基于大数据的汽车残值预测模型及预测方法与流程
本发明涉及数据处理领域,特别是涉及基于大数据的汽车残值预测模型及预测方法。
背景技术:
随着汽车行业中商业租赁和个人租赁的兴起,汽车残值预测在制定租赁价格、核算租赁风险等方面具有关键作用,残值预测越来越受重视。若没有准确的残值预测,汽车租赁将不能得到很好的发展。现有的残值预测方法主要有三种:一、通过市场现在残值状况+人工经验获得预测值。这种方法过于依赖人工,不能评判精确度,尤其是在历史残值都没有很长趋势的情况下,难以保证预测的准确度。二、市场现在残值状况叠加上预测结束时车龄和里程增长情况外推得到预测值,例如A车现在能观察到1年的残值为0.85,那么三年残值预测则为:0.85-两年车龄的影响-3万公里的影响。这种方法一方面无法对刚上市的未观察到残值状况的新车做预测,另一方面,这种方法只考虑车源自身因素的变化,未考虑市场的影响。现在市场的残值和未来市场上同车型的残值很可能会因为外部的市场环境变化而变化,如果这部分被忽略,会存在很大的风险。例如某车型刚刚上市,正处于供不应求期,观察到市场上期残值较高。如果照本方法外推获得残值,三年后还将延续其高残值,仅仅因为车龄和里程的增加而给了折扣。因为供不应求推高的那部分残值仍然保留在预测中了。但是如果三年后不再存在供不应求的情形,其残值会明显低于本方法获得的预测结果。三、在方法二的基础上再叠加由机器学习得到的未来的某种趋势。这种方法,得到的残值预测结果缺乏解释性,并没有科学的预测体系,无法保证准确度。
总的来说,目前缺乏科学、体系的汽车残值预测方法,无法准确地对汽车残值进行预测。
技术实现要素:
为了解决上述的技术问题,本发明的目的是提供基于大数据的汽车残值预测模型及预测方法。
本发明解决其技术问题所采用的技术方案是:
基于大数据的汽车残值预测模型,所述预测模型通过以下步骤建立获得:
S01、获取最近一段时间内汽车的大量历史交易数据;
S02、对历史交易数据进行交叉数据清洗处理,剔除不具备代表性的历史交易数据;
S03、将清洗后的历史交易数据分成N个时间段内的训练数据,结合预设的车型数据库,将每个时间段内的训练数据解析为价格以及多个与二手车价格相关的影响因素;N为自然数;
S04、根据所有历史交易数据的解析结果,针对每种车型,从预设的备选函数库中选取合适的预测函数以及各影响因素的影响函数,组成函数数据库;
S05、基于每个时间段内的训练数据的解析结果,采用优化算法分别计算使得预测函数和各影响函数的成本函数最小的函数参数组合,从而建立与该时段对应的历史参数库;
S06、针对每种车型,根据其在N个时段内的不同的历史参数库,预测获得不同参数随时间的变化趋势,建立预测参数库;
S07、预测获得每个影响因素随时间变化的趋势,建立影响因素预测库;
S08、针对每个历史参数库,计算其对应的预测误差,进而根据N个时段内的预测误差的变化规律,预测获得预测误差随时间的变化趋势,建立预测误差时间序列趋势库;
S09、建立由上述函数数据库、预测参数库、影响因素预测库以及预测误差时间序列趋势库构成的预测模型。
进一步,所述影响因素包括旧车供应量因素、新车价格因素、新车型市场表现因素、消费趋势因素、车型折旧因素、配置价值折旧因素、城市影响因素、交易类型影响因素和个体因子影响因素。
进一步,所述步骤S05中,所述分别计算每种车型在该时段内预测函数和各影响函数相应的函数参数的步骤中,具体通过计算选取使得由预测函数和各影响函数组成的正则化成本函数最小的参数值作为相应的函数参数。
进一步,所述步骤S07中,采用时间序列法或因果预测模型预测获得每个影响因素随时间的变化趋势。
进一步,所述步骤S04中,所述从预设的备选函数库中选取合适的预测函数以及各影响因素的影响函数的步骤中,采用的选取原则为:
