一种实时智能体感同步的方法及系统与流程
本发明涉及局域网及虚拟现实领域,尤其是一种实时智能体感同步的方法及系统。
【背景技术】
虚拟现实技术是仿真技术的一个重要方向,是仿真技术与计算机图形学、人机接口技术、多媒体技术、传感技术、网络技术、等多种技术的集合。是一门富有挑战性的交叉技术前沿学科和研究领域。虚拟现实技术(vr)主要包括模拟环境、感知、自然技能和传感设备等方面。模拟环境是由计算机生成的、实时动态的三维立体逼真图像。感知是指理想的vr应该具有一切人所具有的感知。除计算机图形技术所生成的视觉感知外,还有听觉、触觉、力觉、运动等感知,甚至还包括嗅觉和味觉等,也称为多感知。自然技能是指人的头部转动,眼睛、手势、或其他人体行为动作,由计算机来处理与参与者的动作相适应的数据,并对用户的输入作出实时响应,并分别反馈到用户的五官。传感设备是指三维交互设备。
但是目前基于虚拟现实技术的实时智能体感同步方案还不完善。
技术实现要素:
本发明提供了一种实时智能体感同步的方法及系统,用以完善基于虚拟现实技术的实时智能体感同步技术。
本发明的一种实时智能体感同步的方法,包括下列步骤:s1、获取操作者人物模型头部动作和手臂动作的实时位置数据;s2、根据所述的实时位置数据,测算当前操作者人物模型的全身位置数据。
其中,s2中还包括:对当前操作者人物模型的全身位置数据增加一个时间维度进行超前测算,得到超前操作者人物模型的全身位置数据。
其中,还包括步骤:s3、根据所述的全身位置数据,对操作者人物模型进行实施的动画播放。
其中,s1中所述的获取操作者人物模型头部动作的实时位置数据,具体包括:传感器捕捉到操作者头部的6自由度转动实时信息;根据所述的操作者头部的6自由度转动实时信息调整当前人物模型的头部摄像头位置,同时设置人物模型的头部位置,以得到操作者人物模型头部动作的实时位置数据,并将操作者与人物模型的头部动作同步。
其中,s1中所述的获取操作者人物模型手臂动作的实时位置数据,具体包括:手柄传感器捕捉到操作者手掌的6自由度转动实时信息;根据所述的操作者手掌的6自由度转动实时信息设置当前人物模型的手掌位置;根据所述手掌位置的变化,自动牵拉调整人物模型的手臂姿势,并得到操作者人物模型手臂动作的实时位置数据。
其中,s3中具体包括:根据所述的全身位置数据得到操作者人物模型位置变化量,据此设置动画播放参数,动画状态机完成动画融合并实现对操作者人物模型实施的动画播放。
其中,s3中还包括:对操作者人物模型移动动画的优化,具体包括:获取手柄传感器模型射出的抛物线与场景产生的交点,所述抛物线由一系列线段连接而成,每条线段的终点是根据起点矢量在重力加速度的作用下计算出来的,公式为:pos=lastpos+forward+vector3.up*n*-gravity*0.1f;其中,pos表示终点,lastpos表示起点,forward表示正方向向量,vector3.up表示世界的上方向,n表示当前点的编号,gravity表示重力系数,f表示当前值是个float;所述交点的竖直投影点即为操作者人物模型的目的地;直接设置操作者人物模型位置实现移动至所述的目的地。
其中,还包括步骤:s4、加载全景视频或全景图片,并渲染在虚拟现实场景中。
本发明的一种实时智能体感同步的系统,包括:头部动作数据获取单元,用于获取操作者人物模型头部动作的实时位置数据;手臂动作数据获取单元,用于获取操作者人物模型手臂动作的实时位置数据;全身位置数据测算单元,用于接收所述的操作者人物模型头部动作和手臂动作的实时位置数据,并测算当前操作者人物模型的全身位置数据。
其中,所述的全身位置数据测算单元还用于,对当前操作者人物模型的全身位置数据增加一个时间维度进行超前测算,得到超前操作者人物模型的全身位置数据。
其中,动画播放单元,用于根据所述全身位置数据测算单元测算的全身位置数据,对操作者人物模型进行实施的动画播放。
其中,所述的头部动作数据获取单元具体是捕捉到操作者头部的6自由度转动实时信息;根据所述的操作者头部的6自由度转动实时信息调整当前人物模型的头部摄像头位置,同时设置人物模型的头部位置,以得到操作者人物模型头部动作的实时位置数据,并将操作者与人物模型的头部动作同步。
其中,所述的手臂动作数据获取单元具体是捕捉到操作者手掌的6自由度转动实时信息;根据所述的操作者手掌的6自由度转动实时信息设置当前人物模型的手掌位置;根据所述手掌位置的变化,自动牵拉调整人物模型的手臂姿势,并得到操作者人物模型手臂动作的实时位置数据。
其中,所述的动画播放单元具体是根据所述全身位置数据测算单元测算的全身位置数据得到操作者人物模型位置变化量,据此设置动画播放参数,动画状态机完成动画融合并实现对操作者人物模型实施的动画播放。
其中,所述的动画播放单元还用于对操作者人物模型移动动画的优化,具体是获取手掌模型射出的抛物线与场景产生的交点,所述抛物线由一系列线段连接而成,每条线段的终点是根据起点矢量在重力加速度的作用下计算出来的,公式为:pos=lastpos+forward+vector3.up*n*-gravity*0.1f;其中,pos表示终点,lastpos表示起点,forward表示正方向向量,vector3.up表示世界的上方向,n表示当前点的编号,gravity表示重力系数,f表示当前值是个float;所述交点的竖直投影点即为操作者人物模型的目的地;直接设置操作者人物模型位置实现移动至所述的目的地。
