基于多模态表征的细粒度图像分类方法与流程
本发明涉及一种基于多模态表征的细粒度图像分类技术,属于计算机视觉技术领域。
背景技术
在计算机视觉研究领域,图像分类作为一个重要的研究内容,已经在众多现实场景中得到应用,如自动驾驶中的道路场景识别,安防领域中的人脸识别等。在图像识别的任务中,细粒度图像分类越发得到重视。细粒度图像分析任务相对通用图像(general/genericimages)任务的区别和难点在于其图像所属类别的粒度更为精细,也就是细粒度分类最大的特点:类内差别大,类之间差别小。这些精细分类在图像视觉上相似度非常高,需要提取其中细粒度的特征来区分,但是在细粒度类别标记时一般需要大量的领域知识,因此标注工作量大,并且对于标记人员的要求也比较高,因此如何设计系统识别图像类别,是一个紧迫和艰巨任务。
当前图像分类中主要涉及到对高区分度的物体进行分类例如:马和猫,这些图像具有很强的视觉区分度,这些图像中相似成分更多是偶然性的,而非系统的相似。但是相对于同种类别中不同图像不仅具有高度的轮廓相似度,而且仅在某些细微的部位有颜色可见形式不同,也就是这种相似成分非常高,并且这些图像相似更多的是系统性的,不容易区分的。另一方面,同一物体的不同光照,不同姿势下的在图像上的表现都有很大的差别,细粒度图像分类的难点,就是如何在不同物种的事物,在视觉的各种不同侧面显示极高的视觉相似度,挖掘其中细微的图像差异,并且保证对图像的正确分类。如之前所述,在细粒度图像分类中,由于将同类数据细化到不同物种,类别越精细,标注数据的获取越困难,如何在少量的标注数据上训练网络,使得网络能够得到好的分类效果,是值得思考的问题。
随着深度学习技术不断进步和普及,细粒度图像识别在计算机视觉领域成为了一个研究热点。由于细粒度分类中物体的差异仅体现在细微之处。如何有效地对前景对象进行检测分类,并从中发现重要的局部区域(partlocation)信息,也就是更具区分效果的特征,成为了细粒度图像分类算法要解决的关键问题。对细粒度分类模型,可以按照其使用的监督信息的强弱,分为基于强监督信息的分类模型和基于弱监督信息的分类模型两种大类,,另外还有一种工作是引入辅助信息实现图像识别。这些方法主要内容如下:
(1)所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(obiectboundingbox)和部位标注点(partannotation,同时对应着attribute)等额外的人工标注信息,并且在测试的阶段同时,使用这些标注信息。
(2)思路同强监督分类模型类似,弱监督分类模型同时也需要借助全局和局部信息来做细粒度级别的分类。而区别在于,弱监督细粒度分类希望在不借助partannotation的情况下,也可以做到较好的局部信息的捕捉。该方法主要通过在训练阶段通过检测网络(detectionnetwork),检测关键的局部位置以及相关的点,从而在测试的时候只使用物体级别的标注实现整个识别过程。
(3)引入文本信息的模型主要考虑到,文本中有很多描述待分类物体的文本数据,这些数据中会有大量的描述信息,这些信息很多时候是和分类相关的,有时候能够很好的区分待测物体的关键点,如何有效利用这些文本信息成为该类方法主要考虑的问题。
目前,经过大量的调查和研究,细粒度图像分类在理论上已经取得了长足的进步。考虑到文本和知识库中提供了大量的图像标签的语义信息以及相关的结构化信息,以及文本中具有分类物体大量描述信息,如何将这些不同模态的信息相辅相成,必然成为一个有趣的研究方向,将为图像分类任务提供了更多非视觉信息支持。
