状态分析装置、状态分析方法、以及存储介质与流程
本发明的实施方式涉及状态分析装置、状态分析方法、以及存储介质。
背景技术:
目前正尝试使用在制造过程中积累的数据来解析在制造现场产生的不良原因等的状态。为了根据所积累的数据对产品的状态进行分析,提供可视化界面。在现存的可视化界面中,存在对状态进行分析的分析方法受限或者无法追加分析方法的情况。
现有技术文献
专利文献
专利文献1:日本国特开2010-250769号公报
技术实现要素:
发明所要解决的课题
本发明所要解决的课题在于提供一种能够通过各种各样的分析方法对在产品中产生的状态进行分析的状态分析装置、状态分析方法、以及存储介质。
用于解决课题的手段
实施方式的状态分析装置具有数据分类部、分析部、判定部。数据分类部对输入的数据符合与多个管理项目的各个对应的多个验证项目的哪一个进行分类。分析部基于由上述数据分类部分类后的上述数据而对上述多个管理项目和上述多个验证项目的各组合中的不良(指与目标变量具有关联性的数据,在本说明书的以下的说明中为同样的意思。在本说明书中作为实施例举出以发现成为不良产生、成品率降低的原因的负面的数据作为目的的分析,因此,为了容易理解而使用了不良这一用语,但并不意味着必然限定于负面的意思)的有无进行分析。判定部基于上述分析部分析出的分析结果针对上述管理项目和上述验证项目的组合的每个对分析结果进行判定。
附图说明
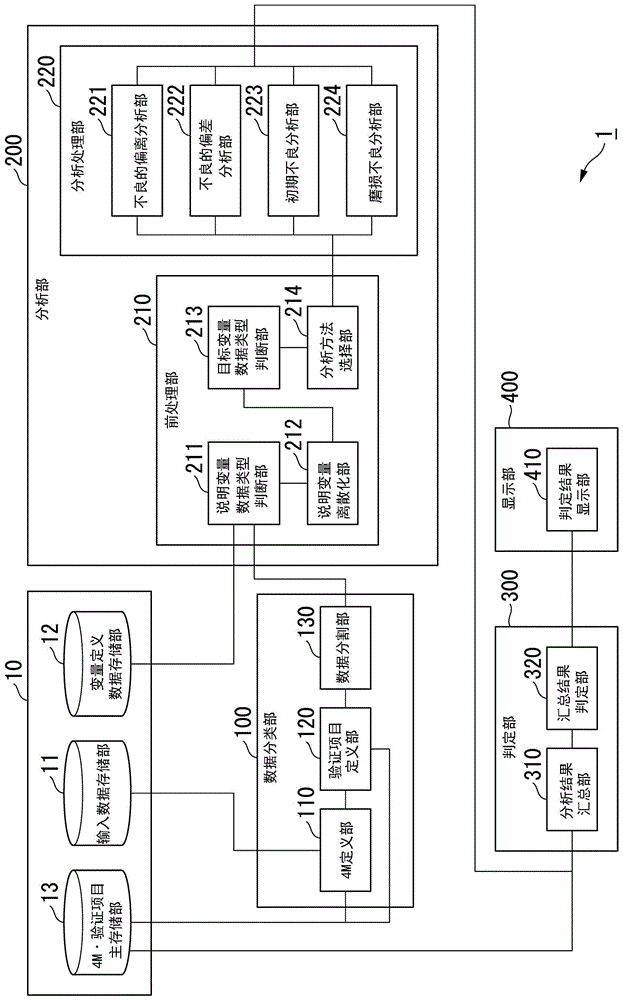
图1是示出第一实施方式的状态分析装置的结构的框图。
图2是示出输入数据的例子的图。
图3是示出对数据的变量进行定义的例子的图。
图4是示出针对4m的各管理项目分配的多个验证项目的图。
图5是示出输入数据的数据要素与4m的管理项目之间的关系的图。
图6a是示出针对输入数据的数据要素的验证项目的图。
图6b是示出映射结果的图。
图7是示出将作为连续值的说明变量离散化的处理的图。
图8是示出离散化后的说明变量的图。
图9是示出不良率的偏离的图表。
图10是示出成品率的偏差的图。
图11是示出初期的不良率高的数据的图。
图12是示出后期的不良率高的数据的图。
图13是示出由不良的偏离分析部进行的t检验的图。
图14是示出由不良的偏离分析部进行的t检验的p值的列表的算出结果的图。
图15是示出由不良的偏离分析部进行的fisher检验(费歇尔检验)的图。
图16是示出由不良的偏离分析部进行的fisher检验的p值的列表的算出结果的图。
图17是示出由不良的偏差分析部进行的f检验的图。
图18是示出由不良的偏差分析部进行的f检验的p值的列表的算出结果的图。
图19是示出在检验前被前处理后的数据的图。
图20是示出由初期不良分析部进行的t检验的图。
图21是示出由初期不良分析部进行的fisher检验的图。
图22是示出由初期不良分析部进行的f检验的p值的列表的算出结果的图。
图23是将分析部为不良的偏离分析部的情况下的分析结果进行汇总后的图。
图24是将所有的分析部的分析结果进行汇总后的图。
图25是示出在判定结果显示部显示的图像的图。
图26是示出状态分析装置的处理的流程图。
图27是示出状态分析装置的处理的流程图。
图28是示出第二实施方式的状态分析装置的结构的框图。
图29是示出对数据的变量进行定义的例子的图。
图30是示出针对4m的各管理项目分配的多个验证项目的图。
图31是统计量以时间系列变化的休哈特的管理图。
图32是示出休哈特的异常判定规则的图。
图33是示出以时间系列产生的数据的变动的图。
图34是示出通过休哈特分析分析的异常的图。
图35是示出在休哈特分析中使用的输入数据的图。
图36是示出由休哈特分析部进行的统计量的算出结果的图。
图37是示出以组单位进行判定处理的结果的图。
图38是示出由休哈特分析进行的异常判定的图。
图39是示出由休哈特分析部进行的t检验的结果的图。
图40是示出由休哈特分析部进行的fisher检验的结果的图。
