一种基于机器学习的商品竞争关系分析方法与流程
本发明涉及数据分析技术领域,具体涉及一种基于机器学习的商品竞争关系分析方法,涉及机器学习knn算法应用、皮尔逊相关矩阵分析、数据可视化分析、数理统计等。
背景技术
随着电子商务的快速发展,商品营销行业人员迫切希望获得发现存在一定竞争关系的商品的能力。现存的相似度竞争判别方法一定程度上可以帮助客户发现存在竞争关系的商品,但是数据分析的结果往往不够准确,加上很多先验知识的误判和分析方法的缺陷,最后的结果往往并不适用于商品竞争关系发掘实用场景。
常用的竞争分析方法swot自形成以来,广泛应用于战略研究与竞争分析,成为战略管理和竞争情报的重要分析工具。分析直观、使用简单是它的重要优点。即使没有精确的数据支持和更专业化的分析工具,也可以得出有说服力的结论。但是,正是这种直观和简单,使得swot不可避免地带有精度不够的缺陷。例如swot分析采用定性方法,通过罗列strengths、weaknesses、opportunities、threats的各种表现,形成一种模糊的企业竞争地位描述。以此为依据作出的判断,不免带有一定程度的主观臆断。所以,在使用swot方法时要注意方法的局限性,在罗列作为判断依据的事实时,要尽量真实、客观、精确,并提供一定的定量数据弥补swot定性分析的不足,构造高层定性分析的基础。由于信息挖掘渠道和关注点往往带有主观性,数据分析人员会朝着预期潜意识判断去收集数据,所以分析结果往往不够准确。
在商品经济时代,同类商品之间激烈的竞争给企业带来了巨大压力,准确而快速的找到具有竞争关系的一对商品必然能够为行业产品的市场拓展和降低成本带来重要参考依据。在大数据场景下,研究人员往往面临海量的数据处理需求,分析结果往往不够客观准确,同时更无法保证传统分析方法的有效性。
目前各大公司在调查存在竞争关系的商品时通常采用实地调研的方式,通过相关营销部门和销售部门去市场取证,使用一些基本的图表统计方法。但是缺乏一套完整的理论支撑,且精准度不够高,分析结果往往带有很大的主观意识。
技术实现要素:
本发明要解决的技术问题是:本发明针对以上问题,提供一种基于机器学习的商品竞争关系分析方法,通过使用数据可视化分析、高斯建模、nearestneighbors机器学习算法、pearson矩阵等一些应用方法可以较好的将具有竞争关系的商品识别出来。
本发明所采用的技术方案为:
一种基于机器学习的商品竞争关系分析方法,所述方法通过商品属性量化商品的相似度,将原始的商品数据进行过滤,同时过滤掉存在异常的业务数据,从而达到系统分析的业务需求。
所述商品数据为商品在指定时间段内的业务数据,这部分数据是相对完整的可做进一步线性分析的。
所述商品数据的选取过程包括内容如下:
从至少一个候选商品数据对象中,获取与待分析商品数据对象最相似的至少一个周期的目标数据对象,包括:确定一个商品数据对象的目标分片和商品销量数据的时间段阈值选取。
所述商品相似度的量化方法为:将商品成对的属性值在二维图上进行展示对比。
所述商品相似度的量化方法为:将不同的商品设置为一个点,并使用散点图来进行可视化分析,更为直观有效。
所述商品相似度的量化采用核函数拟合建模,使用高斯核函数的方法来精确拟合数据属性值的分布,将相似度较高的同类商品聚集在同一个高斯分布,不同相似度的商品分别分布在不同的高斯核函数中,可得到不同类群的商品分类界,同类群商品的密度、颜色深浅可视化展示等度量策略。
所述商品属性为多种属性(多个属性以上达到高维度),数据商品相似度的量化采用安德烈曲线对比不同商品在不同属性上的差异。安德烈曲线能够将高维数据转化为有限傅里叶序列,最后用三角函数输出表示,通过曲线的密集系数判断不同商品之间的相似度。
在得到相似度较高的商品集之后,使用nearestneighbors机器学习算法做进一步的相似度计算。
所述相似度计算过程如下:
设置一个训练样本集,训练样本集中每个数据都存在标签,即我们知道训练样本集中每个数据与所属分类的对应关系;
输入没有标签的新数据后,将新的数据的每个特征与训练样本集中每个数据对应的特征进行比较,然后计算得出与新样本最相似的数据的分类标签。通常只选择样本数据集中前k个最相似的数据,把其中多数属于的分类标签作为新数据的分类标签。