其中,还包括:全景单元,用于加载全景视频或全景图片,并渲染在虚拟现实场景中。
本发明的实时智能体感同步的方法及系统,完善基于虚拟现实技术的实时智能体感同步技术,可以用于实现虚拟现实课堂教学中的教学资源播放、师生互动、教学流程管理等功能,支持师生多人在同一虚拟空间中的协同互动,带来了更优的用户体验。
【附图说明】
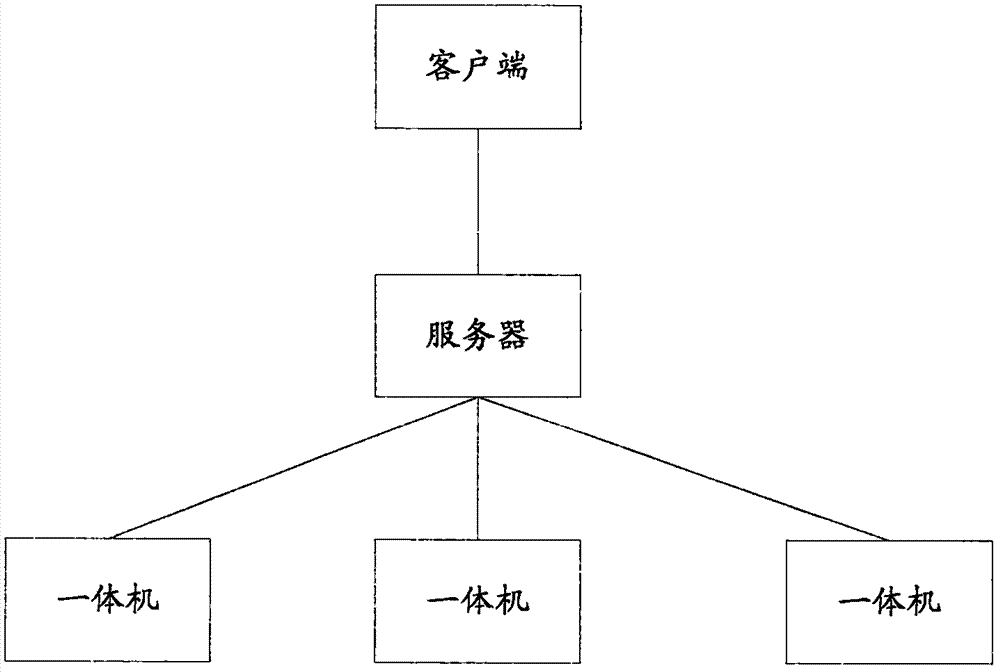
图1是本发明框架性系统结构示意图;
图2是本发明实施例1的方法步骤流程图;
图3是本发明实施例1中的环境模型示意图;
图4是本发明实施例2的方法步骤流程图;
图5是本发明实施例2中的环境模型示意图;
图6是本发明实施例3的系统结构示意图;
图7是本发明实施例3中的环境模型示意图;
图8本发明是实施例4的系统结构示意图;
图9是本发明实施例4中的环境模型示意图。
【具体实施方式】
发明人经过研究提出了一种实时智能体感同步的方法及系统,在具体实现中整套系统是基于局域网的解决方案,该系统用于但不限于实现虚拟现实课堂教学中的教学资源播放、师生互动、教学流程管理等功能,支持师生多人在同一虚拟空间中的协同互动。具体采用基于netty(netty是由jboss提供的一个java开源框架)的c/s通信架构,客户端为pcclient和一体机focusclient,在具体实现中focusclient端可以采用focus头盔,操作者戴上focus头盔后,运行focusclient程序进入vr场景,人物模型支持头部,手臂,转身活动等动作,所有这些动作都是和真实操作者保持同步的,人物模型可以采用finalik技术,模型包含了各种人体关节,支持编程转动,在模型头部处绑定一个u3d摄像头,以此来显示人物模型的视野。服务器为nettyserver。客户端主要采用unity3d技术,通过netty服务器转发实时同步各自的状态,系统架构参见图1所示。主要功能如下:(1)vr课件资源管理:教师使用虚拟现实内容制作工具制作的课件上传至云端后,能实现一键从云端的教学资源库下载资源到本地,并通过type-c接口直接推送进教室里所有vr一体机中,本地已经下载的资源可以自动识别排除。能实现一键清空所有vr一体机上的vr教学资源。能显示vr教学资源下载、安装的进度,以及各台一体机的资源安装情况。对于安装包形式的教学资源可以后台静默安装和卸载。(2)师生分组vr互动教学:针对多人数虚拟现实教学场景,实现了师生分组互动方式。学生被按照物理座位分组,可以通过设置每组人数进行自定义分组管理。每组3-8名学生,默认5人,最后一组如果人数不足,自动合并至上一组。某一组人数调整时后续几组的成员自动依次向前补位,但不会影响到前面的小组。教师用户形象可以出现于所有分组,同时给所有组学生讲解。当场景为全景图片或全景视频时,同一个小组的成员进入同一个全景图片和全景视频。学生可通过手柄实现举手向老师提问功能或取消举手功能。学生举手后获得教师许可发言,其形象可以出现在所有分组中,并获得教师操作权限,教师可以终止其发言。此学生发言或者操作完毕后,使此学生编号从举手队列中消失,收回该学生的语音权、模型操作权和每组复制的影像。(3)vr教学资源播放控制:系统支持在虚拟现实教学场景中播放3d模型、3d场景、全景图片/视频、2d视频、第三方vr内容、传统ppt等多种类型的教学资源,实现展示型虚拟现实教学。系统能在75fps的帧率下播放至少20000片面数的场景和模型,全景视频分辨率至少能达到4096×2160,2d视频分辨至少能达到7680x4320,视频流畅无断帧。支持在vr内用手柄快速切换教学资源,并且可以进行缩放、旋转、拾取操作。(4)vr场景画面传输显示:系统支持将vr里的场景画面传输出来,显示在pc机上和投放到投影仪上,让没有戴上vr一体机的人看到vr里正在发生的事情。以上框架性说明了本发明方法及系统,以下通过实施例描述具体实现方式。
实施例1、本实施例的实时智能体感同步的方法,参见图2所示,包括下列具体步骤:
s101、获取操作者人物模型头部动作和手臂动作的实时位置数据。
具体的头部动作同步技术:focus传感器捕捉到操作者头部的位置实时移动详细信息,可以是6自由度转动信息,传入到focus上运行的u3dclient程序中,u3dclient程序根据这些信息调整当前人物模型的头部摄像头位置(可以是6自由度转动信息),同时设置人物模型的头部位置(可以是6自由度转动信息),由此做到了操作者与模型的头部动作同步。
具体的手臂动作同步技术:focus手柄传感器的实时位置信息,可以是6自由度转动信息,传入到u3dclient程序中,u3dclient程序根据这些信息设置当前人物模型的手掌位置,借助于finalik的机制,手掌位置的变化会自动牵拉调整人物模型的整个手臂的姿势,并得到操作者人物模型手臂动作的实时位置数据。
