一种语句自动排序方法及装置与流程
本发明涉及计算机技术领域,具体的,涉及一种语句自动排序方法及装置。
背景技术
随着互联网技术的迅速发展,中文作文的自动评分研究逐渐兴起,对于提高作文的评分效率,从根本上消除作文评价的不一致,控制评分误差具有十分重要的意义。由于中文语言逻辑的复杂程度大,现有的研究对作文评测大多从词汇使用、语法、表达、作文长度、关联词使用、修辞手法的运用、文章主题一致性等角度而进行评测,并未涉及作文内部逻辑合理性评测。但是,在作文评测中,逻辑合理性同样是评价语言运用能力的一项重要指标。文本中句间的逻辑合理表现在句子组织顺序合理,这样的文本具有很好的可读性。
现有技术中,关于句子排序的研究主要出现在文本自动摘要领域中,文本自动摘要领域内的句子排序任务,主要是将人工已写好的且打乱顺序的文档摘要句集或机器选择的摘要候选句集组织为合理并且可读的文摘。现有的研究大致可划分成以下几类:一、利用句中时间信息确定句子顺序:以句子在语料中出现的时间为依据进行排序,例如新闻语料中,抽取句子内部的时间信息,再辅助排序算法对句子进行排序;二、从文档集合中句间的蕴含关系确定句子顺序:该方法从句子内部实体在句间的转移、事件标签的延续状态、主题转移等方面挖掘句间所蕴含的逻辑关系;三、从依托大型的语料,挖掘内部句子的自然顺序:该方法在词汇的基础上,计算相邻句子间的邻近度,估计句子构成前后句对的条件概率,得到排序结果。
但以上研究还存在诸多问题,对于第一、第二类研究,其问题主要是:利用时间信息、句间的继承关系、句子主题等方法,具有较大的局限性,无法对不包含这些特定信息的文本进行句子排序;另外由于机器对自然语言理解的不足,依托主题词、时间词及隐含的时间识别、隐形的关联词挖掘也是一大困难。对于第三类研究,其不足主要是:依托大型的语料计算句对之间的词语搭配,参数空间大,容易出现数据稀疏的问题,不利于后续的邻近度计算。
技术实现要素:
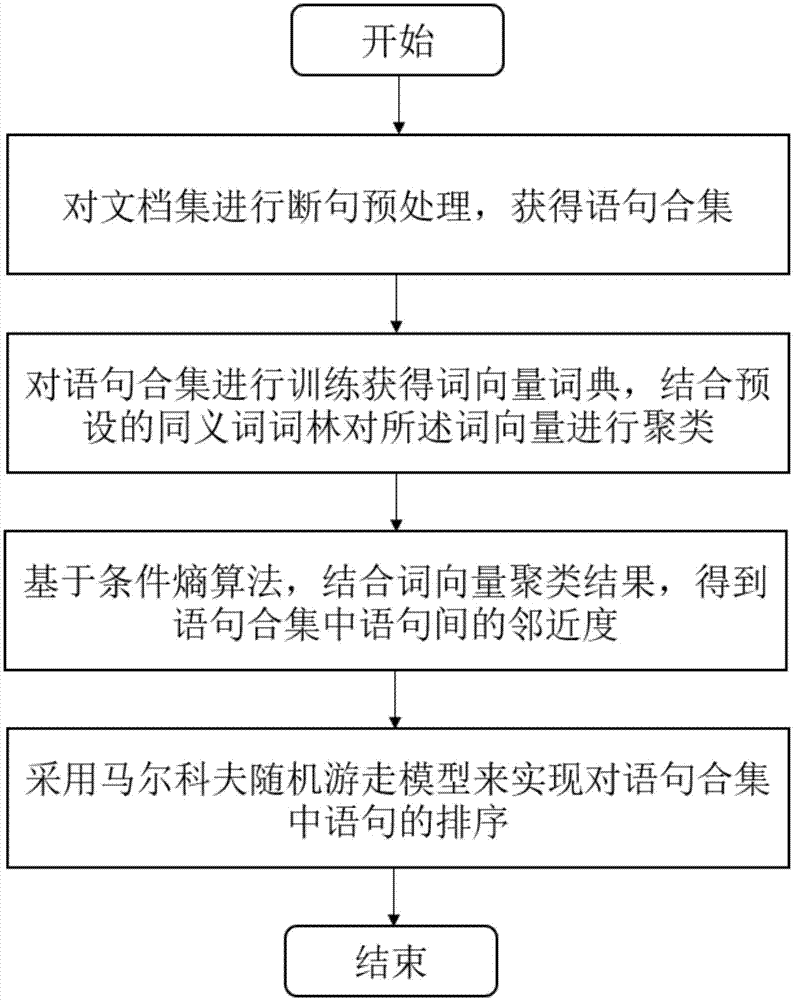
针对现有技术中存在的问题,本发明提供一种语句自动排序方法,包括:
(1)对文档集进行断句预处理,获得语句合集;
(2)对所述语句合集进行训练获得词向量词典,结合预设的同义词词林对所述词向量进行聚类;
(3)基于条件熵算法,结合所述词向量聚类结果,计算所述语句合集中句对间词语的逻辑性搭配信息,从而得到所述语句合集中语句间的邻近度。
进一步的,所述条件熵算法的计算公式如下:
其中,h(sm|sm-1)为所述语句合集中相邻两语句间条件熵的值,sm与sm-1为相邻的两个语句,m为所述语句合集中语句的顺序编号且m为正整数并大于等于2小于等于n,n为所述语句合集中语句的总数;wi为sm-1中出现的词,wj为sm中出现的词,其中,i、j取正整数;p(wiwj)是wi,wj共同出现的概率,p(wj|wi)是条件概率。
进一步的,采用基于神经网络的可从整体递归得到全局信息并决定其中任一节点重要性的算法来实现对所述语句合集中的语句的排序。
进一步的,所述神经网络算法基于马尔科夫随机游走模型。
进一步的,将所述词向量聚类为500-1500类。
进一步的,所述预设的同义词词林中同义词的个数在7000类以上。
进一步的,所述语句自动排序方法还包括对所述语句的排序结果的评测步骤,所述评测步骤基于rouge-l对所述语句的排序结果进行评分。
进一步的,所述rouge-l评分的阈值设为0.6,即将所述文档的真实语句排序结果与所述语句自动排序方法的语句排序结果比较,若所述rouge-l评分大于或等于阈值,则两者排序结果是相似的。
进一步的,对所述语句合集进行划分,划分为若干包含2-3个语句的语句块合集;
首先,基于条件熵算法,结合所述词向量聚类结果,计算所述语句块合集中相邻的语句块之间词语的逻辑性搭配信息,从而得到所述语句块合集中语句块间的邻近度;
