一种语法特征的匹配方法、装置、介质和计算设备与流程
本发明的实施方式涉及软件技术领域,更具体地,本发明的实施方式涉及一种语法特征的匹配方法、装置、介质和计算设备。
背景技术
本部分旨在为权利要求书中陈述的本发明的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
自然语言是指随文化自然演化而形成的语言,例如英语、汉语、日语、法语等。对于一门自然语言,语法特征包括语法结构、单词、短语以及固定搭配等,语言素材包括语言数据、文本数据、图像数据等。
目前,现有技术中通常会基于正则表达式(regularexpression)来实现为语言素材匹配语法特征。以语言素材“heisgoingtoplaybasketball”为例,采用基于正则表达式的技术方案对该语言素材进行匹配时能够为该语言素材匹配到具体单词和“am/are/isgoingto”这一固定搭配,但由于缺乏对自然语言的处理分析,这种技术方案无法进一步匹配到“dosth”(动词原形引导的动词词组)这一语法结构,致使这种技术方案无法匹配到该语言素材包括的语法结构“begoingtodosth”。此外,受限于正则表达式的匹配原理,这种技术方案还存在计算代价高,计算效率低等问题。
综上可知,现有基于正则表达式的技术方案存在自然语言处理性能差,计算代价高,计算效率低等问题,因此现有的基于正则表达式的技术方案无法实现对语法结构等语法特征的匹配。
技术实现要素:
本发明实施例提供一种语法特征的匹配方法、装置、介质和计算设备,用以解决现有基于正则表达式的技术方案存在自然语言处理性能差,计算代价高,计算效率低等问题。为此,非常需要一种语法特征的匹配方法、装置、介质和计算设备,用以实现对语法结构等语法特征的匹配。
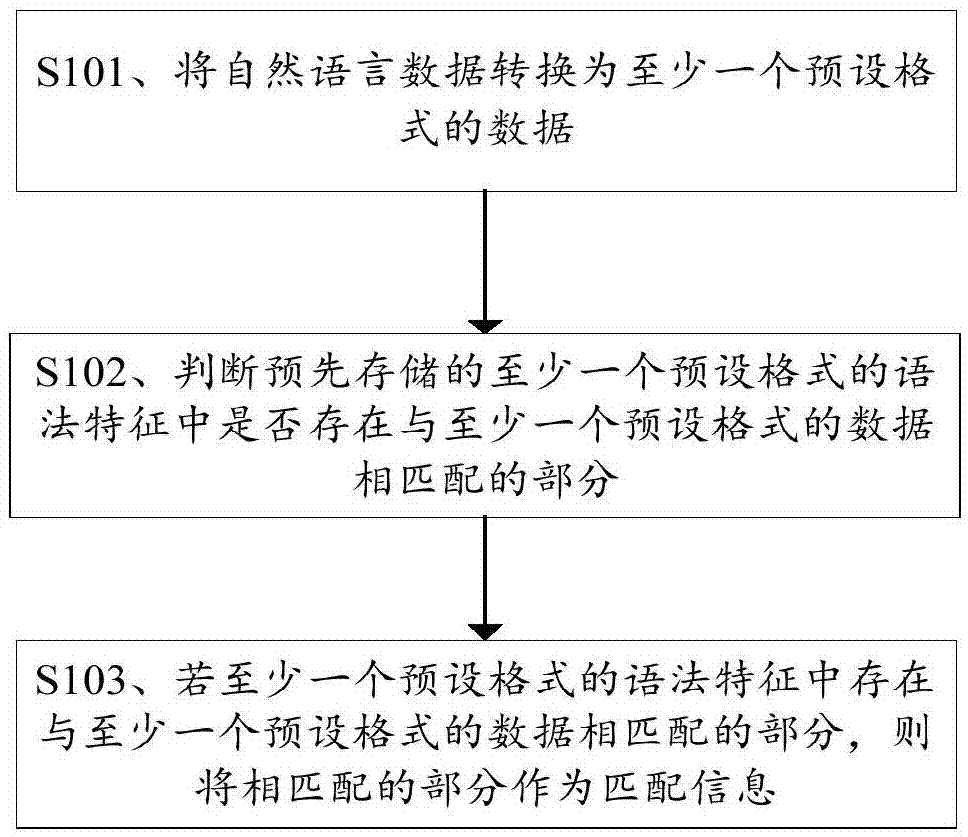
在本发明实施方式的第一方面中,提供了一种语法特征的匹配方法,包括:将自然语言数据转换为至少一个预设格式的数据,预设格式为用于描述自然语言的特征的编程语言格式;判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,至少一个预设格式的语法特征是对语法素材进行转换得到的,语法素材为承载有语法特征的样本数据;若至少一个预设格式的语法特征中存在与至少一个预设格式的数据相匹配的部分,则将相匹配的部分作为匹配信息,匹配信息用于指示自然语言数据具备的语法特征。
可选的,通过如下方法将语法素材转换为至少一个预设格式的语法特征,还包括:将语法素材描述为预设格式,得到至少一个预设格式的语法特征;或者将语法素材输入转换模型,通过转换模型识别语法素材中的语法特征,并将识别出的语法特征作为预设格式的至少一个预设格式的语法特征。
相应地,可选的,语法素材包括以下之一或组合:语法结构、固定搭配、词汇、短语。
可选的,将自然语言数据转换为至少一个预设格式的数据,包括:对自然语言数据进行nlp解析得到至少一个数据段,其中nlp解析包括语句切分、词汇切分、词性标注、语法解析、词汇变形识别中的之一或组合;将至少一个数据段转换为至少一个预设格式的数据。
可选的,对自然语言数据进行词汇变形识别得到至少一个数据段,包括:将自然语言数据分割为至少一个词汇;针对至少一个词汇,确定每一词汇在预先存储的词汇索引库中对应的索引,根据索引得到每一词汇的相关知识点;其中,相关知识点包括以下之一或组合:每一词汇的词性、每一词汇的词尾变化。
可选的,至少一个预设格式的语法特征构成树状结构。判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,包括:针对至少一个预设格式的数据中的每一数据,以树状结构的根节点为起始节点,在树状结构中对该数据进行遍历,判断树状结构中是否存在与该数据相匹配的节点。