s102、根据所述的实时位置数据,测算当前操作者人物模型的全身位置数据。
由于focus传感器只提供头部和手臂位置,不提供躯干,腿部等其他部位位置信息,不能通过focus传感器来同步人物模型的全身位置信息,因此发明人经过研究提出了全身位置数据测算单元,即vrbody-rlm模型,其原理是结合头部动作同步技术和手臂动作同步技术,可以得到实时的头部和手臂运动向量信息,以当前头部和手臂的实时运动向量等作为基本输入,来智能预测输出当前整个模型的位置信息(躯干转动方向,角度,脚部是否跟随转动等)。
在具体实现中先获取focus传感器实时数据输入,即上述步骤得到的头部动作和手臂动作的实时位置数据;再将所述的实时位置数据进入全身位置数据测算单元处理,输出预测的全身位置数据;最后优选使用u3d动画技术进行动画播放。
全身位置数据测算单元的处理方式如下:
确定性的policy(deterministicpolicy):a=π(s)a=π(s)
随机性的policy(stochasticpolicy):π(a|s)=p[at=a|st=t]π(a|s)=p[at=a|st=t]
其中,tt是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合,st代表时刻t的状态,s代表其中某个特定的状态;
at∈a(st)at∈a(st),a(st)a(st)是在状态st下的actions的集合,at代表时刻t的行为,aa代表其中某个特定的行为。
奖励信号(arewardsignal)
reward就是一个标量值,是每个timestep中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用rr来表示。
值函数(valuefunction)
reward定义的是立即的收益,而valuefunction定义的是长期的收益,它可以看作是累计的reward,常用vv来表示。
环境模型(amodeloftheenvironment)参见图3所示,其中,t是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合;
at∈a(st),a(st)是在状态st下的actions的集合;
rt∈r∈r是数值型的reward
qπ(s,a)qπ(s,a)策略ππ的行动价值方法。
v*(s)v*(s)最优状态价值方法。
q*(s,a)q*(s,a)最优行动价值方法。
在网络传输过程中,实时位置数据由网络传输,当接收到位置同步信息时,首先进行数据包的解析,包括拆包和合包。数据包包括包头和包体,包头包含了本数据包的长度,通过读取长度确定该数据是否是一个完整的数据包。如果收到的信息长度大于从包头读取的数据包长度,则说明已经收到一条完整的数据包,读出该长度的数据包进行解析,否则继续接受下一条数据包,直到收到一条完整的数据包。
全身位置数据测算单元避免了硬性编码带来的阈值选择问题(例如:头部转动多大角度才进行躯干转动),同时也避免了产生各种扭曲的非正常模型姿势,从而得到一个非常自然的模型姿势。
进一步考虑到实际因素,受限于focus的计算性能与操作者快速运动等情况,实时预测并设置整个模型位置信息是不现实的,会导致模型的位置信息延迟于操作者的实际位置。因此优选的,全身位置数据测算单元对输出的整个模型的位置信息在时间上有超前的预测,即在全身位置数据测算单元输入向量上增加一个时间维度进行训练和预测,进而得到超前操作者人物模型的全身位置数据。
上述得到超前操作者人物模型的全身位置数据具体是在客户端启动时,服务器计算出每个客户端的ping值,当客户端a有移动的操作时,向服务器发送目标点p。服务器收到消息后向每个客户端广播,发送消息中包含时间差(由客户端a和接收消息的客户端的ping值求得),客户端收到移动的消息时,通过时间差求出该时间点客户端a应该所在的位置p0,然后定义一个点p1,该点在p0后p点前,然后计算出a到p1所需的剩余时间,使客户端中的a在该剩余时间中移动到p1点,然后按照a点原来的移动速度移动到p点。旋转角度的计算同理。
ping=(system.datetime.now.millisecond-oritime)*0.5f;
oritime表示服务器向客户端发送检测ping值消息时的服务器时间
timeinterval=pinga+pingb;
timeinterval表示从a开始移动到b接收到a移动的消息需要的时间
p0=timeinterval*movespeed;
p0表示在这段时间内a已经移动的距离
p1=(p-p0)/2+p0;//自定义
p1是自定义的一个点,表示a从开始移动到b端的a与实际a同步位置的距离
movespeedb=p1/timeinterval;
movespeedb表示b端的a移动到p1的速度。
实施例2、本实施例的实时智能体感同步的方法,参见图4所示,包括下列具体步骤:
s201、获取操作者人物模型头部动作和手臂动作的实时位置数据。