然后,基于条件熵算法,结合所述词向量聚类结果,计算每一所述语句块中的句对间词语的逻辑性搭配信息,从而得到每一所述语句块中的语句间的邻近度。
本发明还提供一种语句自动排序的生成装置,包括:
文档预处理模块,用于对文档集进行语句切分,得到所述文档集对应的语句合集;
词向量聚类模块,用于对所述语句合集进行训练,获得词向量词典,并结合预设的同义词词林对所述词向量进行聚类;
邻近度计算模块,基于条件熵算法,结合所述词向量的聚类结果,计算所述语句合集中句对间词语的逻辑性搭配信息,从而得到所述语句合集中语句间的邻近度;
排序结果生成模块,用于根据所述语句的邻近度计算结果,利用马尔科夫随机游走模型对所述语句进行排序,获得排序结果。
本发明的有益之处在于:
(1)本发明的语义分析方法可实现对文本语句逻辑性的自动评判,提高评判效率、减少评判误差。
(2)本发明采用非监督的方法,对较大数量的语料和较小数量的语料均具有较优的通用性。
(3)本发明利用马尔科夫随机游走模型对句子进行排序,算法效率高、排序结果更可靠。
(4)本发明利用词向量在语义上对词语进行划分与聚类,可降低数据稀疏的影响,提高计算效率。
(5)本发明结合同义词词林可降低自动聚类的不准确性、优化句子排序结果。
(6)本发明的语句自动排序中利用将段落拆分为句子块的方法,可取得更为合理的语句自动排序效果。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明语句自动排序方法的流程图;
图2为本发明语句自动排序装置的结构示意图;
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件;句对指的是语句合集中相邻的两个语句。
参见图1为根据本发明一个实施例的语句自动排序方法的流程图,该语句自动排序方法包括以下步骤:
(1)从网络上各个作文网站获取中小学人物类作文语料16329篇,另外获取了其他类别作文109404篇,获取共计125733篇文档的文档集,对所述文档集进行断句的预处理,获得语句合集;
(2)对所述语句合集通过进行训练,获得词向量词典,结合预设的同义词词林对所述词向量进行聚类。其中,所述词向量优选地通过word2vec进行训练,获得共计79770个词的词向量词典;所述预设的同义词词林中同义词的个数在7000类以上,更优选为《哈工大信息检索研究室同义词词林扩展版》,其共涉及11769类同义词;优选地将所述词向量聚类为500-1500类,更优选地将所述词向量聚类为1500类。
(3)基于条件熵算法,结合所述词向量的聚类结果,计算所述语句合集中句对间词语的逻辑性搭配信息,从而得到所述语句合集中语句间的邻近度,条件熵算法的计算公式如下:
其中,h(sm|sm-1)为所述语句合集中相邻两语句间条件熵的值,sm与sm-1为相邻的两个语句,m为所述语句合集中语句的顺序编号且m为正整数并大于等于2小于等于n,n为所述语句合集中语句的总数;wi为sm-1中出现的词,wj为sm中出现的词,其中,i、j取正整数;p(wiwj)是wi,wj共同出现的概率,p(wj|wi)是条件概率。
(4)在确定了所述语句合集中语句间的邻近度后,采用基于神经网络的可从整体递归得到全局信息并决定其中任一节点重要性的算法来实现对所述语句合集中的语句的排序。优选地,选择马尔科夫随机游走模型对句子进行排序,其计算方法如下:
随机游走矩阵对应一个遍历的马尔科夫链,任意两个状态之间通过不断转移可以互相到达,所述马尔科夫随机游走模型定义了图g=(v,e),v是顶点集,即待排序的所述语句的集合,e是边集,即待排序的所述语句集合中任意两个语句的邻近度,其值即为通过所述条件熵公式计算得到的语句vi→vj的概率,其中,i、j为正整数代表所述语句合集中语句的顺序编号。m个待排序句子可得到游走矩阵序m=|mi,j|m×m,
