一种基于深度学习的车标图像检测方法与流程
本发明涉及一种基于深度学习的车标图像检测方法,属于图像识别、图像检测技术领域。
背景技术
目前,传统的基于图像内容的车标图像检测方法,其图像特征主要是由人工方式手动提取,即主要以手工特征提取方式为主进行图像内容的检测,如:图像颜色直方图、局部二值模式、纹理特征等。即研究者根据自己的主观经验对图像进行特征提取与选择,再对提取出的图像特征进行预处理之后送进分类器,进行图像分类检测,检测结果易受人为主观经验的影响,可能会对检测结果带来误判;其次,基于图像内容的视觉特征编码固定,缺少学习能力,导致图像表达能力不强,检测结果容易受图像缩放、平移、旋转和光照的影响,鲁棒性不高;并且,图像的颜色、纹理等特征比较复杂,视觉维度较高,存在特征冗余的问题,导致图像检测效率不高,难以满足实时性要求。
技术实现要素:
本发明所要解决的技术问题是提供一种基于深度学习的车标图像检测方法,不仅能避免了传统手工特征提取方式因主观经验带来的误判,而且在复杂的自然环境背景下,依然具有较高的检测性能。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于深度学习的车标图像检测方法,通过卷积神经网络的训练,以及采用训练后的卷积神经网络实现图像中车标的检测;所述卷积神经网络包括多尺度特征融合层、三个全连接层、以及顺序串联的三组特征提取层,第一组特征提取层的输入端为卷积神经网络的输入端,各组特征提取层分别包括顺序串联的卷积层、下采样层,三组特征提取层分别与三个全连接层彼此一一对应,三组特征提取层的输出端分别对接对应全连接层的输入端,三个全连接层的输出端对接多尺度特征融合层的输入端,多尺度特征融合层的输出端作为卷积神经网络的输出端。
作为本发明的一种优选技术方案,采用如下步骤a1至步骤a3,获得样本图像集,用于所述卷积神经网络的训练;
步骤a1.获取预设数量包含车标的采集图像,然后进入步骤a2;
步骤a2.分别针对各幅采集图像,基于采集图像中真实车标目标区域图像,以该采集图像中正样本、负样本的预设数量比,获得该采集图像中的各个检测边框区域图像,作为各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签;进而获得所有采集图像所对应的所有样本图像,然后进入步骤a3;
步骤a3.针对所有样本图像进行归一化更新,构建样本图像集。
作为本发明的一种优选技术方案,所述步骤a2中,分别针对各幅采集图像,采用如下步骤a2-1至步骤a2-5,获得采集图像中的各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签;
步骤a2-1.针对采集图像,获得采集图像中真实车标目标区域图像,然后进入步骤a2-2;
步骤a2-2.针对该采集图像,按预设规则,构建一个预设比例尺寸的检测边框,并获得该检测边框区域图像,然后进入步骤a2-3;
步骤a2-3.针对当前循环所获的检测边框区域图像,按如下公式:
获得该检测边框区域图像相对真实车标目标区域图像的交并比iou,其中,soverlap表示该检测边框区域图像与真实车标目标区域图像相交区域的面积,sunion表示该检测边框区域图像与真实车标目标区域图像的并集面积,然后进入步骤a2-4;
步骤a2-4.将该检测边框区域图像作为样本图像,判断该样本图像所对应的交并比iou是否大于预设交并阈值,是则确定该样本图像对应正样本标签,否则确定该样本图像对应负样本标签,然后进入步骤a2-5;其中,预设交并阈值大于0.5;
步骤a2-5.判断该采集图像中正样本、负样本的数量比是否达到预设数量比,是则完成针对该采集图像的操作,获得该采集图像中的各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签;否则返回步骤a2-2。