技术实现要素:
技术问题:本发明提供一种提高了细粒度图像分类的精确度,能够提高图像分类的任务的准确度,尤其是对垂直领域的细粒度的分类任务,具有很好的分类效果的基于多模态表征的细粒度图像分类方法。
技术方案:本发明的基于多模态表征的细粒度图像分类方法,包括如下步骤:
1)确定识别的领域以及该领域的图像数据集合<x,y>∈s,其中s表示所有待分类图片,x表示待分类图片,y表示分类标签;分类标签y对应人为构建的视觉属性集合ai∈a,其中ai表示图像x的第i个视觉属性,a表示所有图像的视觉属性集合;
2)根据分类标签y,从已有的同义词词库和上下文词库中分别抽取y的同义词和上下位词,所有的抽取的结果作为领域知识实体;根据所述领域知识实体从知识库中抽取全部三元组知识,根据视觉属性集合a,构建视觉知识三元组与抽取的三元组知识组成最终的知识库;
3)利用知识库表示领域的知识嵌入模型,得到分类标签y在知识库空间下的低维向量表达δ1(y);
4)利用搜索引擎或者从百科文本中,抽取待识别图像的领域文本;
5)利用百科文本训练词嵌入模型,对所述步骤4)中抽取的待识别图像的领域文本进行微调训练,得到分类标签y在文本空间中的向量表达δ2(y);
6)设计双层卷积神经网络处理图待分类图像,第一层为分类网络fb,第二层为检测网络fa;利用已有的图像数据集初始化训练分类网络fb,分类网络获取图像的全局视觉特征xb;检测网络fa获取图像的局部视觉特征xa,根据下式将两种网络得到的视觉特征通过向量点积运算操作进行融合,得到融合后的视觉特征xab:
xab=xa⊙xb
其中,⊙表示向量点积运算;
7)利用物体的边界信息(x,y,h,w)作为检测网络的监督目标,根据下式计算检测网络的平方误差la:
其中,x,y表示待检测物体的左上角坐标,h,w表示待检测物体的高度和宽度,x′,y′为检测网络预测的物体左上角坐标,h′,w′为检测网络预测的物体的高度和宽度;
8)在分类网络fb上添加两层无激活函数的全连接层,处理成映射回归网络,利用图像标签在知识库的嵌入向量δ1(y)和文本空间的嵌入向量δ2(y)作为分类网络fb的监督目标,根据下式计算监督的平方误差lb:
其中向量
9)利用优化领域常用的误差优化算法训练网络,根据下式将网络训练时的监督目标结合检测网络和分类网络的监督目标组合成l(x,y):
l(x,y)=α*la+lb
其中α为超参数,作为两个网络的平衡因子,根据交叉验证方法选择最优的数值,具体计算公式如下:
优化l(x,y)的具体过程为:将整个图像数据集s划分为训练集s1和测试集s2,在s1上优化l(x,y),使得l(x,y)最小化,并且训练的过程中实时在s2上进行收敛性验证,直到测试集上分类准确度收敛稳定。
10)对于一个全新的图像x,通过整个网络得到图像的视觉特征
进一步的,本发明方法中,步骤3)中的知识嵌入模型为transr模型。
进一步的,本发明方法中,步骤4)中的百科文本为维基百科中实体页面对应的文本。
进一步的,本发明方法中,步骤5)中的词嵌入模型为word2vec模型。
进一步的,本发明方法中,步骤6)中的已有的图像数据集为imagenet,所使用的分类网络fb为vgg、googlenet或resnet的底层卷积设计结构;识别的图像预处理成224*224*3数据结构作为网络输入,预处理训练完毕后,剔除softmax层,加入两层全连接的映射层,作为最终分类网络fb的整体结构。
