一种大数据平台上的电力数据去重方法与流程
本发明涉及一种大数据平台上的电力数据去重方法。
背景技术:
随着信息技术的不断发展,电力信息管理系统作为大型企业生产信息化的重要基础数据平台,产生了大量的数据。以电力系统为例,一方面其数据规模越来越大,其中用电信息采集、调度等系统大的数据规模预计将达到千万甚至上亿规模,数据存储容量到达pb字节以上。另一方面数据的类型越来越多:时序数据、关系型数据、音频数据、视频数据、文档数据等等,数据类型越来越多样。常规的关系数据库根本无法应对如此高速复杂数据处理的挑战,因此,越来越多的电力数据存储在大数据平台。这里边有很多的重复数据,占用了大量的存储资源,因此,需要对电力数据进行去除重复数据的处理。
技术实现要素:
本发明提供一种大数据平台上的电力数据去重方法,本发明所采用的技术方案是:
所述的大数据平台上的电力数据去重方法为分布式的总体架构:分布式的总体架构通过把去重过程分布到多个节点上执行从而避免系统瓶颈和单点故障;
所述的方法所指去重域指的是当用户上传数据的时候,判重过程中数据的对比对象的集合;基于此,去重域分为两类:基于单用户的本地去重域;基于所有用户的全局去重域;
在电力数据去重的时候,在客户端采用单用户的本地去重域,在服务端采用基于所有用户的全局去重域;
去重的可选位置有两种:客户端的源端去重和服务器端的目的端去重;源端去重在用户实际上传数据之前首先对数据的唯一性进行判定然后只传送新的数据到服务器端;目的端的去重中,所有的用户数据都会直接传递给服务器端;然后服务器端会利用后台进程对用户的文件进行指纹计算、数据判重以及后续的重复数据删除工作;
对数据进行判重之前,会对数据内容本身进行哈希计算,将不定长度的文件内容转化为固定长度的指纹;
哈希计算采用两种类型的算法:md5算法,sha-1算法;
设计的去重粒度有两种:文件级和块级:文件级的去重粒度将整个文件作为操作的对象和基本单位,而块级的去重会首先将一个文件划分成多个更小的数据块然后执行去重;对于非结构化数据采用文件级去重,对于结构化数据采用块级去重;
所述的方法获取存储于大数据集群中任意一个或多个节点中,或者分布于任意资源中的电力大数据,按照大数据集群系统的指定输入类格式,对获得的电力数据进行映射处理,按照所述大数据集群系统的归集框架的指定类格式,对所述映射处理的结果,进行归集,归集处理的结果是对电力数据去重的结果;
具体步骤:
先利用大数据平台计算框架来编写映射函数和归集函数;其中映射函数和归集函数可同时分布在大数据平台集群的同一个节点中,也可以分布在归约集群的不同节点中;映射函数可以在归约集群的一个节点中顺序执行,也可以在归约集群的多个节点中同时并发执行映射函数;可以在归约集群的多个节点中执行映射函数,并且同时在归约集群的多个节点中执行归集函数;
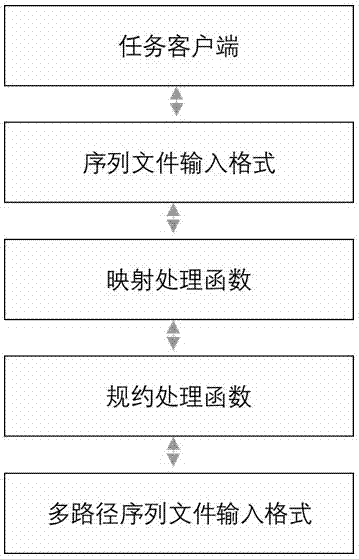
其次设计所有函数的类结构:parseextractdriver类为实现电力数据抽取、去重功能的主类,在这个类中,还包括映射归集任务的映射类、以及归集类,这两个类通过实现映射或是归集接口,分别完成映射归集任务中的映射任务和归集任务:此外,该类图中还包含有从数据解析类、数据规范化类和数据过滤类,完成数据过滤任务、规则匹配和合法性校验,多路径序列文件输入格式类指定该功能模块输出的数据块格式;
所有函数运行的时序:首先将大数据平台中的电力数据文件按照hdfs系统文件块的大小,先划分为不同的数据块,在每一个数据块中,按照待采集的电力数据的格式划分为不同的数据记录,此外,还将未入库中的电力数据文件按照hdfs系统文件块的大小,先划分为不同的数据块,在每一个数据块中,按照待采集的电力数据的格式划分为不同的数据记录;其次,在映射函数中根据数据格式记录的状态字段的值判断该数据对应是否为被采集的数据,如果对应为已采集的数据,则以将哈希值和状态直接写入到中间数据文件中,否则,表明该数据对应的为新数据,调用采集接口进行数据采集,然后对于刚采集的数据,将其状态字段值设置为已采集;最后,在归集阶段根据映射阶段的中间结果处理,对数据进行去重归集保存。
