一种基于多层循环神经网络和D-S证据理论的水质参数预测方法与流程
本发明涉及一种水质参数预测方法,尤其涉及一种基于多层循环神经网络和d-s证据理论的水质参数预测方法。
背景技术
水是工业生产和农业生产中不可或缺的资源,也是人类社会的生命源泉。近年来,随着人类社会的不断发展,水资源正不断的在减少,有些地区甚至严重紧缺,正在制约着人类社会经济的发展,因此进行水质分析,加强水资源的监管和水质预警对水资源的利用至关重要。水质参数的定量分析是进行水质分析的重要任务之一,而获取进行水质参数定量分析的首要任务是获取水质参数的含量。水质预测是利用水质参数含量的历史数据进行建模,并对未来时间水质参数的含量进行估计,为水质参数的定量分析提供了基础数据支持,从而实现水质预警,有效的降低水质恶化所造成的危害。
目前,浅层的非机理模型在水质预测中的应用比较常见,如,径向基函数(radialbasisfunction,rbf)网络,多元线性回归模型(multi-linearregression,mlr),支持向量回归(supportvectorregression,svr),人工神经网络(artificialneuralnetworks,ann),自回归积分滑动平均模型(autoregressiveintegratedmovingaveragemodel,arima)等。
传统的的水质预测模型通常是一些浅层模型,对水环境这种具有高维、多峰值、不连续、非凸性等特征的复杂非线性系统,深层模型具有更强的表达能力。
技术实现要素:
本发明针对现有预测方法中预测水质参数含量精度不高和多参数预警效果较差的问题,提供了一种基于多层循环神经网络和d-s证据理论的水质参数预测方法。
本发明包括以下步骤:
步骤1:对采集的水质参数样本进行预处理:所述水质参数样本为水质参数含量的历史数据,将数据集按照“留出法”划分成训练集和测试集;采用最大最小法分别对训练集和测试集进行归一化处理,转化为[0,1]之间的值。
步骤2:初始化lstm、gru、srn三种多层rnn模型的结构:三种多层rnn模型的隐藏层均为两层,最大迭代次数为200,激活函数为tanh函数,隐藏层神经元个数相同。
步骤3:采用随时间进行反向传播(bptt)算法利用步骤1预处理后的训练集对lstm模型、gru模型、srn模型中的循环层进行训练,具体方法如下:
1).前向计算每个神经元的输出值。
2).反向计算每个神经元的误差项值,它是误差函数对神经元的加权输入的偏导数。
3).计算每个权重的梯度,再用批量梯度下降算法更新权重,判断损失函数是否收敛要求或者是否达到最大迭代次数,损失函数未收敛且未达到最大迭代次数则返回第1)步,否则结束训练。
步骤4:利用步骤3训练好的lstm模型、gru模型和srn模型对水质参数进行预测,分别得到三种模型在预测时刻的初步预测结果p1,p2,p3。
步骤5:对水质参数的历史数据进行自相关分析,获取合适的证据个数,具体方法如下:
1).计算自相关系数rk,计算函数如下:
式(1)中c0是时间序列的样本方差,计算方法如下:
式(1)中ck是中间变量,具体的计算方法如下:
式(2)和式(3)中,t是样本总量,yt是样本在t时刻的实际值,
2).根据rk的值,得到与预测时刻值相关度较大的时间间隔,即rk>0.8时的k的取值,将此时k的值作为证据理论的证据个数。
步骤6:根据d-s证据理论对步骤4中lstm模型、gru模型、srn模型在预测时刻的预测结果p1,p2,p3进行融合,获取最终预测结果,具体方法如下:
1).以lstm模型、gru模型、srn模型对预测时刻的预测结果(p1,p2,p3)作为d-s证据理论中的辨识框架θ={p1,p2,p3},计算三种模型在预测时刻前k个时刻对应的预测残差:
eji=pji-rj(i=1,2,3,j=1,2,...,k)(5)
式(5)中rj为距离预测时刻为j个时间单位的实际观测值,pji为第i个模型距离预测时刻为j个时间单位的模型预测结果。
2).计算距离预测时刻为j个时间单位时lstm模型、gru模型、srn模型预测结果所占的权重,并将该权重作为证据理论中各个证据中的概率分配函数值m'j(p1),m'j(p2),m'j(p3),j=1,2,...,k,第i种模型距离预测时刻为j个时间单位预测结果所占权重wji的具体计算如下:
3).利用冲突解决方案对第2)步得到的分配概率m'j(p1),m'j(p2),m'j(p3)进行重新分配,并得到最终的概率分配:mj(p1),mj(p2),mj(p3),mj(θ),j=1,2,...,k,其中mj(θ)表示第j个证据经过冲突解决之后存在的不确定概率。
4).利用d-s证据理论对k个证据的最终概率分配mj(p1),mj(p2),mj(p3),mj(θ),j=1,2,...,k进行融合,得到三种模型预测结果最终的概率分布m(p1),m(p2),m(p3),m(θ)。其中融合公式如下:
式(7)中
5).利用三种模型预测结果的概率分布m(p1),m(p2),m(p3),m(θ)计算最终的预测输出p,计算公式如下:
p=m(p1)p1+m(p2)p2+m(p3)p3+m(θ)pθ(8)
式(8)中
本发明的预测方法中,使用了多层的lstm模型、gru模型、srn模型作为基础数据的预测,能够较高进度的实现水质参数预测,为了增强模型对不同数据集的适用能力,进而利用d-s证据理论来实现多模型预测结果的融合。该方法不仅可以提升单一参数的预测精度也可以提高多参数预警的效果,增强模型的实用性。
附图说明
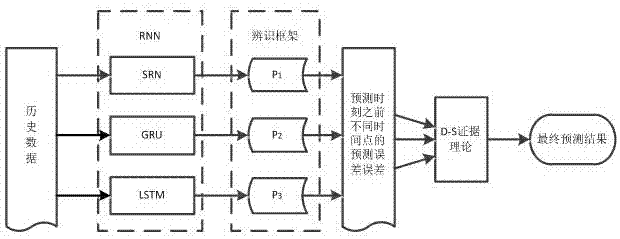
图1是本发明方法的结构图;
图2是本发明方法的流程图。
具体实施方式
本发明具体实现过程如下:
如图1所示,本发明的结构包括:1).用来训练和测试收集的历史数据集;2).进行初步预测的多层rnn循环神经网络;3).初步预测结果所构成的辨识框架;4).d-s证据理论,包括证据融合方法和冲突解决方案;5).最终的融合结果。
如图2所示,本发明的实现流程如下:
步骤1:对采集的水质参数样本进行预处理:所述样本为水质参数值,包括codmn浓度和ph值,将数据集按照“留出法”划分成训练集和测试集,其中训练集所占比例为70%,测试集为30%;进一步,采用最大最小法分别对训练集和测试集进行归一化处理,转化为[0,1]之间的值。
步骤2:初始化lstm、gru、srn三种多层rnn模型的结构:三种多层rnn模型的隐藏层均为两层,最大迭代次数为200,激活函数为tanh函数,两层隐藏层的神经元个数相同,初始值为3,然后不断增加,通过重复试验,比较每次试验结果的rmse,确定的最终个数为20。
步骤3:采用随时间进行反向传播(bptt)算法利用步骤1预处理后的训练集对lstm模型、gru模型、srn模型中的循环层进行训练,具体方法如下:
1).前向计算每个神经元的输出值。
2).反向计算每个神经元的误差项值,它是损失函数对神经元的加权输入的偏导数。
3).计算每个权重的梯度,最后再用批量梯度下降算法更新权重,判断损失函数是否收敛或者是否达到最大迭代次数,损失函数未收敛且未达到最大迭代次数则返回第1)步,否则结束训练。
步骤4:利用步骤3训练好的lstm模型、gru模型和srn模型利用测试集对水质参数进行预测,分别得到三种模型在预测时刻的初步预测结果p1,p2,p3。
步骤5:对水质参数的历史数据进行自相关分析,获取合适的证据个数,具体方法如下:
1).计算自相关系数rk,计算函数如下:
式中,c0是时间序列的样本方差,计算方法如下:
式中,ck是中间变量,具体的计算方法如下:
式中,t是样本总量,yt是样本在t时刻的实际值,
2).根据rk的值,得到相关度较高的时间间隔,即rk>0.8时的k的取值,将此时k的值作为证据理论的证据个数。
步骤6:根据d-s证据理论对步骤4中lstm模型、gru模型、srn模型在预测时刻的预测结果p1,p2,p3进行融合,获取最终预测结果,具体方法如下:
1).以lstm模型、gru模型、srn模型在预测时刻的预测结果(p1,p2,p3)作为d-s证据理论中的辨识框架θ={p1,p2,p3},计算三种模型在之前共k个时刻对应的预测残差,方法如下:
eji=pji-rj(i=1,2,3,j=1,2,...,k)
式中,pji为第i个模型距离预测时刻为j个时间单位的模型预测结果,rj为在预测时刻之前的第j个实际观测值。
2).计算距离预测时刻为j个时间单位时lstm模型、gru模型、srn模型预测结果所占的权重,并将该权重作为证据理论中各个证据中的概率分配函数值m'j(p1),m'j(p2),m'j(p3),j=1,2,...,k,第i种模型距离预测时刻为j个时间单位的预测结果所占权重wji的具体计算方法如下:
3).利用冲突解决方案对第2)步得到的分配概率m'j(p1),m'j(p2),m'j(p3)进行重新分配,并得到最终的概率分配:mj(p1),mj(p2),mj(p3),mj(θ),j=1,2,...,k,其中mj(θ)表示第j个证据经过冲突解决之后存在的不确定概率。
4).利用d-s证据理论对k个证据的最终概率分配mj(p1),mj(p2),mj(p3),mj(θ),j=1,2,...,k进行融合,得到三种模型预测结果最终的概率分布m(p1),m(p2),m(p3),m(θ)。其中融合公式如下:
式中,
5).利用三种模型预测结果的概率分布m(p1),m(p2),m(p3),m(θ)计算最终的预测输出p,计算公式如下:
p=m(p1)p1+m(p2)p2+m(p3)p3+m(θ)pθ
式中,
以上实施例仅用以说明本发明的技术方案而非限制,仅仅参照较佳实施例对本发明进行了详细说明。本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!