具体的头部动作同步技术:focus传感器捕捉到操作者头部的位置实时移动详细信息,可以是6自由度转动信息,传入到focus上运行的u3dclient程序中,u3dclient程序根据这些信息调整当前人物模型的头部摄像头位置(可以是6自由度转动信息),同时设置人物模型的头部位置(可以是6自由度转动信息),由此做到了操作者与模型的头部动作同步。
具体的手臂动作同步技术:focus手柄传感器的实时位置信息,可以是6自由度转动信息,传入到u3dclient程序中,u3dclient程序根据这些信息设置当前人物模型的手掌位置,借助于finalik的机制,手掌位置的变化会自动牵拉调整人物模型的整个手臂的姿势,并得到操作者人物模型手臂动作的实时位置数据。
s202、根据所述的实时位置数据,测算当前操作者人物模型的全身位置数据。
由于focus传感器只提供头部和手臂位置,不提供躯干,腿部等其他部位位置信息,不能通过focus传感器来同步人物模型的全身位置信息,因此发明人经过研究提出了全身位置数据测算单元,即vrbody-rlm模型,其原理是结合头部动作同步技术和手臂动作同步技术,可以得到实时的头部和手臂运动向量信息,以当前头部和手臂的实时运动向量等作为基本输入,来智能预测输出当前整个模型的位置信息(躯干转动方向,角度,脚部是否跟随转动等)。
在具体实现中先获取focus传感器实时数据输入,即上述步骤得到的头部动作和手臂动作的实时位置数据;再将所述的实时位置数据进入全身位置数据测算单元处理,输出预测的全身位置数据;最后优选使用u3d动画技术进行动画播放。
全身位置数据测算单元的处理方式如下:
确定性的policy(deterministicpolicy):a=π(s)a=π(s)
随机性的policy(stochasticpolicy):π(a|s)=p[at=a|st=t]π(a|s)=p[at=a|st=t]
其中,tt是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合,st代表时刻t的状态,s代表其中某个特定的状态;
at∈a(st)at∈a(st),a(st)a(st)是在状态st下的actions的集合,at代表时刻t的行为,aa代表其中某个特定的行为。
奖励信号(arewardsignal)
reward就是一个标量值,是每个timestep中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用rr来表示。
值函数(valuefunction)
reward定义的是立即的收益,而valuefunction定义的是长期的收益,它可以看作是累计的reward,常用vv来表示。
环境模型(amodeloftheenvironment)参见图5所示,其中,t是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合;
at∈a(st),a(st)是在状态st下的actions的集合;
rt∈r∈r是数值型的reward
qπ(s,a)qπ(s,a)策略ππ的行动价值方法。
v*(s)v*(s)最优状态价值方法。
q*(s,a)q*(s,a)最优行动价值方法。
在网络传输过程中,实时位置数据由网络传输,当接收到位置同步信息时,首先进行数据包的解析,包括拆包和合包。数据包包括包头和包体,包头包含了本数据包的长度,通过读取长度确定该数据是否是一个完整的数据包。如果收到的信息长度大于从包头读取的数据包长度,则说明已经收到一条完整的数据包,读出该长度的数据包进行解析,否则继续接受下一条数据包,直到收到一条完整的数据包。
全身位置数据测算单元避免了硬性编码带来的阈值选择问题(例如:头部转动多大角度才进行躯干转动),同时也避免了产生各种扭曲的非正常模型姿势,从而得到一个非常自然的模型姿势。
进一步考虑到实际因素,受限于focus的计算性能与操作者快速运动等情况,实时预测并设置整个模型位置信息是不现实的,会导致模型的位置信息延迟于操作者的实际位置。因此优选的,全身位置数据测算单元对输出的整个模型的位置信息在时间上有超前的预测,即在全身位置数据测算单元输入向量上增加一个时间维度进行训练和预测,进而得到超前操作者人物模型的全身位置数据。
上述得到超前操作者人物模型的全身位置数据具体是在客户端启动时,服务器计算出每个客户端的ping值,当客户端a有移动的操作时,向服务器发送目标点p。服务器收到消息后向每个客户端广播,发送消息中包含时间差(由客户端a和接收消息的客户端的ping值求得),客户端收到移动的消息时,通过时间差求出该时间点客户端a应该所在的位置p0,然后定义一个点p1,该点在p0后p点前,然后计算出a到p1所需的剩余时间,使客户端中的a在该剩余时间中移动到p1点,然后按照a点原来的移动速度移动到p点。旋转角度的计算同理。
ping=(system.datetime.now.millisecond-oritime)*0.5f;
oritime表示服务器向客户端发送检测ping值消息时的服务器时间
timeinterval=pinga+pingb;
timeinterval表示从a开始移动到b接收到a移动的消息需要的时间