图41是示出在判定结果显示部显示的图像im的图。
图42是示出状态分析装置的处理的流程图。
图43是示出状态分析装置的处理的流程图。
具体实施方式
以下,参照附图对实施方式的状态分析装置、状态分析方法、以及存储介质进行说明。
(第一实施方式)
图1是示出第一实施方式的状态分析装置1的结构的框图。状态分析装置1例如是根据在产品的制造过程中积累的各种数据来分析产生不良等的状态是由于何种原因而导致的装置。状态分析装置1例如具备存储部10、数据分类部100、分析部200、判定部300、显示部400。存储部10例如具备输入数据存储部11、变量定义数据存储部12、4m·验证项目主存储部13。数据分类部100例如具备4m定义部110、验证项目定义部120、数据分割部130。分析部200例如具备前处理部210、分析处理部220。判定部300具备分析结果汇总部310、汇总结果判定部320。显示部400例如具备判定结果显示部410。
数据分类部100、分析部200、以及判定部300分别通过cpu(centralprocessingunit)等处理器执行程序(软件)来实现。数据分类部100、分析部200、以及判定部300的功能部中的一部分或者全部可以通过lsi(largescaleintegration)、asic(applicationspecificintegratedcircuit)、fpga(field-programmablegatearray)等硬件实现,也可以通过软件与硬件的协作实现。
存储部10是供各种数据存储的存储装置。存储部10例如由hdd(harddiscdrive)、闪存、eeprom(electricallyerasableprogrammablereadonlymemory)、rom(readonlymemory)、或者ram(randomaccessmemory)等实现。在输入数据存储部11存储有在产品的制造过程中取得的各种输入数据。
图2是示出输入数据的例子的图。输入数据例如是1个产品的数据由1行(记录)表现的形式的数据。输入数据例如是从多达数百的多个制造工序收集的数百万种的庞大的数据。输入数据的说明变量(独立变量)可以像数据1那样为范畴分类(离散数据)的形式,也可以像数据2那样为数值(连续值数据)。输入数据的目标变量(从属变量)是像结果1那样用0或者1(例如良品或者不良品)表示的数据、或者是结果2那样的像成品率那样表示品质的程度的连续值数据。数据按照时间系列的顺序排列。
在变量定义数据存储部12,对输入数据的数据要素是说明变量还是目标变量进行定义并存储。图3是示出对数据的变量进行定义的例子的图。如图所示,图2的数据1以及数据2是说明变量,结果1以及结果2被定义为目标变量。
在4m·验证项目主存储部13,存储有用于对输入数据的数据要素进行分类的管理项目和验证项目。图4是示出针对4m的各管理项目分配的多个验证项目的图。管理项目例如由在品质管理中使用的4m的项目定义。4m例如是由人(man)、机械(machine)、材料(material)、以及方法(method)定义的管理项目。未被分类至4m的、其他(other)的管理项目可以在4m·验证项目主存储部13中定义。这些管理项目可以由用户任意输入。管理项目可以使用上述的4m以外的项目,能够任意地变更以及追加。
验证项目是用于发现针对4m的各管理项目定义的品质不良的原因的多个观点。验证项目例如是根据基于品质工程学、可靠性工程学的验证的观点设定的项目。关于验证项目,例如定义有不良的偏离、不良的偏差、初期不良、以及磨损不良。针对4m(man、machine、material、method)的4个管理项目分别分配不良的偏离、不良的偏差、初期不良、以及磨损不良的验证项目。
