一种基于A-TrAdaboost算法的多源社区标签发展趋势预测方法与流程
本发明涉及数据挖掘、图结构分析技术,特别是涉及一种基于a-tradaboost算法的多源社区标签发展趋势预测方法。
背景技术
当前随着移动互联网和智能设备的广泛普及,改变了人们的生活方式,人们更倾向于在网络上发表自己看法和搜集自己需要的信息,因此在线问答社区变得越来越活跃和流行。由于问答社区中的帖子数量巨大,用户在问答社区中获取的信息主要根据问题答案的标签来进行筛选和推荐,随着时间的推移,标签的数量也越来与巨大,问答社区中的标签研究日益成为关注的热点。
傅晨波等人(见文献[1]fuc,zhengy,lis,etal.predictingthepopularityoftagsinstackexchangeqacommunities[c]//complexsystemsandnetworks(iwcsn),2017internationalworkshopon.ieee,2017:90-95.即傅晨波,郑永立,李诗迪.预测stackexchange问答社区标签流行性[c]//复杂的系统和网络(iwcsn),2017国际研讨会.ieee,2017:90-95。)已经研究了问答社区中新标签未来的流行性发展趋势预测,但是其预测模型仅根据单个社区中标签数据来进行模型构建。在这种情况下,当在一些数据量较小的社区或者新出现的社区中使用模型时,由于标记数据样本较少,会使得训练后的模型并不理想。迁移学习从一个相关并同时拥有丰富训练样本的领域中训练模型,并分享到目标领域。利用迁移学习可以解决目标领域训练数据较少的缺陷。因此我们利用迁移学习的思路在其他较大社区中进行模型训练,然后再迁移到目标社区,以提高预测模型的精度。
单源迁移时常常会遇到负迁移的状况,使得迁移过来的效果并不好。为了解决这一问题,其中一种方法是设置不同的样本权重,通过设置不同样本之间的权重,选择出对目标任务有帮助的样本,提高迁移学习的效果。tradaboost(见文献[2]daiw,yangq,xuegr,etal.boostingfortransferlearning[c]//internationalconferenceonmachinelearning.acm,2007:193-200.即戴文渊,杨强,薛贵荣,俞勇.迁移学习集成[c]//国际机器学习会议.acm,2007:193-200.)方法利用迭代更新权重的方法,通过对每次训练的模型在目标领域上的分类效果,计算误差,反馈更新样本的权重,得出最后的分类模型。另外一种方法是多源迁移的模型框架。已有的多源迁移学习方法已经很多,目前比较常用的迁移学习方法是根据不同领域之间的特征分布的距离作为其衡量领域之间的相似性,进而对不同领域构建的基分类器进行加权。在使用迁移学习的方法来预测问答社区标签流行性发展趋势的预测问题中,根据特征分布之间的差异性来衡量不同领域之间的相似性大小,不能取得较好的迁移提升效果。
技术实现要素:
为了解决跨社区标签流行性的预测问题,为了较好的衡量涉及网络结构的不同领域之间的差异,和改善tradaboost在在具有负迁移数据源上的迁移效果的鲁棒性,本发明提出一种基于网络结构相似性的a-tradaboost算法来预测在线问答社区中新标签在未来的流行性发展趋势。
本发明解决其技术问题所采用的技术方案如下:
一种基于a-tradaboost算法的多源社区标签发展趋势预测方法,包括如下步骤:
步骤1:构建问答社区中标签网络,如果同一个问题帖子下边出现多个标签,则认为这些标签具有连边,构建问答社区标签网络,得到源领域和目标领域社区的网络结构集合
步骤2:计算各社区中网络结构的向量表征,采用graph2vec的方法,将每个网络gi∈ω用一个维度为d的向量来进行表征,最后学习得到源领域网络结构表征向量
步骤3:计算源领域与目标领域之间的结构相似性,计算源领域网络结构表征向量
步骤4:构建基于a-tradaboost算法的多源社区标签流行性预测模型。通过提取源领域
进一步,所述步骤1中,构建问答社区中标签网络,对源领域问答社区si中,统计其社区中所有的新标签,按时间排序,取比例为前α=10%中的新标签中最后一个标签出现的时刻