作为本发明的一种优选技术方案,所述步骤a2-2包括如下步骤a2-2-1至步骤a2-2-2;
步骤a2-2-1.针对该采集图像,以正交交错方式进行网格划分,并获得各个网格的中心位置,然后进入步骤a2-2-2;
步骤a2-2-2.以网格的中心位置作为检测边框的顶点,构建分别对应预设长宽比例集合中各个不同长宽比例的检测边框,并获得该检测边框区域图像,然后进入步骤a2-3。
作为本发明的一种优选技术方案:所述预设交并阈值为0.75。
作为本发明的一种优选技术方案,所述采用训练后的卷积神经网络实现图像中车标的检测之后,还包括如下操作:
针对经卷积神经网络检测操作,所获得图像中的多个车标图像检测框,以及各车标图像检测框分别所对应的置信度,采用非极大值抑制法,针对该图像中的各车标图像检测框进行去冗余操作,更新该图像中的车标图像检测框,进而获得该图像中的各车标图像。
作为本发明的一种优选技术方案,所述采用训练后的卷积神经网络实现图像中车标的检测之后的操作,包括如下步骤步骤b1至步骤b3:
步骤b1.针对经卷积神经网络检测操作,所获得图像中的多个车标图像检测框,以及各车标图像检测框分别所对应的置信度,选择最高置信度所对应的车标图像检测框,作为真实车标目标区域图像,并进入步骤b2;
步骤b2.将除最高置信度所对应车标图像检测框以外的各个车标图像检测框,分别作为检测边框区域图像,按步骤a2-3的操作,获得其余各车标图像检测框分别所对应的交并比,然后进入步骤b3;
步骤b3.分别针对其余各车标图像检测框,判断车标图像检测框所对应的交并比是否大于预设阈值,是则判定该车标图像检测框内的车标图像、与最高置信度所对应车标图像检测框内的车标图像为同一车标目标,将该车标图像检测框删除;否则判定该车标图像检测框内的车标图像、与最高置信度所对应车标图像检测框内的车标图像为不同车标目标,不做处理;如此,针对该图像中的各车标图像检测框进行去冗余操作,更新该图像中的车标图像检测框,进而获得该图像中的各车标图像。
本发明所述一种基于深度学习的车标图像检测方法采用以上技术方案与现有技术相比,具有以下技术效果:
本发明所设计基于深度学习的车标图像检测方法,应用端到端的检测识别结构,避免了传统手工特征提取方式特征方式主观性强、特征提取效率低、特征冗余等问题;而且应用以卷积神经网络为基础的图像检测网络结构,卷积神经网络本身具有自学能力,网络根据图像输入和输出label自学图像特征来提高检测准确率,其对图像的旋转、平移、缩放等均具有良好的鲁棒性,在复杂的自然环境背景下依然具有较高性能。
附图说明
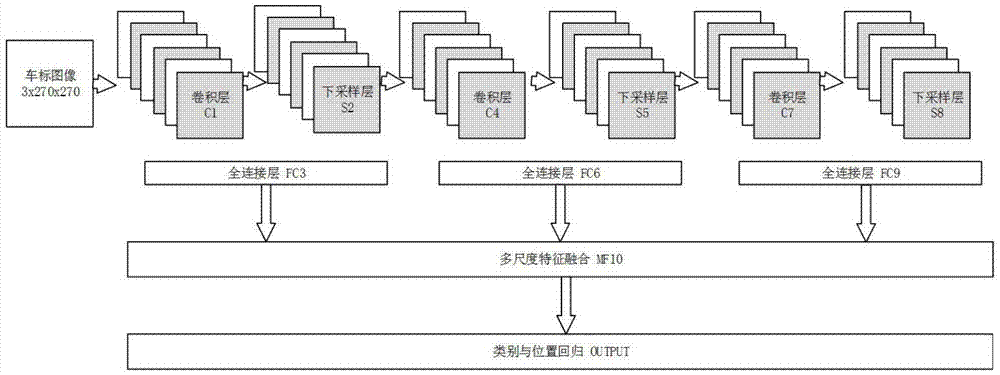
图1为本发明所设计基于深度学习的车标图像检测方法中卷积神经网络的架构示意图;图2表示针对经卷积神经网络所获的车标图像检测框进行位置回归示意图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
本发明所设计一种基于深度学习的车标图像检测方法,实际应用过程当中,通过卷积神经网络的训练,以及采用训练后的卷积神经网络实现图像中车标的检测。
对于卷积神经网络特征图,不同层次的特征图意味着不同大小的感受野,网络越深,其特征图对应的原图中的感受野越大,提取到的特征信息也会不一样。浅层网络中的特征图由于其感受野较小,对应着原图中局部信息;深层特征图由于其感受野变大,越接近图像的全局信息。传统的网络结构中,往往只使用最后一层网络中提取到的全局图像信息,即深层网络特征对图像进行识别分类,而忽略了图像的局部特征。本发明为了提高车标图像的检测效果,综合考虑图像全局信息与局部信息,提出了一种多尺度特征融合的方法,即针对卷积神经网络进行设计,将网络中的浅层、中层和深层特征进行融合。如图1所示,具体包括多尺度特征融合层、三个全连接层、以及顺序串联的三组特征提取层,第一组特征提取层的输入端为卷积神经网络的输入端,各组特征提取层分别包括顺序串联的卷积层、下采样层,三组特征提取层分别与三个全连接层彼此一一对应,三组特征提取层的输出端分别对接对应全连接层的输入端,三个全连接层的输出端对接多尺度特征融合层的输入端,多尺度特征融合层的输出端作为卷积神经网络的输出端。