数据分类部100将针对4m的管理项目的每个分类的输入数据的数据要素分类至对应的多个验证项目的每个。数据分类部100将存储于输入数据存储部11的输入数据的数据要素分类至存储于4m·验证项目主存储部13的4m的管理项目和验证项目的组合的每个。4m定义部110对构成输入数据的数据要素对应于存储于4m·验证项目主存储部13的4m的管理项目的哪一个进行定义。数据要素与4m的管理项目之间的对应关系能够由用户适当设定。
图5是示出输入数据的数据要素与4m的管理项目之间的关系的图。如图所示,4m定义部110对构成输入数据的数据要素相当于4m的哪一个进行定义。数据要素与4m之间的关系能够由用户适当设定。例如数据1被分配4m中的material,数据2被分配machine。
验证项目定义部120对相对于输入数据的各数据要素的各验证项目进行定义。
图6a是示出相对于数据要素的验证项目的图。验证项目定义部120基于在4m定义部110中定义的数据要素与4m的对应关系、和在4m·验证项目主存储部13中存储的验证项目,对相对于输入数据的各数据要素的各验证项目进行定义。例如,数据1以及数据2的验证项目分别被分配不良的偏离、不良的偏差、初期不良、以及磨损不良。这些验证项目能够由用户适当地设定以及追加。
数据分割部130基于由4m定义部110以及验证项目定义部120定义的结果,将从构成输入数据的数据要素提取出的说明变量的数据以及目标变量的数据映射至由4m和验证项目构成的矩阵。图6b是示出映射结果的图。
分析部200基于由数据分类部100分类后的输入数据和存储于变量定义数据存储部12的变量定义,针对4m的管理项目和多个验证项目的组合的每个而对不良的有无进行分析。前处理部210基于数据形式,将由数据分类部100分类后的输入数据转换为能够进行后述的分析的数据形式,并且选择分析方法。
前处理部210具备说明变量数据类型判断部211、说明变量离散化部212、目标变量数据类型判断部213、分析方法选择部214。说明变量数据类型判断部211基于存储于变量定义数据存储部12的变量定义而提取出由数据分类部100分类后的数据的说明变量,判定各说明变量的数据是连续值数据还是离散数据。说明变量数据类型判断部211例如将数据的值的种类为5(=分割数量+1)以上的数据判定为连续值数据。说明变量数据类型判断部211例如将数据的值的种类小于5的数据判定为离散数据。
例如数据1为离散数据,数据2为连续值数据(参照图2)。
当说明变量数据类型判断部211判定为说明变量的数据是连续值数据的情况下,说明变量离散化部212进行将数据离散化的处理。图7是示出对作为连续值的说明变量进行离散化的处理的图。如图所示,例如,说明变量离散化部212将作为连续值的说明变量在4分位点分割为4部分而离散化。图8是示出离散化后的说明变量的图。如图8所示,说明变量离散化部212将作为说明变量的数据2的数值数据离散化为按照l、ml、mh、h这4个类别分类后的数据值。
若说明变量离散化部212进行离散化处理,则在后面的处理中无需识别所处理的数据是连续值数据还是离散化数据,后面的处理变得简单。离散化的数据的分割数量可以根据需要变更为不同的数字。例如说明变量数据类型判断部211将数据的值的种类为5以上的数据识别为连续值数据,也可以将该值根据说明变量离散化部212分割的数据的分割数量变更。
其次,目标变量数据类型判断部213识别数据的目标变量是连续值数据还是离散数据。目标变量数据类型判断部213对目标变量的值的种类进行计数,若目标变量的值的种类为3以上则识别为连续值数据,若目标变量的值的种类为2以下则识别为离散数据。例如作为目标变量的结果1的值的种类为0和1这2种,因此目标变量数据类型判断部213将结果1识别为离散数据(参照图2)。进而,作为目标变量的结果2的值的种类为3种以上,因此目标变量数据类型判断部213将结果2识别为连续值数据(参照图2)。
分析方法选择部214根据由目标变量数据类型判断部213作出的目标变量是连续值数据还是离散数据的识别结果来选择用于对数据进行分析的合适的分析算法。即、分析方法选择部214在选择分析方法时基于数据形式而针对验证项目的每个选择对数据应用的分析方法。例如在如图2所示的输入数据的情况下,分析方法选择部214针对结果1的数据选择作为离散数据的分析方法,针对结果2的数据选择作为连续值数据的分析方法。