进一步的,本发明方法中,步骤6)中的检测网络fa采用与alexnet一致的网络。
进一步的,本发明方法中,步骤9)中的误差优化算法为批梯度下降算法。
本发明根据具体的识别图像的领域从大规模的知识库中抽取相关的领域知识,期望将领域知识库中的信息融入图像分类中。本发明将根据图像标签列表和属性集合,作为该图像领域的领域实体,根据这些实体知识作为全部的关键词查询知识库中的相关信息,从而抽取出领域知识库。领域知识库作为图像之外的另一种模态信息,该领域知识库包含了丰富的实体信息以及实体与实体之间的关系信息;本发明同时考虑利用文本信息,文本信息为细粒度图像识别提供描述信息。最终通过协同关联的深度学习模型,该模型将以图像作为输入,以文本和知识库所在的词或者知识的嵌入空间作为输出,通过端到端的学习,将非结构化的文本空间,结构化的知识库空间以及图像空间,三种不同模态表征关联统一建模学习。
本发明将设计模型将领域知识库中丰富的结构化的信息加入到图像分类的过程中,为了能够更好的表达知识库中的知识,使得能够被机器学习相关模型有效利用,需要对知识得到机器多能理解的向量表达形式。本发明使用知识嵌(embedding)技术得到知识的灵活表达形式,从而获得图像分类中的标签的分布式的向量表达,并期望分布式表达能够包含知识库中的语义信息,也就是本发明中将通过对知识库中的知识的低纬嵌入表达,捕获图像不同的分类标签以及视觉属性的关系信息和语义信息。
本发明利用知识库的嵌入模型,将知识用分布式的向量表达,结合文本的分布式词嵌入表达形式,从而获取图像分类中标签的语义向量表达。并且设计深度学习模型,分别通过检测网络和分类网络学习图像不同层面的特征,将图像与其对应的分类标签的语义向量表达形式映射在一起,提高了细粒度图像分类的精确度。具体的来说,本发明方案通过如下步骤实现细粒度图像分类:
步骤a1-a5是实体在知识库空间下表达映射过程:
a1:确定识别的领域,图像数据<x,y>∈s:表示所有待分类图片,x,y表示图片对应的图像和分类标签,并且图像分类标签列表y∈l,其中每个分类标签yi对应一些人为标注的视觉属性集合ai∈a。
a2:根据图像分类标签y,从已有的同义词词库和上下文词库中分别抽取相关的近义词和上下位词,所有的抽取的结果作为领域知识实体;
a3:根据领域知识实体从大规模的知识库中抽取全部相关的三元组知识;
a4:结合相关的视觉信息,构建视觉知识三元组与a3抽取的三元组知识组成最终的知识库;
a5:利用知识库嵌入表达模型,得到知识的向量表达形式,得到待分类标签y在知识库空间下的低维向量表达:δ1(y)。
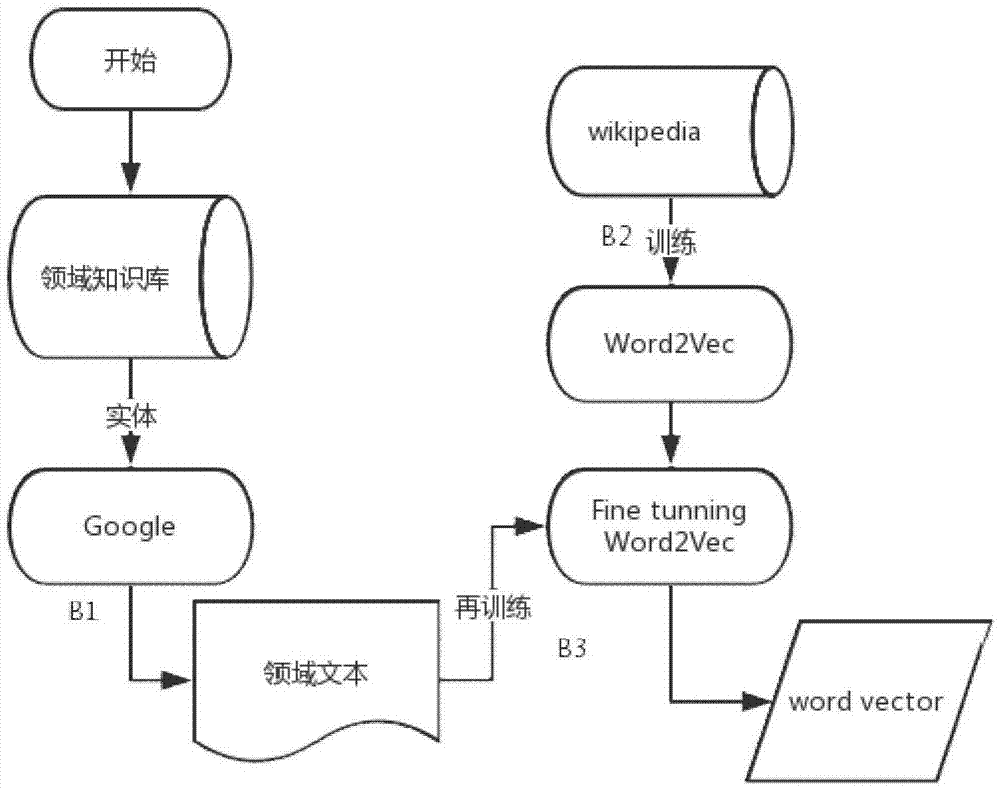
b1-b3是分类实体在文本空间下表达向量的获取步骤:
b1:通过搜索引擎或者大规模的百科文本中,抽取相关的领域文本;
b2:在百科文本中训练词嵌入模型,作为词嵌入模型的初始化过程;
b3:将词嵌入模型在b1中获取的领域文本进行微调训练,得到分类实体在文本空间中的向量表达:δ2(y)。
c1-c7是将图像映射到知识库和文本空间的步骤:
c1:通过在大规模的图像数据库训练初始化卷积神经网络,作为分类网络:fb的预训练;
c2:定义网络的基本架构包括检测网络fa和分类网络fb,其中检测网络fa的输出是待识别物体的边界的右上坐标和长度、宽度值,用(x,y,h,w)表示;分类网络的输出监督是实体在知识库和文本空间的向量表达;
