文本相似度计算方法及装置、智能机器人与流程
本发明实施例涉及文本处理技术领域,并且更具体地,涉及一种文本相似度计算方法及装置、智能机器人。
背景技术
聊天机器人是在大数据及人工智能技术驱动下产生的一个热门应用,在使用过程中,用户输入聊天内容,即用户输入其提出的问题,聊天机器人根据用户输入的问题,自动生成相应的回复,并反馈给用户。这种人工智能的处理方式能够在很大程度上提高服务效率和用户的体验度。目前存在多种类型的聊天机器人,比如苹果公司的siri、微软公司的微软小娜(cortana)与小冰、百度公司的度秘以及京东公司jimi(jd,instantmessagingintelligence),此外还有很多其他类型的聊天机器人,比如儿童教育机器人、车载控制机器人等。
在利用聊天机器人进行智能问答的实际应用场景中,用户向聊天机器人提出问题,聊天机器人从用户提出的问题中提取到关键信息,并根据关键信息从知识库中的选取相似的一个或多个预制问题,之后计算用户提出的问题与每个预制问题的相似度,并判断最大的相似度是否大于预定的置信度,如果大于预定的置信度,则将最大的相似度对应的预制问题的答复反馈给客户,完成智能机器人的一次智能问答。
以上,不管是用户提出的问题,还是知识库中存储的预制问题都是以文本的形式存在,计算用户提出的问题与每个预制问题的相似度,实质上是计算两个文本的相似度。但是由于用户的表达习惯、地域以及文化水平的差异,对于同一问题会有很多种不同的表达方式,具体表现在用户对同一问题的描述在提问风格以及提问长度等方面的区别很大,并且在用户的问题中可能会掺杂很多和业务不相关的词汇,进一步增加了问题的长度,即增加了文本的长度。现有技术中计算两个文本的相似度主要通过对文本进行分词,并利用得到各个词汇计算对应文本的相似度。其中存在的问题是,由于用户提出的问题对应的文本中包含很多不相关的词汇,导致计算的文本相似度偏低。例如某用户要咨询的问题是信用卡办理,其向聊天机器人提出文本的可能是“今天天气很好,我是湖南人,今年26岁,我想办理信用卡”,聊天机器人根据这个包含很多业务不相关词汇计算得到的相似度很可能无法大于预定的置信度,那么聊天机器人就无法为用户提供答复,严重影响了聊天机器人的服务质量以及用户的体验度。如果调整置信度则会影响到整个聊天机器人的答复效果,因此不能轻易调整置信度。
为了克服上述由于文本中包含很多业务不相关词汇,导致计算的文本相似度值偏低的缺陷,现有技术中提出一种文本切分的处理方法,具体地,根据标点符号,将长文本分成若干个短文本,然后根据得到的短文本计算相似度。例如:“今天天气很好,我是湖南人,今年26岁,我想办理信用卡”。可以切分成四个短文本,即“今天天气很好”、“我是湖南人”、“今年26岁”以及“我想办理信用卡”。这种处理方式存在以下问题:第一、如果长文本中不包含标点符号,则无法进行文本切分;第二、文本切分之后要根据切分得到的文本的数量,进行若干次相似度计算,时效性无法保障,导致聊天机器人的服务效率降低;第三、长文本可能包含在若干个短文本,单独的一个短文本不能表达原来长文本的完整涵义,导致计算的到的相似度不准确。可见上述文本切分的方法也无法有效解决上述计算得到的长文本相似度偏低的缺陷。