分析处理部220针对由前处理部210进行前处理后的输入数据执行多个分析处理。分析处理部220具备不良的偏离分析部221、不良的偏差分析部222、初期不良分析部223、磨损不良分析部224。即、分析处理部220具备与验证项目的各个对应的多个分析部。这些分析部可以根据验证项目变更,也可以与其他验证项目对应地追加其他分析部。
不良的偏离分析部221根据不良的偏离的观点对不良的有无进行分析。不良的偏离分析部221提取出不良率(指目标变量取“1”的值的比率,在本说明书的说明中为同样的意思)偏离地高的数据。图9是示出不良率的偏离的图表。不良的偏离分析部221算出作为在某一个说明变量取某一数据值时与除此以外的情况相比不良率是否显著地变高的指标的数值。如图所示,例如在产品中使用的一个部件(material)通过不同的流通路径a~g获取的情况下,能够利用不良的偏离分析部221提取出不良率高的部件的流通路径。不良的偏离分析部221的处理的内容的详细情况将在后面叙述。
不良的偏差分析部222根据不良的偏差的观点对不良的有无进行分析。不良的偏差分析部222提取出成品率(目标变量)的偏差大的数据值。不良的偏差分析部222算出作为在某一个说明变量取某一数据值时与除此以外的情况相比成品率是否显著地变低的指标的数值。图10是示出成品率的偏差的图。如图所示,例如能够提取出:在产品由工作人员a~c组装的情况下,b的成品率的数据偏差多。不良的偏差分析部222的处理的内容的详细情况将在后面叙述。
初期不良分析部223根据初期不良的观点对不良的有无进行分析。初期不良分析部223提取在初期呈现出不良率变高的倾向的数据值。初期不良分析部223算出作为在某一个说明变量连续取某一数据值的制造条件下进行制造的情况下在制造初期与除此以外的情况相比不良率是否显著地变高的指标的数值。图11是示出初期的不良率高的数据的图。由初期不良分析部223进行的分析的目的在于:例如当在产品中使用某一部件的情况下,在产品的制造初期不稳定而引起不良的那样的事例中,发现因部件而导致的原因。初期不良分析部223的处理的内容的详细情况将在后面叙述。
磨损不良分析部224对4m的管理项目的各个与磨损不良的验证项目之间的相关性进行分析。磨损不良分析部224提取呈现出越是后期则不良率越高的倾向的数据值。磨损不良分析部224算出作为在某一个说明变量连续取某一数据值的制造条件下进行制造的情况下在制造后期与除此以外的情况相比不良率是否显著地变高的指标的数值。图12是示出后期的不良率高的数据的图。由磨损不良分析部224进行的分析的目的在于:例如在持续使用某一材料的情况下,在制造后期因材料劣化而引起不良的那样的事例中,发现因部件而导致的原因。磨损不良分析部224的处理的内容的详细情况将在后面叙述。
综上,分析部200在识别数据的数据形式时,识别数据的说明变量以及目标变量是连续值数据还是离散数据。分析部200在说明变量被识别为连续值数据的情况下将数据离散化处理为离散数据,并根据目标变量的识别结果选择针对数据应用的分析方法。
以下对各分析处理的具体的内容详细地进行说明。
不良的偏离分析部221根据数据的种类而实施t检验或者fisher检验。不良的偏离分析部221例如在目标变量为连续值数据的情况下,针对说明变量的数据值的每个实施t检验。在t检验中,算出的t值的绝对值越大,则判断为越明显地显著。不良的偏离分析部221为了调查在目标变量的平均值是否产生显著的差而算出p值。p值是用于判断根据采样数据得到的平均值的差的显著性的指标,若p值小则拒绝零假设,判断为存在因采样而导致的并非偶然的确实在统计学上显著的差。