再进一步,所述步骤2中,计算各个社区中网络结构的向量表征,采用graph2vec(见文献[3]narayanana,chandramohanm,venkatesanr,etal.graph2vec:learningdistributedrepresentationsofgraphs[j].arxivpreprintarxiv:1707.05005,2017.即narayanana,chandramohanm,venkatesanr.graph2vec:学习图的分布式表征[j].arxivpreprintarxiv:1707.05005,2017.)的方法,将每个网络gi∈ω用一个维度为d的向量来进行表征;首先,提取网络gi的根子图结构,利用weisfeiler-lehman(wl)核方法对网络gi中每一个节点依次提取最小子图结构,集合为
更进一步,所述步骤4中,构建基于网络结构相似性的a-tradaboost算法模型,操作如下:根据文献[1]中提取特征和标签标记的方法,得到源领域社区和目标领域的特征标记样本
其中,βt表示为当前的基分类器的权重。再根据误差率更新训练样本的权重,
使得对目标领域有益的样本权重增加,反之权重降低,迭代n次后,对最后得到的n个基分类器{f1,f2,…,fn}进行加权投票得出最后的出最后的预测模型ft,
本发明的有益效果表现在:利用网络图表征的方法,得到各个网络的向量表征,进而计算网络之间的相似性,作为不同问答社区之间的领域距离,并将网络结构之间的相似性作为多源迁移学习算法tradaboost的初始权重,在进行跨社区预测新标签流行性问题时,能够较好的避免多源迁移中的负迁移问题,提高模型的训练时间和精度。
附图说明
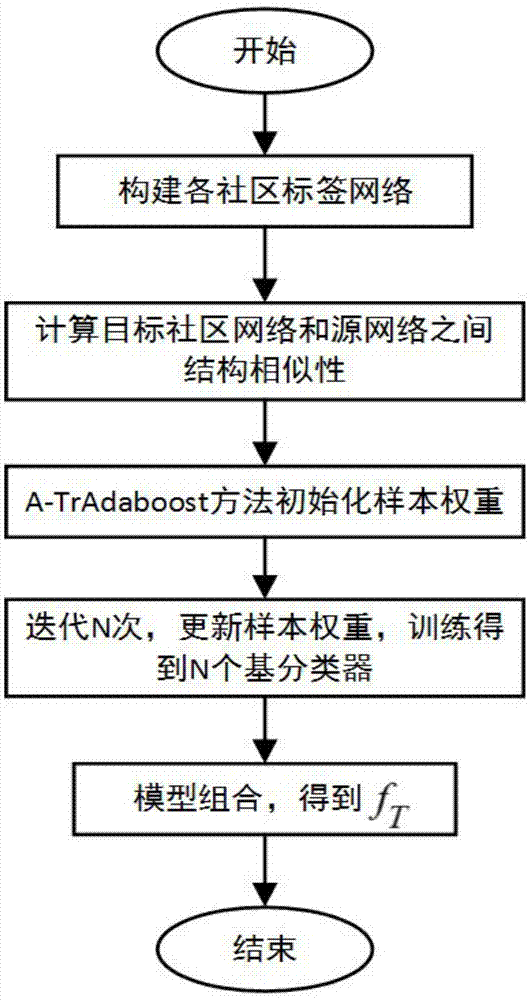
图1基于a-tradaboost算法的多源社区标签发展趋势预测方法流程框图;
图2为a-tradaboost算法的基本步骤。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的描述。
参照图1和图2,一种基于a-tradaboost算法的多源社区标签发展趋势预测方法,本发明使用了stackexchange问答网站中数据进行实例分析,数据采用了部分问答社区中每个帖子创建时间,帖子id,用户id,帖子标签等信息,构建标签网络,提取标签对应的结构特征和非结构特征,进行提出的a-tradaboost模型的构建和训练。
本发明具体分为以下四个步骤::
步骤1:构建问答社区标签网络。
步骤2:计算各个社区中网络结构的向量表征。
步骤3:计算源领域与目标领域之间的相似性。
步骤4:构建基于a-tradaboost算法的多源社区标签流行性预测模型。
所述步骤1中,构建问答社区中标签网络,操作如下:如果同一个问题帖子下边出现多个标签,则认为这些标签具有连边,构建社区的标签网络;例如对源领域问答社区si中,统计其社区中所有的新标签,按时间排序,取比例为前α=10%中的新标签中最后一个标签出现的时刻社区所有标签的网络,作为该社区的网络结构时刻的社区网络结构初步形成,其结构特征能够代表该领域社区的网络结构,最后得到源领域和目标领域社区的网络结构集合
所述步骤2中,计算社区中网络结构的向量表征,采用graph2vec的方法,将每个网络gi∈ω用一个维度为d的向量来进行表征;首先,提取网络gi的根子图结构,利用weisfeiler-lehman(wl)核方法对网络gi中每一个节点依次提取最小子图结构,集合为
所述步骤3中,计算源领域与目标领域之间的结构相似性,计算源领域网络结构表征向量
所述步骤4中,构建基于a-tradaboost算法的多源社区标签流行性预测模型。具体操作如下,根据文献[1]中提取特征和标签标记的方法,得到源领域社区和目标领域的特征标记样本
其中,βt表示为当前的基分类器的权重。再根据误差率更新训练样本的权重,
使得对目标领域有益的样本权重增加,反之权重降低,迭代n次后,对最后得到的n个基分类器{f1,f2,…,fn}进行加权投票得出最后的出最后的预测模型ft,
如上所述为本发明在问答网站stackexchange中进行了基于网络结构相似性的a-tradaboost算法模型的构建,本发明选择多个较大社区里的标记数据作为源领域数据,对目标领域社区中进行多源迁移模型的构建,根据不同社区之间的网络结构相似性,作为源领域社区与目标领域社区之间的初始权重,通过迭代更新得出最后的预测模型,相比于传统的tradaboost方法,能够提高模型训练时间,在某些具有负迁移的数据上,能够具有较好的提升效果。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变,修改,甚至等效,但都将落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!