一种基于哈希编码的印花织物图像检索方法与流程
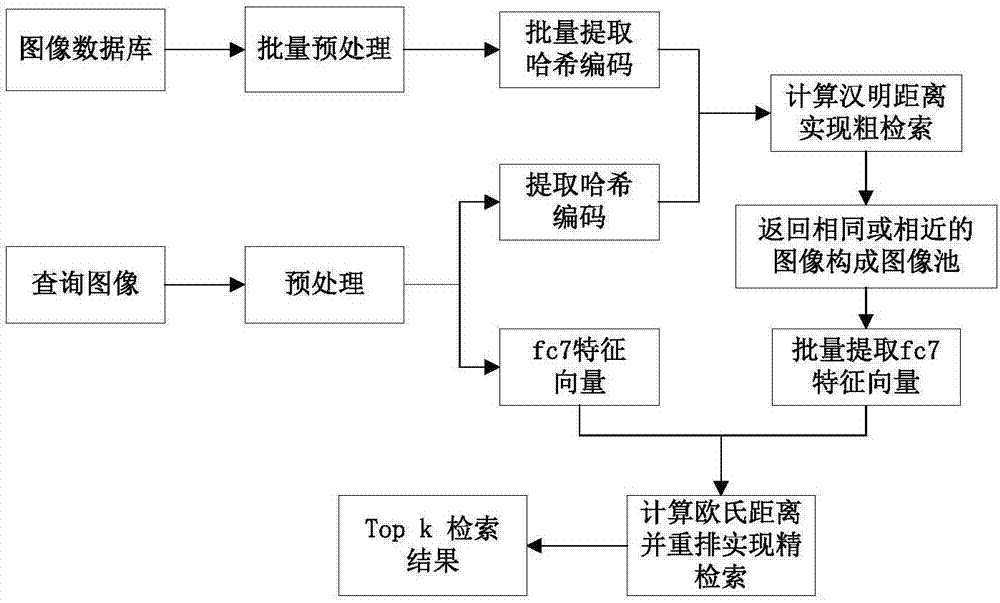
本发明属于计算机与机器视觉技术领域,具体涉及一种基于哈希编码的印花织物图像检索方法。
背景技术
印花织物作为纺织企业生产的基本资源,其在纺织业的发展中占据着重要地位。而对印花织物图像的检索在该领域也具有广泛的应用,如库存管理、在线选购、花型设计等。如何对图像数据进行高效快速的检索以满足用户需求是一个亟待解决的问题。传统的检索方式基本都是基于图像底层视觉特征(如颜色、形状、纹理等)来衡量两幅图像之间的相似性,但这些视觉特征编码固定,缺少学习能力,无法很好地描述图像的高层语义信息,导致检索结果不能很好地满足用户需求。
随着深度学习在计算机视觉领域取得的重大突破,基于深度学习的图像检索成为诸多学者研究的热点,也取得了一定的成果。比较经典的就是利用alexnet网络模型提取图像的fc7全连接层输出特征进行检索,可以获得不错的精度。但卷积神经网络全连接层输出数据为4096维,对于大规模的图像数据检索而言计算量较大,内存占用及时间开销也是用户不愿接受的。近年来,二进制哈希由于其存储空间小和匹配速度快的优势而引起了广泛关注,计算两个低维哈希编码之间的汉明距离能够极大的减少计算成本和时间开销。
技术实现要素:
本发明的目的在于提供一种基于哈希编码的印花织物图像检索方法,解决了现有检索方法中存在的图像检索准确率低、耗费时间长的问题。
本发明所采用的技术方案是,一种基于哈希编码的印花织物图像检索方法,具体按照以下步骤实施:
步骤1,在imagenet数据集上进行有监督训练,得到预训练模型,即alexnet网络;
步骤2,建立印花织物数据库,并批量进行预处理;
步骤3,对经步骤1后得到的alexnet网络进行修改;
步骤4,利用步骤2中建立的印花织物数据库对经步骤3后得到的alexnet网络进行fine-tuning;
步骤5,利用步骤4中fine-tuning得到的网络模型提取每张图像的哈希二值编码,计算查询图像与数据库图像二值哈希编码之间的汉明距离,得到与查询图像最相似的m个池内图像;
步骤6,计算池内m个图像与查询图像fc7层特征向量之间的欧式距离,将图像数据库中的图像按欧式距离由小到大排列,提取出与最小欧式距离相对应的几幅图像,即为要检索的相似度最高的topk图像。
本发明的特点还在于,
步骤1中,alexnet网络,包括五个卷积层和三个全连接层,第一卷积层conv1、第二卷积层conv2、第三卷积层conv3、第四卷积层conv4和第五卷积层conv5,第六全连接层fc6、第七全连接层fc7和第八全连接层fc8,并且第一卷积层至第五卷积层直接依次级联,第六全连接层至第八全连接层直接依次级联,第六全连接层直接连接到第五卷积层上;第一卷积层至第五卷积层为特征提取层,第六全连接层至第八全连接层为特征融合层和分类层。
步骤2中,建立印花织物数据库,并批量进行预处理;具体按照以下步骤实施:
步骤2.1,准备用于检索的印花织物图像库,对库中所有图像进行手动分类;
步骤2.2,将经步骤2.1得到的所有印花织物图像分为训练集train和测试集test两个部分,训练集和测试集均包括图像的每一个类,然后根据图像所属类别对训练集和测试集的图像加上对应的标签生成train.txt和test.txt标签文件,其中train.txt和test.txt文件为包含训练集train和测试集test中所有图像名的txt格式文件,其文件内容为“xx/x,x”格式,其中xx/x表示图像名称及格式,最后一个x为图像对应的标签,从0开始;
步骤2.3,经步骤2.2后,将所有图像统一缩放至256*256像素,并将所有图像转换为leveldb格式;
步骤2.4,经步骤2.3后,计算训练集图像的均值,生成对应的均值文件,用于后续网络模型训练及特征提取;均值文件可利用caffe自带的文件compute_image_mean.exe得出;
其中,均值计算公式,如式(1)所示:
式(1)中,xi为输入第i幅图像的像素值,m为训练样本数。
步骤3具体为:在alexnet网络的最后一个全连接层fc8和倒数第二个全连接层fc7之间加入哈希层,激活函数选用sigmoid,并将原始的第一和第二卷基层后的lrn局部响应归一化改为batchnorm批量归一化;