图13是示出由不良的偏离分析部221进行的t检验的图。此处,t检验针对作为说明变量的数据1取值a的情况下的目标变量2进行。不良的偏离分析部221针对数据1为值a的情况和除此以外的情况分别算出采样数、目标变量2的平均值、标准偏差。然后,不良的偏离分析部221随后实施t检验并调查平均值中是否存在显著差。不良的偏离分析部221针对所有的说明变量的数据值执行这样的处理。图14是示出由不良的偏离分析部221进行的t检验的p值的列表的算出结果的图。
不良的偏离分析部221在目标变量为离散数据的情况下,针对说明变量的各数据值的每个实施fisher检验。进而,不良的偏离分析部221为了调查目标变量取“1(例如相当于不良品)”的值的频度是否在各数据值中显著地变高而算出p值。
图15是示出由不良的偏离分析部221进行的fisher检验的图。fisher检验是由2×2的分割表分割的数据的检验法。针对作为说明变量的数据1为值a的情况下的目标变量1进行。不良的偏离分析部221算出在数据1取值a的情况和除此以外的情况下目标变量1(结果1)的值取“1(例如不良品)”或者“0(例如良品)”的数据件数。进而,不良的偏离分析部221调查目标变量1的值为“1”的频度是否存在显著差。不良的偏离分析部221针对所有的说明变量的数据值执行这样的手续,将p值的列表作为结果输出。图16是示出由不良的偏离分析部221进行的fisher检验的p值的列表的算出结果的图。
不良的偏差分析部222仅在数据的目标变量为连续值的情况下执行处理。不良的偏差分析部222在目标变量为连续值的情况下针对说明变量的数据值的每个实施f检验。f检验是假定检验统计量在零假设下遵从f分布而进行的统计学检验。f分布是若将2个组的标准偏差之比设为统计量f,则在两组均遵从正规分布的情况下f遵从f分布的分布。图17是示出由不良的偏差分析部222进行的f检验的图。
不良的偏差分析部222例如在数据1取值a的情况和除此以外的情况下分别算出采样数、标准偏差,并实施f检验,调查在标准偏差中是否存在显著差。进而,不良的偏差分析部222为了调查在目标变量的标准偏差中是否存在显著的差而算出p值。图18是示出由不良的偏差分析部222进行的f检验的p值的列表的算出结果的图。
不良的偏差分析部222在数据的目标变量为离散值的情况下不执行处理。在目标变量仅取“0”或者“1”的离散值的情况下,目标变量的值的分布遵从二项分布。因此,这是因为偏差的差等价于由不良的偏离分析部221计算的平均值的差,没有重新计算的意思。
其次,在由初期不良分析部223以及磨损不良分析部224进行的分析处理中,作为前处理将针对各数据值的数据分割为初期、中期、后期。图19是示出在检验前被前处理后的数据的图。初期不良分析部223以及磨损不良分析部224对各数据值连续地出现多少次进行计数,将计数值分割为初期、中期、后期的3个区域,根据计数值而将数据分配至各区域。如图所示,例如数据1的a连续的的计数值1~6分别被分割为初期、中期、后期。其余的处理以与不良的偏离分析部221的处理几乎同样的步骤进行。
图20是示出由初期不良分析部223进行的t检验的结果的图。如图所示,初期不良分析部223在目标变量为连续值的情况下实施t检验。初期不良分析部223为了对初期的不良进行分析,例如在说明变量数据1为值a、且计数值为初期的情况下实施针对目标变量2的显著差检验。初期不良分析部223在目标变量为离散值的情况下实施fisher检验。图21是示出由初期不良分析部223进行的fisher检验的图。
初期不良分析部223针对所有的说明变量的数据值执行上述处理。进而,初期不良分析部223将p值的列表作为结果输出。图22是示出由初期不良分析部223进行的t检验或者fisher检验的p值的列表的算出结果的图。
由磨损不良分析部224进行的分析处理基本上与初期不良分析部223的处理同样。磨损不良分析部224为了对后期的不良进行分析,例如在说明变量数据1为值a、且计数值为后期的情况下实施针对目标变量2的显著差检验。关于磨损不良分析部224的分析处理,针对计数值后期执行与初期不良分析部223对计数值初期进行的处理完全相同的处理。通过上述处理,分析部200中的各分析处理结束。
