一种群智优化SAR雷达空中飞行目标识别系统的制作方法
本发明涉及雷达数据处理领域,特别地,涉及一种群智优化sar雷达空中飞行目标识别系统。
背景技术:
空中飞行目标识别技术展现出了强大的生命力,30年来出现了各种的理论方法,研究的比较成熟的算法有经典统计判决、主观bayes推断、d-s证据理论法、神经网络和支持向量机等。因为目标识别的算法的不同有可能会造成表达识别结果的不一致,所以系统为了便于进行处理和对比把各类的识别结果的表达形式统一为主观概率。除此之外,有些研究人员对目标识别进行研究时,引入了粗糙集理论和数据挖掘。也有人将数据挖掘与粗糙集理论结合,对目标识别系统进行研究。目前,归纳学习过程广泛应用了数据挖掘技术,数据挖掘可以从大量数据中提取潜在的规律。其中利用sar图像对空中飞行目标进行监测和识别是目前国际上的一个前沿和热点,可以通过对sar图像进行空中飞行目标的监测识别,获取飞行目标的类型、位置以及航向等重要的信息参数。对于获取空中飞行目标的主动权、确保空中飞行目标行动的成功起到了至关重要的作用。
技术实现要素:
为了克服目前基于sar图像的空中飞行目标识别准确率不高的不足,本发明的目的在于提供一种实现实时分析的群智优化sar雷达空中飞行目标识别系统。
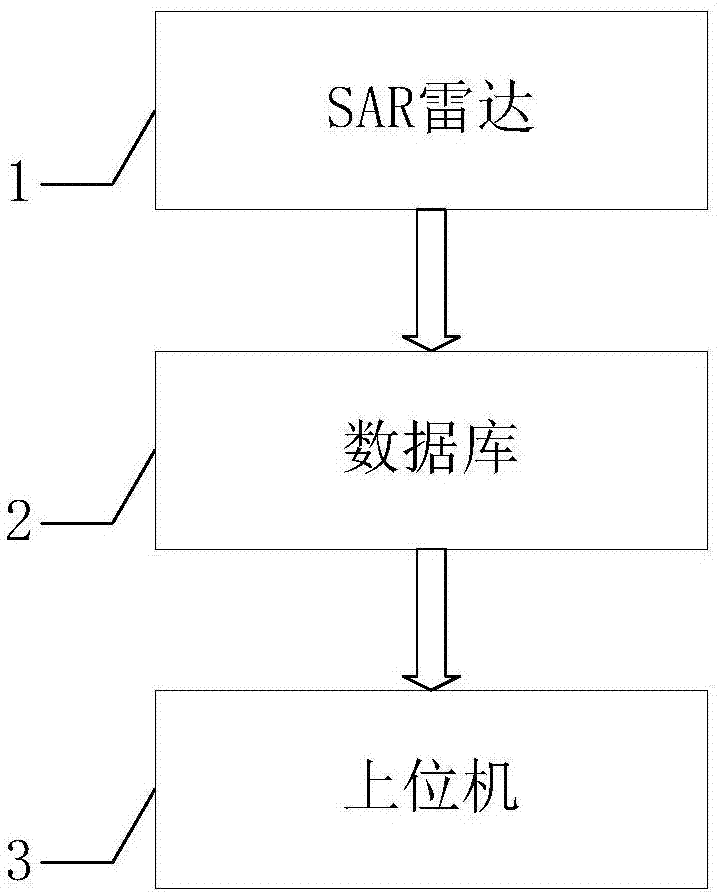
本发明解决其技术问题所采用的技术方案是:一种群智优化sar雷达空中飞行目标识别系统,包括sar雷达、数据库以及上位机,sar雷达、数据库和上位机依次相连,所述sar雷达对空中进行实时监测,并将sar雷达获得的图像数据存储到所述的数据库中,所述的上位机包括:
图像预处理模块,用以进行sar雷达图像数据预处理,采用如下过程完成:
1)从数据库中传来的sar图像灰度级为l,f(x0,y0)为像素点(x0,y0)处的灰度值,g(x0,y0)为像素点(x0,y0)的n×n邻域内像素的平均值,其中x0,y0分别表示像素点的横坐标和纵坐标;
2)通过计算满足f=m和g=n的像素数目h(m,n),得到二维联合概率密度pmn:
pmn=p(m,n)=h(m,n)/m
其中,m表示图像像素的总数目;
3)计算二维直方图的均值向量μ:
4)分别计算图像中目标和背景出现的概率p0,1和均值向量μ0,1:
其中,t、s、下标0、下标1分别表示f分割阈值、g分割阈值、目标区域、背景区域;
5)计算类间方差bcv:
bcv=p0(μ0-μ)(μ0-μ)′+p1(μ1-μ)(μ1-μ)′;
其中,μ表示均值向量,上标’表示矩阵的转置。
6)最佳阈值即为使得bcv为最大值时的二维阈值向量[s0,t0]:
特征提取模块,用以进行飞行目标典型特征的提取,采用如下过程完成:
1)从图像预处理模块传来的只包含一个飞行目标的sar图像切片i(m,n),其中只包含目标区域的二值图为b(m,n),则只包含目标的图像t(m,n):
t(m,n)=i(m,n)×b(m,n)
其中,×表示对应像素相乘;
2)在b(m,n)中根据飞行目标个体的主轴方向求得飞行目标主体区域的最小外接矩形,则该矩形的长边长度length即为飞行目标个体的长度,矩形的短边长度width即为飞行目标个体的宽度;
3)计算得到几何结构特征,其中包括周长、面积、长宽比、形状复杂度、目标质心位置以及转动惯量:
周长
转动惯量
4)计算得到灰度统计特征,其中包括质量、均值、方差系数、标准差、分形维数、加权填充比:
质量
特征选择模块,用以选择出最优特征子集,采用如下过程完成:
1)计算类内距离
其中,i表示特征标号,ω表示飞行目标类别的标号,||fi(ω)||2表示特征向量fi(ω)的2范数,
2)计算得到归一化方差系数ρi(ω):
ρi(ω)=e[||fi(ω)||22]-e2[||fi(ω)||2]/e[||fi(ω)||22]
其中,i表示特征标号,ω表示飞行目标类别的标号,||fi(ω)||2表示特征向量fi(ω)的2范数,e[||fi(ω)||22]和e2[||fi(ω)||2]分别表示特征的平方均值以及均值的平方。特征的方差系数ρi(ω)越小,表明该目标特征的稳定性越好;
3)计算得到相关系数ri,j:
其中,i,j表示特征标号,||fi||2表示特征fi的2范数,
4)通过上述得到的类内类间距、归一化方差系数、相关系数筛选出最优特征子集,构造最优输入特征向量;
分类器训练模块,用以进行分类器训练,采用如下过程完成:
5)从特征选择模块中采集n个sar雷达图像xi作为训练样本,i=1,2,…,n;
6)对训练样本进行归一化处理,得到归一化样本
7)将归一化后的训练样本重构,分别得到输入矩阵x和对应的输出矩阵y:
其中,d表示重构维数,d为自然数,且d<n,d的取值范围为50-70;
8)得到分类器训练集合
其中,ωi代表第i个隐含层节点和输入层之间的权重向量,bi代表第i个隐含层节点的偏置,βi代表第i个隐含层节点和输出层之间的权重向量,oj代表第j个输入数据的目标输出。另外,ωi·xj代表了ωi和xj的内积。
该网络的输出能够无限地接近于输入的n个样本,即:
可得:
上式可以表达为矩阵形式:hβ=t
其中,h表示隐含层的输出矩阵,h的第i列分别表示隐含层的第i个节点对应于n个输入x1,x2,…,xn的输出值。单隐层前馈神经网络(slfns)的输入权值和隐含层的偏差在网络训练的过程中不需要调整,可以任意给定。基于上述理论,输出权重可以通过计算hβ=t的最小二乘解
可以利用线性方法快速求得方程的解,如式所示:
其中,
群智优化模块,用以采用基于群智能算法的优化模块对分类器的核参数θ和惩罚因子γ进行优化,采用如下过程完成:
1)算法初始化,根据待优化的分类器形式构造出初始的解集s=(s1,s2,…,sn),确定蚁群的大小m,设置蚁群寻优算法迭代次数的阈值maxgen并初始化蚁群寻优的迭代次数序号gen=0;
2)计算出解集s对应的适应度值fiti(i=1,2,…,n),适应度值越大代表解越好;再根据下式确定解集中每个解被取到作为蚂蚁寻优的初始解的概率pi(i=1,2,…,n)
初始化执行寻优算法的蚂蚁编号i=0;
3)蚂蚁i选取s中的一个解作为寻优的初始解,选取规则是根据p来做轮盘选;
4)蚂蚁i在选取的初始解的基础上进行寻优,找到更好的解si′;
5)如果i<m,则i=i+1,返回步骤3);否则继续向下执行步骤6);
6)如果gen<maxgen,则gen=gen+1,使用步骤4)中所有蚂蚁得到的最好的解取代s中的对应解,返回步骤2);否则向下执行步骤7);
7)计算出解集s对应的适应度值fiti(i=1,2,…,n),选取适应度值最大的解作为算法的最优解,结束算法并返回。