batchnorm归一化的计算公式,如式(2)所示:
步骤4中,利用步骤2中建立的印花织物数据库对经步骤3后得到的alexnet网络进行fine-tuning,具体按照以下步骤实施:
步骤4.1,将修改后的alexnet网络模型输入数据source及均值路径mean_file改为步骤2中得到的文件路径;
第一卷积层、第二卷积层进行卷积操作后依次进行归一化、relu激活及池化操作,第三卷积层和第四卷积层进行卷积操作后进行relu激活操作,第五卷积层进行卷积操作后进行relu激活及池化操作,最后一层全连接层进行卷积操作后依次进行了accuracy和softmax-loss操作;
其中,relu激活采用的激活函数为f(x)=max(x,0);
池化方法采用max最大池化法,计算方法,如式(3)及式(4)所示:
w1=(w0+2*pad-kernel_size)/stride+1(3);
h1=(h0+2*pad-kernel_size)/stride+1(4);
式(3)及式(4)中,pad为边缘扩充默认为0,kernel_size为池化的核大小,设置为3,步长stride为2;w0、h0为输入的特征图宽度和高度,w1、h1则是池化后的宽度和高度;
步骤4.2,修改solver.prototxt中的训练参数,设置合适的基础学习率,并选用nag代替sgd进行权值更新;
步骤4.3,随机提取图像227*227的子块或镜像输入到经步骤4.1后得到修改后的alexnet网络中,复用alexnet模型的前7层权重做fine-tuning,得到第7层、第8层和output层之间的权重。
步骤5具体为:对步骤2中建立的数据库中的图像进行去均值预处理,利用步骤4中fine-tuning得到的alexnet网络模型提取每张图像的哈希二值编码,存储于数据库中,对于查询图像,先去均值,之后以同样的方法提取二值哈希编码,计算查询图像与数据库图像二值哈希编码之间的汉明距离,进行粗检索,得到与查询图像最相似的m个池内图像;
其中,汉明距离的计算公式,如式(5)所示:
式(5)中,x,y为n位的哈希编码,
步骤6具体为:依次对步骤5中得到的m个池内图像与查询图像提取对应的fc7层输出特征向量,计算池内m个图像与查询图像fc7层特征向量之间的欧式距离,将图像数据库中的图像按欧式距离由小到大排列,提取出与最小欧式距离相对应的几幅图像,即为要检索的相似度最高的topk图像;
其中,欧式距离计算公式,如式(6)所示:
si=||vq-vip||(6);
式(6)中,vq为查询图像iq的特征向量,vip为第i个池内图像的特征向量。
本发明的有益效果是,
通过对卷积神经网络进行修改,可同时学习输入图像的fc7层特征以及对应的哈希编码,利用由粗到精的检索方式对查询图像进行topk结果查询,解决了直接利用4096维特征向量进行遍历查询内存占用大及耗时的问题。
附图说明
图1是本发明一种基于哈希编码的印花织物图像检索方法的流程图;
图2是本发明一种基于哈希编码的印花织物图像检索方法的alexnet及加入哈希层的结构图;
图3是本发明一种基于哈希编码的印花织物图像检索方法中利用fine-tuning得到的模型实现由粗到精分级检索示意图;
图4是本发明一种基于哈希编码的印花织物图像检索方法中印花织物数据集在48位和128位哈希编码下top5检索结果图;
图5是本发明一种基于哈希编码的印花织物图像检索方法中利用不同方法实现的top5检索结果图;
图6是本发明一种基于哈希编码的印花织物图像检索方法在网络数据集上top5检索结果图;
图7是本发明一种基于哈希编码的印花织物图像检索方法中在128位哈希编码下不同哈希算法的检索精度曲线图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于哈希编码的印花织物图像检索方法,如图1所示,具体按照以下步骤实施:
步骤1,在imagenet数据集上进行有监督训练,得到预训练模型,即alexnet网络;