判定部300对分析部200分析出的分析结果进行汇总并且基于汇总结果针对各管理项目和判断项目的组合判定不良的有无。判定部300将所得到的分析结果再次映射于4m×分析项目的矩阵。
分析结果汇总部310针对相对于4m的管理项目的验证项目的每个而对p值的最小值(粗体字)进行汇总。图23是将分析部为不良的偏离分析部221的情况下的分析结果进行汇总后的图。分析结果汇总部310以同样的方式将所有的分析部的分析结果进行汇总。图24是将所有的分析部的分析结果进行汇总后的图。
其次,汇总结果判定部320基于各p值而针对各管理项目与判断项目的组合判定不良的有无。汇总结果判定部320判定各p值相当于不良可能性高(p值小于1%)、不良可能性中(p值为1%以上且小于5%)、不良可能性低(p值为5%以上)的哪一个。即、汇总结果判定部320针对各管理项目和判断项目的组合而将目标变量和数据的关联的显著性划分为多个阶段进行判定。汇总结果判定部320作为阈值使用1%、5%的值,但这些值可以根据需要而变更。
显示部400具备将判定部300的判定结果用图像im显示的判定结果显示部410。图25是示出在判定结果显示部410显示的图像im的图。在图像im中,在4m(管理项目)×各分析部(验证项目)的矩阵分别显示判定部300的判定结果。在图像im的矩阵的各显示栏中,判定结果例如通过颜色的变化显示。
例如,在不良的可能性低的情况下,可以在图像im的矩阵的各显示栏显示蓝色的信号。在不良的可能性为中的情况下,可以在图像im的矩阵的各显示栏显示黄色的信号。在不良的可能性高的情况下,可以在图像im的矩阵的各显示栏显示红色的信号。进而,当不存在数据的情况下,可以使图像im的矩阵的各显示栏无显示。操作者能够通过辨别图像im的颜色来掌握各管理项目与验证项目的组合中的不良的有无。
以下对状态分析装置1的处理的流程进行说明。图26以及图27是示出状态分析装置1的处理的流程图。在4m定义部110中输入与4m的管理项目对应的数据(步骤s110)。在验证项目定义部120中输入验证项目(步骤s111)。数据分割部130将所输入的数据映射至由4m的管理项目和验证项目构成的矩阵(步骤s112)。
说明变量数据类型判断部211判断所映射的数据的说明变量是否为连续值数据(步骤s113)。在说明变量为连续值数据的情况下(步骤s113:是),说明变量离散化部212将说明变量的数据离散化(步骤s114)。
在说明变量并非连续值数据而是离散数据的情况下(步骤s113:否),前进至步骤s115的处理。目标变量数据类型判断部213判定数据的目标变量是否为连续值数据(步骤s115)。在目标变量为连续值数据的情况下(步骤s115:是),分析方法选择部214选择用于对连续值数据进行分析的合适的分析算法(步骤s116)。
不良的偏离分析部221在目标变量为连续值数据的情况下对不良的偏离进行t检验而进行分析(步骤s117)。不良的偏差分析部222在目标变量为连续值数据的情况下针对说明变量的数据值的每个实施f检验(步骤s118)。
初期不良分析部223在目标变量为连续值的情况下实施t检验(步骤s119)。磨损不良分析部224在目标变量为连续值的情况下实施t检验(步骤s120)。在步骤s115中,当目标变量并非连续值数据而是离散数据的情况下(步骤s115:否),分析方法选择部214选择用于对离散数据进行分析的合适的分析算法(步骤s116)。不良的偏离分析部221在目标变量为离散数据的情况下利用fisher检验对不良的偏离进行分析(步骤s131)。
不良的偏差分析部222在目标变量为离散数据的情况下不执行处理。初期不良分析部223在目标变量为离散值的情况下实施fisher检验(步骤s132)。磨损不良分析部224在目标变量为离散值的情况下实施fisher检验(步骤s133)。分析结果汇总部310按照针对4m的管理项目的验证项目的每个而将分析结果进行汇总(步骤s140)。
