基于多类生成对抗网络的高光谱图像分类方法与流程
本发明属于图像处理技术领域,更进一步涉及图像分类技术领域中的一种基于多类生成对抗网络(multi-classgenerativeadversarialnetworks)的高光谱图像分类方法。本发明可用于对高光谱图像的地物进行分类。
背景技术
高光谱图像光谱分辨率的提高,为分类提供了更加丰富信息的同事,也带来了巨大的挑战。目前应用在高光谱图像分类中的传统方法包括支撑矢量机、决策树等,基于深度学习的方法包括栈式自编码器、卷积神经网络等。深度学习需要大量的有标签数据作为训练样本,而在高光谱图像中,难以收集到足够的有标签数据,因此在基于深度学习的高光谱图像分类中,高光谱图像有标签数据不足的问题已经限制了高光谱图像的分类精度。
太仓稻信信息科技有限公司在其申请的专利文献“一种高光谱图像分类方法”(专利申请号:201710406644.4,公开号:cn107247966a)中提出了一种高光谱图像分类方法。该方法首先对要分类的图像进行多尺度分割,对多尺度分割后的图像进行显著图提取,在显著图提取后的图像中,对像元进行光谱特征提取,对提取的特征进行归一化,对归一化后的像元特征用非线性核函数方法分类。该方法虽然能够减少辐射误差和几何误差影响,但是,该方法仍然存在的不足之处是,只提取了像元的光谱特征,没有提取像元邻域的空间特征,导致分类准确性不高。
北京航空航天大学在其申请专利文献“一种基于深度学习的高光谱图像分类方法”(专利申请号:201710052345.5,公开号:cn106845418a)中提出了一种高光谱图像分类方法。该方法首先采用非线性的自编码网络对高光谱图像进行降维。在降维后的图像中,将有标签像元邻域的数据立方体作为样本输入卷积神经网络,然后将像元对应的标签作为卷积神经网络的期望输出,训练卷积神经网络,最后将训练好的卷积神经网络作用于高光谱图像中的每个像元,得到分类结果。该方法虽然保留了样本的非线性信息,但是,该方法仍然存在的不足之处是,样本数目相对于网络参数数目过少,导致网络过拟合,分类准确性不高。
技术实现要素:
本发明的目的是针对上述已有技术的不足,提出一种能够适用于图像处理的基于多类生成对抗网络的高光谱图像分类方法。
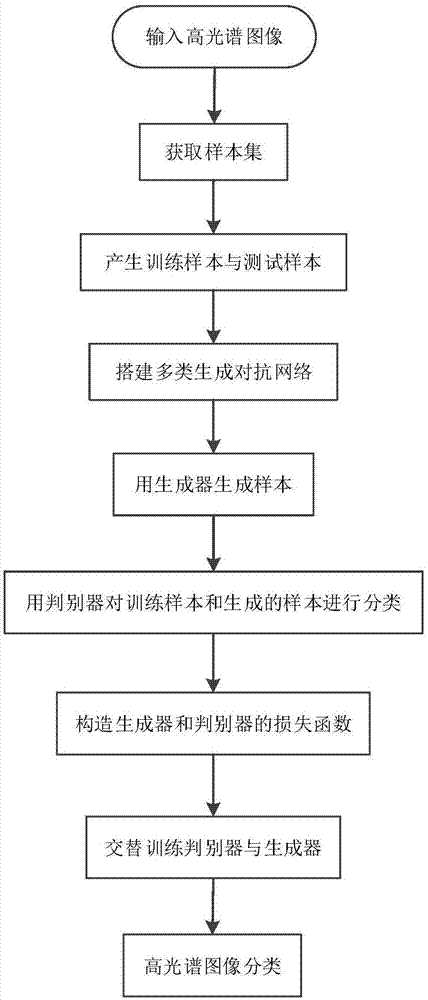
实现本发明目的的思路是,先搭建多类生成对抗网络,用多类生成对抗网络中的生成器生成样本,用判别器对训练样本和生成的样本进行分类,再构造生成器和判别器的损失函数,交替训练生成器和判别器,最后将测试样本输入训练好的多类生成对抗网络的判别器中,得到高光谱图像的分类结果。
本发明的具体步骤包括如下:
(1)输入高光谱图像:
(2)获取样本集:
(2a)以高光谱图像中的每个有标签像素为中心,划定一个27×27个像素大小的空间窗;
(2b)将每个空间窗内所有的像素组成一个数据立方体;
(2c)将所有的数据立方体组成高光谱图像的样本集;
(3)产生训练样本与测试样本:
在高光谱图像的样本集中,随机选取5%的样本,组成高光谱图像的训练样本;将剩余95%的样本组成高光谱图像的测试样本;
(4)搭建多类生成对抗网络:
(4a)搭建一个由全连接层和4个逆卷积层构成的生成器,并设置每层参数;
(4b)搭建一个由4个卷积层和1个多分类层构成的判别器,并设置每层参数;
(4c)将生成器和判别器组成多类生成对抗网络;
(5)用生成器生成样本:
从高斯分布中随机采样生成100维的高斯噪声向量,将高斯噪声向量通过生成器进行非线性映射,转换成高光谱图像的生成的样本;
(6)用判别器对训练样本和生成的样本进行分类:
将训练样本和生成的样本输入到判别器中进行非线性映射,输出训练样本的预测标签和生成的样本的预测标签;
(7)构造生成器和判别器的损失函数:
(7a)生成一个元素个数和高光谱图像地物种类数相等的向量,该向量中每个元素值均等于地物种类数的倒数,将该向量作为生成样本的判别标签;
(7b)利用交叉熵公式,计算生成的样本的预测标签和训练样本标签之间的交叉熵,将生成的样本的预测标签和训练样本标签之间的交叉熵作为生成器的损失函数;