即如图1所示,分别在s2、s5和s8之后连接全连接层fc3、fc6和fc9,分别对应着网络的浅层、中层和深层图像特征,待三个全连接层特征提取完毕之后,再将这三者连接融合,得到一个大的特征图,包括图像的局部特征和全局特征。将该特征输入最终的回归计算层,得到物体的类别信息和位置信息,完成检测。
实际应用中,上述所设计卷积神经网络中,卷积层均采用3x3卷积核,步长stride为1,特征图边补充边缘pad为0,下采样层采用2x2最大值下采样,步长为2。
上述多尺度特征融合是指,在基础网络之后连接的三层多尺度特征层。在预测阶段,融合三种不同尺度的特征层的预测结果,实现相同物体在不同尺度下的检测。该部分的实现关键点在于boundingregion(检测边框区域)的设计,其设计的好坏直接关系到训练样本中正负样本的分布,即用于获得针对设计卷积神经网络进行训练的样本图像集,以使网络能够较快的收敛,且达到较好的检测效果。
因此,针对所设计卷积神经网络的训练操作,采用如下步骤a1至步骤a3,获得样本图像集,用于所述卷积神经网络的训练。
步骤a1.获取预设数量包含车标的采集图像,任何进入步骤a2。
步骤a2.分别针对各幅采集图像,基于采集图像中真实车标目标区域图像,以该采集图像中正样本、负样本的预设数量比,获得该采集图像中的各个检测边框区域图像,作为各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签;进而获得所有采集图像所对应的所有样本图像,然后进入步骤a3。
其中针对上述步骤a2中,分别针对各幅采集图像,具体采用如下步骤a2-1至步骤a2-5,获得采集图像中的各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签。
步骤a2-1.针对采集图像,获得采集图像中真实车标目标区域图像,然后进入步骤a2-2。
步骤a2-2.针对该采集图像,按预设规则,构建一个预设比例尺寸的检测边框,并获得该检测边框区域图像,然后进入步骤a2-3。
对于这里的步骤a2-2,具体应用执行如下步骤a2-2-1至步骤a2-2-2。
步骤a2-2-1.针对该采集图像,以正交交错方式进行网格划分,并获得各个网格的中心位置,然后进入步骤a2-2-2。
步骤a2-2-2.以网格的中心位置作为检测边框的顶点,构建分别对应预设长宽比例集合中各个不同长宽比例的检测边框,并获得该检测边框区域图像,然后进入步骤a2-3。
步骤a2-3.针对当前循环所获的检测边框区域图像,按如下公式:
获得该检测边框区域图像相对真实车标目标区域图像的交并比iou,其中,soverlap表示该检测边框区域图像与真实车标目标区域图像相交区域的面积,sunion表示该检测边框区域图像与真实车标目标区域图像的并集面积,然后进入步骤a2-4。
步骤a2-4.将该检测边框区域图像作为样本图像,判断该样本图像所对应的交并比iou是否大于预设交并阈值,是则确定该样本图像对应正样本标签,否则确定该样本图像对应负样本标签,然后进入步骤a2-5;其中,预设交并阈值大于0.5,
实际应用当中,考虑到大部分车标图像中的车标图案本身的有效检测面积占比不大,并且很多国家车标图案部分相似度很高,如果所述预设交并阈值设的过低,很可能导致将某些正样本识别为负样本,或者出现多种车标混淆的情况。因此,本发明在交并阈值设计上对原始网络进行改进,将阈值提高到0.75,实际使用效果表明,提高阈值后的车标检测效果明显高于阈值低的检测效果,即判断该样本图像所对应的交并比iou是否大于0.75。