从预设的备选函数库中选取函数组成不同的预测函数和各影响函数的函数组合后,代入解析得到的价格以及多个影响因素进行计算,最后选择总体拟合度最好的函数组合。
进一步,所述历史交易数据包括城市、车型、型号、年款、里程、上牌年月、颜色,还包括交易类型、过户次数、车况和/或保养情况。
本发明解决其技术问题所采用的另一技术方案是:
基于大数据的汽车残值预测方法,应用上述的汽车残值预测模型,包括以下步骤:
S11、获取用户输入的目标汽车的车型信息以及预测时间;
S12、根据用户输入的车型信息,结合预设的车型数据库,匹配获得对应的车辆配置信息;
S13、从预测模型的函数数据库、预测参数库、影响因素预测库以及预测误差时间序列趋势库中选取对应的函数以及参数后,将车型信息和预测时间代入预测模型进行计算,获得目标汽车在预测时间的预测残值;
其中,所述车型信息包括型号、上牌时间、里程、车况、交易地点、颜色、配置和/或物理参数。
进一步,还包括以下步骤:
S14、计算获得目标汽车在当前时间到预测时间中不同时段的预测残值,并进行图形化显示。
本发明的有益效果是:本发明建立的预测模型,包括函数数据库、预测误差时间序列趋势库、预测参数库和影响因素预测库,不仅充分考虑了车本身因素以及市场因素等各种影响因素对汽车残值的影响,同时也考虑了这些影响因素自身变动情况对汽车残值的影响,可以科学全面地进行汽车残值预测,提高了预测准确性,预测精度高。
附图说明
图1是本发明的基于大数据的汽车残值预测模型的建立过程流程图;
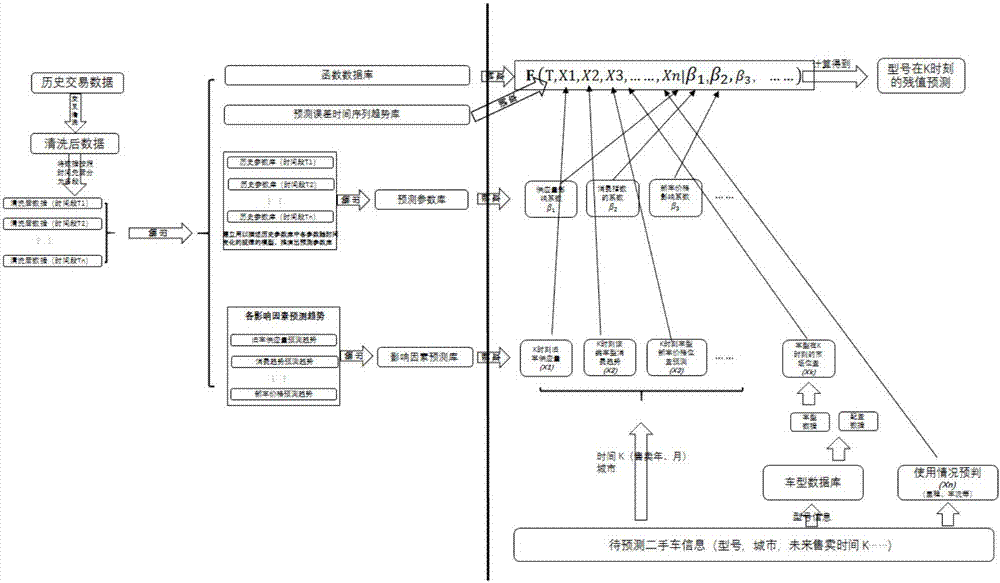
图2是本发明的汽车残值预测模型的建立原理及应用示意图;
图3是本发明的基于大数据的汽车残值预测方法的流程图。
具体实施方式
实施例一
参照图1,本发明提供了一种基于大数据的汽车残值预测模型,所述预测模型通过以下步骤建立获得:
S01、获取最近一段时间内汽车的大量历史交易数据;
S02、对历史交易数据进行交叉数据清洗处理,剔除不具备代表性的历史交易数据;
本实施例中,进行交叉数据清洗处理是通过多维度交叉的逻辑来逐一判断每条记录是否有代表性,从而删除不具备代表性的交易数据。清洗的逻辑就是判断某个车源是否离群,如果离群就不进入建模。而这个“群”是从不同维度定义的。例如单维度出现100万的里程或2000万的售价,这种极端异常记录首先将会被清洗掉。但大多数离群点不这么明显,往往还需要和其它维度交互印证其是否异常。如果单看某车源保值率为90%,不能确认为异常点,但是按照车龄划分群,该车源为3年旧,其90%的保值率在相应的车龄群里面就被认为是不具有代表性的记录,将其进行剔除。这里仅仅列举了按照车龄和保值率关系进行清洗的维度。其他涉及清洗的相关维度还有里程,车身类型,车型,地域等。
S03、将清洗后的历史交易数据分成N个时间段内的训练数据,结合预设的车型数据库,将每个时间段内的训练数据解析为价格以及多个与二手车价格相关的影响因素;N为自然数;
结合预设的车型数据库进行解析的过程:首先通过品牌匹配表找到车型数据库中对应的标准品牌名称。其次新增车源的车型及型号名称会与该品牌下所属各车型和型号逐一进行模糊匹配,找到和车源名称匹配度最好的前几名候选型号。然后再结合配置的相符情况以及销售时间和年款的匹配情况等综合进行打分,分数最高且高于阈值者被认为匹配成功。调取匹配上的标准型号的车型及配置信息补入新增车源记录完成解析。因此解析得到的除了价格之外的信息,均为本实施例中所指的影响因素。影响因素实际上是与车辆的品牌、车型、配置、城市、时间、交易类型、车龄、里程、车况、颜色等与价格相关的特性,每个特性都可能在不同的方面对二手车的价格造成影响,本发明将这些特性归纳为旧车供应量因素、新车价格因素、新车型市场表现因素、消费趋势因素、车型折旧因素、配置价值折旧因素、城市影响因素、交易类型影响因素和个体因子影响因素。
