一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法与流程
本发明涉及数据检测领域,具体涉及一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法。
背景技术:
电力系统不良数据的检测与辨识一直是电力系统状态估计的重要功能之一。电力系统遥测量中产生的不良数据,对调度员掌握实时运行状态并做出正确的调度决策有严重的不良影响。电网规模的不断扩大以及自动化程度的日趋提高,对电力系统数据的准确性提出更高的要求。
关于不良数据辨识处理,国内外学者已经取得不少研究成果,提出了多种辨识的方法。诸如基于估计和残差分析的辨识方法、基于聚类或神经网络算法的辨识方法。其中,GSA方法是一种强化聚类效果的数据挖掘算法,它可以估计数据集最佳的聚类个数。在电力系统不良数据辨识中,可以将良好数据和不良数据所在的聚类准确地区分进而检测和辨识不良数据。但是,传统的GSA算法没有考虑初始聚类中心的优化选择,导致算法常常终止与局部最优,且不适合用于发现非凸状的聚类,对噪声和异常数据敏感,计算耗时高,在大数据量情况下,这一问题尤为突出。
技术实现要素:
为解决上述问题,本发明提供了一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法。
为实现上述目的,本发明采取的技术方案为:
一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法,包括如下步骤:
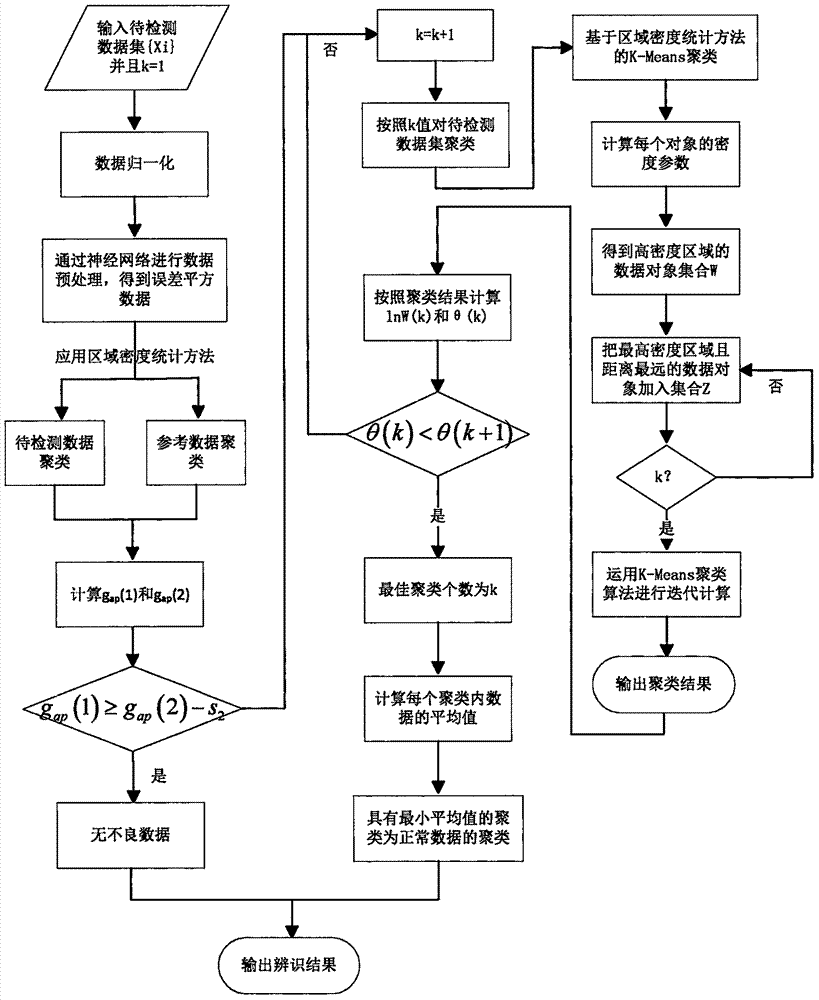
S1、输入待检测数据集{xi},同时设定初始值k=1;
S2、对待检测数据集进行数据归一化处理,利用神经网络算法对数据做预处理,得到误差平方数据;
S3、对待检测数据和参考数据集分别进行基于区域密度统计方法的聚类算法处理,得到聚类中心和聚类离散度;
S4、通过传统的GSA算法,计算gap(1)和gap(2),并验证是否满足以下公式:
gap(1)≥gap(2)-s2
式中:s2为参考数据ln W(2)的数学期望的标准差,具体计算公式为:
如果满足,则数据全部为正常数据,输出辨识结果;如果不满足,令k=k+1;
S5、通过基于区域密度统计方法,确定最优的k个聚类初始中心,并利用K-Means算法进行迭代计算,得到聚类结果;
S6、基于肘形判据的GSA辨识方法,计算聚类离散度ln W(k)和各个点处2条直线段的夹角θ(k),验证是否满足以下公式:
θ(k)<θ(k+1)
如果不满足,重新进行k=k+1计算;如果满足,则得到最优的聚类个数k。
S7、计算每个聚类内部的平均值,认为具有最小平均值的聚类即为正常数据的聚类,输出聚类结果。
其中,所述步骤S4通过以下公式计算gap(1)和gap(2):
gap(k)=Eln[Wr(k)]-ln[W(k)]
式中:E表示参考数据的数学期望,下标r表示参考数据。
其中,所述步骤S5具体包括如下步骤:
S51、计算任意两个数据对象间的距离d(xi,yi);
S52、计算每个对象的密度参数,把处于低密度区域的点删除,得到处于高密度区域的数据对象的集合W;
S53、把处于最高密度区域的数据对象作为第1个中心z1,加入集合Z中,同时从W中删除;
S54、从集合W中找距离集合Z最远的点,加入集合Z,同时从D中删除;
S55、重复S54、,直到Z中的样本个数达到k个;
S56、从这k个聚类中心出发,应用K-Means聚类算法,得到聚类结果。
