基于加权低秩矩阵恢复模型的显著性目标检测方法与系统与流程
本发明涉及计算机图形图像处理技术领域,尤其涉及一种通过加权低秩矩阵恢复的显著性目标检测方法与系统。
背景技术
显著性目标检测是为了在自然场景中检测并分割出重要的区域,这在过去的一个半世纪里已经变成了一个十分受欢迎的话题。它对很多应用都是有帮助的,例如目标检测与识别、图像分类和恢复、目标协同分割,和基于内容的图像编辑等。
在过去的几十年中,已经提出了很多成功的显著性目标检测模型,这些模型大致可以分为两类:从顶向下的方法和从下而上的方法。自顶向下方法是基于用户的任务或目标,通常需要人工标记真值进行监督学习。自下而上的方法利用低级的图像属性,如颜色、渐变、边缘去构造显著图,而并不考虑用户的内部状态。
在自下而上的显著目标检测模型中,一组代表性的方法是基于低阶矩阵恢复(lrr)理论的。这主要是因为在大多数情况下,图像的背景通常位于低维子空间中,而通常偏离该子空间的突出区域可以被认为是稀疏的噪声或错误。
值得注意的是,lrr模型可以直接用于在场景的背景不混乱且具有高对比度的情况下,以确保底层低秩矩阵和稀疏矩阵之间没有高度的一致性。然而,在实际操作中,许多背景都是凌乱的,前景可能与背景有相似的外观。另外,前景有时占据了大部分图像,而这并不能满足稀疏的假设。在这些情况下,以前的基于lrr的方法很难从背景中提取突出的对象。
技术实现要素:
为了克服上述技术问题,本发明提出了一个背景优先级的低阶矩阵恢复模型(wlrr),用于突出对象检测。应用背景加权矩阵,让lr模型知道每个图像区域属于背景的可能性。在f.shang,y.liu,j.cheng,和h.cheng的论文“robustprincipalcomponentanalysiswithmissingdata”中就引入了一个类似的加权投影函数来从缺失和严重破坏的观测中恢复低阶和稀疏矩阵。
本发明解决其技术问题所采用的技术方案是:构造一种基于加权低秩矩阵恢复模型的图像显著性目标检测方法,包括以下步骤:
s1、对于给定的输入图像,运用超像素分割方法将它分割成n个不重叠的超像素区域p1、p2、...、pn;n为大于1的正整数;
s2、对于每一个超像素区域pi,提取出一个d维特征向量,表示为fi∈rd,然后通过集成所有的特征向量来获得图像特征矩阵f=[f1,f2,…fn]∈rd;其中,d为正整数;
s3、运用位置、颜色和边界连通性属性,将每个超像素区域pi的位置、颜色和边界连通性属性融合在一起生成一个高级背景先验图,然后将所有的高级背景先验图一起转换成为一个加权矩阵w;
s4、将图像特征矩阵f分解成一个代表冗余的背景信息的低阶矩阵l和一个代表显著部分的稀疏矩阵s,分解时的目标函数为
s5、将每个超像素区域的显著性值还原映射到超像素区域在所述输入图像中的位置并进行平滑处理,得到最终的显著图;其中,超像素pi的显著值为稀疏矩阵s的第i列的l1范数。
优选地,在本发明的图像显著性目标检测方法中,步骤s3中,对于任意超像素区域pi,生成高级背景先验图的具体步骤为:
s31、位置处理步骤:对于每一个超像素区域pi,计算它的平均位置与所述输入图像中心位置c的距离,表示为d(pi,c),然后得到超像素区域pi的位置先验值lp(i)=1-exp(-d(pi,c)/σ2),σ是控制高斯核函数宽度的标准偏差;
s32、颜色处理步骤:采用基于低秩矩阵恢复的显著目标检测方法获得超像素区域pi的颜色ci,然后得到相应的背景颜色先验值cp(i)=1-ci;
s33、边界连通性处理步骤:使用超像素区域pi和图像边界超像素之间的交集的长度来量化与图像边框的连接程度