基于矩阵模m,所述语句合集中的某个语句在排序中的分值sentscore(vi)可通过与其他语句得到,其计算公式如下:
图g=(v,e)按照以上计算直至收敛,选取其中分值最高的语句优先排序,将剩余句子重新组成新图g'重新执行操作,直至待排序语句v为空。语句的排序顺序即为最终的排序结果。
(5)在得到所述语句合集的排序结果后,对所述语句的排序结果进行评测,利用rouge-l对所述语句的排序结果进行评分,所述rouge-l从最长公共子串的角度考虑,进行相似度的打分,其计算公式如下:
lsc=lsc(stand_order.sorted_order)
其中,lsc为所述语句自动排序方法的排序结果(sorted_order)和所述文档的真实语句排序结果(stand_order)的最长公共子串的长度;len(sorted_order)为所述语句自动排序方法的排序结果的长度,len(stand_order)为所述文档的真实语句排序结果的长度,两者长度是一致的;r表示召回率,p表示准确率,score(rouge-l)为rouge-l的评分;公式经过化简,所述rouge-l的评分由公共子串在所述排序结果中长度中的比例决定。
优选地,所述rouge-l评分的阈值设为0.6,即将所述文档的真实语句排序结果与所述语句自动排序方法的语句排序结果比较,若所述rouge-l评分大于或等于阈值,则两者排序结果是相似的,则可认为所述语句自动排序方法的语句排序结果是一致且可接受的,然后统计经所述语义分析自动排序方法得到的可接受排序比例。
进一步的,本发明通过对实验结果的分析,发现在所述文档集中的文档包含的语句数量较少的情况下,所述语句自动排序方法取得了较多可接受的排序结果,但是随着所述文档集的文档内部语句数量的增多,所述可接受排序比例的数值逐渐下降,因此提出一种对所述语句自动排序方法的优化步骤,具体为:
首先,对所述语句合集进行划分,划分为若干包含2-3个语句的语句块合集;
其次,基于条件熵算法,结合所述词向量聚类结果,计算所述语句块合集中相邻的语句块之间词语的逻辑性搭配信息,从而得到所述语句块合集中语句块间的邻近度;利用马尔科夫随机游走模型,得到所述语句块的排序结果。
再次,基于条件熵算法,结合所述词向量聚类结果,计算每一所述语句块中的句对间词语的逻辑性搭配信息,从而得到每一所述语句块中的语句间的邻近度;利用马尔科夫随机游走模型,得到每一所述语句块中的语句的排序结果。
最后,将所述语句块的排序结果和所述语句块中的语句的排序结果结合,即可得到所述文档语句的最终排序。
通过实验验证,所述语句自动排序方法采取所述优化步骤后,可减缓随着所述文档集的文档内部语句数量的增多所述可接受排序比例的数值逐渐下降的情况,从而验证了所述语句自动排序方法采取的所述优化步骤策略是可行的。
此外,参见图2,本发明还提供一种语句自动排序的生成装置,包括:
文档预处理模块100,用于对文档集进行语句切分,以得到所述文档集对应的语句合集;
词向量聚类模块200,用于对所述语句合集进行训练,获得词向量词典,并结合预设的同义词词林对所述词向量进行聚类;
邻近度计算模块300,基于条件熵算法,结合所述词向量的聚类结果,计算所述语句合集中句对间词语的逻辑性搭配信息,从而得到所述语句合集中语句间的邻近度;
排序结果生成模块400,用于根据所述语句的邻近度计算结果,利用马尔科夫随机游走模型对所述语句进行排序,获得排序结果。
此外,虽然已经显示并描述了本发明总体构思的若干实施例和优选实施方式,但是本领域的技术人员应该理解,在不脱离本发明总体构思的原理和精神的情况下,可以对这些实施例进行改变,本发明的总体构思由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!