本发明涉及人脸及其属性识别、行人及其属性识别的深度学习领域,特别涉及网络结构的构造。
背景技术
目前人脸识别技术成果在学术研究领域突飞猛进,但人脸识别应用到现实生活中往往存在可靠性不高的问题。当前大部分人脸识别系统只能在一些限制环境下使用,例如:1.被测主体需要主动配合;2.人脸图像具有较高分辨率;3.良好的光照条件。在自然场景中往往存在姿态、光照、表情等干扰因素,人脸识别技术的发展和推广必须要克服这些干扰。
行人再识别技术是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。面对海量増长的监控视频,利用计算机对监控视频中的行人进行再识别的需求应运而生。近年来行人再识别在研究人员的不懈努力下已经得到了快速发展,然而与实际应用的需求还有很大的差距。首先,在一般的监控视频里,图像中行人的分辨率较低,人脸信息模糊,这对图像分析、提取特征及分割等都十分不利;其次,行人与行人或其他物体之间会存在遮挡的情况,这对于行人的表示有很大的影响;最后,监控环境的不同、摄像头参数的不同、光照的不同使得同一个人的外貌发生较大的变化,匹配起来有一定的难度。如何克服上述因素对行人匹配任务造成的困难,找出有效的方法来解决,是行人再识别问题的重要研究方向。
技术实现要素:
本发明克服了现有技术的不足之处,提出了一种基于深度学习的人脸与行人及其属性识别网络结构,意在利用基于卷积神经网络的多任务网络进行人脸及其属性识别、行人及其属性识别,并加入行人关键点轨迹特征、人脸关键点轨迹特征,提高人脸与行人及其属性识别的准确性。
本发明为达上述发明目的,采用如下技术方案:
一种基于深度学习的人脸与行人及其属性识别网络结构设计方法,其步骤包括:
步骤(1):将由监控摄像头捕获的连续n帧视频图像输入到行人检测及跟踪模块,当视频图像中出现第i个行人时,输出第i个行人的连续n帧行人图像序列所述行人检测采用开源的fasterr-cnn算法,该算法包含三个基本框架,第一个是候选区域网络结构(regionproposalnetwork,rpn),用来为每一张监控视频图像产生候选区域,第二个是卷积神经网络,用来从候选区域中提取行人特征,第三个是二元softmax分类器,用来判断候选区域中是否包含行人,所述行人跟踪采用opencv的光流跟踪函数;
步骤(2):分别将由步骤(1)得到的第i个行人的连续n帧行人图像序列输入到基于卷积神经网络的行人特征提取子网络中,该网络包含卷积层、最大采样层两种网络层,采用两个卷积层接最大采样层作为一个子结构,所述行人特征提取子网络包含n个串联子结构;
步骤(3):分别对由步骤(1)得到的第i个人的连续n帧行人图像序列进行行人关键点检测得到相应的m个行人关键点通过m个行人关键点位置变化对行人关键点轨迹采用公式(1)进行计算,对获得的m个行人关键点轨迹向量分别采用公式(2)进行归一化,并将经过归一化的m个向量进行合并,作为行人关键点轨迹特征,将行人关键点轨迹特征与行人特征提取子网络连接的全连接层pc的输出进行特征融合,得到融合特征s1,所述特征融合采用深度学习框架caffe中的concat层,将行人关键点轨迹特征和行人特征提取子网络连接的全连接层pc的输出作为concat层的输入,其中,行人关键点轨迹特征的维度为m×(n-1)×2维,行人特征提取子网络相连的全连接层pc的维度为d维,最终concat层的输出即为融合特征s1;
步骤(4):分别将由步骤(1)得到的第i个行人的连续n帧行人图像序列输入到人脸检测模块进行人脸检测,得到第i个人的连续n帧人脸图像序列所述人脸检测模块采用开源人脸识别引擎seetaface的人脸检测模块,该模块采用漏斗型级联结构(funnel-structuredcascade,fust),fust级联结构在顶部由多个针对不同姿态的快速lab级联分类器构成,紧接着是若干个基于surf特征的多层感知机(mlp)级联结构,最后由一个统一的mlp级联结构来处理所有姿态的候选窗口,最终保留正确的人脸窗口,得到人脸图像;
步骤(5):判断由步骤(4)得到的第i个行人的连续n帧人脸图像序列分辨率,将分辨率大于a×b的人脸图像不进行超分辨率处理,将分辨率小于a×b的人脸图像进行超分辨率处理,最终得到第i个行人分辨率较高的连续n帧人脸图像序列