S04、根据所有历史交易数据的解析结果,针对每种车型,从预设的备选函数库中选取合适的预测函数以及各影响因素的影响函数,组成函数数据库;
S05、基于每个时间段内的训练数据的解析结果,采用优化算法分别计算使得预测函数和各影响函数的成本函数最小的函数参数组合,从而建立与该时段对应的历史参数库;
步骤S05的计算原理是,先设定好与预测函数和各影响函数相关的成本函数,例如设定成本函数为预测函数和各影响函数的残差平方和。然后针对步骤S04中选取的预测函数和各影响函数的函数组合,基于每个时间段内的训练数据的解析结果,采用优化算法计算选择一组函数参数组合,使得每种车型在该时间段内的成本函数最小。这里的函数参数组合包括预测函数和各影响函数的函数参数,最后,将获得的每个时间段对应的函数参数组合建立与该时段对应的历史参数库,即针对每种车型,均具有与多个时间段对应的历史参数库,从而后续步骤可以根据多个时间段对应的历史参数库,来预测获得函数参数随时间的变化趋势。
S06、针对每种车型,根据其在N个时段内的不同的历史参数库,预测获得不同参数随时间的变化趋势,建立预测参数库;具体的,对于每个车型的预测函数、影响函数的每个参数,沿时间轴看,每个参数随时间变化会有N个取值,因此,可以根据这N个取值的情况,预测获得参数随时间的变化趋势,进而获得所有参数的预测变化趋势后,可以建立预测参数库。具体的,可以根据N个取值的情况,预测在未来1-5年的参数取值情况。例如,若GPS的三年折旧率在15年是0.4,16年是0.35,17年是0.32,则不难推知未来会继续走低。如果用对数曲线拟合,则可以得到预测模型为折旧率=-0.073*ln(预测年份-2014)+0.4001。则由此可以推知在预测参数库中,GPS三年折旧率在2018-2020年分别对应为0.30/0.28/0.27。
实际进行参数预测的过程中,线性、指数、对数、双曲、多项式、三角函数等多种曲线均可以用来拟合参数随时间的变化情况,针对不同的参数,可以选择不同的曲线进行拟合,根据拟合效果最佳的函数和参数计算的参数预测结果建立预测参数库。
S07、预测获得每个影响因素随时间变化的趋势,建立影响因素预测库;
S08、针对每个历史参数库,计算其对应的预测误差,进而根据N个时段内的预测误差的变化规律,预测获得预测误差随时间的变化趋势,建立预测误差时间序列趋势库;
例如预测误差时间序列显示A车型在每个12月平均会被低估2%,则该结果就会被用于调整该车型未来所有的12月份的预测(例如将12月份的预测值乘以1.02)。当然这里的例子列举的是简单的规律,实际中会更复杂的规律甚至趋势,但是原理相同。通过本步骤,预测获得本模型的预测误差随时间的变化,从而对本预测模型进行修正,可以提高本预测模型的预测精度。
S09、建立由上述函数数据库、预测参数库、影响因素预测库以及预测误差时间序列趋势库构成的预测模型。
图2是本预测模型的建立原理以及应用示意图,图中,F(T,X1,X2,X3,......,Xn|β1,β2,β3,......)表示预测模型的预测函数,其中,X1,X2,X3,……,Xn分别表示各影响因素的影响函数,从函数数据库中调取,且受影响因素预测库的影响,T表示预测误差,从预测误差时间序列趋势库中获取,β1,β2,β3分别表示预测参数库中获取的影响函数的函数参数。通过建立本预测模型后,可以科学、全面地进行汽车残值预测,准确度高。
进一步作为优选的实施方式,所述影响因素包括旧车供应量因素、新车价格因素、新车型市场表现因素、消费趋势因素、车型折旧因素、配置价值折旧因素、城市影响因素、交易类型影响因素和个体因子影响因素。
旧车供应量因素是指旧车供应量对汽车残值的影响,因为某一款汽车的旧车供应量的不同会对汽车残值有不同影响,因此,在进行汽车残值预测时,需要充分考虑旧车供应量因素的影响。同理,新车价格因素、新车型市场表现因素、消费趋势因素分别反映了不同因素对旧车残值的影响,所以在进行残值预测时,需要全面考虑。