其中,alexnet网络包括五个卷积层和三个全连接层,第一卷积层conv1、第二卷积层conv2、第三卷积层conv3、第四卷积层conv4和第五卷积层conv5,第六全连接层fc6、第七全连接层fc7和第八全连接层fc8,并且第一卷积层至第五卷积层直接依次级联,第六全连接层至第八全连接层直接依次级联,第六全连接层直接连接到第五卷积层上;第一卷积层至第五卷积层为特征提取层,第六全连接层至第八全连接层为特征融合层和分类层;
步骤2,建立印花织物数据库,并批量进行预处理;具体按照以下步骤实施:
步骤2.1,准备用于检索的印花织物图像库,对库中所有图像进行手动分类;
步骤2.2,将经步骤2.1中的印花织物图像分为训练集train和测试集test两个部分,训练集和测试集均包括图像的每一个类,然后根据图像所属类别对训练集和测试集的图像加上对应的标签生成train.txt和test.txt标签文件,其中train.txt和test.txt文件为包含训练集train和测试集test中所有图像名的txt格式文件,其文件内容为“xx/x,x”格式,其中xx/x表示图像名称及格式,最后一个x为图像对应的标签,从0开始;比如00012.jpg0,00236.jpg1,00682.jpg3,分别表示该图像属于第1类、第2类、第4类;
步骤2.3,经步骤2.2后,将所有图像统一缩放至256*256像素,并将所有图像转换为leveldb格式;
步骤2.4,经步骤2.3后,计算训练集图像的均值,生成对应的均值文件,用于后续网络模型训练及特征提取;均值文件利用caffe自带的文件compute_image_mean.exe得出;
其中,均值计算公式,如式(1)所示:
式(1)中,xi为输入第i幅图像的像素值,m为训练样本数;
步骤3,对经步骤1后得到的alexnet网络进行修改,具体为:在alexnet网络的最后一个全连接层(fc8)和倒数第二个全连接层(fc7)之间加入哈希层,激活函数选用sigmoid,并将原始的第一和第二卷基层后的lrn局部响应归一化改为batchnorm批量归一化,以提高网络收敛性,同时消除对其他形式的正则化的依赖,有效防止“梯度弥散”,alexnet网络结构如图2中模块1所示,加入哈希层的网络结构如图2中模块2所示;
归一化batchnorm解决的是在训练过程中,数据的分布改变情况;其原理是在网络上一层输入到下一层之前,对输出进行归一化处理,使均值为0,方差为1,具体操作使用的公式,如式(2)所示:
同时,batchnorm层为了不破坏本层学习到的特征,使用了变换重构,引入可学习参数γ、β,当
batchnorm方法的流程是:
输入:valuesofxoveramini-batch:β={x1...m},可学习参数γ、β
输出:{yi=bnγ,β(xi)}
能得到以下数据:训练样本均值:
其中,xi为输入样本;m为训练样本总数;ε为分母附加值,防止除以方差时出现除0操作,默认为1e-5;
步骤4,利用步骤2中建立的印花织物数据库对经步骤3后得到的alexnet网络进行fine-tuning,具体按照以下步骤实施:
步骤4.1,将修改后的alexnet网络模型输入数据source及均值路径mean_file改为步骤2中得到的文件路径;
第一卷积层、第二卷积层进行卷积操作后依次进行归一化、relu激活及池化操作,第三卷积层和第四卷积层进行卷积操作后进行relu激活操作,第五卷积层进行卷积操作后进行relu激活及池化操作,最后一层全连接层进行卷积操作后依次进行了accuracy和softmax-loss操作;
其中,relu激活采用的激活函数为f(x)=max(x,0);
池化方法采用max最大池化法,计算方法,如式(3)及式(4)所示:
w1=(w0+2*pad-kernel_size)/stride+1(3);
h1=(h0+2*pad-kernel_size)/stride+1(4);
式(3)及式(4)中,pad为边缘扩充默认为0,kernel_size为池化的核大小,设置为3,步长stride为2;w0、h0为输入的特征图宽度和高度,w1、h1则是池化后的宽度和高度;
步骤4.2,修改solver.prototxt中的训练参数,设置合适的基础学习率,并选用nag代替sgd进行权值更新;
步骤4.3,随机提取图像227*227的子块或镜像输入到经步骤4.1后得到修改后的alexnet网络中,复用alexnet模型的前7层权重做fine-tuning,得到第7层、第8层和output层之间的权重;
