一种基于影响因子分析的日最大负荷区间预测方法与流程
本发明涉及能源预测技术领域,尤其是指一种基于影响因子分析的日最大负荷区间预测方法。
背景技术
由于电力系统中蕴含了各种不确定因素,使得决策工作必然面临一定程度的风险,所以在决策时必须考虑电力需求的不确定性。传统确定性预测方法的结果不能反映需求的不确定性,而区间预测可满足这种客观要求。区间预测的结果不是一个简单的确定性数值,而是一个区间,并且这个区间对应了一定水平的概率置信水平,能描述未来预测结果的可能范围。根据区间预测结果,电力系统决策人员在进行生产计划、系统安全分析等工作时能够更好地认识到未来负荷可能存在的不确定性和面临的风险因素,从而及时作出更为合理的决策。因此,分析电力系统负荷的变化规律,研究电力负荷区间预测方法,实现电力负荷的不确定性预测具有重要的理论意义和实用价值。
目前区间预测方法存在以下不足:
1、计算复杂;
2、假设性强;
3、计算时间长。
技术实现要素:
本发明的目的在于克服上述现有技术的不足,提供一种基于影响因子分析的日最大负荷区间预测方法,实现对配电区负荷的中期准确预报。
为实现上述目的,本发明的技术方案是:
一种基于影响因子分析的日最大负荷区间预测方法,其特征在于,所述方法包括
下载历史负荷数据,获得历史负荷曲线;
利用中值滤波法找出历史负荷曲线的趋势曲线,获得趋势项负荷;
对电力系统中的影响因子和趋势项负荷进行主成分分析,整合出若干个主成分,若干个主成分作为输入,趋势项负荷作为输出,在支持向量机上实现负荷的趋势项预测;
从历史负荷曲线中减去趋势项负荷,得到随机项;对随机项的曲线按幅值最大最小为上下限平均划分成若干个区间,计算转移概率矩阵,转移概率最大的区间,即为随机项的预测区间;
对随机项利用马尔科夫模型进行区间预测,获得负荷的趋势项预测值;
将负荷的趋势项预测值与随机项的预测区间相加,得到原始预测区间。
所述方法还包括:
利用三次样条插值的方法提取出历史负荷曲线的上、下包络线;
将原始预测区间的上、下限与上、下包络线对比,计算误差;
将误差加入到原始预测区间中,得到最终预测区间。
所述的影响因子包括该负荷覆盖的区域面积、工业/商业/居民用电占比。
所述对电力系统中的影响因子和趋势项负荷进行主成分分析,整合出若干个主成分的过程为:
第一步:假设有n个样本,p个变量,观测数据矩阵为:
其中,x为观测数据矩阵,xij为第i个样本第j个变量的值。
第二步:计算样本的相关系数矩阵
假定原始数据标准化后仍用x表示,则经标准化处理后的数据的相关系数为:
其中,rij为第i个变量与第j个变量的相关系数。
第三步:用雅克比方法求相关系数矩阵r的特征值(λ1,λ2,…,λp)和相应的特征向量ai=[ai1,ai2,…,aip],i=1,2,…,p;
第四步:选择重要的主成分,并写出主成分表达式;
根据各个主成分累计贡献率的大小选取前k个主成分,这里贡献率就是指某个主成分的方差占全部方差的比重,实际也就是某个特征值占全部特征值合计的比重,即
其中,λi为第i个变量的特征值。
贡献率越大,说明该主成分所包含的原始变量的信息越强;主成分个数k的选取,主要根据主成分的累积贡献率来决定,要求累计贡献率达到85%以上;
主成分表达式表示如下:
zi=ai1×x1+ai2×x2+…+aip×xp
其中,zi为第i个主成分,xj为第j个变量,aij为第i个主成分中第j个变量的特征向量。
本发明与现有技术相比,其有益效果在于:
1、预测结果稳定,预测精度高;
2、本发明预测方法是数据驱动、自适应的方法,其预测结果不依赖于使用者的先验知识;
3、本发明思路简单、直观、易操作;
4、本发明对电网的调度、规划等实际情况具有很强的指导意义。
附图说明
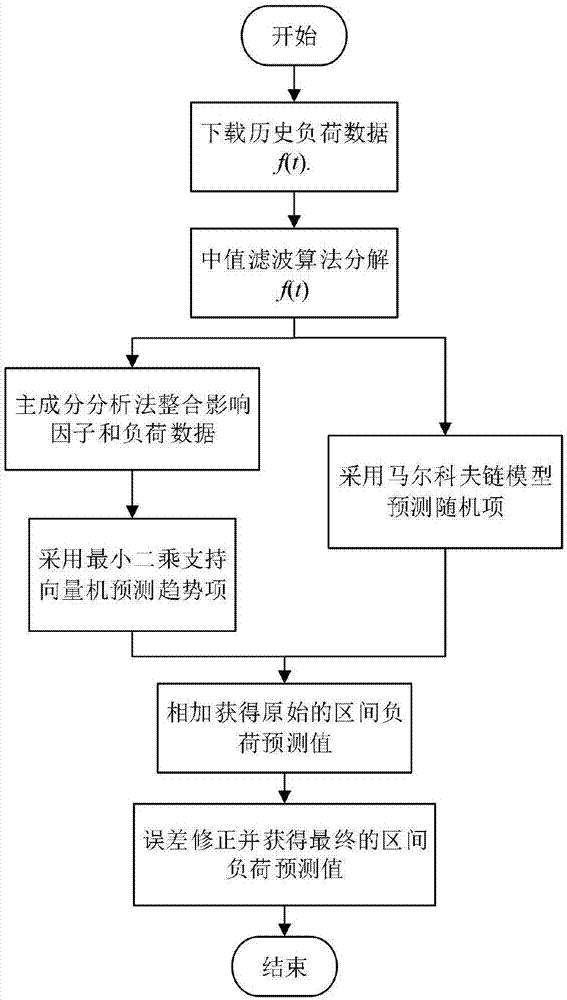
图1为本发明基于影响因子分析的日最大负荷区间预测方法的流程图;
图2为理想预报结果与实际数据的曲线图。
具体实施方式
下面结合附图和具体实施方式对本发明的内容做进一步详细说明。
实施例:
如图1所示,本实施例提供的基于影响因子分析的日最大负荷区间预测方法,具体包括以下步骤:
1)利用中值滤波法找出历史负荷曲线的趋势曲线,获得趋势项负荷,历史负荷曲线减去趋势项负荷,得到随机项。假设历史曲线f(t),t=1,2,…,n,其趋势曲线为m(t),则