综上,现有技术中无法准确地计算包含较多的业务不相关词汇的文本的相似度,进一步地,由于计算得到的文本相似度不够准确,那么聊天机器人根据文本相似度为用户推送的答复也必定不够都准确,严重影响了聊天机器人的服务质量和用户的体验度。
技术实现要素:
本发明实施例提供一种文本相似度计算方法及装置、智能机器人,其能够筛选出业务相关的词汇来计算两个文本的相似度,有效提高了文本相似度的计算精度,聊天机器人利用准确的文本相似度,能够为用户提供更加准确的答复,从而进一步提高了聊天机器人或智能机器人的服务质量和用户的体验度。
第一方面,提供了一种文本相似度计算方法,所述方法包括如下步骤:
分别对所述第一文本和第二文本进行分词处理,得到第一词汇集合和第二词汇集合;
计算所述第一词汇集合与所述第二词汇集合的交集,得到第一目标集合;计算所述第一词汇集合与所述第二词汇集合的并集,得到第二目标集合;
从所述第二目标集合中筛选出包含在预定词汇库中的词汇,得到第三目标集合;
利用所述第一目标集合中每个词汇的预定权重和所述第三目标集合中每个词汇的预定权重,计算得到所述第一文本和第二文本的相似度。
结合第一方面,在第一种可能的实现方式中,所述方法还包括如下步骤:
获取若干个第一预定文本;其中,所述第一预定文本与所述第一文本和/或所述第二文本为业务相关文本;
对每个所述第一预定文本进行分词处理,得到若干个第一预定词汇;
统计每个所述第一预定词汇出现的次数,得到每个所述第一预定词汇的词频;
选取前n个词频最大的所述第一预定词汇,形成所述预定词汇库,其中n为正整数。
结合第一方面,在第二种可能的实现方式中,所述方法还包括如下步骤:
获取若干个第二预定文本;其中,所述第二预定文本与所述第一文本和/或所述第二文本为业务相关文本;
对每个所述第二预定文本进行分词处理,得到若干个第二预定词汇;
计算每个所述第二预定词汇出现的次数与所述第二预定文本的数量的商,得到每个所述第二预定词汇的频率;
筛选频率大于预定值的所述第二预定词汇,得到所述预定词汇库。
结合第一方面,在第三种可能的实现方式中,所述利用所述第一目标集合中每个词汇的预定权重和所述第三目标集合中每个词汇的预定权重,计算得到所述第一文本和第二文本的相似度,包括:
计算所述第一目标集合中所有词汇的预定权重的和,得到第一权重和;
计算所述第三目标集合中所有词汇的预定权重的和,得到第二权重和;
计算所述第一权重和与所述第二权重和的商,得到所述第一文本和第二文本的相似度。
结合第一方面,在第四种可能的实现方式中,所述方法还包括如下步骤:
获取所述第一目标集合中所有词汇的预定权重;
获取所述第三目标集合中所有词汇的预定权重。
第二方面,提供了一种文本相似度计算装置,所述装置包括:
第一集合生成模块,用于分别对所述第一文本和第二文本进行分词处理,得到第一词汇集合和第二词汇集合;
集合处理模块,用于计算所述第一词汇集合与所述第二词汇集合的交集,得到第一目标集合;计算所述第一词汇集合与所述第二词汇集合的并集,得到第二目标集合;
第二集合生成模块,用于从所述第二目标集合中筛选出包含在预定词汇库中的词汇,得到第三目标集合;
相似度计算模块,用于利用所述第一目标集合中每个词汇的预定权重和所述第三目标集合中每个词汇的预定权重,计算得到所述第一文本和第二文本的相似度。
结合第二方面,在第一种可能的实现方式中,所述装置还包括:
第一预定文本获取模块,用于获取若干个第一预定文本;其中,所述第一预定文本与所述第一文本和/或所述第二文本为业务相关文本;
第一预定词汇获取模块,用于对每个所述第一预定文本进行分词处理,得到若干个第一预定词汇;
词频统计模块,用于统计每个所述第一预定词汇出现的次数,得到每个所述第一预定词汇的词频;
第一预定词汇库生成模块,用于选取前n个词频最大的所述第一预定词汇,形成所述预定词汇库,其中n为正整数。
结合第二方面,在第二种可能的实现方式中,所述装置还包括:
第二预定文本获取模块,用于获取若干个第二预定文本;其中,所述第二预定文本与所述第一文本和/或所述第二文本为业务相关文本;
第二预定词汇获取模块,用于对每个所述第二预定文本进行分词处理,得到若干个第二预定词汇;
频率计算模块,用于计算每个所述第二预定词汇出现的次数与所述第二预定文本的数量的商,得到每个所述第二预定词汇的频率;
第二预定词汇库生成模块,用于筛选频率大于预定值的所述第二预定词汇,得到所述预定词汇库。
结合第二方面,在第三种可能的实现方式中,所述相似度计算模块包括:
第一权重计算子模块,用于计算所述第一目标集合中所有词汇的预定权重的和,得到第一权重和;
第二权重计算子模块,用于计算所述第三目标集合中所有词汇的预定权重的和,得到第二权重和;
相似度计算字模块,用于计算所述第一权重和与所述第二权重和的商,得到所述第一文本和第二文本的相似度。
结合第二方面,在第四种可能的实现方式中,所述装置还包括:
第一预定权重获取模块,用于获取所述第一目标集合中所有词汇的预定权重;
第二预定权重获取模块,用于获取所述第三目标集合中所有词汇的预定权重。
第三方面,本申请还提供了一种智能机器人,所述智能机器人包括:
文本接收部件,用于接收第一文本,所述第一文本为用户提问文本;
文本获取部件,用于从预定问答库中获取至少一个第二文本,所述第二文本为标准问题文本;所述预定问答库包括至少一个标准问题文本和每个标准问题文本对应的标准答案文本;
相似度计算部件,用于利用权利要求1至5任一项所述的文本相似度计算方法,计算所述第一文本与每个所述第二文本的目标相似度;
问答匹配部件,用于选取最大的所述目标相似度对应的标准问题文本作为与所述用户提问文本相匹配的目标文本;
答案获取部件,用于从所述预定问答库中获取所述目标文本对应的所述标准答案文本,得到所述用户提问文本的答案。
在本发明实施例的上述技术方案中,利用预定词汇库从两个文本的词汇并集中选取业务相关的词汇,之后利用得到的业务相关词汇以及两个文本的词汇交集计算得到文本相似度,该技术方案有效提高了文本相似度的计算精度,克服了现有技术中只利用文本中的词汇计算文本相似度造成的精度不高的缺陷。进一步地,聊天机器人或智能机器人利用准确的文本相似度,能够为用户提供更加准确的答复,提高了聊天机器人的服务质量和用户的体验度。
附图说明
为了更清楚的说明本发明实施例的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示意性的示出了根据本发明一实施例的文本相似度计算方法的流程图。
图2示意性的示出了根据本发明再一实施例的文本相似度计算方法的流程图。
图3示意性的示出了根据本发明又一实施例的文本相似度计算方法的流程图。
图4示意性的示出了根据本发明一实施例的文本相似度计算装置的框图。
