一种结合评分和项目相关性的协同过滤推荐方法与流程
本发明属于推荐学习技术领域,特别涉及了一种结合评分和项目相关性的协同过滤推荐方法。
背景技术
在推荐系统中,推荐算法是支撑着它运转的重要部分。目前,主要的推荐技术有基于内容的推荐、基于协同过滤的推荐、基于知识的推荐以及混合推荐等等。其中,协同过滤推荐算法由于其简单易于实现的特点,被广泛使用。协同过滤算法可以分为基于邻域的协同过滤算法和基于模型的协同过滤算法。基于邻域的协同过滤推荐算法包括基于用户的协同过滤推荐算法和基于项目的协同过滤算法。评分预测问题是推荐系统中一类重要的问题,研究者针对基于用户和项目的评分预测的协同过滤算法做了大量的相关工作,取得很大的进展。在基于近邻的协同过滤算法中,用户间和项目间的相似度计算是关键步骤,采用更加精确的相似度计算方法,就能找到更加有效的邻居集,进而进行更加精确的推荐。
基于评分预测的协同过滤是一类重要的应用问题,使用基于近邻的协同过滤算法进行预测评分主要分为三个步骤:1.数据收集;2.寻找近邻集;3.预测评分。可见在推荐过程中,相似度度量方法的选择是整个协同过滤推荐算法的核心,传统的协同过滤基于用户-项目评分矩阵来计算用户间或者项目间的相似性,但是用户的评分数据是非常有限的,导致传统的协同过滤算法面临着稀疏性问题,进而影响推荐质量。与此同时,系统中还存在着许多描述用户和项目属性特征的标签信息未被使用,把这些信息融入到传统推荐算法中,利用项目的属性标签挖掘出项目之间的相关性可以弥补相似度计算中的信息不足问题,是缓解数据稀疏性和冷启动问题的有效方法。
技术实现要素:
为了解决上述背景技术提出的技术问题,本发明旨在提供一种结合评分和项目相关性的协同过滤推荐方法,缓解数据稀疏性问题,提高推荐的准确性。
为了实现上述技术目的,本发明的技术方案为:
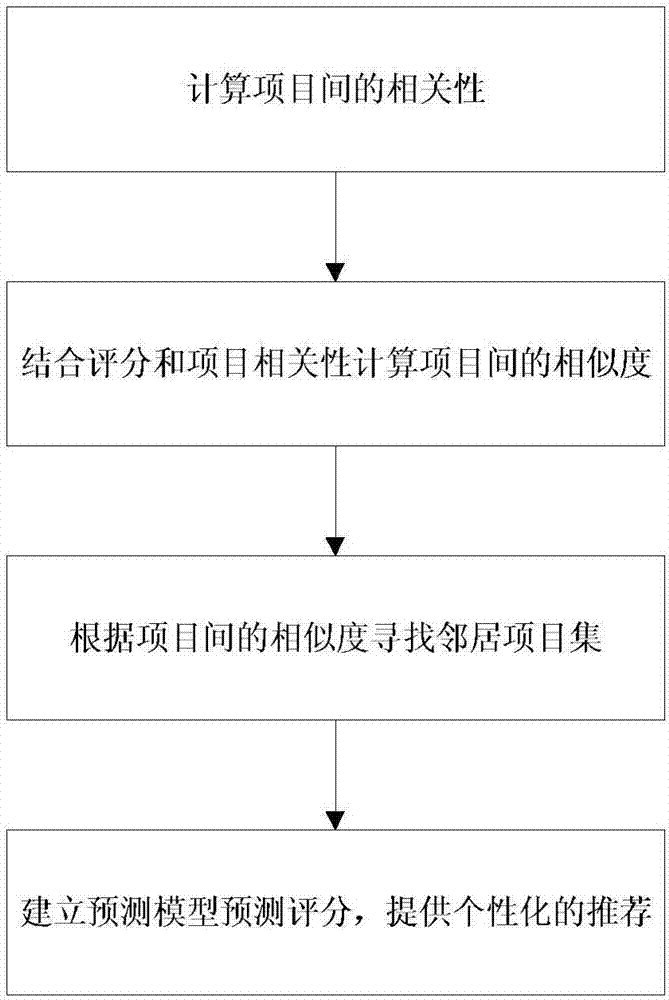
一种结合评分和项目相关性的协同过滤推荐方法,包括以下步骤:
(1)计算项目间的相关性;
(2)结合评分和项目相关性计算项目间的相似度;
(3)根据项目间的相似度寻找邻居项目集;
(4)建立预测模型预测评分,提供个性化的推荐。
进一步地,在步骤(1)中,项目间的相关性包括属性相关性和兴趣相关性;所述属性相关性定义如下:
其中,sim_attr(i,j)表示项目i与项目j间的属性相关性,attri和attrj分别表示项目i和项目j拥有的属性集合;
所述兴趣相关性定义如下:
其中,sim_interest(i,j)表示项目i与项目j间的兴趣相关性,其中ui表示评论过项目i的用户集合,uj表示评论过项目j的用户集合。
进一步地,在步骤(2)中,首先分别计算基于项目相关性的相似度以及基于评分的相似度,然后计算出结合评分和项目相关性计算项目间的相似度。
进一步地,在步骤(2)中,基于项目相关性的相似度计算式如下:
sim_attr_interest(i,j)=sim_attr(i,j)*sim_interest(i,j)
其中,sim_attr_interest(i,j)表示基于项目相关性的项目i与项目j间的相似度。
