一种应用于红外火焰识别的TS-RBF模糊神经网络鲁棒融合算法的制作方法
本发明属于红外火焰识别技术领域,具体涉及一种应用于红外火焰识别的ts-rbf模糊神经网络鲁棒融合算法。
背景技术:
基于红外热释电传感器的火焰探测器广泛应用于现代工业碳氢化合物的火焰检测中,是工业生产系统自动运行的重要组成部分和必要的安全装置。碳氢类火焰和大多数非火焰干扰在红外光谱中具有固定的波长范围,因此可以用多种方法进行分析、识别。众所周知,在处理来自真实工业环境的传感器数据时,火焰识别变得更加复杂和困难,特别是使用多个传感器,每个传感器的工作波长都不相同。传统的多通道红外传感器信号处理方案中存在着一些普遍的困难。首先,在工业环境中安装红外探测系统时,通常很难对其进行正确配置,使其获得准确的采样数据,这可能导致数据丢失或信号饱和。此外,不同的传感器对火源和干扰源具有不同的敏感性,因此传感器信号很容易受随机运动、热空气流动、电弧焊接、热表面反射等非火焰的环境干扰,这可能会导致数据失真或信号饱和。最后,在信号采集和处理过程中,通常会出现设备老化使系统的性能下降,导致数据失真甚至数据丢失。
在过去的几十年里,已经开发出了一些方法,如相关性、周期性检查、取比值、频率分析和阈值交叉等方式,以检测和辨别火焰和非火焰干扰。然而,火焰与非火焰干扰的分离是一个非常复杂的检测过程,尤其是使用多个探测波长不同的传感器,很难在样本数据中通过经验提取和建立变量之间的内在隐含联系。这导致了火焰与非火焰干扰线性分离的困难。为了解决这一问题,提高识别率,采用非线性模式识别方法,如应用模糊神经网络,对不精确、不完整的数据进行分析。众所周知,模糊神经网络融合了模糊系统和神经网络这两种强大方法的优点,通过模糊规则为神经网络系统提供模型解释性,同时神经网络的训练方式也为模糊系统提供了有效的参数辨识方法。在现有的模糊建模方法中,ts模糊推理可以利用一系列模糊规则生成复杂的非线性关系,有效地解决了高维系统建模问题中时常发生的规则灾难。近年来,rbf神经网络融合ts模糊模型具有结构相对简单,较好的局部逼近能力、可解释性和函数等价性等优点。然而,针对二分类问题,如果使用多传感器构建新一代火灾探测系统,传统融合ts模型的rbf神经网络存在以下不足之处:
1.传统的ts-rbf模糊神经网络为了优良的局部逼近性能往往需要数量庞大的隐含层节点(模糊规则)数目。
2.在红外火焰探测的传统ts-rbf建模中,可能存在对于一些离散度较大且不满足高斯特性的特征也采取了高斯隶属度函数计算其隶属度,这显然不准确。
3.在rbf模糊神经网络中为了提升模型泛化能力加入去模糊化后,使得模型无法抑制离群点的输出,模型对于不确定性处理效果不佳,无法将离群点聚为一类。
4.在红外火焰探测中,非火焰探测通道采样数据由于硬件问题、系统老化、传输故障、强外界干扰等因素,发生数据丢失、数据失真、信号饱和时,因为部分特征变化剧烈,会引发整个模糊体系崩溃。
因此,本发明提供了一种应用于红外火焰识别的ts-rbf模糊神经网络鲁棒融合算法,能够使得系统在环境干扰、非火焰通道数据异常的情况下,依然能够有效地识别火焰。
技术实现要素:
本发明旨在提供一种应用于红外火焰识别的ts-rbf模糊神经网络鲁棒融合算法,通过定义新的加权激活度来计算相应模糊规则的模糊规则适应度,它充分考虑了不同特征对于不同聚类集合的代表程度不同,即对不同的特征在不同的模糊规则中采用不同的加权因子计算模糊规则适应度。根据不同特征在不同聚类结果中的相对离散度大小来确定不同的特征表示系数的初值,即加权激活度中的加权因子。并且,采取了在后件隐含层节点输出多项式中的每一项乘上相应特征分量的隶属度函数,可以有效抑制部分特征分量的异常值也可以补偿模型的非线性。
