一种基于MapReduce模型的提升表连接效率的方法与流程
技术特征:
1.一种基于MapReduce模型的提升表连接效率的方法,其特征在于:针对大数据表连接效率提升问题,由于在MapReduce模型中多表连接是由多个两表连接完成的,因此采取先对原两表方法进行改进,之后进一步对多表连接进行改进的技术路线;
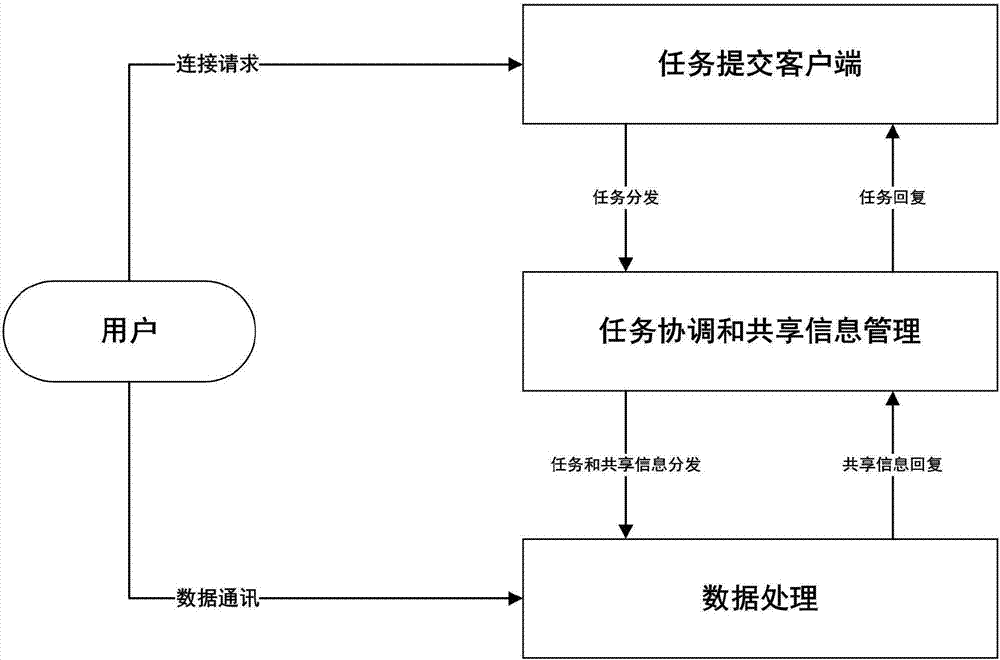
为了达到改进两表连接,本方法设计了信息共享机制对表的信息进行压缩共享,通过共享信息对连接表中无效信息进行过滤,提升中间结果在网络中传输的效率,打破大数据在本地存储时,分片数据信息不全面的瓶颈,从而达到提高整体算法效率的目的;
所述共享信息机制,包含三个功能模块,分别为信息分发模块、信息压缩模块和信息转型模块;
所述信息分发模块,是利用Hadoop平台中的分布式缓存机制,对主节点中的大小为几十MB以内的文件向所有从节点进行分发广播;
共享信息机制分为两个步骤:
S1当Hadoop平台分配任务时,通过静态方法DistributedCache.addCacheFile()设置需要被广播到各个节点的文件;这些文件以URI对象的形式存放在分布式文件系统中;当主节点的Job Tracker运行时,自动读取URI配置文件,同时在所有从节点的Task Tracker中创建指定文件的本地副本;
S2在各个map节点中,当需要使用背景数据时,通过调用DistributedCache.getLocalCac heFiles()获取文件所在路径,之后将“背景”数据读入内存;
所述信息压缩功能,是为了将文件中的连接键信息进行压缩,以便制作成共享信息通过分布式缓存机制分发给各个从节点,达到信息共享的目的;为了达到这一目的,采用Bit-Map算法,对数据进行压缩;该算法是将任意长度的整型数据通过哈希函数映射成一位,实现压缩数据的效果;
Bit-Map算法的设计思想是用一个bit来代表一个对应元素的value;Bit-Map算法的适用范围针对的是整型数据,数据表中的连接键却未必是整型数据,所以需要将连接键映进行转型;
所述信息转型功能,是将待压缩的连接键由字符串类型转换成可用于压缩的整型数据,字符串哈希函数解决这一问题;哈希函数虽然可用性强,但是冲突率却是每个函数都存在的,而冲突率的大小直接影响了“背景”数据过滤元组的效果,因此哈希函数的选取也是非常重要的;为保证算法的高效性和可用性,采用了BKDRHash字符串哈希函数,用于转换字符串数据;
为提高原MapReduce框架下的多表连接效率,除应用信息共享机制,针对多表连接中多个任务顺序执行效率较低的缺点,提出多任务的协调优化机制,用于协调多个任务的并发执行;