其中2d+1是窗长。
2)对影响因子(包括该负荷覆盖的区域面积、工业/商业/居民用电占比等)和趋势项负荷进行主成分分析,整合出若干个主成分;
第一步:假设有n个样本,p个变量,观测数据矩阵为:
其中,x为观测数据矩阵,xij为第i个样本第j个变量的值。
第二步:计算样本的相关系数矩阵
假定原始数据标准化后仍用x表示,则经标准化处理后的数据的相关系数为:
其中,rij为第i个变量与第j个变量的相关系数。
第三步:用雅克比方法求相关系数矩阵r的特征值(λ1,λ2,…,λp)和相应的特征向量ai=[ai1,ai2,…,aip],i=1,2,…,p;
第四步:选择重要的主成分,并写出主成分表达式;
主成分分析能够得到p个主成分,但是,由于各个主成分的方差是递减的,包含的信息量也是递减的,所以实际分析时,通常不是选取p个主成分,而是根据各个主成分累计贡献率的大小选取前k个主成分,这里贡献率就是指某个主成分的方差占全部方差的比重,实际也就是某个特征值占全部特征值合计的比重,即
其中,λi为第i个变量的特征值。
贡献率越大,说明该主成分所包含的原始变量的信息越强;主成分个数k的选取,主要根据主成分的累积贡献率来决定,通常要求累计贡献率达到85%以上,这样才能保证综合变量能包括原始变量的绝大多数信息;
主成分表达式表示如下:
zi=ai1×x1+ai2×x2+…+aip×xp
其中,zi为第i个主成分,xj为第j个变量,aij为第i个主成分中第j个变量的特征向量。
3)将t-1时刻的主成分和历史负荷数据作为输入,t时刻的历史负荷数据作为输出,训练模型;基于训练完成的模型,将预测点前一刻的主成分和负荷数据作为输入,模型进行预测,即得负荷的趋势项预测结果;
4)将随机项曲线按幅值最大最小为上下限平均划分成3个区间,计算转移概率矩阵,转移概率最大的区间,即为随机项的预测区间。
其中,ω1,ω2,ω3代表区间1,区间2,区间3。
转移概率矩阵可表示为
其中,aij(i=1,2,3;j=1,2,3)表示上一时刻的数值s(t-1)位于i区间,下一时刻的数值s(t)位于j区间的概率。即:
其中,bij(t)为判断是否满足上一时刻的数值s(t-1)位于i区间,下一时刻的数值s(t)位于j区间的变量,若满足,则为1,否则为0。
若预测前一天的负荷值位于第i个区间,则预测日的负荷随机项区间sω(t)为ai1,ai2,ai3中的最大值所在的区间。
5)负荷的趋势项预测值与随机项的预测区间之和为原始预测区间。
其中,
6)通过三次样条插值(cubicsplineinterpolation简称spline插值,是通过一系列形值点的一条光滑曲线,数学上通过求解三弯矩方程组得出曲线函数组的过程)的方法找出负荷曲线的上、下包络线y(t)=[yl(t)yh(t)];
7)计算上、下包络线与原始预测区间上、下限之间的误差。
8)原始预测区间与误差之和为最终的预测区间。
在该预测模型中,从准确度和精确度两方面评估本预测方法的预测精度。
1、准确度
若预测点的实际数值落在预测结果的上限和下限之间,为预测准确。
准确度c定义如下:
其中m为预测总个数。
2、精确度
上调距离比例:
下调距离比例:
将上/下调距离比例的平均绝对值、标准差、最大值、最小值作为评价标准,分别标记为
在这八个指标中,值越小,表示预测值与真实值之间的阈值越小,预测越稳定,体现了预测的精确度。
由以上分析可以看出,准确度与精确度之间存在相互制约的关系,准确度高的模型必将导致精确度偏低,精确度高的模型则准确度将受制约。如何在两者中进行权衡选择,则需要对具体情况进行分析。
如图2所示,为理想预报结果与实际数据的曲线图。由图可看出,在绝大多数情况下,真实值位于预测区间上限与预测区间下限之间,准确度极高。预测区间上限与预测区间下限较好地贴合了真实曲线的波动情况,误差较小,精确度较高。
上述实施例只是为了说明本发明的技术构思及特点,其目的是在于让本领域内的普通技术人员能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡是根据本发明内容的实质所做出的等效的变化或修饰,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!