可选的,判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,包括:若至少一个预设格式的语法特征包括短语,则采用动态规划的方式判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分。
可选的,在将相匹配的部分作为匹配信息之后,还包括:在自然语言数据中标记匹配信息,其中标记包括标题标记和/或高亮标记。
可选的,自然语言数据包括下列之一或组合:文本数据、语音数据、图像数据。
在本发明实施方式的第二方面中,提供了一种语法特征的匹配装置,包括:第一转换单元,用于将自然语言数据转换为至少一个预设格式的数据,预设格式为用于描述自然语言的特征的编程语言格式;判断单元,用于判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,至少一个预设格式的语法特征是对语法素材进行转换得到的,语法素材为承载有语法特征的样本数据;匹配单元,用于若至少一个预设格式的语法特征中存在与至少一个预设格式的数据相匹配的部分,则将相匹配的部分作为匹配信息,匹配信息用于指示自然语言数据具备的语法特征。
可选的,还包括第二转换单元用于:将语法素材描述为预设格式,得到至少一个预设格式的语法特征。或者,将语法素材输入转换模型,通过转换模型识别语法素材中的语法特征,并将识别出的语法特征作为预设格式的至少一个预设格式的语法特征。
其中,语法素材包括以下之一或组合:语法结构、固定搭配、词汇、短语。
可选的,第一转换单元具体用于:对自然语言数据进行nlp解析得到至少一个数据段,其中nlp解析包括语句切分、词汇切分、词性标注、语法解析、词汇变形识别中的之一或组合;将至少一个数据段转换为至少一个预设格式的数据。
可选的,第一转换单元在对自然语言数据进行词汇变形识别得到至少一个数据段时,具体用于:将自然语言数据分割为至少一个词汇;针对至少一个词汇,确定每一词汇在预先存储的词汇索引库中对应的索引,根据索引得到每一词汇的相关知识点。其中,相关知识点包括以下之一或组合:每一词汇的词性、每一词汇的词尾变化。
可选的,至少一个预设格式的语法特征构成树状结构。判断单元具体用于:针对至少一个预设格式的数据中的每一数据,以树状结构的根节点为起始节点,在树状结构中对该数据进行遍历,判断树状结构中是否存在与该数据相匹配的节点。
可选的,判断单元具体用于:若至少一个预设格式的语法特征包括短语,则采用动态规划的方式判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分。
可选的,还包括标记单元用于:在匹配单元将相匹配的部分作为匹配信息之后,在自然语言数据中标记匹配信息,其中标记包括标题标记和/或高亮标记。
可选的,自然语言数据包括下列之一或组合:文本数据、语音数据、图像数据。
在本发明实施方式的第三方面中,提供了一种介质,该介质存储有计算机可执行指令,计算机可执行指令用于使计算机执行第一方面中任一实施例的方法。
在本发明实施方式的第四方面中,提供了一种计算设备,包括处理器、存储器以及收发机;存储器,用于存储处理器执行的程序;处理器,用于根据存储器存储的程序,执行第一方面中任一实施例的方法;收发机,用于在处理器的控制下接收或发送数据。
在本发明实施方式的第五方面中,提供了另一种计算设备,包括处理单元以及收发单元。处理单元,用于执行第一方面中任一实施例的方法;收发单元,用于在处理单元的控制下接收或发送数据。