步骤a2-5.判断该采集图像中正样本、负样本的数量比是否达到预设数量比,是则完成针对该采集图像的操作,获得该采集图像中的各个样本图像,并确定各样本图像分别所对应的正样本标签或负样本标签;否则返回步骤a2-2。
步骤a3.针对所有样本图像进行归一化更新,构建样本图像集。这里的归一化更新,主要是对待检测图像进行尺度的归一化操作,使图像在输入网络之前归一化至相同尺寸,保证最终输出的特征维度相一致,通常使用邻域插值方法实现图像归一化。本发明为同时保证模型的准确率和实时性,将图像归一尺寸设为270x270。实际检测环境中,根据不同的车标检测任务和目标,归一化尺寸可以被设计为任意大小。将准确率作为最终的检测目标而不考虑实时性,可将归一化尺寸设计得大一些,如:500x500;反之,将实时性最为最终的检测目标,则可将归一化尺寸设计得小一些,如:180x180。
在完成样本图像集的构建后,即可针对所设计卷积神经网络进行训练,为防止模型过拟合,训练过程中在网络中引入稀疏编码机制,即让部分神经元在训练过程中处于非激活状态,只有部分神经元才处于激活状态,通过这样的设计,使特征层的部分神经元不参与网络学习,在不影响检测精度基础上,减少模型训练参数,同时,在一定程度上对抗过拟合。模型训练时使用sgd优化方法,初始速率0.001,权值衰减0.0005,冲量设置0.9,迭代次数200000,每隔2000迭代保存一次模型。
然后采用训练后的卷积神经网络实现图像中车标的检测,本发明的设计中,涉及到的回归计算包括类别回归与位置回归两部分。类别回归即通过训练后的卷积神经网络对检测出来的车标进行分类,而位置回归则是对检测结果所获车标图像检测框做进一步的修正,提高检测框和车标图像的匹配度;如此通过类别回归和位置回归便最终实现图像中的车标图像的检测。
对于位置回归,即在采用训练后卷积神经网络实现图像中车标的检测之后,执行如下操作,如图2所示,针对所获车标图像检测框,进行位置回归,进而获得该图像中的各车标图像。
针对经卷积神经网络检测操作,所获得图像中的多个车标图像检测框,以及各车标图像检测框分别所对应的置信度,采用非极大值抑制法,针对该图像中的各车标图像检测框进行去冗余操作,更新该图像中的车标图像检测框,进而获得该图像中的各车标图像。
上述针对所获车标图像检测框的位置回归操作,实际应用中,具体包括执行如下步骤步骤b1至步骤b3。
步骤b1.针对经卷积神经网络检测操作,所获得图像中的多个车标图像检测框,以及各车标图像检测框分别所对应的置信度,选择最高置信度所对应的车标图像检测框,作为真实车标目标区域图像,并进入步骤b2。
步骤b2.将除最高置信度所对应车标图像检测框以外的各个车标图像检测框,分别作为检测边框区域图像,按步骤a2-3的操作,获得其余各车标图像检测框分别所对应的交并比,然后进入步骤b3。
步骤b3.分别针对其余各车标图像检测框,判断车标图像检测框所对应的交并比是否大于预设阈值,是则判定该车标图像检测框内的车标图像、与最高置信度所对应车标图像检测框内的车标图像为同一车标目标,将该车标图像检测框删除;否则判定该车标图像检测框内的车标图像、与最高置信度所对应车标图像检测框内的车标图像为不同车标目标,不做处理;如此,针对该图像中的各车标图像检测框进行去冗余操作,更新该图像中的车标图像检测框,进而获得该图像中的各车标图像。
上述技术方案所设计基于深度学习的车标图像检测方法,应用端到端的检测识别结构,避免了传统手工特征提取方式特征方式主观性强、特征提取效率低、特征冗余等问题;而且应用以卷积神经网络为基础的图像检测网络结构,卷积神经网络本身具有自学能力,网络根据图像输入和输出label自学图像特征来提高检测准确率,其对图像的旋转、平移、缩放等均具有良好的鲁棒性,在复杂的自然环境背景下依然具有较高性能。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!