基于深度卷积神经网络的细粒度图像分类方法与流程
本发明属于计算机视觉图像分类技术领域,具体涉及一种基于深度卷积神经网络的细粒度图像分类方法。
背景技术
细粒度图像分类任务相对通用图像分类任务的区别在于其图像所属类别的粒度更为精细,不同细粒度物体类的差异仅体现在细微之处。细粒度图像分类的主要挑战在于类间相似性和和类内多样性。一方面,不同的细粒度类之间的视觉差异仅仅体现在细微之处;另一方面,由于受到位置、视角、光照等条件的影响,即使是同一类的实例也可能会有变化较大的类内视觉差异。例如,californiagull和ringed-beakgull的差异仅仅在于鸟嘴部位的区别,但即使是同一类californiagull(或ringed-beakgull),也会表现出较大的类内差异性。
基于部分的算法细粒度图像分类方法,首先检测目标物体的不同部分,然后通过局部特征建模增加类间的区别、减小类内的差异,这类方法高度依赖精确的部件检测,容易受到遮挡、角度和姿态等影响。应用contractive和triplet损失函数训练深度卷积神经网络的方法,收敛速度较慢,计算复杂度高。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供了一种基于深度卷积神经网络的细粒度图像分类方法。
为达到上述目的,本发明采用如下技术方案:
基于深度卷积神经网络的细粒度图像分类方法,包括以下步骤:
1)准备细粒度图像分类数据集,将训练数据划分为训练数据集和验证数据集;
2)搭建细粒度图像分类的深度卷积神经网络模型,使用训练数据集训练模型,当训练的模型在验证数据集上达到设定的精度,保存网络模型参数;
3)使用训练好的模型计算测试图像分类的标签或测试数据集的分类精度。
本发明进一步的改进在于,步骤2)的具体实现方法如下:
201)搭建细粒度图像分类的深度卷积神经网络模型时,根据图像类标签层级结构特性,对通用图像分类深度卷积神经网络的结构和损失函数进行改进;
202)搭建细粒度图像分类的深度卷积神经网络模型时,在深度卷积神经网络的训练过程中,在网络的特征层使用large-margin损失函数进行监督。
本发明进一步的改进在于,步骤201)的具体实现方法如下:
2011)搭建细粒度图像分类的深度卷积神经网络模型时,在网络结构方面,用标签层数个全连接层替换通用图像分类神经网络的最后一个全连接层,网络特征层和各个全连接层两两之间有直接连接或者跨层连接;
2012)搭建细粒度图像分类的深度卷积神经网络模型时,在损失函数方面,对2011)中新增加的全连接层,使用级联softmax损失函数进行训练;
在细粒度图像分类的典型数据集中,类别标签通常根据它们的语义使用树形结构表示,其中叶节点和根节点分别对应细粒度级和粗粒度级标签;定义具有层次结构标签的图像数据集的数学符号如下:
定义级联的softmax损失函数如下:
其中
本发明进一步的改进在于,步骤202)中搭建细粒度图像分类的深度卷积神经网络模型时,深度卷积神经网络的训练过程中,在网络的特征层使用large-margin损失函数进行监督,其中large-margin损失函数的定义说明如下:
对于每个给定的细粒度类c,将剩下的细粒度类划分为两个组sp(c)和
其中,πc是属于类别c的训练样本的索引集,
其中,nc=|πc|,
对于细粒度类p和细粒度类q,设特征向量集
其中,
给定上述定义,glm损失函数的两个约束推导如下:
其中,α1和α2是两个预设的间隔,[x]+=max{x,0},且:
在上述公式中,sp(c)由与c共享同一父粗粒度类别的细粒度类组成,
使用上述定义,两级标签结构的glm损失定义为:
同样的,三级标签结构的glm损失推导如下:
首先,对于每个给定的细粒度类c,除了将其余的细粒度类划分为两个组sp(c)和
其中,α3是预定义的间隔,且
使用上述定义,三层标签结构的glm损失函数定义为:
其中,
同理,将glm损失函数扩展到一般的多层次结构标签的情况。
相对于现有技术,本发明具有如下的优点:
本发明提出的细粒度图像分类框架独立于并可应用于任何dcnn结构,具有很好的可移植性。具体的主要贡献有:本发明引入h个fc层来替换给定dcnn模型的顶层fc层,并用级联的softmax损失函数进行模型的训练,以更好地模拟细粒度图像类的h级分层标签结构。本发明提出广义大边缘(glm)损失,使给定的dcnn模型明确地探索分级标签结构和细粒度图像类的相似性规律。
本发明利用caffe开发平台在3个最流行的深度卷积神经网络(alexnet、googlenet和vgg-19)和3个学术界广泛利用的细粒度图像分类数据集(stanfordcar、cub-200-2011和fgvc-aircraft)上对本发明所提出的框架进行了充分的评估验证。stanfordcar数据集包含16185张图像,共196类;cub-200-2011数据集包含11788张图像,共200类;fgvc-aircraft数据集包含10000张图像,共100类。图5、6、7中的表格分别列出了性能比较结果,在这三个表还包含了当前一些最具代表性的方法的测试结果。从这三个表可以看出,本团队提出细粒度图像分类的深度卷积神经网络训练方法,无论在什么样的网络上都能显著提高分类精度,充分证明了本团队所提框架的有效性。
附图说明
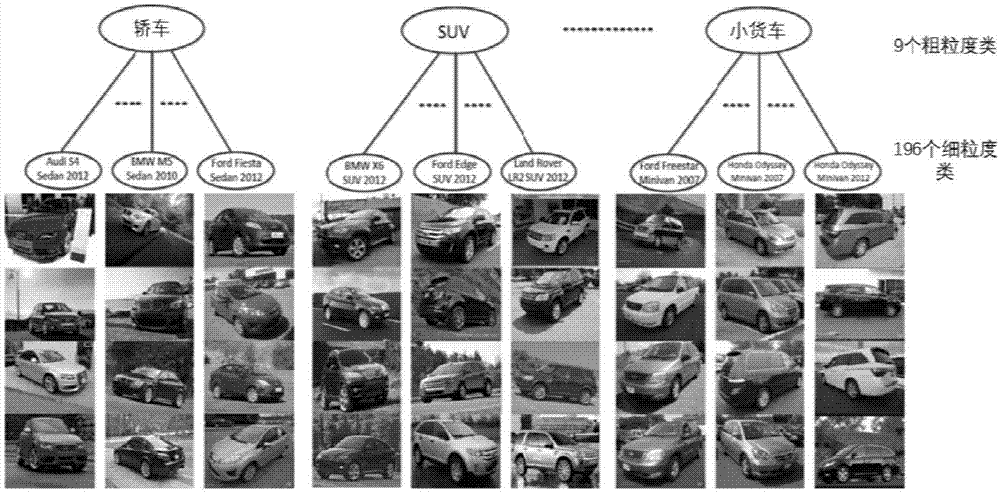
图1为stanfordcar数据集的样本图像,该数据集的类别标签具两层级关系。
图2为以改进alexnet为例的两层标签结构细粒度图像分类方法示意图。
图3为以改进alexnet为例的三层标签结构细粒度图像分类框架示意图。
图4为两层标签分层结构示意图。
图5为在stanfordcar数据集上的性能比较结果。
图6为在cub-200-2011数据集上的性能比较结果。
图7为在fgvc-aircraft数据集上的性能比较结果。
具体实施方式
鉴于细粒度图像分类的主要挑战(类间相似性和和类内多样性),本发明提出利用类标签层级结构关系、级联softmaxloss和泛化large-marginloss来改进深度卷积神经网络的细粒度图像分类性能。具体地,本发明从以下两个方面来改进深度卷积神经网络的细粒度图像分类精度。首先,对于一个给定的深度卷积神经网络,为了更好地利用细粒度类标签之间h-level的层级结构关系,本发明提出利用h个全连接层来替换神经网络的最后一个全连接层,这些新的全连接层的参数用本发明提出的级联softmaxloss来学习。其次,本发明提出了一个新的目标函数,即泛化的large-marginloss,以便充分利用细粒度类标签之间的层级结构关系和相似性关系信息来监督深度卷积神经网络的训练过程。在深度卷积神经网络所学到的特征空间中,泛化的large-marginloss不但能够减少类间相似性和类内变化,而且能够使得属于同一父类的子类之间的相似性大于那些属于不同父类的子类之间的相似性。本发明所提出的细粒度图像分类框架不依赖于任何的神经网络结构,可以应用于任何的深度卷积神经网络。
在细粒度图像分类的典型数据集中,类别标签通常根据它们的语义使用树形结构表示,其中叶节点和根节点分别对应细粒度级和粗粒度级标签。本发明定义具有层次结构标签的图像数据集的数学符号如下。
首先介绍级联softmax损失函数的定义。对于具有h层标签的细粒度图像分类问题,本发明通过用h个全连接层替换其原始顶层的全连接层来修改给定的dcnn模型,并且使用级联softmax损失函数对其进行训练。为了简化说明,并且不失一般性,本发明以使用alexnet对具有两层标签的图像数据集进行分类为例,其他基于深度卷积神经网络的细粒度图像分类问题以此类推。