通过本发明实施例提供的技术方案,可以实现对语法结构等语法特征的匹配,从而有助于实现对自然语言数据中语法特征的大规模检测,提高了自然语言数据的处理效率,尤其是提高了对英语数据中语法特征的检测速度。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
图1示意性地示出了根据本发明实施例涉及的一种语法特征的匹配方法的流程示意图;
图2示意性地示出了根据本发明实施例涉及的一种英语文本中的语法特征的匹配方法的流程示意图;
图3示意性地示出了根据本发明实施例涉及的一种装置的结构示意图;
图4示意性地示出了根据本发明实施例涉及的一种介质的结构示意图;
图5示意性地示出了根据本发明实施例涉及的一种计算设备的结构示意图。
在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
下面将参考若干示例性实施方式来描述本发明的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本发明,而并非以任何方式限制本发明的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
本领域技术人员知道,本发明的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
发明概述
本发明人发现,目前现有基于正则表达式的技术方案存在自然语言处理性能差,计算代价高,计算效率低等问题,因此现有的基于正则表达式的技术方案无法实现对语法结构等语法特征的匹配。为了实现对语法结构等语法特征的匹配,本发明提供了一种语法特征的匹配方法、装置、介质和计算设备。通过本发明提供的技术方案,可以将自然语言数据转换为至少一个预设格式的数据,然后从预先存储的至少一个预设格式的语法特征中获取与至少一个预设格式的数据相匹配的部分作为匹配信息,从而可以通过匹配信息指示出自然语言数据具备的语法特征。
通过上述方案实现了对语法结构等语法特征的匹配,从而有助于实现对自然语言数据中语法特征的大规模检测,提高了自然语言数据的处理效率,尤其是提高了对英语数据中语法特征的检测速度。
在介绍了本发明的基本原理之后,下面具体介绍本发明的各种非限制性实施方式。
应用场景总览
本发明实施例可以应用于检测语法特征的场景,尤其是对自然语言数据中的语法特征进行检测的场景。此处自然语言包括但不限于英语,自然语言数据包括但不限于文本数据、语音数据、图像数据,语法特征包括但不限于语法结构、固定搭配、词汇、短语、词汇的词性、词汇的词尾变化。下面举例说明本发明实施例适用的几种场景:
场景一:对英语教学所采用的自然语言数据中的知识点进行检测/识别,尤其是针对数据量较大的自然语言数据,通过本发明实施例中的检测方法可以自动识别出这些数据量较大的自然语言数据中的知识点(即语法特征),从而这些知识点更清晰地呈现给用户,提高自然语言数据的处理速度,提升用户的学习效果(noticingeffect)。
场景二:识别出英语教学所采用的练习题中的知识点(即语法特征),尤其是针对数据量较大的练习题,通过本发明实施例中的检测方法可以自动识别出这些数据量较大的练习题中的知识点,从而能够通过这些知识点及其对应的题目的答题正确率来判断用户对这些知识点的掌握情况,这样有助于为用户规划更合理的学习方向,提升用户的学习效果。
场景三:通过本发明实施例中的检测方法识别出自然语言教学内容中的知识点以及教学大纲中的知识点,并进一步判断英语教学内容中的知识点是否教学大纲的要求,这样有助于校正英语教学内容,加速英语教学内容的编写速度。例如,可以将英语教学内容和教学大纲的数据格式转换为t-rex表达式(即预设格式),然后遍历英语教学内容来判断英语教学内容中的知识点出现的位置以及出现的频率是否符合教学大纲的要求。
