一种网络语义收集分析及内容概括分析系统及方法与流程
本发明涉及互联网应用技术领域,尤其涉及一种应用于互联网数字营销行业、大数据挖掘及分析行业、物联网行业等一系列与互联网相关的网络语义收集分析及内容概括分析系统及方法。
背景技术:
根据中国互联网络信息中心(cnnic)于今年1月31日发布的第41次《中国互联网络发展状况统计报告》,截至2017年12月,我国的网民规模已经达到了7.72亿,全年新增网民有4074万人,网民规模保持着稳定的增长。其中手机网民规模更是达7.53亿,占总体网民规模有97.5%,同时电视上网的网民规模也呈现提升的趋势,达到了28.2%。
在所有网民的日常浏览行为中,文本内容的信息传递依然占据很大篇幅,因此文本的内容主题在较多场景下都成为网民兴趣的指向标。所以研究网页主体语义、语法成为网民行为研究分析的重要依据。
从当前情况来看,完整的网络语义收集分析和内容概括的方法需要具备以下几个方面:完整文本内容长期的收集聚合、科学合理的内容分类和留存技术、智能的语义归类模型、自适应和自增长的热点词语新增与筛选、分行业和应用的语义价值判断、适当的人工介入接口。
当前市场上主要的语义分析产品主要有以下几个方面的缺点:
1、爬虫类全网络收集页面内容,根据字面关键字概括网页内容,缺点主要在于概括网页内容的时候过于简单,将整个网络浓缩成主要的关键字兴趣,对于文本全文提取较为粗略。
2、通过全文语义分析,归类出主要话题和语法关系,通过算法总结文本内容,缺点是无法区分正面与负面词,例如新闻中的负面内容对于兴趣的影响无法事先区分。
3、对于新出现的话题场景语义,无法记忆性归类,如语义本身并无交集,但是通过某一个影视作品产生关联的内容,是按照其本身语义进行归纳,还是特定作品环境归纳,此时需要人工介入并且记忆。
技术实现要素:
本发明针对上述现有技术的不足,提供了一种网络语义收集分析及内容概括分析系统及方法,其建立了完整的网络语义收集分析和内容概括方法,有效的解决了现有技术在概括网页内容过于简单、无法区分正面与负面词及无法记忆性归类等方面的问题。
为解决现有技术中存在的问题,采用的具体技术方案是:
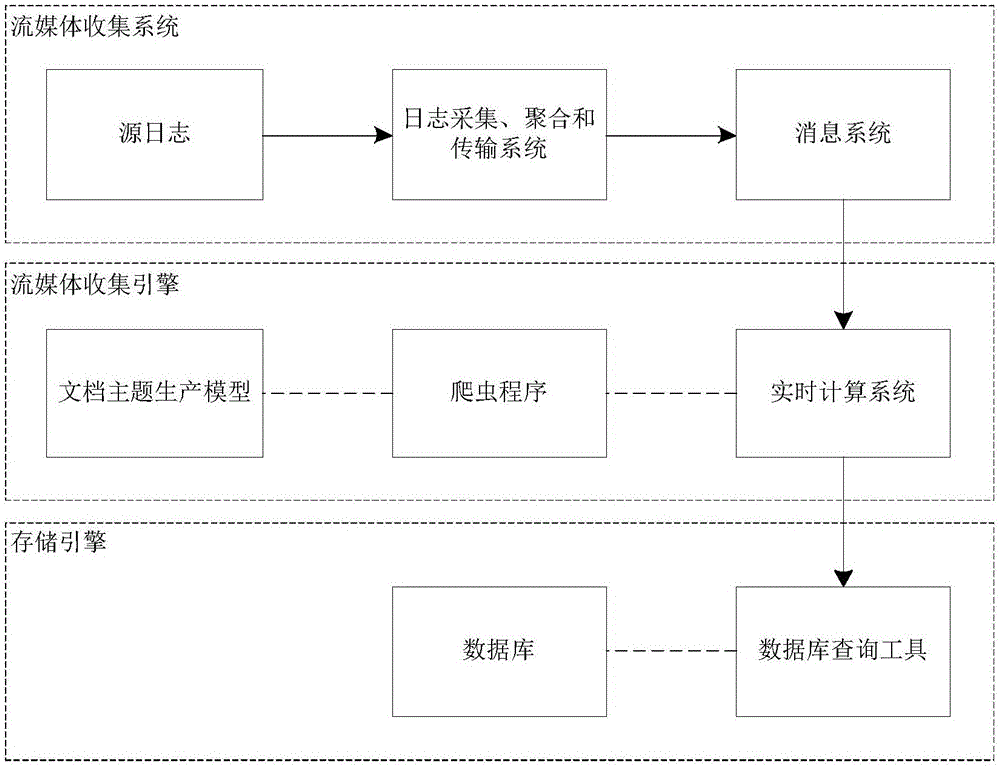
一种网络语义收集分析及内容概括分析系统,其包括流媒体收集模块、流媒体处理引擎模块、储存引擎模块;所述流媒体收集模块用于获取相关日志,并将日志经过日志采集、聚合和传输系统导入高吞吐量消息系统,实现原始日志的收集聚合;所述流媒体处理引擎模块用于从所述高吞吐量消息系统中获取数据并对数据进行处理;所述储存引擎模块用于对经过流媒体处理引擎模块处理后的数据进行存储。
所述流媒体收集模块通过dsp、dmp、ssp渠道获取相关日志,进行实时数据收集。
所述流媒体处理引擎模块对数据处理的方法为:流媒体处理引擎模块从高吞吐量消息系统中获取数据,并将数据输送到分布式实时计算系统,分布式实时计算系统查询数据是否存在;若已存在则直接取用原数据信息;若是新数据,则将完整文本抓取下来,然后通过文档主题生成模型对文本进行文档主题生成处理。
本发明还提供了一种网络语义收集分析及内容概括分析系统的分析方法,其包括以下步骤:
s1、完整文本内容的收集聚合;
s2、完整文本内容的分类及留存;
s3、文本语义的归类;
s4、热点词语的新增与筛选;
s5、文本语义价值的判断。
优选的方案,所述完整文本内容的收集聚合是通过多渠道数据收集得到相关日志,并通过日志中的url下载到网页内容,然后在其html格式下获取得到完整的文本内容。