(7c)利用交叉熵公式,计算生成的样本预测标签和生成的样本的标签之间的交叉熵;
(7d)利用交叉熵公式,计算训练样本的预测标签和训练样本标签之间的交叉熵;
(7e)将上面两个交叉熵之和,作为判别器的损失函数;
(8)交替训练生成器和判别器:
(8a)利用梯度下降方法,用生成器的损失函数值训练生成器;
(8b)利用梯度下降方法,用判别器的损失函数值训练判别器;
(8c)判断当前迭代次数是否为第1500次,若是,则执行步骤(9),否则,将当前迭代次数加上1后执行步骤(8);
(9)对高光谱图像进行分类:
将高光谱图像的测试样本输入到训练好的多类生成对抗网络的判别器中,输出测试样本的预测标签,获得分类结果。
本发明与现有技术相比具有以下优点:
第一,由于本发明搭建了多类生成对抗网络,利用搭建的多类生成对抗网络中的空间卷积和逆卷积操作提取像元领域的空间特征,克服了现有技术只提取像元的光谱特征,没有提取像元邻域的空间特征,导致分类准确性不高的问题,使得本发明增强了网络的提取特征能力,提高了分类的准确性。
第二,由于本发明用生成器生成样本,用判别器对训练样本和生成的样本进行分类,生成的样本加入样本集合增加了样本的数量,克服了现有技术中样本数目相对于参数数目过少,导致的网络过拟合,分类准确性不高的问题,使得本发明提高了在样本数量较少的情况下分类的准确性。
附图说明
图1是本发明的流程图;
图2是本发明的仿真图。
具体实施方式
下面结合附图对本发明做进一步的描述。
结合附图1中,实现本发明的具体步骤如下:
步骤1,输入高光谱图像。
步骤2,获取样本集。
以高光谱图像中的每个有标签像素为中心,划定一个27×27个像素大小的空间窗。
将每个空间窗内所有的像素组成一个数据立方体。
将所有的数据立方体组成高光谱图像的样本集。
步骤3,产生训练样本与测试样本。
在高光谱图像的样本集中,随机选取5%的样本,组成高光谱图像的训练样本;将剩余95%的样本组成高光谱图像的测试样本。
步骤4,搭建多类生成对抗网络。
搭建一个由全连接层和4个逆卷积层构成的生成器,并设置每层参数。
所述的生成器的层间设置按照从左到右依次为,全连接层,逆卷积层,逆卷积层,逆卷积层,逆卷积层,其中,全连接层的输入和输出节点个数分别为100和512,每个逆卷积层的卷积核大小为5×5个像素大小,步长为2。
搭建一个由4个卷积层和1个多分类层构成的判别器,并设置每层参数。
所述的判别器的层间设置按照从左到右依次为,卷积层,卷积层,卷积层,卷积层,多分类层,其中,每个卷积层的卷积核为5×5个像素大小,步长为2,全连接层的输入节点个数是512,输出节点个数和高光谱图像地物种类数相等。
将生成器和判别器组成多类生成对抗网络。
步骤5,用生成器生成样本。
从高斯分布中随机采样生成100维的高斯噪声向量,将高斯噪声向量通过生成器进行非线性映射,转换成高光谱图像的生成的样本。
所述的高斯噪声向量通过生成器进行非线性映射的步骤如下:
第1步,将100维的高斯噪声向量输入生成器的全连接层,依次进行线性的全连接变换、非线性relu变换、矩阵形状变换、批标准化,得到2×2×128个像素大小的全连接层输出特征图。
第2步,将全连接层输出特征图输入到生成器的第一个逆卷积层,依次进行逆卷积操作、非线性relu变换、批标准化,得到4×4×64个像素大小的第一个逆卷积层的输出特征图。
第3步,将第一个逆卷积层的输出特征图输入到生成器的第二个逆卷积层,依次进行逆卷积操作、非线性relu变换、批标准化,得到7×7×32个像素大小的第二个逆卷积层的输出特征图。
第4步,将第二个逆卷积层的输出特征图输入到生成器的第三个逆卷积层,依次进行逆卷积操作、非线性relu变换、批标准化,得到14×14×16个像素大小的第三个逆卷积层的输出特征图。
第5步,将第三个逆卷积层的输出特征图输入到生成器的第四个逆卷积层,依次进行逆卷积操作、非线性relu变换、批标准化,得到27×27×3个像素大小的生成样本。
步骤6,用判别器对训练样本和生成的样本进行分类。