需要注意的是,除了这三种场景之外,本发明实施例提供的技术方案还可以应用于其他场景,本发明实施例中并不限定。
示例性方法
参考图1来描述根据本发明示例性实施方式的匹配方法。需要注意的是,上述应用场景仅是为了便于理解本发明的精神和原理而示出,本发明的实施方式在此方面不受任何限制。相反,本发明的实施方式可以应用于适用的任何场景。
本发明实施例提供了一种语法特征的匹配方法,如图1所示,该方法包括:
s101:将自然语言数据转换为至少一个预设格式的数据,预设格式为用于描述自然语言的特征的编程语言格式。
s102:判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,至少一个预设格式的语法特征是对语法素材进行转换得到的,语法素材为承载有语法特征的样本数据。
s103:若至少一个预设格式的语法特征中存在与至少一个预设格式的数据相匹配的部分,则将相匹配的部分作为匹配信息,匹配信息用于指示自然语言数据具备的语法特征。
s102之前,将语法素材转换为至少一个预设格式的语法特征的方法有多种。例如以下几种方法:
方法一:将语法素材描述为预设格式,得到至少一个预设格式的语法特征。
方法二:将语法素材输入转换模型,通过转换模型识别语法素材中的语法特征,并将识别出的语法特征作为预设格式的至少一个预设格式的语法特征。
本发明实施例中,语法素材包括但不限于语法结构、固定搭配、词汇、短语,自然语言数据包括但不限于文本数据、语音数据、图像数据。
本发明实施例中涉及的预设格式可以为t-rex表达式。t-rex表达式是一种用于描述自然语言数据中的语法特征的编程语言,尤其是用于描述英语数据中的语法特征。以自然语言数据“am/is/are(not)goingtodosth”对应的t-rex表达式为:
通过这个t-rex表达式可以把上述自然语言数据转换为用于描述语法特征的编程语言,计算设备可以直接处理转换为t-rex表达式的自然语言数据。
s101中将自然语言数据转换为至少一个预设格式的数据的方法包括以下步骤:
步骤一:对自然语言数据进行nlp解析得到至少一个数据段。其中,nlp解析包括但不限于语句切分、词汇切分、词性标注、语法解析、词汇变形识别中的之一或组合。
以对自然语言数据进行词汇变形识别得到至少一个数据段为例,将自然语言数据分割为至少一个词汇;针对至少一个词汇,确定每一词汇在预先存储的词汇索引库中对应的索引,根据索引得到每一词汇的相关知识点。
本发明实施例中,每一词汇的相关知识点包括但不限于以下之一或组合:每一词汇的词性、每一词汇的词尾变化。
步骤二:将至少一个数据段转换为至少一个预设格式的数据。
s102中判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分的实现方式有多种。下面将会对其中的两种实现方式进行说明:
实现方式一:若至少一个预设格式的语法特征构成树状结构,则针对至少一个预设格式的数据中的每一数据,以树状结构的根节点为起始节点,在树状结构中对该数据进行遍历,判断树状结构中是否存在与该数据相匹配的节点。
实现方式二:若至少一个预设格式的语法特征包括短语,则采用动态规划的方式判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分。
可选的,实现方式二中采用动态规划的方式判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分的具体步骤可以为:
步骤1:将树状结构的语法解析模型抽象成有向无环图(acyclicgraph)。以自然语言数据是短语“iread”为例,将“iread”的语法解析模型包括如下语句:
将“iread”的语法解析模型抽象出的有向无环图包括如下语句:
np->vp
np->vb
