一种基于Hadoop与Spark的效用次序并行确定方法与流程
本发明涉及智能并行化信息处理领域,尤其涉及一种基于Hadoop与Spark的效用次序并行确定方法。
背景技术:
随着互联网技术的飞速发展,各行各业产生的数据呈现指数级增长的趋势,海量数据信息资源提供了新机遇、也带来了新挑战。传统单机效用次序确定方法在数据规模很大的时候会面临内存开销大、磁盘IO非常多、运行效率低下等问题。因此,需要构建云系统来实现效用次序确定工作的并行化,以提高运行效率、降低运行成本。
本发明构建基于Hadoop与Spark的云系统以开源软件Hadoop和开源软件Spark为基础,以Hadoop的HDFS和Spark的RDD为主要构件。Hadoop是Apache旗下的一种开源软件,用于海量数据的存储和计算,主要包括HDFS和MapReduce两部分。它可以部署在成千上万台普通的物理机上组成集群,通过利用HDFS文件系统实现数据分布式存储,利用MapReduce并行计算模型实现数据并行处理。Spark也是Apache旗下的一种开源软件,通过借助弹性分布式数据集(Resilient Distributed Dataset)RDD,可以高效地并行处理各种不同的应用,包括迭代式计算、交互式查询、实时数据处理等,解决了MapReduce模型的I/O负载过高、容错性差等问题。
Spark采用RDD抽象数据结构,它是由多个分区组成的只读记录集合,每个分区通常存储在各个物理结点对应的内存上。利用RDD实现了分布式内存的抽象使用,是一种基于内存的计算,并将所有的计算任务翻译成对RDD的基本操作。利用persist操作我们可以将数据保存到内存或磁盘中来达到数据的多次共享和复用,有效地减少了I/O负载,从而提高效率,如果后面的操作再也用不到之前persist过的数据,可以使用unpersist来将缓存的数据从内存中删除,这样灵活地使用这两个操作可以有效地提高效率。Spark采用的编程接口包括:转换和动作类操作,可以充分利用内存对RDD中的数据进行各种处理。每个RDD的内部保存了血统(lineage)信息,lineage记录了当前RDD是如何从其他固定存储器上的数据以及对多个不同RDD的变换得到的。当某个RDD中的数据丢失或者某个结点出现故障时,通过lineage可以实现丢失数据的快速恢复,从而达到容错的目的,而不是使用副本。此外,还可以通过checkpoint机制对数据进行备份以便出错时能快速恢复,这是对lineage的辅助,对于长lineage我们可以采用checkpoint来达到高容错的目的。当用户提交一个应用到Spark系统中,调度器会自动构建一个由若干阶段(stage)组成的DAG(有向无环图)。每个阶段都包含对RDD数据的多种窄依赖类型的变换操作,并在内部进行了流水线优化。之后,调度器会分配多个任务到不同结点上,并通过在多个结点并行计算,快速对数据进行处理。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于Hadoop与Spark的效用次序并行确定方法。
本发明的技术方案如下:一种基于Hadoop与Spark的效用次序并行确定方法,该方法包括以下步骤:
(1)在大型存储计算服务器组上搭建基于Hadoop与Spark的云系统,具体过程如下:
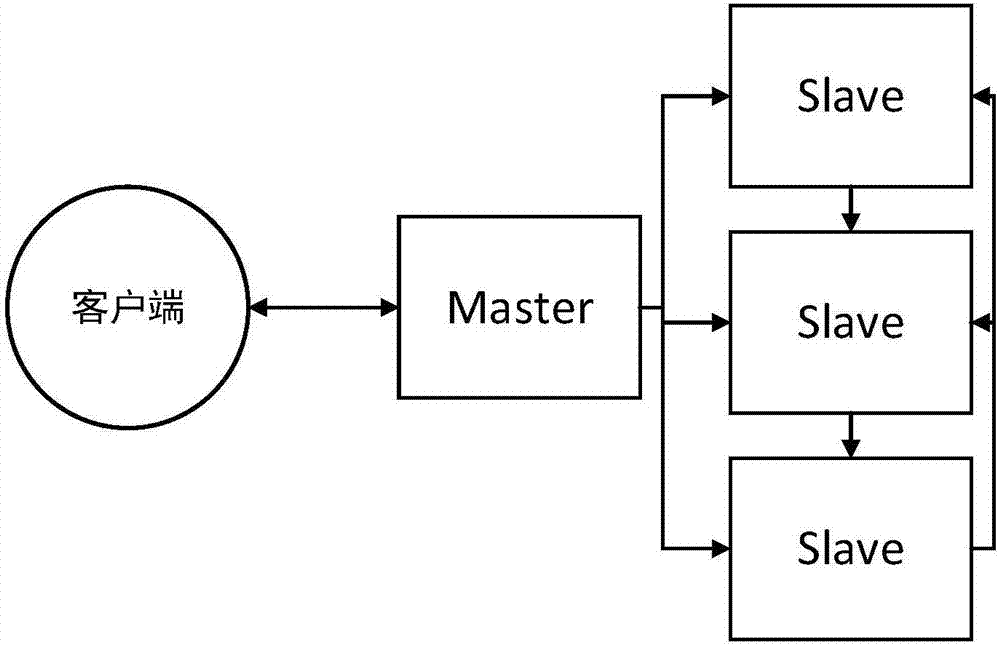
(1.1)在大型存储计算服务器组上,选取M+1台服务器,运行Linux系统,其中一台作为主服务器Master,用于与客户端的连接交互访问,剩余的M台服务器用于并行计算,称作Slaves;
(1.2)ssh无密码验证配置:安装和启动ssh协议,配置Master无密码登录所有Salves,并配置所有Slaves无密码登录Master,这样每台服务器上都有Master和Slaves的公钥;
(1.3)搭建Java和Scala基础运行环境,在此基础上,将Hadoop与Spark文件分发到Master和所有Slaves上,并在Master服务器上启动Hadoop与Spark;
至此,完成基于Hadoop与Spark的云系统的搭建,Hadoop HDFS用来做数据存储,Spark RDD用来并行计算;
(2)用户在客户端上制定高效的划分方法,高效的划分方法可以均衡系统负载,使各分组的计算量保持一致,进而让用户更快的确定效用次序,具体过程如下:
将效用次序的搜索空间表示为一棵集合枚举树,树的每个结点表示一个次序,其中,树根表示一个空的次序,第k层表示所有k阶效用次序;为了避免树中出现重复的次序,集合枚举树中的所有项目需按照指定顺序排列;
假设项目有N个并按照字典序排序,云系统有M个节点(服务器),作如下分配:如果N<=M,那么只要分配N个节点,将N个项目一个接一个分配给节点1,2,…N,如果N>M,将前M个项目一个接一个分配给节点1,2,…M,计算第M+1个项目的负载,将其加入到负载最小的那一节点,并更新该节点的负载值,之后的项目做同样的操作,最后得到一个Map类型的数据结构GList;
(3)客户端连接服务器组,和基于Hadoop与Spark的云系统进行交互,高效地并行确定效用次序:具体过程如下:
为了更高效的适用效用次序确定方法,增强系统可用性,从容错性、资源分配、任务调度、RDD压缩等方面入手对基于Hadoop与Spark的云系统进行优化配置,配置如下:
设置spark.speculation的值为true,使得在任务调度的时候,如果没有适合当前本地性要求的任务可供运行,将跑得慢的任务在空闲计算资源上再度调度;
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈,增大timeout值来提高容错性;
在磁盘IO或者GC问题不能得到很好解决时,将spark.rdd.compress设置为true,即采用RDD压缩,在RDD Cache的过程中,RDD数据在序列化之后进一步进行压缩再储存到内存或磁盘上;
为了应对大量数据中快速确定效用次序,将并行数值spark.default.parallelism设置为用于计算的服务器的数量(Slaves)的两倍到三倍;
将Spark中默认的序列化方式改为Kryo,这样更快速高效;
配置完成后,开始以下两个阶段:
第一阶段先将存储在分布式文件系统HDFS中的数据库文件加载到程序中,转换为弹性分布式数据集RDD,并对此RDD中的元素计算效用值,得到每条事务记录的效用值,再继续执行归并操作来累加计算数据库文件中每个项目的事务加权效用TWU,并将此数据库RDD cache到内存中以便之后的操作可以快速访问;
第二阶段读取第一阶段cache到内存的数据库RDD,读取每条事务记录,再根据步骤(2)估算每条事务记录中每个项目的负载,均衡划分项目以及事务记录,得到一条事务记录中各个项目及其子搜索空间属于的分组,继而通过归并操作得到每个分组中的项目及其中各个项目的搜索空间,对划分之后的每个分组中的项目及其中各个项目的搜索空间进行深度优先搜索,最终并行确定效用次序。
进一步地,所述步骤(3)中,第一阶段的具体过程如下:
首先经textFile()操作将数据库中存储在HDFS上的事务记录文件加载到程序中,得到一个RDD,记为transactionsRDD,该transactionsRDD是所有事务记录的一个集合,该transactionsRDD中的每个元素表示一条事务记录;然后对transactionsRDD中每个元素t执行flatMap()操作,并通过查询效用表计算每条事务记录t的效用tu,生成一个新的RDD,记为flatMapRDD,并且flatMapRDD中的每个元素表示为一个键值对(item,tu);之后,在flatMapRDD上执行reduceByKey()操作:对含有相同item的键值对的事务记录效用tu求和,得到该item对应的事务加权效用值TWU,从而生成一个新的RDD,记为itemTWURDD,itemTWURDD中的每个元素表示一个键值对(item,TWU)。
进一步地,所述步骤(3)中,第二阶段的具体过程如下:
首先,经过textFile()操作将所有的事务记录加载到transactionsRDD的多个分区中;然后,对分区中的每个元素(一条事务记录)执行flatMap()操作,该操作首先会依据第一阶段计算得到的TWU值将当前事务记录中的TWU值小于最小效用阈值minutil的项目剔除,并根据步骤(2)得到的GList来划分事务记录并产生每个分组对应的数据,形成NodeTransEntryRDD,该NodeTransEntryRDD中的元素形式为(gid,<tid,Relatedtrans>),其中gid为分组编号,tid为事务记录编号,Relatedtrans为剔除之后的事务记录集合;继续在NodeTransEntryRDD上执行groupByKey()操作,将gid相同的键值对合并为一组,得到NodeTransactionRDD,并且NodeTransactionRDD中的每个元素是键值对(gid,Iterable(<tid,Relatedtrans>));最后,执行mapValues()操作,对每个分组内的项目以及其子搜索空间进行深度优先搜索得到一个新的RDD,记为AllPtternsRDD;最后通过action操作类型的count()操作来触发job的执行,从而得到所有的效用次序。