其中,所述步骤S6中各个点处2条直线段的夹角θ(k)通过以下公式计算:
θ(k)=π/2+θu+θr;
式中:θu为直线段和垂线的夹角,θr为直线段与水平线的夹角,具体计算公式为:
θr=arctan{ln[W(k)]-ln[W(k+1)]}。
本发明具有以下有益效果:
本发明基于区域密度统计方法优化的GSA辨识法在算法执行的过程中,通过计算密度参数最大的数据对象,选出k个距离最远的最高密度区域的点作为最优的聚类初值,大大提高了算法的精确度,有效的避免了GSA肘形判据算法的缺点。在面对大规模的电网数据,可以通过最优聚类初值的选取,有效的减少迭代计算的计算量,大大减少计算时间。在避免残差污染和残差淹没的基础上,计算更为客观准确,计算速度大为提高;对于大系统、数据量巨大的情况,该方法是一种快速高效的算法。
附图说明
图1为肘形判据原理图。
图2为本发明实施例一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法的流程图。
图3为正常量测数据的预处理结果
图4为正常量测数据辨识时间图
图5为含单个不良数据时量测数据的预处理结果
图6为单个不良数据情况下的θ(k)曲线
图7为单个不良数据辨识时间图
图8为含多个不良数据时量测数据的预处理结果
图9为多不良数据情况下的θ(k)曲线
图10为多个不良数据辨识时间图
图11为含相互关联不良数据时量测数据的预处理结果
图12为相互关联不良数据情况下的θ(k)曲线
图13为相互关联不良数据辨识时间图。
具体实施方式
为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图2所示,本发明实施例提供了一种基于区域密度统计方法优化的GSA不良数据检测与辨识方法,包括如下步骤:
S1、输入待检测数据集{xi},同时设定初始值k=1;
S2、对待检测数据集进行数据归一化处理,利用神经网络算法对数据做预处理,得到误差平方数据;
S3、对待检测数据和参考数据集分别进行基于区域密度统计方法的聚类算法处理,得到聚类中心和聚类离散度;
S4、通过传统的GSA算法,计算gap(1)和gap(2),并验证是否满足以下公式:
gap(1)≥gap(2)-s2;
式中:s2为参考数据ln W(2)的数学期望的标准差,具体计算公式为:
如果满足,则数据全部为正常数据,输出辨识结果;如果不满足,令k=k+1;
S5、通过基于区域密度统计方法,确定最优的k个聚类初始中心,并利用K-Means算法进行迭代计算,得到聚类结果;
S6、基于肘形判据的GSA辨识方法,计算聚类离散度ln W(k)和各个点处2条直线段的夹角θ(k),验证是否满足以下公式:
θ(k)<θ(k+1)
如果不满足,重新进行k=k+1计算;如果满足,则得到最优的聚类个数k。
S7、计算每个聚类内部的平均值,认为具有最小平均值的聚类即为正常数据的聚类,输出聚类结果。
传统的GSA算法是在一组样本{xi}中,假设样本集被聚类成k个聚类G1,G2,G3,…,Gk,对于任何一个聚类Ga,其内部每个样本围绕聚类中心的距离平方和Da为:
式中ca是聚类Ga的中心。
对应于聚类个数k的聚类离散度为
GSA算法的核心就是将聚类离散度的自然对数与一个参考值进行比较,进而确定最佳的聚类个数。为了让离散度曲线更加线性化,使样本聚类和参考数据聚类之间的间隙值更容易被确定,GSA算法使用自然对数对聚类离散度进行处理。这里定义
gap(k)=Eln[Wr(k)]-ln[W(k)] (3)
式中:E表示参考数据的数学期望,下标r表示参考数据。