np->read
prp->vp
prp->vb
prp->read
i->vp
i->vb
i->read
步骤2:基于动态规划的方式将上述语句例如“prp->read”、“i->vp”分别与预先存储的至少一个t-rex表达式的语法特征进行匹配,判断两者是否存在相匹配的部分。需说明的是,动态规划的方式与现有技术类似,此处不再赘述。
通过上述两个步骤实现短语匹配的复杂度最大值为o(mn),即复杂度最大值为t-rex表达式中的节点个数和语法解析模型中节点个数的乘积,其中m为语法特征表示长度,n为自然语言特征表示长度。而现有技术中采用穷举法实现短语匹配的复杂度为指数级的,因此通过本发明实施例提出的动态规划的方式实现短语匹配有助于降低短语匹配的复杂度,提高短语匹配的速度。
可选的,在将相匹配的部分作为匹配信息之后,在自然语言数据中标记匹配信息,其中标记包括标题标记和/或高亮标记。这样有助于及时帮助用户找到自然语言数据中的知识点,提升用户的学习体验,提高用户的学习效率。
例如,用户完成英语课程的学习之后,可以向用户展示一个包括本课程中的知识点总结的页面,该页面内含有本课程所涉及的每个知识点的标题以及该知识点对应的例句,此例句中的知识点也将会采用高亮的方式标记出来。标记例句中的知识点的过程如下:把例句经过标准nlp解析后得到的解析结果与采用t-rex表达式描述的语法特征进行匹配,如果解析结果与采用t-rex表达式描述的语法特征存在匹配部分,则将该匹配部分标记为高亮,并将该匹配部分对应的知识点作为该例句中的知识点标题。以例句“youarechristina”为例,通过上述过程可以将“are”标记为高亮,并将“are”对应的知识点“be动词的用法”作为该例句中的知识点标题。
举例说明一
如图2所示,假设自然语言数据为英语文本,语法素材包括英语语法点、词汇、固定搭配,英语文本中的语法特征的匹配方法包括以下步骤:
s201:将语法素材通过标注的方式描述为t-rex表达式得到多个t-rex表达式的语法特征,从而这多个t-rex表达式的语法特征构成t-rex规则。
s202:将英语文本转换为t-rex表达式的数据得到t-rex格式的文本。
s203:判断t-rex规则中是否存在与t-rex格式的文本相匹配的部分。
s204:若t-rex规则中存在与t-rex格式的文本相匹配的部分,则将该部分作为匹配信息,此处的匹配信息用于指示英语文本中的语法特征。
s205:将上述匹配信息通过图2所示的展示页面推送给用户。
通过这一方法,可以自动检测英语文本中的语法特征并将这些知识点推送给用户,从而更清晰地向用户展示英语文本中的语法特征,提高用户的学习效率。
举例说明二
假设自然语言数据为语音数据,语法素材包括英语语法点、词汇、固定搭配,则语音数据中的语法特征的匹配方法可以为:将语法素材通过人工标准描述为t-rex表达式得到多个t-rex表达式的语法特征,从而这多个t-rex表达式的语法特征形成t-rex规则。将语音数据描述为至少一个t-rex表达式的数据,判断t-rex规则中是否存在与至少一个t-rex表达式的数据相匹配的部分,然后若t-rex规则中存在与至少一个t-rex表达式的数据相匹配的部分,则将该部分作为匹配信息并将这些匹配信息通过展示页面推送给用户。其中,匹配信息用于指示语音材料中的重点单词的写法和意思。
通过举例说明二的方法,可以帮助用户理解语音材料中的重点单词的写法和意思,从而提高用户的学习效果。同时,也不需要消耗大量人力成本对各个单词进行标注和校对,这样有助于提升用户的学习效率和可扩展性。
通过本发明实施例提供的一种语法特征的匹配方法,可以实现对语法结构等语法特征的匹配,从而有助于实现对自然语言数据中语法特征的大规模检测,提高了自然语言数据的处理效率,尤其是提高了对英语数据中语法特征的检测速度。