所述多任务协调机制,这个机制是针对多表连接在处理多任务时缺乏并发性而设计;在该模块的作用下,每个MapReduce任务的执行会参考共享信息的提取和任务的执行情况,适时的启动下一个MapReduce任务,完成部分前期的数据准备工作,在上一个MapReduce任务完全执行完毕时,再开始完成剩下的工作,实现提高任务并发性的效果;
不论是启动前的预备操作,还是为了部分输入数据的等待,这些在时间轴上与前一个任务都是串行的关系;实际上将这部分花费的时间,与上一个任务在时间轴上进行并行,形成一个流水线的并行模型,而且这些操作并不影响整个任务的流程;
不同的连接顺序对网络传输和I/O的影响还是很显著的,一个合理的连接顺序进一步提高共享机制的过滤效率;
针对上述情况设计制定了一个表连接顺序选择的策略;
在MapReduce框架下,影响连接顺序主要需要考虑类似于传统连接顺序判定的连接基数,表示两个表连接后输出结果和和输入数据表的笛卡尔积的比值,比值越大,表示连接基数越大,说明两个表中相等的元组个数越多,反之则表示两个表中相等的元组个数越小;
虽然连接基数可以准确反映两个表中连接键的一致情况,但是连接基数的应用条件却是建立在传统数据库的技术条件下,在传统的数据库中,由于数据量较小,所以可以对全局数据创建索引对数据进行维护和统计,能够很便利的进行连接技术的计算;但是对于海量数据来说,数据构成复杂、结构各异,不便于信息统计,只能分析处理一些很简单的日志文件,因此只能得到一些统计信息,当数据存入HDFS时,文件系统中的计数器会对数据中的元组数进行计数,除此之外也会记录一些基本信息;若是要计算像连接基数这样的数据,则需要对两个数据表进行详细的对比计数,在大数据中这样的统计代价巨大,而且建立索引对于大数据也是较为困难的;
所以使用数据属性种类与总元组数的比值来近似代表连接基数;
在规定的连接顺序中,每个表都有一个唯一确定的代表其本身的分布比例值,这个比例值近似的表示连接基数的概念,比例值越小说明,使用该属性制作的共享有效信息就越少,体现出的过滤效果也就越好;反之,共享信息越多,过滤掉的元组也就越少。
2.根据权利要求1所述的一种基于MapReduce模型的提升表连接效率的方法,其特征在于:在实际的大数据平台中,分布比例通过统计近似的得出一个数值,通常有三种途径:1、设计专门的技术器,用于在数据存储时进行统计计算;2、从概率统计的角度出发,随机采集有限的样本进行估值;3、在大数据平台中,有专门的系统来估计分布比例大小;根据上述的分析,现做出如下连接顺序规则:
(一)以不破坏最终的连接结果为原则,且各个表都能按规则连接的情况下,优先处理分布比例小的表;
(二)当在连接队列的某一个位置同时出现多个比例相同的候选数据表时,此时应比较表的大小,将数据表较小的进行优先处理。
- 还没有人留言评论。精彩留言会获得点赞!