算该ip总数出现的概率,基于统计结果进行该离散型随机变量的数学期望计算,得到的数值就是m。
本发明提供了一种位置粒度判定算法,用于对获得的服务ip位置进行判定,统计不重复的服务ip的位置,包括:首先基于服务ip位置中的“国家-省份”信息等级进行不同位置的初级判断,对满足同一“国家-省份”位置信息等级的不同的服务ip,再利用ip的经纬度信息结合地球面距离计算公式,计算不同服务ip的位置的距离差,当计算的距离差达到设定的量级时,将判定不同的服务ip处于不同的物理位置,否则判定为处于同一物理位置。
本发明方法采用spark计算引擎对海量数据进行分析计算,并使用多重性能调优方法,包括:使用双重聚合的方法和基于运行资源的并行度调整;采用spark缓存机制,对于重复利用的rdd对象进行缓存;结合海量数据的数据量级确定数据的资源配置。其中,双重聚合方法是指:将原有的key值加上指定范围内的随机前缀,使其变为不同key值,将原有的一个任务中的数据量分配到多个不同的任务中进行聚合分析;在添加随机前缀进行一次聚合后,再去掉随机前缀进行第二次聚合,得到最终结果。
相对于现有技术,本发明的优点和积极效果在于:
(1)本发明方法综合服务ip个数、不同地理位置区域、以及是否使用提供cdn服务ip等因素就可以对数据进行价值数据的过滤、提取和深度分析,并对价值数据进行精准的、多维度的分析判断,最终实现从海量数据中分析挖掘出使用cdn服务的域名信息。
(2)本发明方法综合考虑正则规则、http协议特性、host域名层级特性,提出一种更精准有效的域名提取方法,在该方法中首先对初始的url信息进行url解码,以保证host域名提取的准确性和完整性;然后对解码后的url进行host域名提取和正确性验证,从而提高host域名提取的准确性和可靠性。
(3)本发明方法利用cdn服务ip个数阈值判定算法得到的阈值,筛选出满足阈值约束条件的域名及对应信息,并利用cdn域名使用的cdn服务ip将分布于多处不同的地理位置的特性,再次对域名进行筛选,以提高分析出的cdn域名的精准度和可靠性。
(4)本发明紧密结合了使用cdn服务域名的特性,在分析中利用了多种精准的、有依据的分析方法,进行多维度分析判断,保证了分析的可靠性和准确度,因此,本发明方法可以为后续的网络安全应用和分析提供坚实的基础数据支持,使得相关领域有更加广泛的应用前景。
附图说明
图1为本发明基于海量数据分析挖掘cdn域名的一个实现流程图;
图2为本发明提供的更精准有效的域名提取方法操作流程图;
图3为基于服务ip个数、不同地理位置区域、以及是否使用提供cdn服务ip三个维度进行cdn域名的分析发现流程图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明的技术方案进一步详细说明。
基于cdn技术原理分析得到使用了cdn服务域名的特点如下:
1)该域名对应的服务ip变换为提供cdn服务的ip(域名对应的真实ip将被隐藏);
2)该域名将与多个服务ip构成映射关系;
3)该域名对应的多个服务ip中必然包含着一定数量的提供cdn服务的ip;
4)该域名对应的一定数量的提供cdn服务的ip对应的地理位置将各有不同(cdn的服务ip分布于全国)。
本发明基于使用了cdn服务域名的以上特点,综合服务ip个数、不同地理位置区域、以及是否使用提供cdn服务ip等因素对数据进行价值数据的过滤、提取和深度分析,并对价值数据进行精准的、多维度的分析判断,最终得到使用cdn服务的域名信息。