c3:设计检测网络的输出监督形式为检测物体的边界;
c4:分类网络设计为映射回归网络,其监督的目标为标签y用嵌入空间δ1(y)和δ2(y);
c5:检测网络和分类网络在优化过程中联合建模,其中检测网络的得到的视觉特征为:xa,分类网络得到的分类特征为:xb,二者通过特征向量点积运算操作相互融合影响;
c6:通过梯度下降优化整个模型,通过验证模型在训练数据集上准确度是否收敛判断模型是否训练完毕;
c7:模型的具体使用过程中,对于一个全新的图像x,通过如下计算公式在候选的y集合中选择分类结果。
本发明方法结合图像分类标签、图像视觉属性,对传统的大规模知识库进行丰富,在大规模知识库的基础上抽取出领域知识库,并且将领域知识库,领域文本信息与图像信息协同关联建模,建模中提出一个端到端的深度学习模型,将三种不同模态信息映射关联,从而提高细粒度图像识别的效果。
有益效果:本发明主要考虑到利用图像之外的模态信息作为图像识别的辅助信息,其中构建的知识库的优势就是:1)规模较小,便于分析;2)将领域知识库中的实体知识映射表达的时,使得分布式的知识嵌入表达更加具有垂直领域针对性。并且利用知识库的嵌入模型,将知识用分布式的向量表达,结合文本的分布式词嵌入表达形式,从而获取图像分类中标签的语义向量表达。并且设计深度学习模型,分别通过检测网络和分类网络学习图像不同层面的特征,将图像与其对应的分类标签的语义向量表达形式映射在一起,从而能够提高图像分类的任务准确度,尤其是对垂直的具体领域的细粒度的分类任务,具有很好的分类效果。
附图说明
图1为从领域知识库中获取知识嵌入的流程图。
图2为从领域文本中获取知识嵌入的流程图。
图3为基于多模态信息联合建模识别图像的流程图。
具体实施方式
下面结合附图和实例对本发明的技术方案进行详细说明。
如图1所示,步骤a1-a5是实体在知识库空间下表达映射过程:
a1:确定识别的领域,例如科研常用的鸟类图像数据<x,y>∈s:表示所有待分类图片,x,y表示图片对应的图像和分类标签,并且图像标签列表y∈l,其中每个图像标签yi对应一些人为的视觉属性集合ai∈a。
a2:根据图像标签y,从已有的同义词词库wordnet和上下文词库中分别抽取相关的近义词和上下位词,丰富当前分类领域的知识,所有的抽取的知识作为领域知识实体;
a3:根据领域知识实体从大规模的知识库dbpedia中抽取全部相关的三元组知识,这一步骤是抽取基本层面的领域知识三元组;
a4:结合相关的视觉信息,视觉信息提供了大量的可区分性的属性,这些属性对物体的识别具有至关重要的作用,由于视觉属性是一个共享的属性,也就是不同实体的对应图像都可能具有这种特性,为了得到属性和标签之间的关系,可以构建属性与标签对应的三元组来丰富当前抽取的领域知识库,与a3步骤抽取的三元组知识组成最终的知识库;
a5:利用知识库嵌入模型transr将结构化的三元组知识表示为低维稠密的实数向量表达形式,并且保留知识库中三元组隐含的结构化信息,从而得到待分类标签y在知识库空间下的低维向量表达:δ1(y)。
如图2所示,b1-b3是分类实体在文本空间下表达向量的获取步骤:
b1:通过搜索引擎google或者大规模的维基百科文本中,抽取相关的领域文本;
b2:在百科文本中训练词嵌入模型word2vec,作为词嵌入模型的初始化过程,该步骤保证了word2vec的浅层网络表示的稠密向量具有一个语义层面的实值初始化,利于后面步骤得到更加精确的语义向量,这样防止训练出来的单词的向量由于维基百科中的文档中图像标签统计数量较少,使得向量表达不够准确;