对应的,预测参数库包括车型折旧参数库、配置价值折旧参数库、城市影响参数库、交易类型影响参数库、个体因子影响参数库,以及旧车供应量参数库、新车价格参数库、新车型市场表现参数库、消费趋势参数库。
具体的,本实施例中,车型数据库被配置为:包含每个型号车辆的特征信息,例如该型号所属车型和品牌、新车在售时间段、年款、厂商建议价、重要的配置信息、以及物理参数诸如长宽高排量等信息。
预测参数库的各参数库的详细描述如下:
一、车型标准折旧库,记载了每个车型根据车龄增长的折旧曲线。对于不同城市这个折旧曲线可以不同。则在建立预测模型的过程中,针对不同城市,车型标准折旧库的参数可以是不同的。
二、配置价值折旧库:记载了车辆的每个重点配置信息特有的折旧曲线,这个折旧曲线可以与车型折旧曲线相同,也可以不同。
三、城市影响参数库:记载每个城市的二手车价格相对全国平均的整体偏移情况、该城市中与整体偏移不相符的特殊车型是哪些及这些车型个体偏移情况。
四、交易类型影响参数库:记录不同交易类型对于价格造成的价差。这个交易类型的价差会随着城市变化而变化。
五、个体因子影响参数库:包含各类个体因子影响的参数和函数,这些函数可以将里程、上牌时间、车况、颜色等个体因子的变化情况折算为对二手车价格影响的值。不同城市不同车型的这一套影响参数可以不同。
具体到步骤S07中,因为各个影响因素对汽车的残值都有影响,因此,本实施例除了在建立预测模型时充分考虑各影响因素之外,还考虑每个影响因素随时间的变化趋势,预测获得每个影响因素的预测变化趋势,如图2中所示的旧车供应量预测趋势、消费趋势预测趋势以及新车价格预测趋势,以及新车市场表现预测趋势等,从而将这些预测趋势建立影响因素预测库,从而对预测模型进行修正,使得预测结果更为准确。
其中,旧车供应量预测趋势用于:预测未来旧车供应量的变化趋势;
新车价格预测趋势用于:预测未来新车价格的变化趋势;
消费趋势预测趋势用于:预测不同细分市场在旧车市场上的消费趋势变化趋势;细分市场是指车型的细分市场,同一类价格功能相近的车型被称作一个细分市场,例如紧凑型SUV,中级轿车,紧凑型轿车等等就是不同的细分市场。
新车型市场表现因素用于:根据新上市车型的产品特征等预测未来这个车的市场表现趋势。
假设,已知旧车供应量对残值的影响为F(旧车供应量变化量*β),而且预测参数库提供的参数β显示,旧车供应量每增加一倍,汽车残值会减少3%。但要预测2020年供应量对残值的影响,还要知道未来旧车供应量的变动情况。因此需要知道2020年旧车供应量会增加多少。这个增加多少就是由旧车供应量预测趋势给出的结果。例如该趋势给出旧车供应量在2020年会比现在增加50%,则可知在2020年,汽车残值会因为供应量增加而减少1.5%(=3%*50%)。
总的来说,本预测模型充分考虑了车本身因素以及市场因素等各种影响因素对汽车残值的影响,同时也考虑了这些影响因素自身变动情况对汽车残值的影响,可以科学全面地进行汽车残值预测,提高了预测准确性,预测精度高。
进一步作为优选的实施方式,所述步骤S05中,所述分别计算每种车型在该时段内预测函数和各影响函数相应的函数参数的步骤中,具体通过计算选取使得由预测函数和各影响函数组成的正则化成本函数最小的参数值作为相应的函数参数。
进一步作为优选的实施方式,所述步骤S07中,采用时间序列法或因果预测模型预测获得每个影响因素随时间的变化趋势。
时间序列法:对于一些难以和当前情况建立因果关系的影响因素,一般通过经典时间序列方法拆解季节,趋势和不规则项,寻找其趋势或规律对未来进行预测。对于有权威预测的经济类变量如GDP,直接引用结果作为影响因素随时间的变化趋势。