本发明的技术方案:
一种应用于红外火焰识别的ts-rbf模糊神经网络鲁棒融合算法,步骤如下:
步骤一、采集不同火焰和干扰源的时域信号数据,并对时域信号数据进行预处理,得到频域信号数据;
步骤二、对波形的时域、频域信号数据进行特征信息的提取,获得样本的特征向量,组成样本集;
步骤三、将样本集划分为训练集、验证集和测试集;
步骤四、搭建ts-rbf模糊神经网络;
步骤五、设定ts-rbf模糊神经网络参数初始值,利用训练集的样本对ts-rbf模糊神经网络进行训练;
步骤六、利用验证集对训练好的ts-rbf模糊神经网络进行验证及模型选择;
步骤七、将测试集输入选择好的ts-rbf模糊神经网络中,其结果作为对模型的最终评价。
进一步的,所述步骤一中的时域信号数据变为频域信号,预处理的步骤为:
(1)将采集到的时域信号减去基准电压,对采样信号加汉宁窗做周期性处理;
(2)用快速傅里叶变换(fft变换)提取步骤1处理后的信号的频谱信息。
进一步的,所述步骤二中提取的特征信息为:不同微米通道的电压峰值、两个微米通道的电压峰值之比、波形中的极值点、频域中不同频率段的能量大小之和、频域中具有最高能量的频率、频域中具有最高能量的频率的幅值。
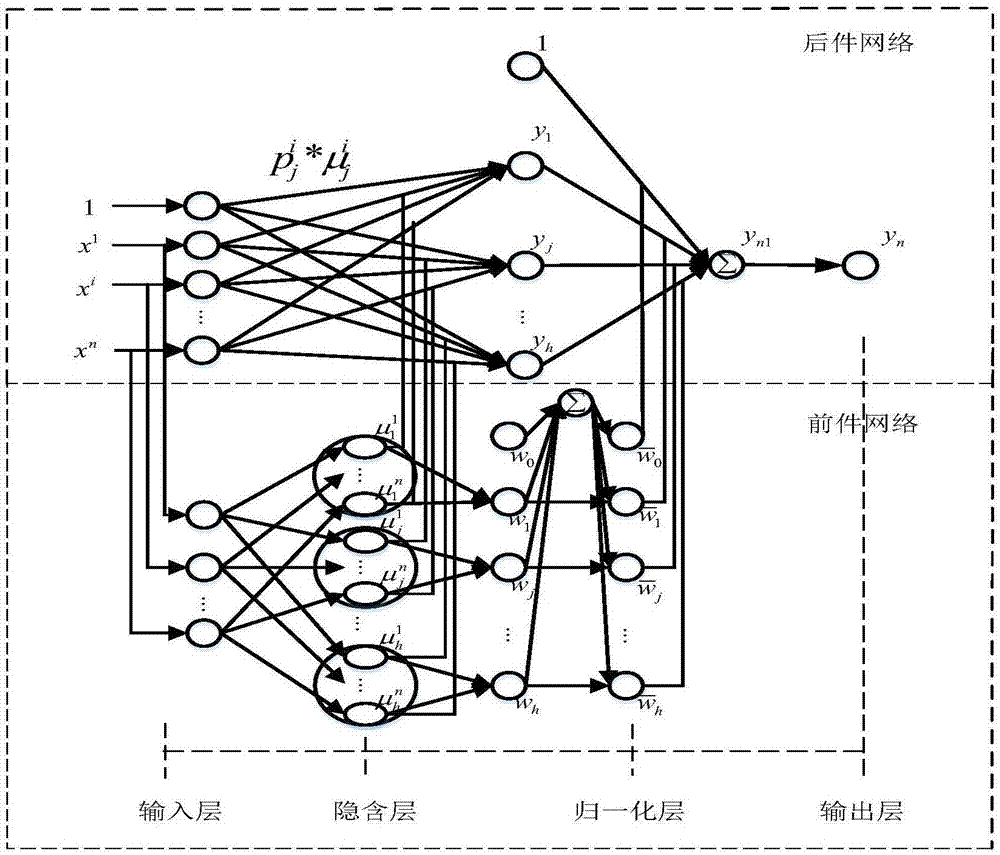
进一步的,所述步骤四搭建ts-rbf模糊神经网络时,ts模型和rbf神经网络融合的前提条件有以下三点:
a.rbf神经网络中归一化层采用的方法与ts模型中去模糊化的方式相同,且rbf神经网络计算隐含层节点输出的方式与模糊规则适应度的生成方式相同。
b.隐含层的节点数等于模糊规则的数目。
c.rbf神经网络中的高斯型激活函数对应和模糊系统中的隶属度函数相同。
基于上述条件,改进之后的ts-rbf模糊神经网络结构如附图1所示
搭建过程如下:
(1)构建ts-rbf模糊神经网络的前件网络
1)设输入层的输入向量为x=[x1x2…xn]t,其中n为输入特征的维数,xi表述样本中的第i维特征;
2)对ts-rbf神经网络的训练集利用k-means(欧式距离)进行聚类,得到h类模糊聚类集群,以确保隐含层具有h个节点,且每个节点具有n维高斯隶属度函数对应着n个模糊集;将第j类模糊聚类中心作为第j个隐含层节点的高斯隶属度函数的初始中心,如下所示
其中,
在前件网络的隐含层中,第j条模糊规则的模糊规则适应度wj把马氏距离作为评价尺度的方法改为如下:
其中,
所述第j类聚类样本的第i个特征所对应的
1.1)先将第j类聚类样本的特征归一化到[-1,1];
1.2)通过第j类聚类样本中包含的m个样本计算不同特征的标准差;
其中,
1.3)通过标准差
3)在归一化层中,采取重心法式(6)进行去模糊化,并且加入正数w0作为偏置,用于平衡方程和抑制离群点输出的情况;
其中,
(2)构建ts-rbf模糊神经网络的后件网络
1)将
2)在多传感器的红外火焰检测过程中,当某些特征分量发生数据丢失、失真或信号饱和时,后件网络中隐藏层节点的输出就会发生剧烈波动,导致模糊规则输出异常进而导致火焰识别检测失败,因此,在后件网络中,隐含层中的h条模糊规则对应h个节点,其中第j条模糊规则的输出yj通过如下修改的规则计算:
规则j:
其中,
输出层的输入yn1是