s34、计算各个超像素区域pi的最终高级背景先验图:w(i)=lp(i)·cp(i)·bp(i),然后将计算出的w(i)组合成加权矩阵w:
优选地,在本发明的图像显著性目标检测方法中,步骤s4中分解特征矩阵f的具体步骤为:
s41、引入拉格朗日乘数y,将模型的解算器转移到最小化下面的增广拉格朗日函数κ:
再使用admm模型迭代执行步骤s42-s44,直至搜索到最优s、l和y,其中μ为一个正常数,||·||f表示f范;
s42、更新l:当s和y是固定的,在(k+1)次迭代中l(k+1)的解决方案通过求解下述公式的最优解得到:
s43、更新s:用固定的l和y更新s(k+1),通过下述公式求解s(k+1):
s44、更新y:采用下述公式更新得到yk+1:
根据本发明的另一方面,本发明为解决其技术问题,还提供了一种基于加权低秩矩阵恢复模型的图像显著性目标检测系统,包括以下模块:
超像素处理模块,用于对于给定的输入图像,运用超像素分割方法将它分割成n个不重叠的超像素区域p1、p2、...、pn;n为大于1的正整数;
特征矩阵处理模块,用于对于每一个超像素区域pi,提取出一个d维特征向量,表示为fi∈rd,然后通过集成所有的特征向量来获得图像特征矩阵f=[f1,f2,…fn]∈rd;其中,d为正整数;
加权矩阵处理模块,用于运用位置、颜色和边界连通性属性,将每个超像素区域pi的位置、颜色和边界连通性属性融合在一起生成一个高级背景先验图,然后将所有的高级背景先验图一起转换成为一个加权矩阵w;
特征矩阵处理模块,用于将图像特征矩阵f分解成一个l代表冗余的背景信息的低阶矩阵,以及一个代表了显著部分的稀疏矩阵s,分解时的目标函数为
最终结果处理模块,用于将每个超像素区域的显著性值还原映射到超像素区域在所述输入图像中的位置并进行平滑处理,得到最终的显著图;其中,超像素区域pi的显著值为稀疏矩阵s的第i列的l1范数。
优选地,在本发明的图像显著性目标检测系统中,加权矩阵处理模块中,对于任意超像素区域pi,采用以下子模块生成高级背景先验图:
位置处理步骤子模块,用于对于每一个超像素区域pi,计算它的平均位置与所述输入图像中心位置c的距离,表示为d(pi,c),然后得到超像素区域pi的位置先验值lp(i)=1-exp(-d(pi,c)/σ2),σ是控制高斯钟宽度的标准偏差;
颜色处理步骤子模块,用于采用基于低秩矩阵恢复的显著目标检测方法获得了超像素区域pi的颜色ci,然后得到相应的背景颜色先验值cp(i)=1-ci;
边界连通性处理子模块,用于使用超像素区域pi和图像边界超像素之间的交集的长度来量化与图像边框的连接程度
加权矩阵合成子模块,用于计算各个超像素区域pi的最终高级背景先验图:w(i)=lp(i)·cp(i)·bp(i),然后将计算出的w(i)组合成加权矩阵w:
优选地,在本发明的图像显著性目标检测系统中,特征矩阵处理模块采用如下子模块来分解特征矩阵f:
拉格朗日处理子模块,用于引入拉格朗日乘数y,将模型的解算器转移到最小化下面的增广拉格朗日函数κ:
再使用admm模型迭代调用步骤更新l子模块、更新s子模块、更新y子模块,直至搜索到最优s、l和y,其中μ为一个正常数,||·||f表示f范;
更新l子模块,用于当s和y是固定的,在(k+1)次迭代中l(k+1)的解决方案通过求解下述公式的最优解得到:
更新s子模块,用于用固定的l和y更新s(k+1),通过下述公式求解s(k+1):
更新y子模块,用于采用下述公式更新得到yk+1:
实施本发明的通过加权低秩矩阵恢复的显著性目标检测方法与系统,对于前景与背景的外观相似时,以及前景占据了大部分图像时均能很好地从背景中提取突出的对象。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
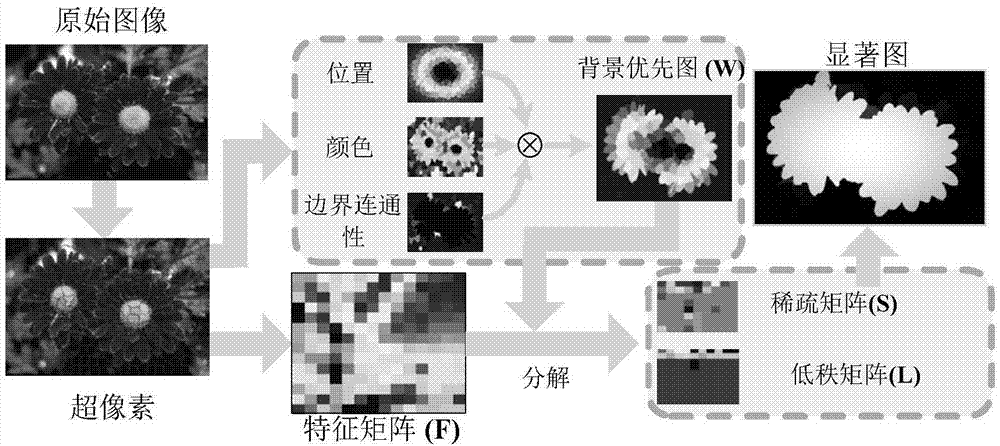
图1为本发明实施例提供的通过加权低秩矩阵恢复的显著性目标检测模型的流程图;
图2为使用admm的wlrr求解算法步骤原理图;
图3是本发明与一些最近提出的方法在不同数据集上的表现的直观比较图;
图4为wlrr与其他最近提出的方法在ecssd数据集上的pr曲线和f-measure曲线;
图5为wlrr与其他最近提出的方法在sod数据集上的pr曲线和f-measure曲线;
图6为wlrr与其他最近提出的方法在msra10k数据集上的pr曲线和f-measure曲线。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
参考图1,其为本发明实施例提供的通过加权低秩矩阵恢复的显著性目标检测模型的流程图。在本实施例的基于加权低秩矩阵恢复模型的图像显著性目标检测方法中,其包括以下步骤:
s1、对于给定的输入图像,运用超像素分割方法将它分割成n个不重叠的超像素区域p1、p2、...、pn;n为大于1的正整数。
s2、对于每一个超像素区域pi,提取出一个d维特征向量,表示为fi∈rd,然后通过集成所有的特征向量来获得图像特征矩阵f=[f1,f2,…fn]∈rd;其中,d为正整数。
s3、运用位置、颜色和边界连通性属性,将每个超像素区域pi的位置、颜色和边界连通性属性融合在一起生成一个高级背景先验图,然后将所有的高级背景先验图一起转换成为一个加权矩阵w。
对于任意超像素区域pi,生成高级背景先验图的具体步骤为:
s31、位置处理步骤:一般来说,靠近图像中心的物体对人更有吸引力。在离图像中心很远的物体上,有更大的可能性属于背景;对于每一个超像素区域pi,计算它的平均位置与输入图像中心位置c的距离,表示为d(pi,c),然后得到超像素区域pi的位置先验值lp(i)=1-exp(-d(pi,c)/σ2),σ是控制高斯钟宽度的标准偏差;
s32、颜色处理步骤:在我们的日常生活中,红色和黄色等暖色往往会更明显,这里直接使用x.shen和y.wu在2012年发表的“aunifiedapproachtosalientobjectdetectionvialowrankmatrixrecovery”一文中所提出的方法来获得背景颜色先验:采用基于低秩矩阵恢复的显著目标检测方法(即aunifiedapproachtosalientobjectdetectionvialowrankmatrixrecovery)获得了超像素区域pi的颜色ci,然后得到相应的背景颜色cp(i)=1-ci;
s33、边界连通性处理步骤:背景区域与图像边界连接的可能性非常高,而很少有显著区域连接到图像边界;这里使用超像素区域pi和图像边界超像素之间的交集的长度来量化与图像边框的连接程度
s34、在得到上述三个背景优先之后,超像素区域pi的最终背景可以通过w(i)=lp(i)·cp(i)·bp(i)。为了方便表示和计算,本发明把w(i)通过复制d
行组合得到权重矩阵w,然后将计算出的w(i)组合成加权矩阵w:
s4、将图像特征矩阵f分解成一个低阶矩阵l代表冗余的背景信息,以及一个稀疏矩阵s代表了显著部分。本发明提出了一种新的背景优先wlrr模型:
其中,||·||*表示矩阵的核范数,它是秩函数的凸松弛,被定义为矩阵奇异值的和,||·||1表示矩阵的l1范数,