因果预测模型:有些影响因素和当前甚至历史的同一类或另外一类影响因素有因果关系,这类影响因素就可以通过建立其和当前影响因素量化关系的模型进行预测。例如旧车供应量和历史上新车的售卖情况紧密相连,而且可以说新车的销量是旧车供应量的驱动变量。所以,通过建立当前旧车供应量和过往历史上新车销量的因果预测模型,得到旧车供应量预测趋势。这个因果预测模型建立好后,可以通过现有的新车销量,对未来旧车供应量进行预测。例如通过历史数据拟合得到以下旧车供应量预测趋势为:T时期3年旧车供应量=(T-3)时期新车销量*0.17。
进一步作为优选的实施方式,所述步骤S04中,所述从预设的备选函数库中选取合适的预测函数以及各影响因素的影响函数的步骤中,采用的选取原则为:
从预设的备选函数库中选取函数组成不同的预测函数和各影响函数的函数组合后,代入解析得到的价格以及多个影响因素进行计算,最后选择总体拟合度最好的函数组合。
另外,需要注意,本实施例对每种车型,均选择总体拟合度最好的预测函数和多个影响函数,从而构建的预测模型中,每种车型均具有根据最好拟合原则挑选获得的预测函数以及对应的影响函数,结合根据每个时间段的训练数据计算获得的历史参数库所预测获得的预测参数库,本发明对每种车型均可以得到最为准确的预测结果。
本实施例中,所述备选函数库中包括以下函数:线性函数、多项式函数、指数函数族、分段函数、三角函数、双曲函数和/或示性函数
进一步作为优选的实施方式,所述历史交易数据包括城市、车型、型号、年款、里程、上牌年月、颜色,还包括交易类型、过户次数、车况和/或保养情况。
实施例二
参照图3,基于大数据的汽车残值预测方法,应用上述实施例一的汽车残值预测模型,包括以下步骤:
S11、获取用户输入的目标汽车的车型信息以及预测时间;本步骤中,可以通过APP、网站或者API接口,获取用户输入的数据;
S12、根据用户输入的车型信息,结合预设的车型数据库,匹配获得对应的车辆配置信息;
S13、从预测模型的函数数据库、预测参数库、影响因素预测库以及预测误差时间序列趋势库中选取对应的函数以及参数后,将车型信息和预测时间代入预测模型进行计算,获得目标汽车在预测时间的预测残值;
其中,所述车型信息包括型号、上牌时间、里程、车况、交易地点、颜色、配置和/或物理参数。
本方法上述预测模型来预测获得汽车残值,科学、全面,预测准确度高,而且稳定性高,可以较为准确地预测获得汽车残值。
实际计算中,步骤S12匹配获得对应的车辆配置信息后,将车型信息和车辆配置信息转换为数值变量后,再代入预测函数中进行计算。具体信息转化过程可以采用现有数据处理中的通用做法,例如采用标识码来标识一些重要信息,采用总时长来标识上牌时间等。
进一步作为优选的实施方式,还包括以下步骤:
S14、计算获得目标汽车在当前时间到预测时间中不同时段的预测残值,并进行图形化显示。
本方式,可以计算获得一段时间内的汽车预测残值,并通过曲线等图形化显示形式显示汽车残值的动态变化,可以直观、明确地指示残值预测趋势。
实施例三
本实施例是实施例二的详细实例,具体包括步骤:
步骤1、获取用户输入的目标汽车的车型信息以及预测时间如下:
型号:北京奔驰奔驰C级2017款C L 200 4MATIC运动版;
地点:北京;
颜色:白色;
上牌时间:2017年10月;
预测二手车售卖时间:2020年10月。
本实施例中所述的目标汽车,指要进行残值预测的二手车。
步骤2、根据用户输入的车型信息,结合预设的车型数据库,匹配获得对应的包括标准车型型号在内的车辆配置信息:
排量:2.0;
马力:184;
发动机类型:涡轮增压;
变速箱类型:自动;
驱动方式:全时四驱;
排量:国五;
MSRP:39.98万。MSRP表示厂商建议零售价。
步骤3、设定以下关于使用情况的影响因素:
使用情况:非营运;
里程:4.5万公里;
车况:优秀;
交易类型:厂商拍卖给自身二手车商;