本发明有益效果如下:本发明基于Hadoop与Spark的效用次序并行确定方法,可以适用于云系统下的大规模效用次序确定需求,具有更高效、快捷、安全、易扩展的特点,应用前景广阔。
附图说明
图1为本发明效用次序并行确定方法操作流程图;
图2为本发明效用次序并行确定方法交互结构示意图;
图3为枚举树图;
图4为事务记录数据库图;
图5为效用信息图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
本发明提供一种基于Hadoop与Spark的效用次序并行确定方法,该方法包括以下步骤:
(1)在大型存储计算服务器组上搭建基于Hadoop与Spark的云系统,具体过程如下:
(1.1)在大型存储计算服务器组上,选取M+1台服务器,运行Linux系统,其中一台作为主服务器Master,用于与客户端的连接交互访问,剩余的M台服务器用于并行计算,称作Slaves;
(1.2)ssh无密码验证配置:安装和启动ssh协议,配置Master无密码登录所有Salves,并配置所有Slaves无密码登录Master,这样每台服务器上都有Master和Slaves的公钥;
(1.3)搭建Java和Scala基础运行环境,在此基础上,将Hadoop与Spark文件分发到Master和所有Slaves上,并在Master服务器上启动Hadoop与Spark;
至此,完成基于Hadoop与Spark的云系统的搭建,Hadoop HDFS用来做数据存储,Spark RDD用来并行计算;
(2)用户在客户端上制定高效的划分方法,高效的划分方法可以均衡系统负载,使各分组的计算量保持一致,进而让用户更快的确定效用次序,具体过程如下:
将效用次序的搜索空间表示为一棵集合枚举树,树的每个结点表示一个次序,其中,树根表示一个空的次序,第k层表示所有k阶效用次序;为了避免树中出现重复的次序,集合枚举树中的所有项目需按照指定顺序排列;
假设项目有N个并按照字典序排序,云系统有M个节点(服务器),作如下分配:如果N<=M,那么只要分配N个节点,将N个项目一个接一个分配给节点1,2,…N,如果N>M,将前M个项目一个接一个分配给节点1,2,…M,计算第M+1个项目的负载,将其加入到负载最小的那一节点,并更新该节点的负载值,之后的项目做同样的操作,最后得到一个Map类型的数据结构GList;
(3)客户端连接服务器组,和基于Hadoop与Spark的云系统进行交互,高效地并行确定效用次序:具体过程如下:
为了更高效的适用效用次序确定方法,增强系统可用性,从容错性、资源分配、任务调度、RDD压缩等方面入手对基于Hadoop与Spark的云系统进行优化配置,配置如下:
设置spark.speculation的值为true,使得在任务调度的时候,如果没有适合当前本地性要求的任务可供运行,将跑得慢的任务在空闲计算资源上再度调度;
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈,增大timeout值来提高容错性;
在磁盘IO或者GC问题不能得到很好解决时,将spark.rdd.compress设置为true,即采用RDD压缩,在RDD Cache的过程中,RDD数据在序列化之后进一步进行压缩再储存到内存或磁盘上;
为了应对大量数据中快速确定效用次序,将并行数值spark.default.parallelism设置为用于计算的服务器的数量(Slaves)的两倍到三倍;
将Spark中默认的序列化方式改为Kryo,这样更快速高效;
配置完成后,开始以下两个阶段:
第一阶段先将存储在分布式文件系统HDFS中的数据库文件加载到程序中,转换为弹性分布式数据集RDD,并对此RDD中的元素计算效用值,得到每条事务记录的效用值,再继续执行归并操作来累加计算数据库文件中每个项目的事务加权效用TWU,并将此数据库RDD cache到内存中以便之后的操作可以快速访问;第一阶段的具体过程如下:
首先经textFile()操作将数据库中存储在HDFS上的事务记录文件加载到程序中,得到一个RDD,记为transactionsRDD,该transactionsRDD是所有事务记录的一个集合,该transactionsRDD中的每个元素表示一条事务记录;然后对transactionsRDD中每个元素t执行flatMap()操作,并通过查询效用表计算每条事务记录t的效用tu,生成一个新的RDD,记为flatMapRDD,并且flatMapRDD中的每个元素表示为一个键值对(item,tu);之后,在flatMapRDD上执行reduceByKey()操作:对含有相同item的键值对的事务记录效用tu求和,得到该item对应的事务加权效用值TWU,从而生成一个新的RDD,记为itemTWURDD,itemTWURDD中的每个元素表示一个键值对(item,TWU)。
第二阶段读取第一阶段cache到内存的数据库RDD,读取每条事务记录,再根据步骤(2)估算每条事务记录中每个项目的负载,均衡划分项目以及事务记录,得到一条事务记录中各个项目及其子搜索空间属于的分组,继而通过归并操作得到每个分组中的项目及其中各个项目的搜索空间,对划分之后的每个分组中的项目及其中各个项目的搜索空间进行深度优先搜索,最终并行确定效用次序。第二阶段的具体过程如下:
首先,经过textFile()操作将所有的事务记录加载到transactionsRDD的多个分区中;然后,对分区中的每个元素(一条事务记录)执行flatMap()操作,该操作首先会依据第一阶段计算得到的TWU值将当前事务记录中的TWU值小于最小效用阈值minutil的项目剔除,并根据步骤(2)得到的GList来划分事务记录并产生每个分组对应的数据,形成NodeTransEntryRDD,该NodeTransEntryRDD中的元素形式为(gid,<tid,Relatedtrans>),其中gid为分组编号,tid为事务记录编号,Relatedtrans为剔除之后的事务记录集合;继续在NodeTransEntryRDD上执行groupByKey()操作,将gid相同的键值对合并为一组,得到NodeTransactionRDD,并且NodeTransactionRDD中的每个元素是键值对(gid,Iterable(<tid,Relatedtrans>));最后,执行mapValues()操作,对每个分组内的项目以及其子搜索空间进行深度优先搜索得到一个新的RDD,记为AllPtternsRDD;最后通过action操作类型的count()操作来触发job的执行,从而得到所有的效用次序
实施例
图1为本发明提供的基于Hadoop与Spark的效用次序并行确定方法操作流程图,图2为本发明提供的基于Hadoop与Spark的效用次序并行确定方法交互结构示意图;该方法包括以下步骤:
步骤A:在大型存储计算服务器组上搭建基于Hadoop与Spark的云系统;
步骤B:用户在客户端上制定高效的划分方法;
根据图3,可以得到项目集合{e,c,b,a,d},所以N=5,为了方便说明实施方式,此处设服务器为3台,一台作为Master,两台作为Slave,所以M=2,e,c,b,a,d的负载分别为log5,log4,log3,log2,log1。e,c分别分配给节点(服务器)1,2;节点1的负载为log5,节点2的负载为log4,b加入负载最小的那一组,也就是节点2,并更新负载为log4+log3。这样节点1的负载为log5,节点2的负载为log4+log3。a加入负载最小的那一组,就是节点1,之后节点1,2的负载分别为log5+log2,log4+log3,继续将d加入负载最小的那一组,就是节点1。这样分配完之后,节点1有e,a,d,节点2有c,b。GList={(e,1)、(a,1)、(d,1)、(c,2)、(b,2)}。这样分组后,搜索空间的划分就相对平衡了。
步骤C:客户端连接服务器,和基于Hadoop与Spark的云系统进行交互,可以高效地并行确定效用次序。
在提交到基于Hadoop与Spark的云系统上时,对云系统进行了如下的配置:
conf.set("spark.speculation","true")
Speculation是在任务调度的时候,如果没有适合当前本地性要求的任务可供运行,将跑得慢的任务在空闲计算资源上再度调度的行为。