结果显示模块,用以进行识别结果的显示,即将输入sar图像中飞行目标的类型显示在屏幕当中。
本发明的技术构思为:本发明针对sar雷达全天时、全天候工作以及强穿透的特性,对sar雷达监测到的空中图像进行图像预处理,接着进行特征的提取以及特征的选择,最后通过分类器的训练过程建立空中飞行目标识别模型,从而实现sar雷达空中飞行目标的识别。
本发明的有益效果主要表现在:1、可实时识别空中飞行目标;2、所用的识别方法只需较少的训练样本;3、智能化、受人为因素干扰小。
附图说明
图1是本发明所提出的系统的整体结构图;
图2是本发明所提出的上位机的功能模块图。
具体实施方式
下面根据附图具体说明本发明。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
实施例
参照图1、图2,一种群智优化sar雷达空中飞行目标识别系统,包括sar雷达1、数据库2及上位机3,sar雷达1、数据库2和上位机3依次相连,所述sar雷达1对所监测海域进行照射,并将sar雷达图像存储到所述的数据库2,所述的上位机3包括:
图像预处理模块4,用以进行sar雷达图像数据预处理,采用如下过程完成:
1)从数据库中传来的sar图像灰度级为l,f(x0,y0)为像素点(x0,y0)处的灰度值,g(x0,y0)为像素点(x0,y0)的n×n邻域内像素的平均值,其中x0,y0分别表示像素点的横坐标和纵坐标;
2)通过计算满足f=m和g=n的像素数目h(m,n),得到二维联合概率密度pmn:
pmn=p(m,n)=h(m,n)/m
其中,m表示图像像素的总数目;
3)计算二维直方图的均值向量μ:
4)分别计算图像中目标和背景出现的概率p0,1和均值向量μ0,1:
其中,t、s、下标0、下标1分别表示f分割阈值、g分割阈值、目标区域、背景区域;
5)计算类间方差bcv:
bcv=p0(μ0-μ)(μ0-μ)′+p1(μ1-μ)(μ1-μ)′;
其中,μ表示均值向量,上标’表示矩阵的转置。
6)最佳阈值即为使得bcv为最大值时的二维阈值向量[s0,t0]:
特征提取模块5,用以进行飞行目标典型特征的提取,采用如下过程完成:
1)从图像预处理模块传来的只包含一个飞行目标的sar图像切片i(m,n),其中只包含目标区域的二值图为b(m,n),则只包含目标的图像t(m,n):
t(m,n)=i(m,n)×b(m,n)
其中,×表示对应像素相乘;
2)在b(m,n)中根据飞行目标个体的主轴方向求得飞行目标主体区域的最小外接矩形,则该矩形的长边长度length即为飞行目标个体的长度,矩形的短边长度width即为飞行目标个体的宽度;
3)计算得到几何结构特征,其中包括周长、面积、长宽比、形状复杂度、目标质心位置以及转动惯量:
周长
转动惯量
4)计算得到灰度统计特征,其中包括质量、均值、方差系数、标准差、分形维数、加权填充比:
质量
特征选择模块6,用以选择出最优特征子集,采用如下过程完成:
1)计算类内距离
其中,i表示特征标号,ω表示飞行目标类别的标号,||fi(ω)||2表示特征向量fi(ω)的2范数,
2)计算得到归一化方差系数ρi(ω):
ρi(ω)=e[||fi(ω)||22]-e2[||fi(ω)||2]/e[||fi(ω)||22]