本发明的wlrr模型通过将图像各区域属于背景的可能性考虑在内,扩展了经典的矩阵恢复模型,从而增强了l和s的低等级和稀疏性。当加权矩阵在特征矩阵f中分配更小的权重时,在恢复的稀疏矩阵s中对应向量的l1范数倾向于更小。因此,前景部分可以更有效地突出显示。
wlrr模型显然是一个凸优化问题,它可以通过倍增器(admm)的近交方向法有效地解决。参考图2,首先引入拉格朗日乘数y,然后模型的解算器可以被转移到最小化下面的增广拉格朗日函数:,
然后使用admm模型来交替轮流地搜索最优s、l和y,其中μ为一个正常数,||·||f表示f范。
admm模型由z.lin,r.liu,和z.sui在proc.adv.neuralinf.process.syst.24,2011,pp.612–620.发表的“linearizedalternatingdirectionmethodwithadaptivepenaltyforlow-rankrepresentation”提出。
更新l:当s和y是固定的,在(k+1)次迭代中l(k+1)的解决方案可以通过解决以下问题得到:
更新s:用固定的l和y更新s(k+1),得到了下面的最小化问题:
s(k+1)的解决方案有一个近似的形式:
这里,shrink(x,t)=sign(x)max(abs(x)-t,0)
更新y:
s5、将每个超像素的显著性值还原映射到超像素在所述输入图像中的位置并进行平滑处理,得到最终的显著图;其中,超像素区域pi的显著值为将s的第i列的l1范数。
图2中的算法1的主要计算成本是在使用线性化的admm方法时,在更新l的步骤中,d×n矩阵的奇异值分解(svd)。它的计算复杂度是ο(d2n+dn2+n3)。幸运的是,d和n在算法1中并不是非常大(具体来说,d=53,n≈200)。因此,本发明的算法也非常高效,它需要大约1.51s来计算在msra10k数据集上的分辨率为400×300的图像。
参考图4-6将本发明的方法与其他多种最近提出的显著性检测方法在三个公开的数据集上进行了比较。特别地,们使用msra10k数据集中只有一个突出对象的图像,sod数据集中有多个突出对象的图像,和ecssd数据集中具有复杂场景的图像。在本发明的实验中,本发明提取了与ulr模型相同的特征,并设置λ为0.6。
ulr模型由x.shen和y.wu在proc.ieeecomput.vis.patternrecognit.,2012,pp.853–860.论文“aunifiedapproachtosalientobjectdetectionvialowrankmatrixrecovery”中提出。
如图3所示,通过与一些先进技术方法的比较,说明了本模型的有效性。可以看出,我们的方法能够适应不同的场景,和具有复杂的前景和背景的图像处理。
在定量评价的基础上,本发明对两个通用的性能指标进行了比较:pr曲线和f-measure曲线。
f-measure曲线被定义为:
在msra10k数据集上,我们的方法的pr曲线几乎与最好的方法相同,而我们模型的f-measure曲线下的区域几乎是最好的。
在sod数据集上,本发明的方法在pr曲线上也有竞争力,值得注意的是,本发明的wlrr模型在rr曲线上比其他所有方法都要好,本发明模型的f-measure曲线下的面积也是最好的。
在ecssd数据集上,本发明的模型的pr比最好的方法稍微低一些,但是比其他所有的方法都要好。对于f-measure曲线下的面积,我们的模型也只比最好的方法要小一点点。这些结果验证了我们的wlrr模型能够很好地处理复杂场景的图像。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!