conf.set("spark.akka.timeout","300")
conf.set("spark.network.timeout","300")
conf.set("spark.task.maxFailures","8")
conf.set("spark.rpc.askTimeout","300")
conf.set("spark.core.connection.ack.wait.timeout","300")
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈,设置合适的值(增大)来提高容错性。
conf.set("spark.rdd.compress","true")
这个参数决定了RDD Cache的过程中,RDD数据在序列化之后是否进一步进行压缩再储存到内存或磁盘上。在磁盘IO的确成为问题或者GC问题真的没有其它更好的解决办法的时候,可以考虑启用RDD压缩。
conf.set("spark.default.parallelism","100")
为了应对大量数据中的确定效用次序并且更快速的确定效用次序,将并行数值设置为用于计算的服务器的数量(Slaves)的两倍到三倍。
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
Spark中默认的序列化方式java.io.Serializable,Kryo快速高效。
接下来,通过具体例子来进一步说明。
首先,对于图4和图5,进行交互时,遍历图3中的枚举树。当tid=1,对此transaction((b,1),(c,2),(d,1),(g,1))执行flatMap操作,计算得到事务记录效用tu(1)=10,因此输出键值对(b,10)、(c,10)、(d,10)、(g,10)。对flatMapRDD中的键值对执行reduceByKey()操作,当item=a,TWU=tu(2)+tu(3)+tu(5)+tu(6)=18+11+22+18=69。经过第一阶段计算,得到所有item的TWU值,即itemTWURDD=((a,69),(b,68),(c,66),(d,71),(e,49),(f,27),(g,10))。
接着,设置最小效用阈值minutil=48。
当tid=1,对此transaction((b,1),(c,2),(d,1),(g,1))执行flatMap()操作。由第一阶段的计算结果,我们发现项目g对应的TWU值小于minutil,因此在当前transaction中除去项目g,itemAndQuantityArr=((b,1),(c,2),(d,1))。对itemAndQuantityArr排序得到((c,2),(b,1),(d,1)),gidArray初始为空,遍历itemAndQuantityArr中的元素,首先遍历项目c,由于c属于分组2,gidArray不包含2的,所以输出(2,<1,{(c,2),(b,1),(d,1)}>),并将分组编号2加入到gidArray中去,遍历项目b,b是属于分组2的,gidArray中包含2,所以不输出。遍历项目d,d是属于分组1的,gidArray中已经不包含1,所以输出(1,<1,{(d,1)}>)。最后输出(1,<1,{(d,1)}>)、(2,<1,{(c,2),(b,1),(d,1)}>)。同样地,当tid=3时,最后输出(1,<3,{((a,4),(d,1)}>)、(2,<3,{c,2),(a,4),(d,1)}>),当对所有事务记录执行flatMap()操作之后最终生成NodeTransEntryRDD。
再执行groupByKey()操作,得到NodeTransactionRDD,此时以tid为1和3两个事务记录为例所得到此RDD中的每个元素为(1,Iterator(<1,{(d,1)}>,<3,{(a,4),(d,1)}>)),(2,Iterator(<1,{(c,2),(b,1),(d,1)}>,<3,{c,2),(a,4),(d,1)}>))。
然后执行mapValues(),对每个分区中的项目进行深度优先搜索,可以并行确定这些项目各自为根的子树中的所有效用次序。最后通过action操作类型的count()操作触发job的执行,得到所有的效用次序。
- 还没有人留言评论。精彩留言会获得点赞!