进一步优选的方案,完整文本内容的分类及留存的方法为:系统根据获取到的完整文本内容,切分出与词库匹配的词,分词采用的是全切分方法,它首先切分出与词库匹配的所有可能的词,再运用统计语言模型决定最优的切分结果,它的优点在于可以解决分词中的歧义问题;再根据词的热度及价值进行评分,最后将这些词语及它们的关联关系一起存入到数据库中。在保存词语的同时,完整的文本内容也将被存入到数据库中,供算法模型进一步分析。
更进一步优选的方案,文本语义的归类的方法为:首先,随机初始化每个词的所属话题,并统计两个频率计数矩阵:“文档-话题计数矩阵”和“词-话题计数矩阵”。其中,所述文档-话题计数矩阵描述每个文档中的主题频率分布,所述词-话题计数矩阵表示每个主题下词的频率分布;然后遍历训练y样本,按照概率公式重新采样每个词所对应的主题,更新两个计数矩阵的计数,直至主题模型收敛。基于主题模型,可以计算出文本的话题分布,将此模型用作机器学习任务的特征,再通过半监督分类算法,从而训练出智能化的文本语义归类模型。
再进一步优选的方案,热点词语的新增与筛选的方法为:后台获取新词,前端界面通过接口展示将新词展示在界面上,并对推荐词进行分类,一定周期后,再通过接口将新的热点词发布到词库模型中。
文本语义价值的判断的方法为:首先,获取完整文本进行词的提取,形成词集;然后使用知识图谱对词集进行过滤,过滤掉一些没有意义的词;再对词集进行分析得到文本的主题分布情况及各自词的频次热度评分;最后再通过智能推荐及人工介入接口对文本语义进行分行业和应用的价值判断。
通过采用上述方案,本发明的一种网络语义收集分析及内容概括分析系统及方法与现有技术相比,其技术效果在于:
1、分词采用的是全切分方法,它首先切分出与词库匹配的所有可能的词,再运用统计语言模型决定最优的切分结果,它的优点在于解决了分词中的歧义问题;
2、本发明与现有技术相比,可以更全面的概括网页内容,具有智能化语义归类、热点词语自适应增长和智能语义价值判断等优点;建立了完整的网络语义收集分析和内容概括方法,有效的解决了现有技术在概括网页内容过于简单、无法区分正面与负面词及无法记忆性归类等方面的问题。
附图说明
图1为本发明一种网络语义收集分析及内容概括分析系统的系统结构示意图;
图2为本发明一种网络语义收集分析及内容概括分析系统分析方法的流程示意图;
图3为本发明的完整文本内容收集流程图;
图4为本发明的完整文本内容分类及留存流程图;
图5为本发明的语义归类模型流程图;
图6为本发明的热点词语的新增与筛选流程图;
图7为本发明的文本语义价值判断流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实例并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
本发明主要基于完整文本内容长期的收集、分类和留存,通过机器学习算法建立起智能的语义归类模型,再辅以热点新词的自适应和自增长体系及适当的人工介入接口,建立起完整的网络语义收集分析和内容概括方法,有效的解决现有技术在概括网页内容过于简单、无法区分正面与负面词及无法记忆性归类等方面的问题。
本发明一种网络语义收集分析及内容概括分析系统主要分为三个模块,如图1所示:
流媒体收集模块:通过dsp、dmp、ssp等渠道获取到相关日志,然后经过日志采集、聚合和传输系统,导入消息系统处理动作流数据,实现原始日志的收集聚合。