随着k的变化,当首次出现某个较大gap(k)的时候,此时的k就被认为是最合适的聚类个数,而当k变化时,gap(k)并无明显变化,认为最佳的聚类个数为k;
参考数据集的选取一直是GSA方法的重要问题,经过学者的研究,可以在待检测数据集的观察范围内以均匀分布方式产生参考数据集。为了使参考数据集更具有合理性,该方法中共需要产生F组参考数据集,通过取其均值作为E ln[Wr(k)]的估计。计算公式为:
(2)基于肘形判据的GSA辨识法
肘形判据是一种通过分析数据集的聚类离散度与聚类个数k的关系,按照各个k点的聚类离散度计算k处的肘形折角,并用最小肘形折角做为判断最佳聚类个数的依据。
分析GSA算法可知,其本质是建立一个合适的依据,分析聚类离散度与聚类个数的关系,以确定最佳的聚类个数。对ln W(k)-k曲线图的分析可以看出,从某个k值开始,曲线下降明显变得平缓。此时k值所对应的位置即为“最小肘形折角”位置,也就是最大间隙gap值出现的位置。
图1是聚类个数为2的ln W(k)-k的典型曲线,根据图形求曲线在各个k处的肘形折角,即各个点处2条直线段的夹角θ(k)。这里定义θ(k)的计算公式为:
θ(k)=π/2+θu+θr (5)
其中:θu为直线段和垂线的夹角,θr为直线段与水平线的夹角,具体计算公式为:
θr=arctan{ln[W(k)]-ln[W(k+1)]} (7)。
由于必须已知ln[W(k-1)]和ln[W(k+1)]值才能求得θ(k),而求取θ(1)就必须已知ln[W(0)],也就是说必须已知数据集的聚类个数为0的聚类离散度才能对聚类个数为1的情况进行有效估计,而一个数据集聚类成零个聚类的聚类离散度没有一个客观的计算依据。
关于GSA的研究表明:GSA在聚类个数为1的情况下比以往任何估计聚类个数的方法都优秀。但当聚类个数大于1时,由于需要产生F组均匀参考分布数据分别进行聚类计算,因此GSA的计算量较大,而肘形判据在聚类个数大于1时的计算量小,判断准确度高。针对这种情况可以考虑将GSA方法与肘形判据相结合,形成基于肘形判据的GSA辨识法。
基于肘形判据的GSA辨识法,包括如下步骤:
1)判断不良数据的存在性。
对一组待检测数据{xi},将待检测数据和参考数据分别聚类,得到聚类数据的聚类离散度,并计算gap(1)和gap(2).
如果公式(8)满足
gap(1)≥gap(2)-s2 (9)
式中:
则最合适的聚类个数应该为1。则说明所有的数据均是良好数据。如果公式(8)不满足公式(9),则进入下一步。
2)应用肘形判据计算肘形折角
置k=1,并令k=k+1,分别求取待检测数据的聚类离散度ln W(k),进而通过公式(5)计算聚类离散度曲线在各个聚类点处的肘形折角θ(k),对待检测数据在各个聚类点处的肘形折角的计算完成后,进入下一步。
3)确定最合适的聚类个数
在这个步骤中,寻找最小的k,使之满足
θ(k)<θ(k+1) (12)
所求的k值即为最佳的聚类个数。
4)检测和辨识不良数据
如果最佳的聚类个数为1,则表示所有的量测数据都是正常数据,否则就表示存在不良数据,要计算每个聚类内数据的平均值。具有最小平均值的聚类被认为是正常数据的聚类,其余的都被认为是不良数据组成的聚类,这样不良数据就可以被检测和辨识出来。
基于区域密度统计优化的K-Means算法