过户次数:0。
步骤4、计算各影响因素对汽车残值的影响。通过从预测模型的函数数据库、预测参数库、影响因素预测库以及预测误差时间序列趋势库中选取对应的函数以及参数后,将车型信息和预测时间代入预测模型进行计算,获得目标汽车在预测时间的预测残值。
a、计算起点::MSRP 39.98万;
b、查询预测函数:通过预测模型的函数数据库查找对应的预测函数,索引关键字为:奔驰C+广州,得到预测函数为:
(MSRP+上牌时间影响*配置影响+供应量影响+年款影响+消费趋势影响+里程影响+交易类型影响+其他个体影响)*颜色影响*城市影响*交易时间影响+模型误差调整项
需要注意,本发明的预测函数不仅仅只有上述加和乘的组合,也可以有其他组合方式,例如指数形式、对数形式等,本实施例不一一列举。
c、根据上牌时间计算获得上牌时间影响价格为:-9万,具体为:
1)、查车型标准折旧库,索引关键字为:奔驰C,2017款,北京,36个月,2020年,得到年&月车龄影响系数,以及影响函数G(.),这里车龄影响系数则为影响函数的函数参数。
2)进行上牌时间对于二手车价格的影响计算:
G(36个月*月车龄影响系数,3年*年车龄影响系数)=-9万
d、根据车辆配置,在配置价值折旧库中查找“奔驰C,北京,36个月,2020年”,得到影响值为“110%”。
f、计算旧车供应量的影响价格为-1.05万。计算过程如下:
一、在影响因素预测库中进行匹配,索引关键字为:奔驰C,北京,2020年,得到供应量增长幅度:70%;
二、在预测参数库中进行匹配,索引关键字为:奔驰C,北京,2020年,获得旧车供应量影响参数为:-1.5万/供应量每增长100%;
三、计算得到旧车供应量影响:70%*-1.5万=-1.05万。
g、根据3年旧车款计算获得影响价格为:-0.3万,过程与上述步骤c相似,同样是在车型标准折旧库中进行匹配,索引关键字为:奔驰C,北京,2020年。
h、同样在车型标准折旧库中进行匹配,索引关键字为:奔驰C,北京,2020年,匹配获得该车型为最新一代,折价+1.2万。
i、计算获得消费趋势的影响价格为:+0.8万。在影响因素预测库和预测参数库中进行匹配,计算方式与步骤f类似。
j、根据里程,在个体因子影响参数库采用索引关键字“奔驰C,北京,2020年,4.5万公里”匹配获得折价为-1.3万。
k、根据交易类型,在交易类型影响参数库中,查找“奔驰C,北京,2020年,厂商拍卖”,得到折价为-2.1万。
l、对其它个体因素,在个体因子影响参数库中查找得到对应的折价为0.7万。具体的个体因素包括车况,过户次数,质保是否到期,维修情况等。
m、根据车辆颜色,在个体因子影响参数库中采用索引关键字“奔驰C,北京,2020年,白色”匹配获得影响值为“98%”。
根据城市,在城市影响参数库中,查找“奔驰C,北京,2020年”,得到影响值为“97%”。
根据时间,在时间影响参数库中,查找“奔驰C,北京,2020年”,得到影响值为“96%”。
预测误差调整箱:在预测误差时间序列趋势库中,查找“奔驰C,北京,2020年”,得到影响价格为-0.5万。
n、将上述影响因素的影响结果一起计算获得该二手车的残值为:
(39.98-9*110%-1.05-0.3+1.2+0.8-1.3-2.1+0.7)*98%*97%*96%-0.5=25.08万。
因此,本预测方法充分考虑了车本身因素以及市场因素等各种影响因素对汽车残值的影响,同时也考虑了这些影响因素自身变动情况对汽车残值的影响,可以科学全面地进行汽车残值预测,提高了预测准确性,预测精度高。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变型或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!