p0=timeinterval*movespeed;
p0表示在这段时间内a已经移动的距离
p1=(p-p0)/2+p0;//自定义
p1是自定义的一个点,表示a从开始移动到b端的a与实际a同步位置的距离
movespeedb=p1/timeinterval;
movespeedb表示b端的a移动到p1的速度。
s203、根据所述的全身位置数据,对操作者人物模型进行实施的动画播放。
根据全身位置数据得到操作者人物模型位置变化量,据此设置动画播放参数,动画状态机完成动画融合并实现对操作者人物模型实施的动画播放,具体结合u3d的动画状态融合树,动画遮罩技术实现模型的动画播放,当操作者转身时,根据全身位置数据测算单元的输出得到位置变化量大小,由此设置动画播放参数,动画状态机完成动画融合,人物过渡播放移动效果。
在animatorcontroller中添加一个空状态idel,然后设置动画片断为我们的待机动画。
然后再创建一个动画融合树waltorun:
双击融合树进入编辑状态,在右侧的inspector面板中的motion列表中添加两个元素,从上到下依次选择我们的行走动画和奔跑动画。
创建float类型动画参数run,将融合树的parameter参数设置为run:
最后,将待机状态idel使用translation连接到融合树,设置condition参数为rungreater0.1,反过来融合树到idel的连接condition设置为runless0.1。
遮罩层的基本原理是:能够透过该图层中的对象看到“被遮罩层”中的对象及其属性(包括它们的变形效果),但是遮罩层中的对象中的许多属性如渐变色、透明度、颜色和线条样式等却是被忽略的。比如,我们不能通过遮罩层的渐变色来实现被遮罩层的渐变色变化。要在场景中显示遮罩效果,可以锁定遮罩层和被遮罩层。可以用“actions”动作语句建立遮罩,但这种情况下只能有一个“被遮罩层”,同时,不能设置_alpha属性。不能用一个遮罩层试图遮蔽另一个遮罩层。遮罩可以应用在gif动画上。在制作过程中,遮罩层经常挡住下层的元件,影响视线,无法编辑,可以按下遮罩层时间轴面板的显示图层轮廓按钮,使之变成,使遮罩层只显示边框形状,在种情况下,你还可以拖动边框调整遮罩图形的外形和位置。在被遮罩层中不能放置动态文本。通过加入动作动画进行补偿,使得人物与模型动作同步变得非常真实与流畅,增强了用户vr体验。
优选对操作者人物模型移动动画进行优化,具体包括:抛物线的产生使用了线段射线技术,即整条抛物线是由一系列线段连接成的。每条线段的终点是根据起点矢量在重力加速度的作用下计算出来的,公式为:(终点)pos=(起点)lastpos+forward+vector3.up*n*-gravity*0.1f;其中,pos表示终点,lastpos表示起点,forward表示正方向向量,vector3.up表示世界的上方向,n表示当前点的编号,gravity表示重力系数,f表示当前值是个float。抛物线与场景的交点定位借助了u3d的射线+碰撞器机制自动产生,交点的竖直投影点就是人物模型的目的地。线段射线技术算法可以快速定位目的地,而无需借助u3d自带重力系统的作用产生(重力系统作用于物体仿真产生抛物线需要时间),同时使用gl绘制该抛物线可以让操作者快速看见行动轨迹和目的地,为操作者提供了良好的用户体验。目的地确定后,u3d可以直接设置人物模型位置实现移动。这种瞬时移动的方式避免了连续移动时场景变化带来的眩晕感,进一步提升了用户体验。
s204、加载全景视频或全景图片,并渲染在虚拟现实场景中。
具体在vr场景中,整个vr场景是在一个球体内部,将加载的全景视频和全景图片渲染在vr场景环境球体内表面,而focus操作者的人物模型观察到的就是球体内表面上的全景视频和全景图片,由此达到身临其境的状态。使用u3d的videoplayer组件和movietexture组件可以对全景视频和全景图片进行加载,同时使用u3d的shader技术,修改3d网格渲染面,使球体内表面渲染材质,视频流和图片转换为材质贴到球体里面,完成vr内部全景视频和全景图片的播放与展示。
实施例3、本实施例的实时智能体感同步的系统,参见图6所示,包括下列单元:头部动作数据获取单元301,手臂动作数据获取单元302,全身位置数据测算单元303。
头部动作数据获取单元301,用于获取操作者人物模型头部动作的实时位置数据。具体是focus传感器捕捉到操作者头部的位置实时移动详细信息,可以是6自由度转动信息,传入到focus上运行的u3dclient程序中,u3dclient程序根据这些信息调整当前人物模型的头部摄像头位置(可以是6自由度转动信息),同时设置人物模型的头部位置(可以是6自由度转动信息),由此做到了操作者与模型的头部动作同步。
手臂动作数据获取单元302,用于获取操作者人物模型手臂动作的实时位置数据。具体是focus手柄传感器的实时位置信息,可以是6自由度转动信息,传入到u3dclient程序中,u3dclient程序根据这些信息设置当前人物模型的手掌位置,借助于finalik的机制,手掌位置的变化会自动牵拉调整人物模型的整个手臂的姿势,并得到操作者人物模型手臂动作的实时位置数据。
