一种基于用户情感和时间动态的旅游目的地推荐方法与流程
本发明涉及旅游推荐领域,尤其涉及一种基于旅游目的地推荐系统。
背景技术:
在过去十年中,互联网上可用的信息量和用户数量大大增加,对于计划访问不知名的旅游目的地并且必须安排旅行计划的用户来讲,这些信息会特别有价值。然而,搜索引擎提供的旅游目的地信息的可能性列表时是压倒性的。用户需要花费大量的时间和精力评估收集到的信息,并花费更多的时间来提取有用的信息。
推荐系统可以帮助用户应对信息过载,并向他们提供个性化的推荐、内容和服务。在旅游领域,旅游推荐系统通过分析其显性或隐性反馈,自动学习用户的喜好,使旅游休闲资源的特点与用户需求相匹配。事实上,旅游目的地的推荐比其他旅游目的地更为复杂,因为用户对旅游目的地的评价数量很少,数据更加稀疏,因此,综合概况不容易建立。而且旅游目的地推荐易受到季节、交通、成本等因素的影响,因此很难构建出一个综合了许多有价值的因素的旅游目的地的推荐模型。
技术实现要素:
本发明所要解决的技术问题是实现一种能够基于用户情感和时间动态的旅游目的地推荐系统,提出了一个时间和空间的动态模型,嵌入推荐系统中提高推荐准确性。
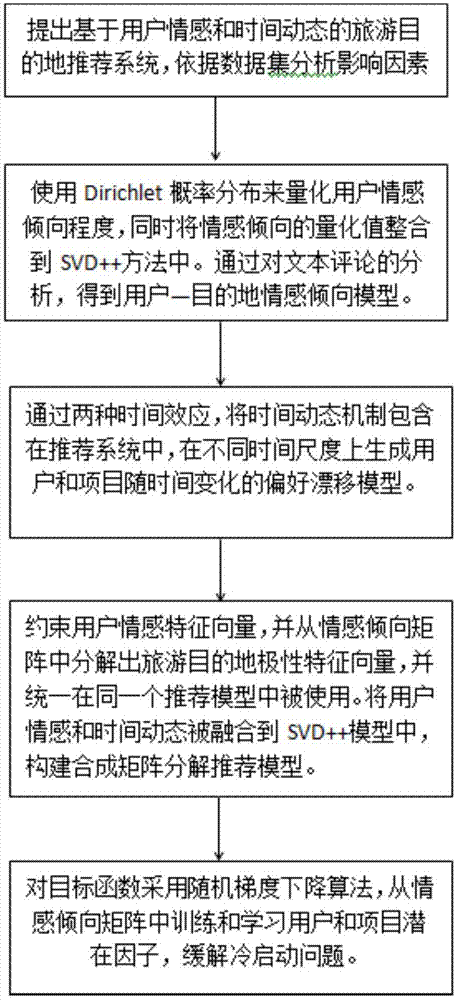
为了实现上述目的,本发明采用的技术方案为:一种基于用户情感和时间动态的旅游目的地推荐方法:
s1、提出基于用户情感和时间动态的旅游目的地推荐系统,依据数据集分析影响因素
s2、使用dirichlet概率分布来量化用户情感倾向程度,同时将情感倾向的量化值整合到svd++方法中。通过对文本评论的分析,可以得到用户—目的地情感倾向矩阵。
s3、通过两种时间效应,将时间动态机制包含在推荐系统中,这样项目的偏差就会被添加到时间动态中,尝试用不同的时间尺度来捕捉旅游目的地偏差。
s4、约束用户情感特征向量,并从情感倾向矩阵中分解出旅游目的地极性特征向量,并统一在同一个推荐模型中被使用。整合用户情感和时间动态融合到svd++模型中,合成矩阵分解推荐模型。
s5、对目标函数采用随机梯度下降算法,从情感倾向矩阵中训练和学习用户和项目潜在因子,缓解冷启动问题。
所述s2中,对文本评论的分析使用dirichlet概率分布来量化用户情感倾向程度,同时将情感倾向的量化值整合到svd++方法中。
所述s2包括以下步骤:
s21、将文本评论分为几个条款;
s22、识别给出正面或负面意见的条款;
s23、计算情感倾向的用户关于旅游目的地。
所述dirichlet概率分布定义如下:
计算文本极性公式如下:
定义用户对旅游目的地的情感倾向为:
所述s3将项目的偏差添加到时间动态中,并采用不同的时间尺度来捕捉旅游目的地偏差。
所述s4中时间动态模型中预测公式如下:
其μ中表示整体平均评分,参数bu和bi分别表示观察到的用户u和项目i与平均值的偏差,iu表示用户u评价的项目集合,yj表示用户u关于项目j的隐式反馈。
所述s5中目标函数获得方式如下:
所述s5采用加权正则化处理方法,目标函数公式如下:
其中,正则化参数,λ,λs,用户特殊向量pu、项目特殊向量qi、用户情感特殊向量θu和旅游目的地极性特殊向量zi,ui表示用户集里评价过项目i的用户。
本发明旅游目的地推荐方法提高了推荐准确率和质量,并在公开可用的数据集上进行了一系列实验评估,表明所提出的推荐系统是优于现有的推荐系统。
附图说明
下面对本发明说明书中每幅附图表达的内容作简要说明:
图1为基于用户情感和时间动态的旅游目的地推荐方法流程图;
图2情感分析过程图;
图3(a)为查看目标等级的编号图;
图3(b)为特征词分布图;
图4(a)按日期分的旅游人数图;
图4(b)按月份的平均评分图;
具体实施方式
本发明是一种基于用户情感和时间动态的旅游目的地推荐方法,提出了一个时间和空间的动态模型,嵌入推荐系统中提高推荐准确性。旅游目的地推荐方法应用在旅游目的地推荐系统中,如含有相关软件的pc机或互联网云端,如图1所示,该方法包括如下步骤:
图1为本发明实施例,提供一种基于用户情感和时间动态的旅游目的地推荐系统的流程图,该方法包括如下步骤:
s1、提出基于用户情感和时间动态的旅游目的地推荐系统,依据数据集分析影响因素;
本发明研究中使用的数据集是从中国著名的旅游社交网络同程提取的。本文从2012年1月到2014年12月期间从312,896位用户获得了与5,722个旅游目的地相关的985,683条评论。评论包含结构化元数据,包括星级评分(从1到5),日期、文字评论和旅游类别,清楚地表明了旅游资料的稀疏性。
图3(a)和图3(b)给出了这六个主要因素的特征词的分布。这六个方面的特征词总数占70.1%,特别是风景数量,是用户最关心的话题。通过数据分析,发现用户在文本评论和星级评分中的情感强烈正相关。因此,对用户情感的更好的解释范围赋予了本文在旅游目的地推荐系统中融合文本评论的动机。
第二组调查结果显示,游客人数是周期性的,长期来看也是逐渐增加的。而且,平均评级随时间波动。本文按月计算了游客人数,如图4(a)所示。如图4(b)所示。由于旅游目的地受季节影响,游客的经历也会发生变化。统计结果清楚地表明,发现游客的高峰数量与中国的假期有关。因此,想提出一个假设,即来自用户的关于旅游目的地的评论是与时间敏感相关的。
基于上述两个发现,将文本评论和时间因素整合到旅游目的地推荐模型中。
s2、使用dirichlet概率分布来量化用户情感倾向程度,同时将情感倾向的量化值整合到svd++方法中。通过对文本评论的分析,可以得到用户—目的地情感倾向矩阵模型。
从文本评论中挖掘知识对于旅游建议尤为重要。使用意见挖掘技术来计算与旅游目的地相关的用户情感的值,而不仅仅分析文本评论的主题。意见挖掘算法的主要动机是量化用户对旅游目的地的情感倾向。在这个过程的最后,可以从文本评论数据集中获得一个用户目标情感矩阵。如图2所示,给出一组用户文本评论,可以分成以下步骤:
s21、将文本评论分为几个条款;
s22、识别给出正面或负面意见的条款;
s23、计算情感倾向的用户关于旅游目的地。
使用dirichlet概率分布来量化用户情感倾向程度,dirichlet分布表示为
其中,p、r和α并且分别表示概率变量、极性观测变量和先验基础速率变量。w表示非信息性先验权重,r(li)表示具有第i个子句极性的k个可能结果的观察值序列,α(li)代表第i个子句极性的结果满足α(li)>0和
从公式(2)计算出文本的极性,所使用概率期望如下:
文本极性根据计算公式(3)计算的是一个带有分量的向量。本文需要将矢量转换为点值。定义用户对旅游目的地的情感倾向的价值为:
在公式(4)中,s的值分布在[0,1]的范围内。
根据前面提到的第二个发现,本文的情感模型建立在koren提出的被称为svd++模型的最先进的模型的基础之上[8]。svd++背后的想法是考虑用户和项目的偏见和评价项目的隐含影响,除了用户和项目特定的向量对评级预测。形式上,来自用户的项目的评分由以下等式预测:
其μ中表示整体平均评分,参数bu和bi分别表示观察到的用户u和项目i与平均值的偏差。iu表示用户u评价的项目集合,yj表示用户u关于项目j的隐式反馈。
此前,强调从文本评论的意见挖掘对于更好的建议的重要性,并采用意见挖掘来计算情感倾向的价值。因此,通过结合用户对旅游目的地的情感倾向来改善svd++模型。具体而言,用户情感对旅游目的地的明确影响可以与评价项目相同的方式考虑,由以下给出:
现在,一个用户被建模
更进一步地,本文将旅游目的地极性特定向量z合并到模型中,这是基于方程(8)。同样,旅游目的地被表示为
s3、通过两种时间效应,将时间动态机制包含在推荐系统中,项目的偏差就会被添加到时间动态中,尝试用不同的时间尺度来捕捉旅游目的地偏差。
大部分时间可变性由于两种主要的时间效应被包括在推荐模型。第一种代表一个项目随时间变化的受欢迎程度,另一种则与随着时间推移而更改基准评级的用户有关。之前已经揭示了旅游目的地的时间效应,它们可以分为三个类别:季节性的影响、节日的影响和长期的影响。项目的偏差就会被添加到时间动态中,变成了公式(10)