汇总结果判定部320基于分析结果判定不良的有无(步骤s141)。在不良的可能性低的情况下(步骤s142:是),判定结果显示部410显示蓝色的信号。
在不良的可能性为中的情况下(步骤s143:是),判定结果显示部410显示黄色的信号。在不良的可能性高的情况下(步骤s144:是),判定结果显示部410显示红色的信号。当不存在数据的情况下,判定结果显示部410无显示。
根据以上说明了的第一实施方式,状态分析装置1具有数据分类部100、分析部200、判定部300,由此,能够利用各种各样的分析方法1次对在产品产生的状态进行包罗性的分析。即,根据状态分析装置1,能够基于在产品的制造过程中积累的庞大的量的各种数据来分析产生不良等的状态是因何种原因而导致的。根据状态分析装置1,能够将在与多个管理项目对应的多个验证项目中产生不良等的状态以可视化的方式容易地掌握。
具体地说,根据状态分析装置1,只要输入数据为一定的数据形式,则无论是针对何种数据都能够自动地输出显示在4m(+other)×在品质工程学中使用的4个分析方法的矩阵中的不良的俯瞰图。由此,根据状态分析装置1,无需对分析方法进行试错,能够在短时间内容易地掌握在品质管理的何处存在课题,也能够防止观点的看漏。
(第二实施方式)
在第一实施方式中,假设在分析部200中对是否产生不良的偏离、不良的偏差、初期不良、以及磨损不良的各验证项目的原因进行分析而进行说明。分析的观点并不限定于此,也可以对分析部200追加进行其他的分析方法的结构。在第二实施方式中,对上述的验证项目追加进一步的验证项目而分析不良的原因。
图28是示出第二实施方式所涉及的状态分析装置2的结构的框图。状态分析装置2与第一实施方式相比对分析部200追加了与已经准备的验证项目不同的其他的分析方法即休哈特分析部225。进而,在4m·验证项目主存储部13也追加存储有与已经准备的验证项目不同的其他的验证项目即休哈特分析的验证项目。在状态分析装置2中,能够追加或者删除分析的验证项目以及处理模块而自由地取舍选择验证项目。
图29是示出对数据的变量进行定义的例子的图。如后面即将说明的那样,为了进行基于休哈特的管理图的分析,需要确定用于定义被称为“组”的集团单位的变量,在该例子中数据1相当于此。图30是示出针对4m的各管理项目分配的多个验证项目的图。此处,与第一实施方式相比追加了休哈特分析的验证项目(参照图4)。
图31是统计量以时间系列变化的休哈特的管理图。休哈特分析是判定在将根据数据算出的统计量按照时间系列的顺序排列时的变动是否为在统计学上极其稀少地产生的异常的变动的方法。如图所示,在某一天确认到急剧的变动数据,利用休哈特分析来分析该变动是否为异常的变动。
图32是示出休哈特的异常判定规则的图。如图所示,异常的判定根据是否满足8个规则来进行。图33是示出以时间系列产生的数据的变动的图。如图所示,在休哈特的管理图的考虑方法中,认为生产工序的品质要素(4m)均匀的时间性的模块(以下称为“组”)内的平均的组内变动被看作组1那样偶然变动(通常的状态)。进而,在休哈特的管理图的考虑方法中,无法用偶然变动说明的组2那样的组内变动或组3那样的组间变动(与通常不同的状态)被作为异常检测。
在休哈特的管理图中,对根据数据的各组算出的统计量进行描点(参照图31)。统计量例如是组的平均值、中央值、偏差(最大值与最小值之差)等。图34是示出利用休哈特分析来分析的异常的图。在基于休哈特管理图的分析中,通过在产生异常的组和未产生异常的组中对不良率进行比较,来调查休哈特的异常与不良是否存在相关性。
以下,对由休哈特分析部225进行的具体的分析步骤进行说明。在进行休哈特的分析时,在变量定义数据中,预先定义哪个数据是规定组的变量(以下称为组变量)(参照图29)。对4m·验证项目主存储部13的验证项目追加“休哈特”。对分析部200追加休哈特分析部225。此处,在追加4m·验证项目主存储部13的验证项目和分析部200的休哈特分析部225的情况下,可以由用户设定,也可以通过与其他的状态分析装置2连接而自动追加。