将训练样本和生成的样本输入到判别器中进行非线性映射,输出训练样本的预测标签和生成的样本的预测标签。
所述的将训练样本和生成的样本输入到判别器中进行非线性映射的步骤如下:
第1步,将27×27×3个像素大小的高光谱图像生成样本和训练样本输入到判别器的第一个卷积层,依次进行卷积操作、非线性relu变换、批标准化,得到14×14×16个像素大小的第一个卷积层的输出特征图。
第2步,将第一个卷积层的输出特征图输入到判别器的第二个卷积层,依次进行卷积操作、非线性relu变换、批标准化,输出7×7×32个像素大小的判别器第二个卷积层的输出特征图。
第3步,将第二个卷积层的输出特征图输入到判别器的第三个卷积层,依次进行卷积操作、非线性relu变换、批标准化,输出4×4×16个像素大小的判别器第三个卷积层的输出特征图。
第4步,将第三个卷积层的输出特征图输入到判别器的第四个卷积层,依次进行卷积操作、非线性relu变换、批标准化,输出2×2×128个像素大小的第四个卷积层的输出特征图。
第5步,将第四个卷积层的输出特征图输入到判别器的多分类层,依次进行矩阵形状变换、线性全连接变换、非线性soft-max变换,得到训练样本和生成的样本的预测标签。
所述的将训练样本和生成的样本输入到判别器中进行非线性映射的步骤如下:
所述的训练样本的预测标签和生成的样本的预测标签为两个向量,每个向量中的元素总数等于高光谱地物种类数,每个向量中的单个元素值等于样本属于某一类地物的概率值。
步骤7,构造生成器和判别器的损失函数。
生成一个元素个数和高光谱图像地物种类数相等的向量,该向量中每个元素值均等于地物种类数的倒数,将该向量作为生成样本的判别标签。
利用交叉熵公式,计算生成的样本的预测标签和训练样本标签之间的交叉熵,将生成的样本的预测标签和训练样本标签之间的交叉熵作为生成器的损失函数。
所述的交叉熵公式如下:
其中,l表示交叉熵,σ表示求和操作,yi表示标签向量的第i个元素,ln表示以e为底的对数操作,
所述的计算预测标签和标签之间的交叉熵的步骤如下:
第1步,对预测标签中的每一个元素值分别进行以e为底的对数操作,将对数操作后的所有元素组成向量y。
第2步,用向量y中的每一个元素值乘以标签中相同位置的元素值,对乘法操作之后的所有元素求和,将求和结果作为预测标签和标签之间的交叉熵。
利用交叉熵公式,计算生成样本预测标签和判别标签之间的交叉熵。
所述的交叉熵公式如下:
其中,l表示交叉熵,σ表示求和操作,yi表示标签向量的第i个元素,ln表示以e为底的对数操作,
所述的计算预测标签和标签之间的交叉熵的步骤如下:
第1步,对预测标签中的每一个元素值分别进行以e为底的对数操作,将对数操作后的所有元素组成向量y。
第2步,用向量y中的每一个元素值乘以标签中相同位置的元素值,对乘法操作之后的所有元素求和,将求和结果作为预测标签和标签之间的交叉熵。
利用交叉熵公式,计算训练样本的预测标签和训练样本标签之间的交叉熵;
所述的交叉熵公式如下:
其中,l表示交叉熵,σ表示求和操作,yi表示标签向量的第i个元素,ln表示以e为底的对数操作,
所述的计算预测标签和标签之间的交叉熵的步骤如下:
第1步,对预测标签中的每一个元素值分别进行以e为底的对数操作,将对数操作后的所有元素组成向量y。
第2步,用向量y中的每一个元素值乘以标签中相同位置的元素值,对乘法操作之后的所有元素求和,将求和结果作为预测标签和标签之间的交叉熵。
将上面两个交叉熵之和,作为判别器的损失函数。
步骤8,交替训练生成器和判别器。
第1步,利用梯度下降方法,用生成器的损失函数值训练生成器。
第2步,利用梯度下降方法,用判别器的损失函数值训练判别器。
第3步,判断当前迭代次数是否为第1500次,若是,则执行步骤9,否则,将当前迭代次数加上1后执行本步骤的第1步。
步骤9,对高光谱图像进行分类。
将高光谱图像的测试样本输入到训练好的多类生成对抗网络的判别器中,输出测试样本的预测标签,获得分类结果。
下面结合附图2的仿真图对本发明的效果做进一步说明。