bi(t)=bi+bi,season(t)+bi,holiday(t)(10)
如公式(10)所示,会尝试用不同的时间尺度来捕捉旅游目的地偏差的变化。在本文中,定义season(t)和holiday(t)如下:
season(t)∈{feb,jan,mar,apr,may,june,july,aug,sep,oct,nov,dec}(11)
holiday(t)∈{newyear’sday,springfestival,chingmingfestival,laborday,thedragonboatfestival,mid-autumnfestival,nationalday}(12)
类似地,也可以在用户这边找到周期性的影响。例如用户可能更倾向于在假期或周末旅行。但与旅游目的地不同的是,对单个用户的评分只有很少的一部分。这意味着不能将时间片分割成更小的间隔。在本文中,定义了用户的偏差:
bu(t)=bu+bu,t,(13)
公式(13)中bu,t代表了周末和节日的特殊时间。
事实上,在时间动态模型中,没有增加长期影响,因为用户评分很稀疏,而旅游目的地的评分相对稳定。因此,可以改进模型如下:
s4、约束用户情感特征向量,并从情感倾向矩阵中分解出旅游目的地极性特征向量,并统一在同一个推荐模型中被使用。整合用户情感和时间动态融合到svd++模型中,合成矩阵分解推荐模型。
将上面提到的两个模型合并到一个模型中,并将其称为synst-stsvd++模型(用户情感和时间动态合成svd++模型)。当用户情感和时间动态被融合到svd++模型中,就能够获得一个更复杂的模型,并且将目标函数最小化如下:
为了减少模型的复杂性,对所有变量使用相同的正则化参数,λ。此外,约束用户情感特征向量,并从情感倾向矩阵中分解出旅游目的地极性特征向量。这些特征向量共享相同的特征空间,以便将评分矩阵和情感倾向矩阵连接在一起。这样,这两种信息就可以在一个统一的推荐模型中被使用。因此,将公式(6)和公式(15)整合形成新的模型,新的目标函数由给出如下:
而且,本文还采用了一种叫做加权正则化的技术,在学习参数时避免了过度拟合,并使用了两种正则化参数,λ,λs。由于活跃用户对多个目的地进行了评分,并留下了大量文本评论,因此考虑了用户特殊向量pu、项目特殊向量qi、用户情感特殊向量θu和旅游目的地极性特殊向量zi。正如郭等人所建议的那样[33],本文认为评分多个项目的用户和评级较低的项目会受到更多的惩罚。因此,改进的损失函数最小化是基于公式(16)如下:
ui表示用户集里评价过项目i的用户。
s5、对目标函数采用随机梯度下降算法,从情感倾向矩阵中训练和学习用户和项目潜在因子,缓解冷启动问题。
模型的目标是最优化地学习pu和qi,并准确地为用户的评分建模。同时,根据用户的文字评论,获得最可能的用户情感特殊向量θu,以及旅游目的地极性特殊向量zi。所以由给出的公式(16)可以获得最小化的目标函数。对pu,qi,bu,bi,yi,zi和θu执行以下的梯度下降,结果如下:
在冷启动的情况下,用户留下少量评分或项目收到少量评级,情感倾向矩阵的分解可以比仅仅评分矩阵分解,要帮助产生更多的可靠的用户潜在因子和项目潜在因子向量。即使在极端的某些用户和项目没有评分的情况下,公式(20)和(21)可以确保用户和项目潜在因子向量可以从情感倾向矩阵中被训练和学习。这表明将情感倾向并入矩阵分解模型可以缓解冷启动问题。
梯度下降方法的主要计算开销在于评估目标函数
上面结合附图对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的方法构思和技术方案进行的各种非实质性的改进,或未经改进将本发明的构思和技术方案直接应用于其它场合的,均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!