图35是示出在休哈特分析中使用的输入数据的图。针对成为分析对象的输入数据,假设在变量定义数据存储部12中数据1被指定为组变量。前提是数据按照时间系列顺序排列。在该条件下,当组变量连续取同一值的情况下认为这些数据是同一组而将输入数据利用数据分割部130分割为组单位,并利用休哈特分析部225针对每个组算出统计量(例如平均值)。
图36是示出由休哈特分析部225进行的统计量的算出结果的图。若将数值在图表描点,则能够得到时间系列图表(参照图31)。休哈特分析部225检索以组单位算出的统计量中是否存在满足8个规则(参照图32)中的任一个的组。若休哈特分析部225检索的结果是存在满足8个规则的组则判定为在该组产生异常。图37是示出以组单位进行判定处理后的结果的图。其次,休哈特分析部225将成为组单位的图37的数据展开为原来的个体单位的数据,并判定在连续的组的各个中产生的异常。
图38是示出基于休哈特分析的异常判定的图。如图所示,休哈特分析部225例如在像组5那样将1个组判定为异常的情况下,认为在该组所包含的所有的个体中产生异常而进行处理。以后,休哈特分析部225通过检验来判定在休哈特的异常与目标变量之间是否存在相关性。休哈特分析部225在存在休哈特的异常的个体集合和不存在休哈特的异常的个体集合中执行检验。该处理与在第一实施方式中说明了的分析不良的偏离的手续相同。
休哈特分析部225例如若输入数据的目标变量为连续值则进行t检验。图39是示出由休哈特分析部225进行的t检验的结果的图。休哈特分析部225例如若输入数据的目标变量为离散值则实施fisher检验,获得检验p值。图40是示出由休哈特分析部225进行的fisher检验的结果的图。以后的状态分析装置2中的处理与第一实施方式相同。
若在判定部300中将检验p值汇总在由4m和各验证项目构成的矩阵中,并在显示部400利用表示判定结果的图像im将其可视化,则附加了基于休哈特的管理图的分析的映射完成。图41是示出在判定结果显示部显示的图像im的图。
以下对状态分析装置2的处理进行说明。除了s221以及s234的由休哈特分析部225进行的分析处理以外均与第一实施方式的处理相同,因此,以下仅对s221以及s234的处理内容进行说明。图42以及图43是示出状态分析装置2的处理的流程图。
在验证项目定义部120中输入附加了休哈特分析的验证项目(步骤s211)。休哈特分析部225算出数据的说明变量的每个组的统计量,并针对每个组判定是否满足休哈特的异常判定规则。休哈特分析部225在目标变量为连续值的情况下在存在休哈特的异常的个体集合和不存在休哈特的异常的个体集合中执行t检验而算出检验p值(步骤s221)。休哈特分析部225在目标变量为离散值的情况下在存在休哈特的异常的个体集合和不存在休哈特的异常的个体集合中执行fisher检验而算出检验p值(步骤s234)。
根据以上说明了的第二实施方式所涉及的状态分析装置2,通过在分析部200追加其他的分析部,能够将在用户所期望的验证项目中产生不良等的状态以可视化的方式容易地掌握。具体地说,根据状态分析装置2,通过附加基于休哈特的管理图的分析,能够自动提取出对品质造成影响的“与通常不同的状态(异常)”。
根据以上说明了的至少一个实施方式,状态分析装置1具有数据分类部100、分析部200、判定部300,由此能够利用各种各样的分析方法对在产品中产生的状态进行分析。
虽然对本发明的几个实施方式进行了说明,但上述实施方式只不过是作为例子加以提示,并非意图限定发明的范围。上述实施方式能够以其他各种各样的方式实施,能够在不脱离发明的主旨的范围进行各种省略、置换、变更。上述实施方式及其变形包含于发明的范围或主旨中,同样也包含于技术方案所记载的发明及其等同的范围中。例如,实施方式的状态分析装置除了能够在分析生产线的不良原因的场合应用之外,还能够用于分析生产线以外的不良原因。
- 还没有人留言评论。精彩留言会获得点赞!