原始的alexnet由五个卷积层(conv1-5)和三个完全连接层(fc6-8)组成,其中fc7,fc8分别作为特征输出层和顶层fc层。对具有两个层次标签的图像进行分类,本发明用fc8′和fc9替换fc8,并将fc9与fc7和fc8′完全连接。本发明将从fc7到fc9的连接称为跨层连接(如图2所示)。fc8′和fc9中的神经元数分别设为c(1)和c(2)。给定输入图像xi,fc8′和fc9输出所有叶细粒度类标签
本发明引入跨层连接(fc7→fc9)为粗粒度分类层(fc9)同时提供对输入图像xi学习的特征(fc7的输出)和对所有细粒度类别
对于上述改进的alexnet,本发明在训练过程中将级联的softmax损失函数应用于fc8′和fc9,其定义如下:
其中
改进的dcnn模型的整体目标函数定义如下:
其中
图2是改进alexnet的双层标签结构细粒度图像分类框架,这个框架可以推广到多层次的分层标签结构,并且是独立的任何dcnn结构。图3展示了改进alexnet的三层标签结构细粒度图像分类框架,为了简单起见,省略fc7之前的图层。与原始alexnet相比,本发明用fc8′,fc9和fc10替换fc8。fc9完全连接到fc7和fc8′,而fc10完全连接到fc7,fc8′和fc9。fc8′,fc9和fc10的输出维度分别等于底层细粒度类别的数量、第2层粗粒度类别的数量和第3层粗粒度类别的数量。
其次介绍glm损失函数的定义。为简单起见,本发明首先推导出两层标签结构的glm损失,然后将其推广到多层标签。对于每个给定的细粒度类c,本发明将剩下的细粒度类划分为两个组sp(c)和
细粒度类c的训练样本的特征向量集表示如下,
其中,πc是属于类别c的训练样本的索引集。
其中,nc=|πc|。
设特征向量
其中,
给定上述定义,glm损失函数的两个约束推导如下:
其中,α1和α2是两个预设的间隔,[x]+=max{x,0},且:
在上述公式中,sp(c)由与c共享同一父粗粒度类别的细粒度类组成,
使用上述定义,两级标签结构的glm损失可以定义为:
到目前为止,本发明主要讨论了两层结构标签的情况。事实上,glm损失函数可以很容易地扩展到一般的多层次结构标签,例如三级标签结构的glm损失可以推导如下。首先,对于每个给定的细粒度类c,除了将其余的细粒度类划分为两个组sp(c)和
其中,α3是预定义的间隔,且
使用上述定义,三层标签结构的glm损失函数可定义为:
其中,
本发明使用小批量的标准bp算法来训练改进的dcnn模型,总体目标函数如公式(2)所示。为优化模型,本发明需要计算损失函数l对于所有dcnn层响应的梯度,即相关层的误差流。softmax损失函数的梯度计算很简单,下面本发明详细说明glm损失函数对xi的梯度计算方法。
对于两级分层标签结构,
其中,i(·)为指示函数,当条件为真则等于1,否则为0。下标符号(:,i)表示矩阵的第i列,并且:
对于三层标签结构,
其中,
以8层alexnet模型为例,本发明提出的系统框架训练流程如下:
输入:训练集
输出:
步骤:
1、从
2、对每个样本执行前向传播,计算所有层的响应。
3、根据softmax损失计算fc9的误差流(对于粗粒度类别)。然后通过反向传播分别计算fc9到fc7和算fc8′的误差流。
4、根据softmax损失(对于细粒度类别)计算fc8′的误差流。
5、计算fc8′的总误差流,即从fc9和从softmax损失传递的误差流的总和(对于细粒度类别)。然后,用bp算法计算从fc8′到fc7的误差流。
6、根据方程式(19)和缩放因子λ计算从glm损失到fc7的误差流。
7、计算fc7的总误差流,即来自fc8′,fc9和glm损失的误差流总和。
8、从fc7到conv1执行反向传播,通过bp算法依次计算这些层的误差流。
9、根据各层的响应和误差流,用bp算法计算
10、通过梯度下降算法更新
11、iter←iter+1。若iter<imax,执行步骤1。
- 还没有人留言评论。精彩留言会获得点赞!