进一步地,在步骤(2)中,基于评分的相似度计算式如下:
其中,sim_rating(i,j)表示基于评分的项目i与项目j间的相似度,rui、ruj分别表示用户u对项目i的评分和用户u对项目j的评分,
进一步地,在步骤(2)中,结合评分和项目相关性的项目间的相似度计算式如下:
unified_sim(i,j)=r*sim_rating(i,j)+(1-r)*sim_attr_interest(i,j)
其中,unified_sim(i,j)表示结合评分和项目相关性的项目i与项目j间的相似度,r为比例参数。
进一步地,在步骤(3)中,对步骤(2)获得的项目间的相似度矩阵进行排序,得到topk个与活动项目最相似的邻居项目集合,记为n(i)。
进一步地,在步骤(4)中,采用如下预测模型预测评分:
其中,pui为预测的评分。
采用上述技术方案带来的有益效果:
本发明结合评分信息和项目相关性来计算相似度,缓解数据稀疏性问题,有效提高推荐的精确性。本发明提出的方法可以针对基于评分矩阵计算出的并不精确的相似度进行改良,进而提高推荐系统的推荐准确性。
附图说明
图1是本发明的整体流程图。
具体实施方式
以下将结合附图,对本发明的技术方案进行详细说明。
如图1所示,本发明提出的一种结合评分和项目相关性的协同过滤推荐方法,包括如下步骤:
步骤1,计算项目间的相关性;
步骤2,结合评分和项目相关性计算项目间的相似度;
步骤3,根据项目间的相似度寻找邻居项目集;
步骤4,建立预测模型预测评分,提供个性化的推荐。
首先定义项目相关性,项目相关性分为两个方面,一是属性相关性,而是兴趣相关性。
项目间属性相关性定义公式是:
其中,sim_attr(i,j)表示项目i与项目j间的属性相关性,attri和attrj分别表示项目i和项目j拥有的属性集合。
项目间兴趣相关性定义公式是:
其中,sim_interest(i,j)表示项目i与项目j间的兴趣相关性,其中ui表示评论过项目i的用户集合,uj表示评论过项目j的用户集合。
基于项目相关性的相似度计算公式是:
sim_attr_interest(i,j)=sim_attr(i,j)*sim_interest(i,j)
计算项目i和项目j之间的评分相似性如下:
其中,rui、ruj分别表示用户u对项目i的评分和用户u对项目j的评分,
结合评分和项目相关性的相似度计算公式如下:
unified_sim(i,j)=r*sim_rating(i,j)+(1-r)*sim_attr_interest(i,j)
其中,sim_rating(i,j)表示项目间的评分相似度,sim_attr_interest(i,j)表示基于项目相关性的项目相似度,二者的比例通过参数r来控制。
获得了项目间的相似度矩阵以后,我们可以得到topk个与活动项目最相似的邻居项目集合,分别记为n(i)。得到了邻居项目集合,接下来就可以对活动项目进行评分预测。
最终预测模型是:
实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!