1.仿真实验条件:
本发明的仿真实验的硬件测试平台是:处理器为inteli75930kcpu,主频为3.5ghz,内存16gb。
本发明的仿真实验的软件平台为:windows10操作系统和python3.5.2。
本发明仿真实验的输入图像为高光谱图像印第安松树indianpines,图像大小为145×145×220个像素,图像共包含220个波段和16类地物,图像格式为mat。
2.仿真内容:
本发明仿真实验是采用本发明和三个现有技术(支撑向量机svm分类方法、栈式自编码器sae分类方法、卷积神经网络cnn分类方法)对输入的高光谱图像印第安松树indianpines进行分类,获得分类结果图,同时利用三个评价指标(总精度oa、平均精度aa、卡方系数kappa)对分类结果进行评价。
在仿真实验中,采用的三个现有技术具体如下:
melgani等人在“classificationofhyperspectralremotesensingimageswithsupportvectormachines,ieeetrans.geosci.remotesens.,vol.42,no.8,pp.1778–1790,aug.2004”中提出的高光谱图像分类方法,简称支撑向量机svm分类方法。
chen等人在“deeplearning-basedclassicationofhyperspectraldata,ieeej.sel.topicsappl.earthobserv.remotesens.,vol.7,no.6,pp.2094-2107,jun.2014”中提出的高光谱图像分类方法,简称栈式自编码器sae分类方法。
yu等人在“convolutionalneuralnetworksforhyperspectralimageclassification,”neurocomputing,vol.219,pp.88-98,2017”中提出的高光谱图像分类方法,简称卷积神经网络cnn分类方法。
在仿真实验中,采用的三个评价指标具体如下:
总精度oa表示正确分类的样本占所有样本的比例,值越大,说明分类效果越好。
平均精度aa表示每一类分类精度的平均值,值越大,说明分类效果越好。
卡方系数kappa表示混淆矩阵中不同的权值,值越大,说明分类效果越好。
图2为仿真实验结果图。其中,图2(a)为输入的高光谱图像印第安松树indianpines的真实地物分布图,其大小为145×145个像素。图2(b)为采用支撑向量机svm方法对高光谱图像印第安松树indianpines进行分类的结果图。图2(c)为采用栈式自编码器sae方法对高光谱图像印第安松树indianpines进行分类的结果图。图2(d)为采用卷积神经网络cnn方法对高光谱图像印第安松树indianpines进行分类的结果图。图2(e)为本发明对高光谱图像印第安松树indianpines进行分类的结果图。
3.仿真结果分析:
统计附图2中本发明和三个现有技术对高光谱图像印第安松树indianpines的分类结果,包括每类地物的分类精度,总精度oa、平均精度aa、卡方系数kappa,最后把统计到的每类地物的分类精度和各评价指标的值绘制成表1.
结合表1和附图2可以看出,支撑向量机svm和栈式自编码器sae方法的分类结果比较差,主要因为这两种方法都只提取了高光谱图像像元的光谱特征,没有提取空间特征,使得分类准确性不高;同时卷积神经网络cnn方法的分类结果有很大改善,准确率有所上升,但是卷积神经网络cnn方法中,样本数目相对于参数数目过少,导致网络过拟合,所以依然存在样本错分较多的现象;本发明的分类效果优于前三种现有技术分类方法,达到了较理想的分类效果。
以上仿真实验表明:本发明方法能够提取像元领域的空间特征,利用生成样本来增加样本数量,解决现有技术方法中存在的只提取光谱特征、样本数目相对于参数数目过少导致的网络过拟合、分类精度低等问题,是一种非常实用的高光谱图像分类方法。
表1.仿真实验中本发明和各现有技术分类结果的定量分析表
- 还没有人留言评论。精彩留言会获得点赞!