图5示意性的示出了根据本发明再一实施例的文本相似度计算装置的框图。
图6示意性的示出了根据本发明又一实施例的文本相似度计算装置的框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
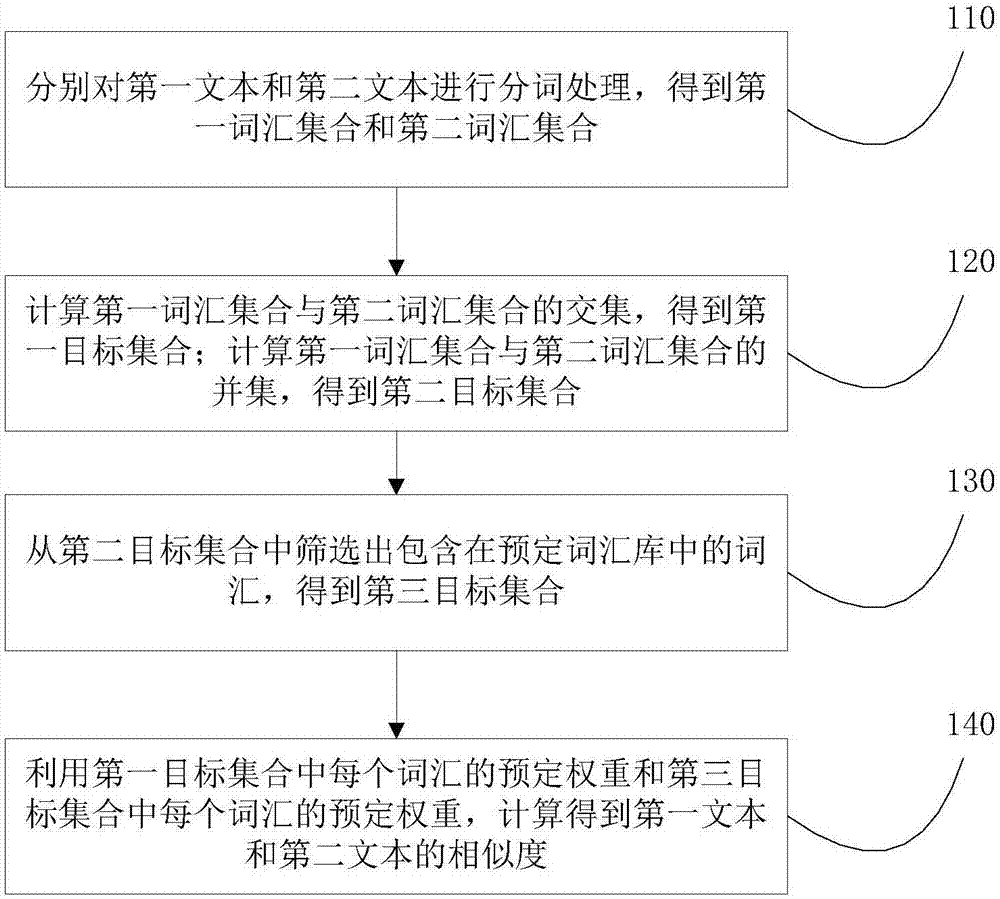
在一个实施例中,提供了一种文本相似度计算方法,如图1所示,该方法包括如下步骤:
110、分别对第一文本和第二文本进行分词处理,得到第一词汇集合和第二词汇集合;
此步骤中,第一文本和第二文本是需要计算相似度的两个文本;
此步骤中,对文本进行分词处理即是将文本分成各个词汇,例如文本为“我喜欢你”,分词处理后得到的词汇的集合为{我,喜欢,你};
此步骤中,第一词汇集合中包括第一文本中的所有词汇,第二词汇集合中包括第二本文中的所有词汇;
120、计算第一词汇集合与第二词汇集合的交集,得到第一目标集合;计算第一词汇集合与第二词汇集合的并集,得到第二目标集合;
此步骤中,第一目标集合包括第一词汇集合和第二词汇集合中共有的词汇;
130、从第二目标集合中筛选出包含在预定词汇库中的词汇,得到第三目标集合;
此步骤中,预定词汇库是预先设定的,其中包括特定业务场景下的多个词汇,即预定词汇库中包括多个业务相关词汇;此步骤即是利用预定词汇库从第二目标集合中筛选业务相关词汇;
此步骤中,实质上就是分别判断第一目标集合中的每个词汇是否包含在预定词汇库中,若包含在预定词汇库中,则将第一目标集合中的该词汇放入第三目标集合;
140、利用第一目标集合中每个词汇的预定权重和第三目标集合中每个词汇的预定权重,计算得到第一文本和第二文本的相似度;
此步骤中,每个词汇的预定权重是根据实际应用场景的需求预先设定的,同一个词汇的预定权重在不同的应用场景下可能不同;
此步骤中,具体可以利用如下子步骤计算第一文本和第二文本的相似度:
子步骤一、计算第一目标集合中所有词汇的预定权重的和,得到第一权重和;
子步骤二、计算第三目标集合中所有词汇的预定权重的和,得到第二权重和;
子步骤三、计算第一权重和与第二权重和的商,得到第一文本和第二文本的相似度,优选地,将第一权重和除以第二权重和得到的商作为第一文本和第二文本的相似度。
本实施例利用预定词汇库从两个文本的词汇并集中选取业务相关的词汇,之后利用得到的业务相关词汇以及两个文本的词汇交集计算得到文本相似度,该技术方案有效提高了文本相似度的计算精度,克服了现有技术中只利用文本中的词汇计算文本相似度精度不高的缺陷。进一步地,聊天机器人利用准确的文本相似度,能够为用户提供更加准确的答复,提高了聊天机器人的服务质量和用户的体验度。
在一个实施例中,如图2所示,预定词汇库还可以利用如下步骤形成:
210、获取若干个第一预定文本;其中,第一预定文本与第一文本和/或第二文本为业务相关文本;
此步骤中,第一预定文本是特定业务场景下的业务相关文本,这里的第一预定文本可以在具体的业务场景下通过积累得到;
220、对每个第一预定文本进行分词处理,得到若干个第一预定词汇;
230、统计每个第一预定词汇出现的次数,得到每个第一预定词汇的词频;
240、选取前n个词频最大的第一预定词汇,形成预定词汇库,其中n为正整数,
此步骤就是选取在特定业务场景下出现次数多的词汇,形成预定词汇库。