全身位置数据测算单元303,用于接收所述的操作者人物模型头部动作和手臂动作的实时位置数据,并测算当前操作者人物模型的全身位置数据。
由于focus传感器只提供头部和手臂位置,不提供躯干,腿部等其他部位位置信息,不能通过focus传感器来同步人物模型的全身位置信息,因此发明人经过研究提出了全身位置数据测算单元303,其原理是结合头部动作同步技术和手臂动作同步技术,可以得到实时的头部和手臂运动向量信息,以当前头部和手臂的实时运动向量等作为基本输入,来智能预测输出当前整个模型的位置信息(躯干转动方向,角度,脚部是否跟随转动等)。
在具体实现中先获取focus传感器实时数据输入,即上述步骤得到的头部动作和手臂动作的实时位置数据;再将所述的实时位置数据进入全身位置数据测算单元303处理,输出预测的全身位置数据;最后优选使用u3d动画技术进行动画播放。
全身位置数据测算单元303的处理方式如下:
确定性的policy(deterministicpolicy):a=π(s)a=π(s)
随机性的policy(stochasticpolicy):π(a|s)=p[at=a|st=t]π(a|s)=p[at=a|st=t]
其中,tt是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合,st代表时刻t的状态,s代表其中某个特定的状态;
at∈a(st)at∈a(st),a(st)a(st)是在状态st下的actions的集合,at代表时刻t的行为,aa代表其中某个特定的行为。
奖励信号(arewardsignal)
reward就是一个标量值,是每个timestep中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用rr来表示。
值函数(valuefunction)
reward定义的是立即的收益,而valuefunction定义的是长期的收益,它可以看作是累计的reward,常用vv来表示。
环境模型(amodeloftheenvironment)参见图7所示,其中,t是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合;
at∈a(st),a(st)是在状态st下的actions的集合;
rt∈r∈r是数值型的reward
qπ(s,a)qπ(s,a)策略ππ的行动价值方法。
v*(s)v*(s)最优状态价值方法。
q*(s,a)q*(s,a)最优行动价值方法。
在网络传输过程中,实时位置数据由网络传输,当接收到位置同步信息时,首先进行数据包的解析,包括拆包和合包。数据包包括包头和包体,包头包含了本数据包的长度,通过读取长度确定该数据是否是一个完整的数据包。如果收到的信息长度大于从包头读取的数据包长度,则说明已经收到一条完整的数据包,读出该长度的数据包进行解析,否则继续接受下一条数据包,直到收到一条完整的数据包。
全身位置数据测算单元303避免了硬性编码带来的阈值选择问题(例如:头部转动多大角度才进行躯干转动),同时也避免了产生各种扭曲的非正常模型姿势,从而得到一个非常自然的模型姿势。
进一步考虑到实际因素,受限于focus的计算性能与操作者快速运动等情况,实时预测并设置整个模型位置信息是不现实的,会导致模型的位置信息延迟于操作者的实际位置。因此优选的,全身位置数据测算单元303对输出的整个模型的位置信息在时间上有超前的预测,即在全身位置数据测算单元303输入向量上增加一个时间维度进行训练和预测,进而得到超前操作者人物模型的全身位置数据。上述得到超前操作者人物模型的全身位置数据具体是在客户端启动时,服务器计算出每个客户端的ping值,当客户端a有移动的操作时,向服务器发送目标点p。服务器收到消息后向每个客户端广播,发送消息中包含时间差(由客户端a和接收消息的客户端的ping值求得),客户端收到移动的消息时,通过时间差求出该时间点客户端a应该所在的位置p0,然后定义一个点p1,该点在p0后p点前,然后计算出a到p1所需的剩余时间,使客户端中的a在该剩余时间中移动到p1点,然后按照a点原来的移动速度移动到p点。旋转角度的计算同理。
ping=(system.datetime.now.millisecond-oritime)*0.5f;
oritime表示服务器向客户端发送检测ping值消息时的服务器时间
timeinterval=pinga+pingb;
timeinterval表示从a开始移动到b接收到a移动的消息需要的时间
p0=timeinterval*movespeed;
p0表示在这段时间内a已经移动的距离
p1=(p-p0)/2+p0;//自定义
p1是自定义的一个点,表示a从开始移动到b端的a与实际a同步位置的距离
movespeedb=p1/timeinterval;
movespeedb表示b端的a移动到p1的速度。
实施例4、本实施例的实时智能体感同步的系统,参见图8所示,包括下列单元:头部动作数据获取单元401,手臂动作数据获取单元402,全身位置数据测算单元403,动画播放单元404,以及全景单元405。