3)采用如下的双曲正切函数作为输出层的激活函数:
yn=tanh(yn1)(9)
训练过程为:
(1)对ts-rbf模糊神经网络参数初始化,包括
(2)利用自适应的梯度下降的学习方式,对建立的ts-rbf模糊神经网络进行训练;
1)设定代价函数如下:
其中,k=1,2,…,n,n是训练集样本的总数;yd(k)是样本标签值,yn(k)是网络的实际输出,e(k)=yd(k)-yn(k)是误差,λ是惩罚项系数;由于w0和
2)定义性能指标pi如下:
3)调整具体参数如下:
其中,α、β代表学习率和动量因子,h是模糊规则数,n是特征维数;学习率自适应调整取决于性能指标pi,具体如下:
(a)当pi(t+1)≥pi(t)时,那么
α(t+1)=hdα(t),β(t+1)=0.(17)
(b)当pi(t+1)<pi(t)并且
α(t+1)=hiα(t),β(t+1)=β0.(18)
(c)当pi(t+1)<pi(t)并且
α(t+1)=hiα(t),β(t+1)=β(t).(19)
其中,t是迭代次数,hd和hi分别是减少和增加因子;δ是基于均方根误差(rmse)的相对指标的阈值;因此,需要满足如下条件(20):
0<hd<1,hi>1.(20)
其中,
进一步的,所述步骤六、七中模型选择、最终评价如下:
训练得到的模型评价方式通过定义均方根误差为:
计算训练均方根误差时u=n,通过验证集进行模型选择时,u为验证集的样本数目,通过测试集对模型效果评价时,u为测试集的样本数目。
本发明的有益效果:
1.减少了模型所需要的模糊规则数量,同时可以较好解决特征存在的不确定性时模型泛化能力的不足。
2.通过引入w0以及在后件网络隐含层节点输出的多项式中的每一项乘上相应特征分量的隶属度,可以将离群点统一归为一类,抑制了离群点输出的不确定性。
3.模型的鲁棒性大大提高可以抵御在红外火焰探测中,非火焰探测通道采样数据发生数据丢失、数据失真、信号饱和的情况。
附图说明
图1为改进ts-rbf模糊神经网络结构示意图。
图2为三波段红外火焰探测器硬件结构图。
图3(a)为正庚烷燃烧的采样时域信号。
图3(b)为正庚烷燃烧的采样频域信号。
图3(c)为酒精灯燃烧的采样时域信号。
图3(d)为酒精灯燃烧的采样频域信号。
图4(a)为蜡烛燃烧的采样时域信号。
图4(b)为蜡烛燃烧的采样频域信号。
图4(c)为电烙铁的采样时域信号。
图4(d)为电烙铁的采样频域信号。
图5(a)为手机灯的采样时域信号。
图5(b)为手机灯的采样频域信号。
图5(c)为自然光的采样时域信号。
图5(d)为自然光的采样频域信号。
图6(a)为3.8通道数据丢失时正庚烷燃烧的采样时域信号。
图6(b)为3.8通道数据丢失时正庚烷燃烧的采样频域信号。
图6(c)为5.0通道数据丢失时正庚烷燃烧的采样时域信号。
图6(d)为5.0通道数据丢失时正庚烷燃烧的采样频域信号。
图7(a)为3.8通道数据失真时正庚烷燃烧的采样时域信号。
图7(b)为3.8通道数据失真时正庚烷燃烧的采样频域信号。
图7(c)为5.0通道数据失真时正庚烷燃烧的采样时域信号。
图7(d)为5.0通道数据失真时正庚烷燃烧的采样频域信号。
图8(a)为3.8通道信号饱和时正庚烷燃烧的采样时域信号。
图8(b)为3.8通道信号饱和时正庚烷燃烧的采样频域信号。
图8(c)为5.0通道信号饱和时正庚烷燃烧的采样时域信号。
图8(d)为5.0通道信号饱和时正庚烷燃烧的采样频域信号。
图9为模型训练的rmse。