示例性装置
在介绍了本发明示例性实施方式的方法之后,接下来,介绍本发明提供了示例性实施的装置。
参考图3,本发明提供了一种装置,该装置可以实现图2对应的对本发明示例性实施方式中的方法。参阅图3所示,该装置包括:
第一转换单元,用于将自然语言数据转换为至少一个预设格式的数据,预设格式为用于描述自然语言的特征的编程语言格式;
判断单元,用于判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分,至少一个预设格式的语法特征是对语法素材进行转换得到的,语法素材为承载有语法特征的样本数据;
匹配单元,用于若至少一个预设格式的语法特征中存在与至少一个预设格式的数据相匹配的部分,则将相匹配的部分作为匹配信息,匹配信息用于指示自然语言数据具备的语法特征。
可选的,还包括第二转换单元用于:将语法素材描述为预设格式,得到至少一个预设格式的语法特征。或者,将语法素材输入转换模型,通过转换模型识别语法素材中的语法特征,并将识别出的语法特征作为预设格式的至少一个预设格式的语法特征。
其中,语法素材包括以下之一或组合:语法结构、固定搭配、词汇、短语。
可选的,第一转换单元具体用于:对自然语言数据进行nlp解析得到至少一个数据段,其中nlp解析包括语句切分、词汇切分、词性标注、语法解析、词汇变形识别中的之一或组合;将至少一个数据段转换为至少一个预设格式的数据。
可选的,第一转换单元在对自然语言数据进行词汇变形识别得到至少一个数据段时,具体用于:将自然语言数据分割为至少一个词汇;针对至少一个词汇,确定每一词汇在预先存储的词汇索引库中对应的索引,根据索引得到每一词汇的相关知识点。其中,相关知识点包括以下之一或组合:每一词汇的词性、每一词汇的词尾变化。
可选的,至少一个预设格式的语法特征构成树状结构。判断单元具体用于:针对至少一个预设格式的数据中的每一数据,以树状结构的根节点为起始节点,在树状结构中对该数据进行遍历,判断树状结构中是否存在与该数据相匹配的节点。
可选的,判断单元具体用于:若至少一个预设格式的语法特征包括短语,则采用动态规划的方式判断预先存储的至少一个预设格式的语法特征中是否存在与至少一个预设格式的数据相匹配的部分。
可选的,还包括标记单元用于:在匹配单元将相匹配的部分作为匹配信息之后,在自然语言数据中标记匹配信息,其中标记包括标题标记和/或高亮标记。
可选的,自然语言数据包括下列之一或组合:文本数据、语音数据、图像数据。
示例性介质
在介绍了本发明示例性实施方式的方法和装置之后,接下来,参考图4,本发明提供了一种示例性介质,该介质存储有计算机可执行指令,该计算机可执行指令可用于使所述计算机执行图1对应的本发明示例性实施方式中任一项所述的方法。
示例性计算设备
在介绍了本发明示例性实施方式的方法、介质和装置之后,接下来,参考图5,介绍本发明提供的一种示例性计算设备,该设备包括处理器、存储器以及收发机,其中该存储器,用于存储处理器执行的程序;该处理器,用于根据该存储器存储的程序,执行图1对应的本发明示例性实施方式中任一项所述的方法;该收发机,用于在该处理器的控制下接收或发送数据。
应当注意,尽管在上文详细描述中提及了匹配装置的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
此外,尽管在附图中以特定顺序描述了本发明方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
虽然已经参考若干具体实施方式描述了本发明的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
- 还没有人留言评论。精彩留言会获得点赞!