头部动作数据获取单元401,用于获取操作者人物模型头部动作的实时位置数据。具体是focus传感器捕捉到操作者头部的位置实时移动详细信息,可以是6自由度转动信息,传入到focus上运行的u3dclient程序中,u3dclient程序根据这些信息调整当前人物模型的头部摄像头位置(可以是6自由度转动信息),同时设置人物模型的头部位置(可以是6自由度转动信息),由此做到了操作者与模型的头部动作同步。
手臂动作数据获取单元402,用于获取操作者人物模型手臂动作的实时位置数据。具体是focus手柄传感器的实时位置信息,可以是6自由度转动信息,传入到u3dclient程序中,u3dclient程序根据这些信息设置当前人物模型的手掌位置,借助于finalik的机制,手掌位置的变化会自动牵拉调整人物模型的整个手臂的姿势,并得到操作者人物模型手臂动作的实时位置数据。
全身位置数据测算单元403,用于接收所述的操作者人物模型头部动作和手臂动作的实时位置数据,并测算当前操作者人物模型的全身位置数据。
由于focus传感器只提供头部和手臂位置,不提供躯干,腿部等其他部位位置信息,不能通过focus传感器来同步人物模型的全身位置信息,因此发明人经过研究提出了全身位置数据测算单元403,其原理是结合头部动作同步技术和手臂动作同步技术,可以得到实时的头部和手臂运动向量信息,以当前头部和手臂的实时运动向量等作为基本输入,来智能预测输出当前整个模型的位置信息(躯干转动方向,角度,脚部是否跟随转动等)。
在具体实现中先获取focus传感器实时数据输入,即上述步骤得到的头部动作和手臂动作的实时位置数据;再将所述的实时位置数据进入全身位置数据测算单元403处理,输出预测的全身位置数据;最后优选使用u3d动画技术进行动画播放。
全身位置数据测算单元403的处理方式如下:
确定性的policy(deterministicpolicy):a=π(s)a=π(s)
随机性的policy(stochasticpolicy):π(a|s)=p[at=a|st=t]π(a|s)=p[at=a|st=t]
其中,tt是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合,st代表时刻t的状态,s代表其中某个特定的状态;
at∈a(st)at∈a(st),a(st)a(st)是在状态st下的actions的集合,at代表时刻t的行为,aa代表其中某个特定的行为。
奖励信号(arewardsignal)
reward就是一个标量值,是每个timestep中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用rr来表示。
值函数(valuefunction)
reward定义的是立即的收益,而valuefunction定义的是长期的收益,它可以看作是累计的reward,常用vv来表示。
环境模型(amodeloftheenvironment)参见图9所示,其中,t是时间点,t=0,1,2,3,......t=0,1,2,3,......
st∈s,s是环境状态的集合;
at∈a(st),a(st)是在状态st下的actions的集合;
rt∈r∈r是数值型的reward
qπ(s,a)qπ(s,a)策略ππ的行动价值方法。
v*(s)v*(s)最优状态价值方法。
q*(s,a)q*(s,a)最优行动价值方法。
在网络传输过程中,实时位置数据由网络传输,当接收到位置同步信息时,首先进行数据包的解析,包括拆包和合包。数据包包括包头和包体,包头包含了本数据包的长度,通过读取长度确定该数据是否是一个完整的数据包。如果收到的信息长度大于从包头读取的数据包长度,则说明已经收到一条完整的数据包,读出该长度的数据包进行解析,否则继续接受下一条数据包,直到收到一条完整的数据包。
全身位置数据测算单元403避免了硬性编码带来的阈值选择问题(例如:头部转动多大角度才进行躯干转动),同时也避免了产生各种扭曲的非正常模型姿势,从而得到一个非常自然的模型姿势。
进一步考虑到实际因素,受限于focus的计算性能与操作者快速运动等情况,实时预测并设置整个模型位置信息是不现实的,会导致模型的位置信息延迟于操作者的实际位置。因此优选的,全身位置数据测算单元403对输出的整个模型的位置信息在时间上有超前的预测,即在全身位置数据测算单元403输入向量上增加一个时间维度进行训练和预测,进而得到超前操作者人物模型的全身位置数据。上述得到超前操作者人物模型的全身位置数据具体是在客户端启动时,服务器计算出每个客户端的ping值,当客户端a有移动的操作时,向服务器发送目标点p。服务器收到消息后向每个客户端广播,发送消息中包含时间差(由客户端a和接收消息的客户端的ping值求得),客户端收到移动的消息时,通过时间差求出该时间点客户端a应该所在的位置p0,然后定义一个点p1,该点在p0后p点前,然后计算出a到p1所需的剩余时间,使客户端中的a在该剩余时间中移动到p1点,然后按照a点原来的移动速度移动到p点。旋转角度的计算同理。