流媒体处理引擎模块:从消息系统中获取数据到实时计算系统,实时计算系统会先去数据库中查询这部分数据,如果已存在则直接取用原数据信息,如果是新数据,则会使用爬虫程序将完整文本抓取下来,然后通过文档主题生成模型对文本进行处理。
储存引擎模块:该技术使用开源的分布式数据库系统对数据进行存储,其扩展性良好。
本发明网络语义收集分析及内容概括分析的分析方法流程如图2所示,具体为:
一、完整文本内容的收集,如图3所示:
表示完整文本内容长期的收集聚合过程。我方拥有dsp、dmp、ssp等多个渠道进行实时数据收集,可以长期获取大量的相关日志,通过这些日志中的url下载到网页内容,然后在其html格式下去获取完整的文本内容。
二、完整文本内容的分类及留存,如图4所示:
在获取到完整的文本内容后,系统首先会进行分词操作,分词采用的是全切分方法,它首先切分出与词库匹配的所有可能的词,再运用统计语言模型决定最优的切分结果,它的优点在于可以解决分词中的歧义问题。然后根据这些词语的热度和它们之间的关联关系进行分值评定,最后将这些词语及它们的关联关系一起存入到数据库中,这是个可持续的机器学习过程。在保存词语的同时,完整的文本内容也将被存入到数据库中,供算法模型进一步分析。
三、文本语义的归类,如图5所示:
我方采用的是文档主题生成模型。首先,随机初始化每个词的所属话题,并统计两个频率计数矩阵:文档-话题计数矩阵,描述每个文档中的主题频率分布;词-话题计数矩阵,表示每个主题下词的频率分布。第二步,开始遍历训练样本,按照概率公式重新采样每个词所对应的话题,更新两个计数矩阵的计数。最后重复遍历训练,直到主题模型收敛。
基于主题模型,可以计算出文本的话题分布,将此模型用作机器学习任务的特征,再通过半监督分类算法,从而训练出智能化的文本语义归类模型。
四、热点词语的新增与筛选,如图6所示:
在深度学习中,我们一般用“词向量”来描述一个词。词向量可以挖掘词之间的关系,譬如同义词;也可以用于机器翻译,将一种语言转变成另一种语言;也可以用于提取词语之间的层次关系。基于词向量和人工介入接口,我们形成了一套自适应和自增长的热点词新增体系,用于扩充我们的训练词库。
后台算法在获取到新词之后,会将推荐的词通过接口展现在界面上,管理员可以通过接口在界面上对推荐词进行分类,也可以通过接口人工添加新词。在一定周期后,再通过接口将这些新的热点词发布到词库模型中。
五、文本语义价值的判断:
在文本分析的过程中,一般都会出现多个话题的情况,多个话题可能讲的是同一个话题,也有可能讲的是多个话题。多个话题对文本语义的影响,我们该如何做一个价值判断?首先,我们获取完整文本进行词的提取,形成词集,然后使用知识图谱对词集进行过滤,过滤掉一些没有意义的词,再使用演进成熟的文档主题生产模型和词向量算法对词集进行分析,从而得到文本的话题分布情况及各自词的频次热度评分。最后再通过智能推荐及人工介入接口对文本语义进行分行业和应用的价值判断。
本发明的工作原理为:本发明基于完整文本内容长期的收集、分类和留存,通过机器学习算法建立起智能的语义归类模型,再辅以热点新词的自适应和自增长体系及适当的人工介入接口,建立起完整的网络语义收集分析和内容概括方法,有效的解决现有技术在概括网页内容过于简单、无法区分正面与负面词及无法记忆性归类等方面的问题。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明的保护范围,凡在本发明的精神和原则之内,所作的任何修改、等同替换、均包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!