基于GSA的肘形判据方法可以很好的解决K-Means聚类中最佳聚类个数的问题,但是K-Means聚类算法存在对初始聚类中心敏感的问题。K-Means算法过程是随机的选取k个点作为聚类初值,再利用迭代的重定位技术进行聚类,直到聚类结果稳定。因此,聚类初值不同,可能会导致聚类结果不同。针对此问题,本课题主要通过找到一组能反映数据分布特征的数据对象作为初始聚类中心,优化K-Means的聚类效果。
(1)优化算法设计思路
在用欧氏距离作为相似性度量的K-Means算法中,相互距离最远的k个数据对象比随机取的k个数据对象更具有代表性。不过在实际的数据集中往往有噪声数据存在,如果只是单纯的取相互距离最远的k个点来代表k个不同的类别,有时会取到噪声点,从而影响聚类效果。一般在一个数据空间中,高密度的数据对象区域被低密度的对象区域所分割,通常认为处于低密度区域的点为噪声点。为了避免取到噪声点,取相互距离最远的k个处于高密度区域的点作为初始聚类中心。
以空间点xi为中心,包含n个数据对象的空间区域的半径ε,称之为对象xi的密度参数。ε越大,说明数据对象所处的区域的数据密度越低。反之,说明数据对象所处区域的数据密度越高。
在空间中,样本点xi和样本点yi的距离公式为
一个样本点x与另一个样本集合Z的距离定义为x与Z中所有点当中最近的距离,距离公式为:
d(x,Z)=min(d(x,y),y∈Z) (14)
通过计算每个数据对象xi的密度参数,就可以发现处于高密度区域的点,从而得到一个高密度点集合W。在W中取处于最高密度区域的数据对象作为第1个中心z1,加入集合Z中;计算W中每个样本点yi到集合Z的距离,找出距离集合Z最远的样本点,即max(min(d(yi,Z)))加入集合Z中作为第二个中心z2。同样的方法,依次得到k个初始聚类中心。
(2)基于区域密度统计的K-Means算法描述
输入:聚类个数k以及包含n个数据对象的数据集;
输出:满足目标函数值最小的k个聚类。
1)计算任意两个数据对象间的距离d(xi,yi);
2)计算每个对象的密度参数,把处于低密度区域的点删除,得到处于高密度区域的数据对象的集合W;
3)把处于最高密度区域的数据对象作为第1个中心z1,加入集合Z中,同时从W中删除;
4)从集合W中找距离集合Z最远的点,加入集合Z,同时从D中删除;
5)重复(4),直到Z中的样本个数达到k个;
6)从这k个聚类中心出发,应用K-Means聚类算法,得到聚类结果。
实施例
以下实施例的实验数据取自吉林省电力有限公司调度控制中心D5000系统中的实时运行数据。通过调研采集了2016年4月26日全省全天范围内的遥测采样数据。D5000系统每分钟采集一次全省电网设备运行数据,全天共计1440个数据文件,数据量大小共计6.48G。其中随机选取了吉林丰满水电站、四平热电厂、松花江厂、九台变电站、大安变电站和致富变电站3个发电厂和3个变电站的局部电网的运行数据。从调研数据中共获取121个测量值,其中包括21个节点电压值,20对发电机组出力的有功和无功,10对负荷潮流值,8对变压器输入有功无功以及12对线路潮流值。另外,从调研数据中获取240组量测数据,其中,200组作为训练样本对神经网络进行训练,余下的40组用来对神经网络进行测试。神经网络被训练好之后,将待检测的量测值,经过神经网络测试,得出的输入输出差的平方值作为聚类分析的依据。
(1)正常数据情况
对第205组量测数据先进行归一化处理,再通过神经网络算法得到数据的误差平方和,处理结果如图3所示。
在此种情况下,程序会先判断是否含有不良数据,计算gap(1)和gap(2),判断式(8)是否满足式(9)的条件。通过计算可以确定,gap(1)≥gap(2)-s2,最佳聚类个数为1,即所有待检测数据全部为正常数据。计算得到的结果见表1.