步骤5,对步骤2中建立的数据库中的图像进行去均值预处理,利用步骤4中fine-tuning得到的网络模型提取每张图像的哈希二值编码,存储于数据库中,对于查询图像,先去均值,之后以同样的方法提取二值哈希编码,计算查询图像与数据库图像二值哈希编码之间的汉明距离,进行粗检索,得到与查询图像最相似的m个池内图像;
其中,汉明距离为任意两个二值编码之间对应位上编码取值不同位的数目,如:(00)与(01)的汉明距离是1,(110)与(101)的汉明距离为2;
汉明距离的计算公式,如式(5)所示:
式(5)中,x,y为n位的哈希编码,
步骤6,依次对步骤5中得到的m个池内图像与查询图像提取对应的fc7层输出特征向量,计算池内m个图像与查询图像fc7层特征向量之间的欧式距离,将图像数据库中的图像按欧式距离由小到大排列,排序后,提取出与最小欧式距离相对应的几幅图像,如图3所示,即为要检索的相似度最高的topk图像;其中,欧式距离计算公式,如式(6)所示:
si=||vq-vip||(6);
式(6)中,vq为查询图像iq的特征向量,vip为第i个池内图像的特征向量。
本发明的方法在alexnet网络中加入哈希层,通过神经元关联将fc7层4096维的输出压缩成一个低维的01二值向量,之后利用二值哈希编码在数据库中查找与查询图像相同或相似的池内图像,并计算查询图像与池内图像的4096维特征向量之间的距离,重排后得到最终检索结果。与现有方法相比,这种基于哈希编码由粗到精的图像检索方法,其具有精度高、检索速度快、占用内存小的优点;同时,该方法中采用了nag及batchnorm优化算法,在提高网络收敛性的同时,能有效防止“梯度弥散”。
实施例
本实施例是针对印花织物数据集进行实验评估,其中fine-tuning阶段使用数据集包含2640张图像,其中包括训练集2400张,测试集240张。
其中,印花织物数据集上两张查询图像分别在48和128位哈希编码下top5检索结果样例,如图4所示,经过实验分析得知在印花织物数据集上128位哈希码能更好地检索出与查询图像类别和语义相似的图像,所以本发明选择在128位哈希编码下进行实验分析验证;
本发明方法采用fine-tuning后的网络模型提取fc7层输出特征向量(fc7特征向量)、128位哈希码与单独采用alexnet卷积神经网络提取fc7层的top5检索结果图,如图5所示,上述方法在印花织物数据集上的检索平均精度(map)以及f1-score,如表1所示,其中,map值计算过程主要分为两步,第一步计算平均准确率ap,假设经过检索系统返回k个相关图像,其位置分别为x1,x2,...,xk,则单个类别的平均准确率api表示为:
第二步对ap进行算术平均,定义图像类别数为m,则map为:
f1-score为查准率p和查全率r的协调平均值,f1值越高说明实验方法比较理想,计算方式如下:
表1印花织物数据集上的map和f1-score
根据图5中对两张图像分别利用以上方法检索的top5结果以及表1数据可以看出,本发明提出的方法检索出的topk结果图像更加准确,其次是单独使用fc7层输出向量检索结果,单独使用fc7层特征向量检索结果固然和本发明提出方法接近,但计算两幅图像之间的4096维特征向量之间的欧氏距离需耗时153.72ms,而计算两个128位哈希编码之间的汉明距离只需0.24ms,这在时间上大大节约了检索耗时,而且利用哈希编码可以很大程度上减少内存消耗。
本发明方法在网络数据集上检索花卉图像返回的top5结果,如图6所示,其证明了本发明方法在其他数据集上也能达到很好地检索效果,具有一定的普适性。
为了评估本发明提出方法的检索性能,并与已有哈希算法进行比较,印花织物数据集在不同哈希编码位数下的平均检索精度值(map),如表2所示:
表2印花织物数据集在不同哈希编码位数下的平均检索精度值
由表2可知,与几种常见的哈希算法相比,在印花织物数据集上本发明方法平均检索精度达到最优。
如图7所示,不同哈希算法在印花织物数据集上的topk检索精度曲线图,其中,使用128位哈希编码,并且利用汉明距离计算图像间的相似性,由图7可知,本发明方法明显优于其他哈希算法。
- 还没有人留言评论。精彩留言会获得点赞!