在一个实施例中,如图3所示,预定词汇库还可以利用如下步骤形成:
310、获取若干个第二预定文本;其中,第二预定文本与第一文本和/或第二文本为业务相关文本;
此步骤中,第二预定文本是特定业务场景下的业务相关文本,这里的第二预定文本可以在具体的业务场景下通过积累得到;
320、对每个第二预定文本进行分词处理,得到若干个第二预定词汇;
330、计算每个第二预定词汇出现的次数与第二预定文本的数量的商,得到每个第二预定词汇的频率;
340、筛选频率大于预定值的第二预定词汇,得到预定词汇库;
此步骤即是选取在特定场景下频率较大的词汇,形成预定词汇库。
在一个实施例中,文本相似度计算方法还包括如下步骤:
410、获取第一目标集合中所有词汇的预定权重;
420、获取第三目标集合中所有词汇的预定权重。
本实施例中的预定权重是预先设定的,可以根据实际应用场景改变。
下面用过一个具体的实施例对本发明的文本相似度计算方法进行说明。
本实施例计算q1、q2两个文本的相似度,q1:“今天天气很好,我是湖南人,今年26岁,信用卡很好,我想办理”,q2:“信用卡办理”,本实施例利用如下步骤计算上述两个文本的相似度:
步骤一、对文本q1、q2进行分词处理,得到两个词汇的集合,分别是{信用卡,办理,我,是,湖南,人,今天,天气,很好,今年,26,岁,好,想}和{信用卡,办理};
步骤二、计算上述两个词汇的集合的交集,得到集合{信用卡,办理},计算上述两个词汇的集合的并集,得到集合{信用卡,办理,我,是,湖南,人,今天,天气,很好,今年,26,岁,好,想};
步骤三、利用预定词汇库,从上述并集中提取业务相关词汇,得到集合{信用卡,办理};
步骤四、利用上述交集以及业务相关词汇的集合,计算两个文本q1、q2的相似度,若预定每个词汇的权重均相等,则得到的相似度为1。
可见,本实施例在计算文本相似度的过程中,剔除了业务不相关词汇,得到的文本相似度值相对于现有方法计算得到的文本相似度有所提高,适用于长句相似度的计算,避免了达不到置信度造成的无法为用户提供答复的缺陷。
本实施例中的预定词汇库可以是预先设定好的,其中包括特定业务场景下的业务相关词汇。当然预定词汇库也可以利用如下步骤获取到:
步骤一、特定业务场景下存在如下几个预定文本:“信用卡办理”、“信用卡怎么办”、“怎么办理信用卡”、“办理信用卡”以及“办信用卡”,统计上述预定文本中各个词汇出现的词频,并按照词频从大到小排序,得到如下序列:信用卡、办理、办、怎么;
步骤二、根据实际业务需求,选取前n个词汇,得到预定词汇库。
本实施例也可以通过如下步骤获取预定词汇库:
步骤一、特定业务场景下存在如下几个预定文本:“信用卡办理”、“信用卡怎么办”、“怎么办理信用卡”、“办理信用卡”以及“办信用卡”,统计上述预定文本中各个词汇出现的词频,并按照词频从大到小排序,得到如下序列:信用卡、办理、办、怎么;
步骤二、计算每个词汇的词频与预定文本的数量的商,得到每个词汇的频率;
步骤三、选取频率大于预定值的词汇,得到预定词汇库,这里的预定值可以根据实际应用场景灵活设定。
对应于上述文本相似度计算方法,本发明实施例还公开了一种文本相似度计算装置,如图4所示,该装置包括:
第一集合生成模块,用于分别对第一文本和第二文本进行分词处理,得到第一词汇集合和第二词汇集合;