所述方法通过使用nearestneighbors近邻法,通过计算两个商品之间的最小相似距离,精确的计算出与每个商品相似度最高的另一个商品,这样计算得出的商品为进一步的分析提供了重要基础。
两个商品之间的相似距离越小说明两个商品之间相似度越高。经过实际测验,两列商品对应的属性非常接近。
具有竞争关系的一对商品在投放市场之后,市场往往需要一段时间来接受,随着口碑的传播和广告效应的扩散,销量往往会逐渐升高,市场饱和之后具有竞争关系的一对商品在销量上往往会有特殊的表现。例如一个商品销量的快速增长可能会导致另一个商品销量的下降,一个商品在短期内表现疲软、销量停滞不前、增长乏力的同时,另一个商品开始逐步扩大市场销量也逐渐升高。具有这种表现的一对商品往往具有竞争关系。最后为了提高数据的可靠性,还需要对这些呈竞争性关系的商品做过滤。两种商品在市场上都占有一定的份额时,由于竞争的原因他们的销量有可能在一段时间内比较接近,所以有必要对这些数据进行再一步的筛选。最终我们得到了具有竞争关系的多个商品对。
本发明的有益效果为:
本发明通过使用可视化工具对这些实验中的商品销量进行线性对比,发现两个商品在一定时间段内表现出一定的竞争关系,为行业业务人员的工作开展提供了方便,为商品竞争调查取证提供了决策支撑,保证了数据的可靠性,同时又大大降低了产品营销人员和决策管理人员的数据调查工作量,为商品的未来规划提供了有力依据。
附图说明
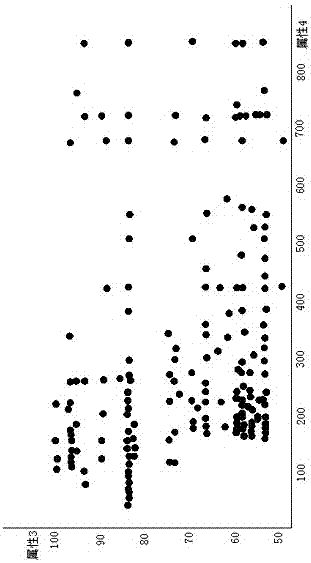
图1为不同商品在两个属性上的分布图。
具体实施方式
下面结合附图,根据具体实施方式对本发明进一步说明:
实施例1:
一种基于机器学习的商品竞争关系分析方法,所述方法通过商品属性量化商品的相似度,将原始的商品数据进行过滤,同时过滤掉存在异常的业务数据,从而达到系统分析的业务需求。
所述商品数据为商品在指定时间段内的业务数据,这部分数据是相对完整的可做进一步线性分析的。
所述商品数据的选取过程包括内容如下:
从至少一个候选商品数据对象中,获取与待分析商品数据对象最相似的至少一个周期的目标数据对象,包括:确定一个商品数据对象的目标分片和商品销量数据的时间段阈值选取。
实施例2
所述商品相似度的量化方法为:将商品成对的属性值在二维图上进行展示对比。
实施例3
如图1所示,所述商品相似度的量化方法为:将不同的商品设置为一个点,并使用散点图来进行可视化分析,更为直观有效。
图中每一个点代表一个商品,坐标轴分别代表商品的两个属性,集中在一起的商品点说明这些商品在属性3和属性4上表现接近,属于比较相似的商品。
实施例4
所述数据商品相似度的量化采用核函数拟合建模,使用高斯核函数的方法来精确拟合数据属性值的分布,将相似度较高的同类商品聚集在同一个高斯分布,不同相似度的商品分别分布在不同的高斯核函数中,可得到不同类群的商品分类界,同类群商品的密度、颜色深浅可视化展示等度量策略。
实施例5
所述商品属性为多种属性(多个属性以上达到高维度),数据商品相似度的量化采用安德烈曲线对比不同商品在不同属性上的差异。安德烈曲线能够将高维数据转化为有限傅里叶序列,最后用三角函数输出表示,通过曲线的密集系数判断不同商品之间的相似度。
实施例6
在得到相似度较高的商品集之后,使用nearestneighbors机器学习算法做进一步的相似度计算。
所述相似度计算过程如下:
设置一个训练样本集,训练样本集中每个数据都存在标签,即我们知道训练样本集中每个数据与所属分类的对应关系;
输入没有标签的新数据后,将新的数据的每个特征与训练样本集中每个数据对应的特征进行比较,然后计算得出与新样本最相似的数据的分类标签。通常只选择样本数据集中前k个最相似的数据,把其中多数属于的分类标签作为新数据的分类标签。
所述方法通过使用nearestneighbors近邻法,通过计算两个商品之间的最小相似距离,精确的计算出与每个商品相似度最高的另一个商品,这样计算得出的商品为进一步的分析提供了重要基础。
两个商品之间的相似距离越小说明两个商品之间相似度越高。经过实际测验,两列商品对应的属性非常接近。
实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!