b3:将词嵌入模型word2vec在b1中获取的领域文本进行微调训练,得到分类实体在文本空间中的向量表达:δ2(y)。
如图3所示,c1-c7是将图像映射到知识库和文本空间,并且对细粒度图像识别分类的步骤:
c1:通过在大规模的图像数据库imagenet训练初始化卷积神经网络vgg,googlenet,resnet等网络,作为分类网络fb的预训练,与训练的过程能够使得网络的浅层部分能够得到更加泛化的特征,在后续的训练过程卷积部分的参数将被冻结,仅仅优化全连接层的网络参数,保证网络不易过拟合。
c2:定义网络的基本架构包括检测网络fa((alexnet)和分类网络fb。其中检测网络fa的输出是待识别物体的边界的右上坐标和长度、宽度值,用(x,y,h,w)表示,检测网络能够提取到物体的边缘和局部特征,该类特征对于区分细粒度图像具有决定性的作用;分类网络的输出监督是实体在知识库和文本空间的向量表达,从而有效的利用了知识库和文本中的语义知识,该流程基于的数学原理是贝叶斯后验概率最大化:
p:f(x)=argmaxip(y/x)
模型将整体的标签y用嵌入空间δ1(y)和δ2(y)来表示,所以整体的计算公式用如下计算公式表示:
f(x)=argmaxip(δ1(y),δ2(y)|x)
考虑到δ1(y)和δ1(y)是在不同模态中获取得到的语义表达形式,其在y下是符合条件独立的所以最终的计算公式为:
c3:设计检测网络的输出监督形式为检测物体的边界,这里设计的网络的输出不在是多分类输出的softmax层,而是多元回归层,那么定义检测网络的监督的目标为:
其中为了方便ti和t′i(i=1,2,3,4))分别表示为物体的真实边界和检测网络的预测边界。
c4:分类网络设计为映射回归网络,该回归网络将视觉特征v经过两个线性变化层,从而使得视觉空间特征能够分别线性映射到对应的知识库语义空间中和文本语义空间中,其监督的目标为标签y用嵌入空间δ1(y)和δ2(y),将二者通过一个公式联合在一起:
其中v表示网络的得到的视觉特征,m表示线性映射矩阵。
c5:检测网络和分类网络在优化过程中联合建模,其中检测网络的得到的视觉特征为:xa,分类网络得到的分类特征为:xb,二者通过特征向量点积运算操作相互融合影响,计算公式如下:
xab=xa⊙xb
通过联合两个网络同时训练,训练过程采用随机梯度下降算法,网络的最终的训练目标计算公式为:
l(x,y)=α*la+lb
其中α为超参数,作为两个网络的平衡因子,对于不同应用场景下根据交叉验证选择最优的数值,通常定义在0.5~1.0之间的一个实数,具体确定计算公式:
c6:通过梯度下降优化整个模型,模型在训练的过程中,时刻观察不同时刻模型的收敛情况,当模型的在整体数据集上的准确度逐渐收敛,可以认为模型训练完毕。通过如下计算公式验证模型在训练数据集上的稳定:
c7:模型的具体使用过程中,对于一个全新的图像x,通过比较欧式距离来确定最终的分类结果。通过如下计算公式在候选的y集合中选择分类结果:
为了验证本发明的可行和有效性,选择了实验数据为caltech-ucsdbirds,最终可在测试数据集上达到87%的准确度,准确度在相关研究领域为最好的结果。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!