表1 正常数据情况下结果分析
在实验的运行时间上,通过本发明提出的基于区域密度统计方法优化的GSA辨识法,对算法执行过程中聚类初值的选择,有了很大的改进,在迭代计算上所耗时间大大减少。
图4为传统GSA算法、基于肘形判据的GSA辨识法和本文提出优化的GSA辨识法三种算法执行的时间对比图。可以看出,本文提出的方法在执行时间上有了很大的改进。
(2)单个不良数据情况
这里假设第215组中的第34号量测数据(吉林丰满水电厂220kV交流线段有功功率)超过正常值25%。先对第215组量测数据进行归一化处理,通过神经网络算法进行数据预处理,结果如图5所示。
经过优化的GSA辨识法计算后的实验结果如表2所示:
表2 单个不良数据情况下辨识结果分析
由表2的gap(k)可知,gap(1)<gap(2)-s2,说明数据中存在不良数据,然后用肘形判据进行分析计算θ(k)。从图6中可以明显看出θ(2)<θ(3),故最佳的聚类个数为2。进一步计算2个聚类内部元素的平均值,得到较大平均值聚类内的元素为第34号数据。仿真结果验证了算法的准确定和有效性。
在运行时间方面,经过区域密度统计的优化后的GSA算法,计算出了2个区域密度最大的聚类初值,在K-Means算法后续的迭代计算中节省了大量的时间。具体的运行时间如图7所示。
(3)多不良数据情况
电力系统中不良数据出现的机率是比较小的,一般约为0.27%;多不良数据出现的可能性则更小。虽然这种情况下不易出现,但这种情况用常规状态估计方法通常难以解决,而且一旦出现多不良数据的情况,必然会严重影响电力调度人员对电网运行状态的实时监控,危及电网的安全稳定运行。所以,有必要对多不良数据情况进行实验分析,验证算法的有效性。在这种情况下,假设第230组量测数据共出现6个不良数据,编号分别是4,15,36,75,96和112,其值与正常值相差在15%~30%之间。对第230组量测数据进行归一化处理,通过神经网络算法进行数据预处理。结果如图8所示。
经过优化的GSA辨识法对不良数据辨识后的计算结果如表3所示。
表3 多不良数据情况下辨识结果分析
由表3可知,gap(1)<gap(2)-s2,说明数据中存在不良数据,下一步利用肘形判据理论进行分析计算。从图9中可以明显的看出θ(3)<θ(4),故最佳聚类个数为3.进一步计算3个聚类内元素的平均值,得到2个较大的平均值聚类内的元素为6个假设的不良数据。
从图10可以看出,通过区域密度统计方法优化的GSA辨识法在处理聚类个数较多的时候,其表现的性能更为明显。尤其是在处理大数据量的时候,能节省大量的时间,提高准确度。
(4)相互关联不良数据情况
系统一般出现不良数据时,不良数据往往相互关联。下面分析相互关联的不良数据情况的仿真。这种情况下,假设第234组量测数据中,不良数据为九台变电站220kV东母线、九台变电站220kV#1变压器的有功无功以及九台厂220kV玉九线有功无功共5个量测值。假设其不良数据的值为超过正常值15%~20%。首先对第234组量测数据进行归一化处理,通过神经网络算法对数据进行预处理,得到输入输出差的平方值。结果如图11所示:
经过优化的GSA辨识法计算的结果如表4所示。
表4 相互关联不良数据情况的辨识结果分析
由表4可知,gap(1)<gap(2)-s2,说明数据中存在不良数据。通过肘形判据方法进行计算分析,从图12可以明显看出θ(2)<θ(3),最佳聚类个数为2.进一步计算2个聚类内元素的平均值,得到较大的平均值聚类内的元素为6个假设的不良数据。
在计算时间上,通过区域密度统计方法,很好的找到了2个K-Means的聚类初值。具体的运行时间图如图13所示。
本具体实施在对GSA肘形判据法研究的基础上,提出了基于区域密度统计优化后的GSA算法。并通过实验结果对优化后的GSA辨识法的性能进行分析。
(1)算法的准确度方面
基于肘形判据的GSA辨识法在进行聚类的时候,忽视了聚类初始中心点的选择问题。盲目的选择聚类初值,会造成聚类算法陷入局部最优,降低了算法的精确度和准确度。而基于区域密度统计方法优化的GSA辨识法在算法执行的过程中,通过计算密度参数最大的数据对象,选出k个距离最远的最高密度区域的点作为最优的聚类初值,大大提高了算法的精确度,有效的避免了GSA肘形判据算法的缺点。
(2)算法的计算量方面
由于基于肘形判据的GSA辨识法没有确定最优的聚类初值,在聚类算法的迭代过程中,会大大增加计算量,消耗大量的计算时间。尤其是在电网不断发展的现在,电网数据骤然增加,算法的效率问题尤为突出。本文提出的基于区域密度统计方法优化的GSA方法,面对大规模的电网数据,可以通过最优聚类初值的选取,有效的减少迭代计算的计算量,大大减少计算时间。
将该方法应用于吉林省局部电网实时数据的不良数据检测和辨识中,通过对几种不同情况下的不良数据的实验仿真可以发现:与已有的GSA方法相比,该方法在避免残差污染和残差淹没的基础上,计算更为客观准确,计算速度大为提高。对于大系统、数据量巨大的情况,该方法是一种快速高效的算法。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!