ping=(system.datetime.now.millisecond-oritime)*0.5f;
oritime表示服务器向客户端发送检测ping值消息时的服务器时间
timeinterval=pinga+pingb;
timeinterval表示从a开始移动到b接收到a移动的消息需要的时间
p0=timeinterval*movespeed;
p0表示在这段时间内a已经移动的距离
p1=(p-p0)/2+p0;//自定义
p1是自定义的一个点,表示a从开始移动到b端的a与实际a同步位置的距离
movespeedb=p1/timeinterval;
movespeedb表示b端的a移动到p1的速度。
动画播放单元403,用于根据所述全身位置数据测算单元测算的全身位置数据,对操作者人物模型进行实施的动画播放。具体是根据全身位置数据得到操作者人物模型位置变化量,据此设置动画播放参数,动画状态机完成动画融合并实现对操作者人物模型实施的动画播放,具体结合u3d的动画状态融合树,动画遮罩技术实现模型的动画播放,当操作者转身时,根据全身位置数据测算单元的输出得到位置变化量大小,由此设置动画播放参数,动画状态机完成动画融合,人物过渡播放移动效果。
在animatorcontroller中添加一个空状态idel,然后设置动画片断为我们的待机动画。
然后再创建一个动画融合树waltorun:
双击融合树进入编辑状态,在右侧的inspector面板中的motion列表中添加两个元素,从上到下依次选择我们的行走动画和奔跑动画。
创建float类型动画参数run,将融合树的parameter参数设置为run:
最后,将待机状态idel使用translation连接到融合树,设置condition参数为rungreater0.1,反过来融合树到idel的连接condition设置为runless0.1。
遮罩层的基本原理是:能够透过该图层中的对象看到“被遮罩层”中的对象及其属性(包括它们的变形效果),但是遮罩层中的对象中的许多属性如渐变色、透明度、颜色和线条样式等却是被忽略的。比如,我们不能通过遮罩层的渐变色来实现被遮罩层的渐变色变化。要在场景中显示遮罩效果,可以锁定遮罩层和被遮罩层。可以用“actions”动作语句建立遮罩,但这种情况下只能有一个“被遮罩层”,同时,不能设置_alpha属性。不能用一个遮罩层试图遮蔽另一个遮罩层。遮罩可以应用在gif动画上。在制作过程中,遮罩层经常挡住下层的元件,影响视线,无法编辑,可以按下遮罩层时间轴面板的显示图层轮廓按钮,使之变成,使遮罩层只显示边框形状,在种情况下,你还可以拖动边框调整遮罩图形的外形和位置。在被遮罩层中不能放置动态文本。通过加入动作动画进行补偿,使得人物与模型动作同步变得非常真实与流畅,增强了用户vr体验。
动画播放单元403优选对操作者人物模型移动动画进行优化,具体包括:抛物线的产生使用了线段射线技术,即整条抛物线是由一系列线段连接成的。每条线段的终点是根据起点矢量在重力加速度的作用下计算出来的,公式为:(终点)pos=(起点)lastpos+forward+vector3.up*n*-gravity*0.1f;其中,pos表示终点,lastpos表示起点,forward表示正方向向量,vector3.up表示世界的上方向,n表示当前点的编号,gravity表示重力系数,f表示当前值是个float。抛物线与场景的交点定位借助了u3d的射线+碰撞器机制自动产生,交点的竖直投影点就是人物模型的目的地。线段射线技术算法可以快速定位目的地,而无需借助u3d自带重力系统的作用产生(重力系统作用于物体仿真产生抛物线需要时间),同时使用gl绘制该抛物线可以让操作者快速看见行动轨迹和目的地,为操作者提供了良好的用户体验。目的地确定后,u3d可以直接设置人物模型位置实现移动。这种瞬时移动的方式避免了连续移动时场景变化带来的眩晕感,进一步提升了用户体验。
全景单元405,用于加载全景视频或全景图片,并渲染在虚拟现实场景中。具体在vr场景中,整个vr场景是在一个球体内部,将加载的全景视频和全景图片渲染在vr场景环境球体内表面,而focus操作者的人物模型观察到的就是球体内表面上的全景视频和全景图片,由此达到身临其境的状态。使用u3d的videoplayer组件和movietexture组件可以对全景视频和全景图片进行加载,同时使用u3d的shader技术,修改3d网格渲染面,使球体内表面渲染材质,视频流和图片转换为材质贴到球体里面,完成vr内部全景视频和全景图片的播放与展示。
这里本发明的描述和应用都只是说明性和示意性的,并非是想要将本发明的范围限制在上述实施例中。这里所披露的实施例的变形和改变是完全可能的,对于那些本领域的普通技术人员来说,实施例的替换和等效的各种部件均是公知的。本领域技术人员还应该清楚的是,在不脱离本发明的精神或本质特征的情况下,本发明可以以其它形式、结构、布置、比例,以及用其它组件、材料和部件来实现,以及在不脱离本发明范围和精神的情况下,可以对这里所披露的实施例进行其它变形和改变。
- 还没有人留言评论。精彩留言会获得点赞!