本发明重复数据删除使用的总体架构为分布式:分布式的总体架构通过把去重过程分布到多个节点上执行,从而避免系统瓶颈和单点故障。本发明对数据进行判重之前,会对数据内容本身进行哈希计算,将不定长度的文件内容转化为固定长度的指纹可以大大地提高判重的效率。哈希计算采用两种类型的算法:md5算法,sha-1算法。使用两种函数进行计算,这减少了些函数都存在着数据冲突的可能性,即不同的数据内容可能对应同一个数据哈希值。
附图说明
图1本发明的流程示意图;
图2为本发明的去重模块的类结构示意图;
图3为本发明的函数运行的时序图。
具体实现方式
以下结合附图的具体实施例对本发明进一步说明.(但不是对本发明的限制)。
重复数据删除作为一种数据压缩技术,是通过某种方式标识出内容相同的文件,并且删除重复的文件,只保留一份文件,其他文件添加对保留文件的链接,从而达到高效利用底层存储空间的目的。重复数据删除中涉及到的关键技术包括以下几个方面:
本发明重复数据删除使用的总体架构为分布式:分布式的总体架构通过把去重过程分布到多个节点上执行从而避免系统瓶颈和单点故障。
本发明所指去重域指的是当用户上传数据的时候,判重过程中数据的对比对象的集合。基于此,去重域分为两类:基于单用户的本地去重域;基于所有用户的全局去重域。很显然,去重域越大,系统能够检测到的重复数据越多,底层存储空间利用率越高。但是去重域增大之后大量的去重元信息的保存、检索也成为一个制约系统总体性能的关键点。本发明在电力数据去重的时候,在客户端采用单用户的本地去重域,在服务端采用基于所有用户的全局去重域。
本发明去重的可选位置有两种:客户端的源端去重和服务器端的目的端去重。源端去重在用户实际上传数据之前首先对数据的唯一性进行判定然后只传送新的数据到服务器端,大大地节省了网络带宽。目的端的去重中,所有的用户数据都会直接传递给服务器端。然后服务器端会利用后台进程对用户的文件进行指纹计算、数据判重以及后续的重复数据删除工作。
本发明对数据进行判重之前,会对数据内容本身进行哈希计算,将不定长度的文件内容转化为固定长度的指纹可以大大地提高判重的效率。哈希计算采用两种类型的算法:md5算法,sha-1算法。使用两种函数进行计算,这减少了些函数都存在着数据冲突的可能性,即不同的数据内容可能对应同一个数据哈希值。
本发明设计的去重粒度有两种:文件级和块级。文件级的去重粒度将整个文件作为操作的对象和基本单位,而块级的去重会首先将一个文件划分成多个更小的数据块然后执行去重。发明对于非结构化数据采用文件级去重,对于结构化数据采用块级去重。
如图1所示:获取存储于大数据集群中任意一个或多个节点中,或者分布于任意资源中的电力大数据,按照大数据集群系统的指定输入类格式,对获得的电力数据进行映射处理,按照所述大数据集群系统的归集框架的指定类格式,对所述映射处理的结果,进行归集,归集处理的结果是对电力数据去重的结果
具体步骤如图所示:
先利用大数据平台计算框架来编写映射函数和归集函数。其中映射函数和归集函数可以同时分布在大数据平台集群的同一个节点中,也可以分布在归约集群的不同节点中。映射函数可以在归约集群的一个节点中顺序执行,也可以在归约集群的多个节点中同时并发执行映射函数。可以在归约集群的多个节点中执行映射函数,并且同时在归约集群的多个节点中执行归集函数。
其次设计所有函数的类结构。parseextractdriver类为实现电力数据抽取、去重功能的主类,在这个类中,还包括映射归集任务的映射类、以及归集类,这两个类通过实现映射或是归集接口,分别完成映射归集任务中的映射任务和归集任务。此外,该类图中还包含有从数据解析类、数据规范化类和数据过滤类,完成数据过滤任务、规则匹配和合法性校验,多路径序列文件输入格式类指定该功能模块输出的数据块格式。
所有函数运行的时序图如附图3所示。首先将大数据平台中的电力数据文件按照hdfs系统文件块的大小,先划分为不同的数据块,在每一个数据块中,按照待采集的电力数据的格式划分为不同的数据记录,此外,还将未入库中的电力数据文件按照hdfs系统文件块的大小,先划分为不同的数据块,在每一个数据块中,按照待采集的电力数据的格式划分为不同的数据记录;其次,在映射函数中根据数据格式记录的状态字段的值判断该数据对应是否为被采集的数据,如果对应为已采集的数据,则以将哈希值和状态直接写入到中间数据文件中,否则,表明该数据对应的为新数据,调用采集接口进行数据采集,然后对于刚采集的数据,将其状态字段值设置为已采集;最后,在归集阶段根据映射阶段的中间结果处理,对数据进行去重归集保存。
- 还没有人留言评论。精彩留言会获得点赞!