图1给出了本发明基于海量数据分析挖掘cdn域名的实现方法整体组织结构示意图。从图中可以看出,整个分析挖掘的组织结构主要包括数据接入、数据分析挖掘、数据存储三大部分。其中,数据接入主要是获取原始海量数据以待后续分析;数据分析挖掘主要包含数据过滤、基于url的host域名提取,综合考虑服务ip个数、不同地理位置区域、以及是否使用提供cdn服务ip等因素进行三个维度的分析判断,其中使用到了cdn服务ip个数阈值判定、位置粒度判定等分析方法;数据存储主要就是将分析挖掘出的cdn域名等价值信息进行保存,以待后续分析和使用。
本发明基于spark框架实现了一套支持海量数据cdn域名分析发现的分析模型,海量的数据中需要包含url(或者host域名)和对应服务ip信息。在数据接入阶段,首先对海量的网络数据进行一个初步过滤,过滤掉无url信息的数据、无对应服务ip信息的数据等。
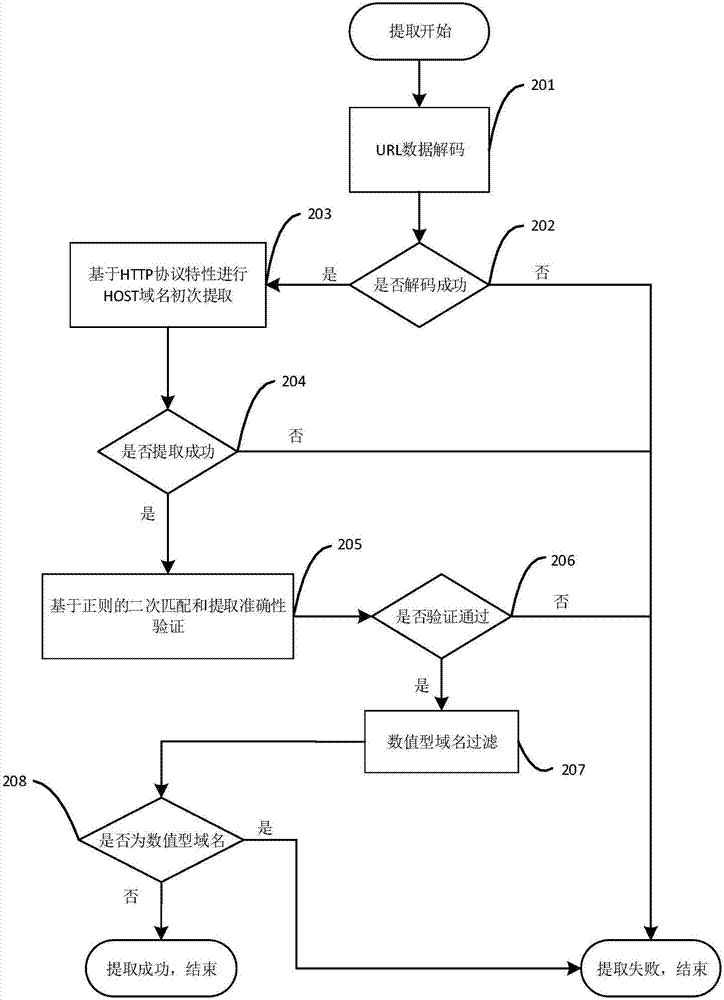
在数据挖掘阶段,本发明方法综合考虑正则规则、http协议特性、host域名层级特性,还提供了一种更精准有效的域名提取方法。基于对http协议、url地址格式和url编码的分析了解,在该方法中将首先对于初始的url信息进行url解码操作,以保证host域名提取的准确性和完整性;然后结合多重的host域名提取方法对解码后的url进行host域名提取和正确性验证,从而提高host域名提取的准确性和可靠性。如图2所示,下面说明所提供的的域名提取方法的一个具体实现步骤。
步骤201:将url数据进行解码操作,防止url编码导致域名提取不准确或遗漏等问题;
步骤202:判断url数据解码是否成功,如果成功则执行步骤203,否则,域名提取失败,结束本次提取;
步骤203:基于http协议特性对已解码成功的url数据进行初次的host域名提取;
初次的host域名提取就是指从url数据中提取host域名,利用现有的java.net包中类实现。
步骤204:判断host域名提取是否成功,如果成功则执行步骤205,否则域名提取失败,结束本次方法;
步骤205:基于正则方法对于成功提取出的host域名进行二次匹配,同时验证host域名提取的正确性;
二次匹配是对提取的host域名与正则表达式匹配,以判断是否满足正则表达式规定的条件。正则匹配公式是结合host域名格式定义和步骤203中提取出的host域名格式,自定义的,用来对host域名进行正确性验证。
步骤206:判断正则匹配验证是否通过,即判断host域名提取是否正确,如果成功则执行步骤207,否则表示域名提取失败,结束本次提取;
步骤207:对于提取出的数值型的host域名进行过滤;
自定义过滤规则为“host域名除去分隔符‘.’后,剩余字符串是否完全由数字构成,若是则判定为数值型host域名,否则判定为非数值型host域名。
步骤208:判断host域名是否为数值类型,若不是则表示域名提取成功,结束本次提取,否则表示域名提取失败,结束本次提取。
本发明在数据分析挖掘中,基于概率论中离散型随机变量的数学期望定义和原理,提出并实现了cdn服务ip个数阈值判定算法。基于cdn域名的特性可知大部分cdn域名一段周期内对应的cdn服务ip个数将不低于期望平均水平,故这里将使用离散型随机变量数学期望的方法判定cdn服务ip个数阈值。将cdn服务的ip个数作为随机变量。概率论中的离散型随机变量数学期望定义:将离散型随机变量的所有可能的数值与该随机变量出现概率的乘积之和被称为该离散随机变量的数学期望。假设离散型随机变量x的取值分别为x1,x2,...,xn,且其对应数值出现的概率分别为f(x1),f(x2),...,f(xn),则该离散随机变量的数学期望e(x)的公式说明如下:
基于一定周期内的海量数据进行有效数据初步提取,以每个cdn域名对应的所有服务ip的总数作为离散型随机变量,并基于所有cdn域名对应的服务ip总数统计出该ip总数出现的次数,从而计算该随机变量出现的概率,基于统计结果进行该离散型随机变量的数学期望计算,得到的数值即为cdn服务ip个数的阈值约束,设为m。
图3给出了基于服务ip个数、不同地理位置区域、以及是否使用提供cdn服务ip三个维度进行cdn域名的分析发现流程图,具体步骤如下:
步骤301:基于过滤并且host域名提取成功后的数据,按照{host域名,服务ip}进行重复数据删除操作;
步骤302:以host域名作为key值进行分组,在组内统计对应不重复的服务ip的信息及计数;
步骤303:利用去重后的数据,结合大量数据的阈值训练得到阈值m,进行疑似度较高的提供cdn服务的服务ip的分析获取;
结合cdn技术原理并考虑到前国内被许可做cdn业务的企业有限(即cdn服务ip数量是有限的),故可分析得到提供cdn服务的服务ip必然存在的特性:一个cdn服务ip将同时给大量的不同域名提供加速服务。本发明中利用cdn服务ip的该特性并结合大量数据的阈值训练,从海量数据中提取出疑似度较高的提供cdn服务的ip。基于本发明的提出的cdn服务ip个数阈值判定算法得到的阈值,筛选出满足阈值约束条件的域名及对应信息。
步骤304:判断域名对应不重复服务ip总数是否通过阈值n限制,如果通过检验则执行步骤305,否则判定为未使用cdn服务的域名,结束本方法;
此处阈值n的限制为维度一,通过阈值n的限制来减少处理数量级,提高分析效率。阈值n为正整数,范围设置在5~20。
步骤305:将步骤304中通过维度一判断的数据和步骤303中挖掘出的提供cdn服务疑似度较高的服务ip及对应host域名数据进行融合。
融合是指将通过步骤304检验得到的{host域名,服务ip}n条数据和通过步骤303检验得到的{host域名,服务ip}m条数据整合到一起得到{host域名,服务ip}共(n+m)条数据。n、m均为正整数。
步骤306:将融合后的数据按照host域名为key值进行分组,组内统计不重复的提供cdn服务的服务ip的信息及计数;
步骤307:判断域名对应不重复的提供cdn服务的服务ip总数是否通过阈值m限制(维度二),如果通过检验则执行步骤308,否则判定为未使用cdn服务的域名;其中,阈值m为利用本发明提供的基于概率论中离散型随机变量的数学期望训练得到。
步骤308:采用离线定位,对通过维度二检验的数据的服务ip进行位置信息获取;
步骤309:以host域名为key值分组,组内统计不重复的服务ip的位置信息及计数;
步骤310:判断域名对应服务ip不重复位置的总数是否通过阈值m限制(维度三),如果通过检验则判定为cdn域名,结束本方法,否则判定为非cdn域名,结束本方法。
步骤309在统计位置的计数时,基于位置的经纬度信息,本发明提出并实现了位置粒度判定算法。本发明的位置粒度判定算法基于位置经纬度信息粒度分析判定服务ip定位得到的位置是否表示为两个不同的物理位置,从而支持cdn域名的分析发现。首先利用离线ip定位技术获取ip定位后的信息,基于位置中的“国家-省份”信息等级进行不同位置的初级判断,满足同一“国家-省份”位置信息等级的不同的服务ip,再利用其经纬度信息结合地球面距离计算公式,计算得到的不同服务ip之间的位置要存在一定量级的距离差,则将其不同的服务ip判定为处于不同的物理位置。