图10为训练效果。
图11为验证效果。
图12为测试效果。
图13为3.8通道数据丢失测试效果。
图14为5.0通道数据丢失测试效果。
图15为3.8通道数据失真测试效果。
图16为5.0通道数据失真测试效果。
图17为3.8通道信号饱和测试效果。
图18为5.0通道信号饱和测试效果。
具体实施方式
以下根据附图和具体实施方式对本发明的技术方案进行进一步的陈述。
本例是在附图2所示的三波段火焰探测器的硬件基础上所做的实验,三个热释电红外传感器对不同波段的红外光具有不同的敏感因子。探测波段选定3.8微米(人工热源波段),4.3微米(火焰探测波段),5.0微米(背景辐射波段),三波段的半波带宽均为0.2微米。
火焰探测器的主要硬件结构包括:传感器模块、信号放大滤波模块、a/d采样模块、通信接口模块、电压参考模块、微处理器模块等,如附图2和表1所示。
表1探测器的硬件组成
实验采集的数据包括了不同火源和干扰源,具体有:正庚烷、蜡烛、酒精灯、电烙铁、手机灯等。正庚烷燃烧实验操作遵守国家标准gb15631–2008,燃烧箱尺寸约33厘米(长度)×33厘米(宽度)×5厘米(高度),距离25-60米。其他火源的火焰尺寸均为1厘米(宽度)×2厘米(高度),与干扰源一样距探测器约为0.5米。本实验的目的在于验证改进ts-rbf模糊神经网络是否能够有效的区分火源:正庚烷、蜡烛、酒精灯和人工热源干扰以及背景光源干扰。火源在水平面上的正、负偏转角均小于45度。实验数据是在144hz采样频率下采集的时域数据,根据火焰闪烁频率主要集中在3-25hz的规律,将时域数据通过fft变换(快速傅里叶变换)为对应的频域数据。
为了获得良好的火焰识别性能,在时域内对采样信号进行如下预处理:
(1)将4.3微米通道采集到的信号减去基准电压2v,之后每200点加一个汉宁窗做处理。
(2)用fft变换(快速傅里叶变换)提取(1)中得到的信号的频谱信息。
从不同的燃烧源和干扰源得到的实验数据如附图3-5所示,图中每个图都包含了时域采样的信号,以及在4.3微米通道上使用fft变换得到的相应的频域信号。
为了测试模型的鲁棒性,在3.8微米、5.0微米两个非火焰探测通道进行了数据丢失、数据失真、信号饱和的鲁棒性实验。附图6是传感器故障、通道数据传输问题引起的数据丢失,表现为波形在0v附近。附图7是非火焰探测通道多级放大器故障、单一非火焰探测传感器失灵引起的数据失真表现为单一通道信号在基准电压附近。附图8是电烙铁近距离和太阳强光直射干扰,表现为相应通道信号饱和。
为了从实验数据中提取特征信息,从波形的每200个采样数据中提取特征向量x=[x1x2…xn]t,其中包含12个特征,如表2所示,其中n=12。
表2特征向量中的特征分量
正常工作状态实验中得到571组样本,其中410组(210组正样本,200组负样本)作为训练集,61组(29组正样本,32组负样本)作为验证集,100组(50组正样本,50组负样本)作为测试集。
按技术方案训练之后模型具体参数如表3所示,模型正常工作状态实验效果如表4,附图9-12所示,可以看到模型在正常工作状态下能够有效地识别火焰和非火焰干扰,且识别率达到100%。模型鲁棒性实验效果如表5,附图13-18所示,可以看到模型在数据丢失、数据失真和信号饱和的情况下虽然略有波动,但总体上还是能够可靠地完成火焰和非火焰干扰的识别,模型拥有较高地鲁棒性。
表3模型参数
表4模型正常工作效果
表5模型鲁棒性实验效果
- 还没有人留言评论。精彩留言会获得点赞!