其中,i表示特征标号,ω表示飞行目标类别的标号,||fi(ω)||2表示特征向量fi(ω)的2范数,e[||fi(ω)||22]和e2[||fi(ω)||2]分别表示特征的平方均值以及均值的平方。特征的方差系数ρi(ω)越小,表明该目标特征的稳定性越好;
3)计算得到相关系数ri,j:
其中,i,j表示特征标号,||fi||2表示特征fi的2范数,
4)通过上述得到的类内类间距、归一化方差系数、相关系数筛选出最优特征子集,构造最优输入特征向量;
分类器训练模块7,用以进行分类器训练,采用如下过程完成:
1)从特征选择模块中采集n个sar雷达图像xi作为训练样本,i=1,2,…,n;
2)对训练样本进行归一化处理,得到归一化样本
3)将归一化后的训练样本重构,分别得到输入矩阵x和对应的输出矩阵y:
其中,d表示重构维数,d为自然数,且d<n,d的取值范围为50-70;
4)得到分类器训练集合
其中,ωi代表第i个隐含层节点和输入层之间的权重向量,bi代表第i个隐含层节点的偏置,βi代表第i个隐含层节点和输出层之间的权重向量,oj代表第j个输入数据的目标输出。另外,ωi·xj代表了ωi和xj的内积。
该网络的输出能够无限地接近于输入的n个样本,即:
可得:
上式可以表达为矩阵形式:hβ=t
其中,h表示隐含层的输出矩阵,h的第i列分别表示隐含层的第i个节点对应于n个输入x1,x2,…,xn的输出值。单隐层前馈神经网络(slfns)的输入权值和隐含层的偏差在网络训练的过程中不需要调整,可以任意给定。基于上述理论,输出权重可以通过计算hβ=t的最小二乘解
可以利用线性方法快速求得方程的解,如式所示:
其中,
群智优化模块9,用以采用基于群智能算法的优化模块对分类器的核参数θ和惩罚因子γ进行优化,采用如下过程完成:
1)算法初始化,根据待优化的分类器形式构造出初始的解集s=(s1,s2,…,sn),确定蚁群的大小m,设置蚁群寻优算法迭代次数的阈值maxgen并初始化蚁群寻优的迭代次数序号gen=0;
2)计算出解集s对应的适应度值fiti(i=1,2,…,n),适应度值越大代表解越好;再根据下式确定解集中每个解被取到作为蚂蚁寻优的初始解的概率pi(i=1,2,…,n)
初始化执行寻优算法的蚂蚁编号i=0;
3)蚂蚁i选取s中的一个解作为寻优的初始解,选取规则是根据p来做轮盘选;
4)蚂蚁i在选取的初始解的基础上进行寻优,找到更好的解si′;
5)如果i<m,则i=i+1,返回步骤3);否则继续向下执行步骤6);
6)如果gen<maxgen,则gen=gen+1,使用步骤4)中所有蚂蚁得到的最好的解取代s中的对应解,返回步骤2);否则向下执行步骤7);
7)计算出解集s对应的适应度值fiti(i=1,2,…,n),选取适应度值最大的解作为算法的最优解,结束算法并返回。
结果显示模块8,用以进行识别结果的显示,即将输入sar图像中飞行目标的类型显示在上位机当中。
所述上位机3的硬件部分包括:i/o元件,用于数据的采集和信息的传递;数据存储器,存储运行所需要的数据样本和运行参数等;程序存储器,存储实现功能模块的软件程序;运算器,执行程序,实现指定的功能;显示模块,显示设置的参数和识别结果。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!