地球面上的两点距离实际上就是计算经过这两个点的大圆链接两点构成的一段弧线的长度,其中大圆是经过地球球心的截球面所得的圆。假设地球是个球体(地球形状近似于椭球体),假设地球半径为r,地球面上两点经纬度信息分别为a(xa,ya),b(xb,yb),其中xa和xb表示经度,ya和yb表示纬度,且都为弧度单位,则用于计算弧
在获得距离
本发明结合cdn技术原理并考虑到前国内被许可做cdn业务的企业有限,即cdn服务ip数量是有限的,故可分析得到提供cdn服务的服务ip必然存在的特性:一个cdn服务ip将同时给大量的不同域名提供加速服务。本发明方法利用cdn服务ip的该特性并结合大量数据的阈值训练,首先从海量数据中提取出疑似度较高的提供cdn服务的ip,并基于本发明所提出的cdn服务ip个数阈值判定算法得到的阈值m,筛选出满足阈值约束条件的域名及对应信息,并利用cdn域名使用的cdn服务ip将分布于多处不同的地理位置的特性,再次对域名进行筛选,以提高分析出的cdn域名的精准度和可靠性。
本发明基于spark计算引擎并结合多重的性能调优方法,实现在大数据背景下高效分析发现cdn域名的方法。spark是一种与hadoopmapreduce相似的针对于处理大规模数的并行计算引擎,依赖于hadoop集群环境执行。该计算引擎拥有着hadoopmapreduce的优点,且由于其中间输出结果可存储于内存中,无需读写hdfs,得到其运行效率高于hadoop,故本发明选择spark计算引擎对海量数据进行分析。分析时结合数据特性和数据处理方法特性可知,在涉及到shuffle操作时不可避免的会出现某一个任务中要处理的数据量明显高于其他任务的情况,故本发明将使用双重聚合的方法和基于运行资源的并行度调整,防止数据倾斜的发生,避免影响整体处理性能,并采用spark缓存机制,对于重复利用的rdd对象进行缓存,防止其多次重头执行。最后,结合海量数据的数据量级对应确定其资源配置方法,保证效率并充分使用资源等。
其中,数据倾斜指定的是在并行处理数据集时,某一个任务要处理的数据量明显高于其他任务,从而其执行速度和性能过低,严重的影响了整体的处理速度和性能,多由shuffle操作引起。shuffle操作是指数组中的元素按随机顺序重新排列。
双重聚合方法说明:将原有的key值(即host域名)加上指定范围内的随机前缀,这里用从1开始的整数值作为随机前缀,使其变为不同key值,则可实现将原有的一个任务中的数据量分配到多个不同的任务中进行聚合分析,这样就防止了一个任务要处理的数据量过多而导致的数据倾斜的问题。添加随机前缀进行一次聚合后,再去掉随机前缀进行第二次聚合,即可得到最终结果。
基于运行资源的并行度调整,是指可通过spark引擎中的spark.default.parallelism参数控制shuffle过程中的并行度。调整规则是:根据运行spark任务设置的core总数调整,调整为其core总数的2-3倍左右,同时根据待处理数据的数据量大小调整并行度,保证每个任务中待处理数据量不会太大,从而减轻内存压力。
应该注意到并理解,在不脱离后附的权利要求所要求的本发明的精神和范围的情况下,能够对上述详细描述的本发明做出各种修改和改进。因此,要求保护的技术方案的范围不受所给出的任何特定示范教导的限制。
- 还没有人留言评论。精彩留言会获得点赞!