集合处理模块,用于计算第一词汇集合与第二词汇集合的交集,得到第一目标集合;计算第一词汇集合与第二词汇集合的并集,得到第二目标集合;
第二集合生成模块,用于从第二目标集合中筛选出包含在预定词汇库中的词汇,得到第三目标集合;
相似度计算模块,用于利用第一目标集合中每个词汇的预定权重和第三目标集合中每个词汇的预定权重,计算得到第一文本和第二文本的相似度。
在一个实施例中,如图5所示,文本相似度计算装置还包括:
第一预定文本获取模块,用于获取若干个第一预定文本;其中,所述第一预定文本与所述第一文本和/或所述第二文本为业务相关文本;
第一预定词汇获取模块,用于对每个所述第一预定文本进行分词处理,得到若干个第一预定词汇;
词频统计模块,用于统计每个所述第一预定词汇出现的次数,得到每个所述第一预定词汇的词频;
第一预定词汇库生成模块,用于选取前n个词频最大的所述第一预定词汇,形成所述预定词汇库,其中n为正整数。
在一个实施例中,如图6所示,文本相似度计算装置还包括:
第二预定文本获取模块,用于获取若干个第二预定文本;其中,所述第二预定文本与所述第一文本和/或所述第二文本为业务相关文本;
第二预定词汇获取模块,用于对每个所述第二预定文本进行分词处理,得到若干个第二预定词汇;
频率计算模块,用于计算每个所述第二预定词汇出现的次数与所述第二预定文本的数量的商,得到每个所述第二预定词汇的频率;
第二预定词汇库生成模块,用于筛选频率大于预定值的所述第二预定词汇,得到所述预定词汇库。
在一个实施例中,相似度计算模块包括:
第一权重计算子模块,用于计算第一目标集合中所有词汇的预定权重的和,得到第一权重和;
第二权重计算子模块,用于计算第三目标集合中所有词汇的预定权重的和,得到第二权重和;
相似度计算字模块,用于计算第一权重和与第二权重和的商,得到第一文本和第二文本的相似度。
在一个实施例中,文本相似度计算装置还包括:
第一预定权重获取模块,用于获取第一目标集合中所有词汇的预定权重;
第二预定权重获取模块,用于获取第三目标集合中所有词汇的预定权重。
本发明上述实施例中的装置是与本发明上述实施例中的方法对应的产品,本发明上述实施例中的方法的每一个步骤均由本发明上述实施例中的装置的部件或模块完成,因此对于相同的部分不再进行赘述。
对应于上述实施例的文本相似度计算方法和文本相似度计算装置,本实施例还提供了一种智能机器人,所述智能机器人包括:
文本接收部件,用于接收第一文本,所述第一文本为用户提问文本;
文本获取部件,用于从预定问答库中获取至少一个第二文本,所述第二文本为标准问题文本;所述预定问答库包括至少一个标准问题文本和每个标准问题文本对应的标准答案文本;
相似度计算部件,用于利用权利要求1至5任一项所述的文本相似度计算方法,计算所述第一文本与每个所述第二文本的目标相似度;
问答匹配部件,用于选取最大的所述目标相似度对应的标准问题文本作为与所述用户提问文本相匹配的目标文本;
答案获取部件,用于从所述预定问答库中获取所述目标文本对应的所述标准答案文本,得到所述用户提问文本的答案。
智能机器人利用上述实施例得到的准确的文本相似度,能够为用户提供更加准确的答复,提高了只能机器人的服务质量和用户的体验度。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!