步骤(6):分别将由步骤(5)得到的人脸图像序列输入到基于卷积神经网络的人脸特征提取子网络中,该网络由m个卷积层构成;
步骤(7):分别对由步骤(5)得到的人脸图像序列进行人脸关键点检测得到相应s个人脸关键点通过s个人脸关键点位置变化对人脸关键点轨迹采用公式(1)进行计算,对获得的s个人脸关键点轨迹向量分别采用公式(2)进行归一化,并将经过归一化的s个向量进行合并,作为人脸关键点轨迹特征,将人脸关键点轨迹特征与人脸特征提取子网络连接的全连接层fc的输出进行特征融合,得到融合特征s2,其中,人脸关键点轨迹特征的维度为s×(n-1)×2维,人脸特征提取子网络相连的全连接层fc的维度为d维;
步骤(8):将由步骤(7)得到的融合特征s2作为人脸身份特征层、人脸属性1特征层、人脸属性2特征层、...、人脸属性v特征层的输入,将人脸身份特征层作为身份分类层的输入,人脸属性1特征层作为人脸属性1分类层的输入,人脸属性2特征层作为人脸属性2分类层的输入,...,人脸属性v特征层作为人脸属性v分类层的输入;
步骤(9):对由步骤(3)得到的融合特征s1和由步骤(7)得到的融合特征s2进行特征融合得到特征融合s3,其中融合特征s1的维度为m×(n-1)×2+d维,融合特征s2的维度为s×(n-1)×2+d维;
步骤(10):将由步骤(9)得到的融合特征s3作为行人身份特征层、行人属性1特征层、行人属性2特征层、...、行人属性v特征层的输入,将行人身份特征层作为行人身份分类层的输入,行人属性1特征层作为行人属性1分类层的输入,行人属性2特征层作为行人属性2分类层的输入,...,行人属性u特征层作为行人属性u分类层的输入;
其中,当t=0时,表示计算第i个行人的行人关键点轨迹,k表示第i个行人的第k个行人关键点,k∈[1,m],j表示第i个行人的第j帧行人图像,j∈[1,n-1],表示第i个行人的第j帧到第j+1帧行人图像的第k个行人关键点轨迹,表示第i个行人的第j+1帧行人图像的第k个行人关键点坐标,表示第i个行人的第j帧行人图像的第k个行人关键点坐标,表示第i个行人的第j+1帧行人图像第k个行人关键点的x轴坐标,表示第i个行人的第j+1帧行人图像第k个行人关键点的y轴坐标,表示第i个行人的第j帧行人图像第k个行人关键点的x轴坐标,表示第i个行人的第j帧行人图像第k个行人关键点的y轴坐标;
当t=1时,表示计算第i个行人的人脸关键点轨迹,k表示第i个行人的第k个人脸关键点,k∈[1,s],j表示第i个行人的第j帧人脸图像,j∈[1,n-1],表示第i个行人的第j帧到第j+1帧人脸图像的第k个人脸关键点轨迹,表示第i个行人的第j+1帧人脸图像的第k个人脸关键点坐标,表示第i个行人的第j帧人脸图像的第k个人脸关键点坐标,表示第i个行人的第j+1帧人脸图像第k个人脸关键点的x轴坐标,表示第i个行人的第j+1帧人脸图像第k个人脸关键点的y轴坐标,表示第i个行人的第j帧人脸图像第k个人脸关键点的x轴坐标,表示第i个行人的第j帧人脸图像第k个人脸关键点的y轴坐标。
其中,当t=0时,表示对第i个行人的行人关键点轨迹向量进行归一化,k表示第i个行人的第k个行人关键点,k∈[1,m],j表示第i个行人的第j帧行人图像,j∈[1,n-1],表示第i个行人的连续n帧行人图像的第k个行人关键点轨迹特征,为(n-1)×2维的向量,表示第i个行人的连续n帧行人图像的第k个行人关键点轨迹,表示第i个行人的第j帧到第j+1帧行人图像的第k个行人关键点轨迹长度;
当t=1时,表示对第i个行人的人脸关键点轨迹向量进行归一化,k表示第i个行人的第k个人脸关键点,k∈[1,s],j表示第i个行人的第j帧人脸图像,j∈[1,n-1],表示第i个行人的连续n帧人脸图像的第k个人脸关键点轨迹特征,为(n-1)×2维的向量,表示第i个行人的连续n帧人脸图像的第k个人脸关键点轨迹,表示第i个行人的第j帧到第j+1帧人脸图像的第k个人脸关键点轨迹的长度。
与现有技术相比,本发明的有益效果体现在:
本发明提出一种基于深度学习的人脸与行人及其属性识别网络结构设计方法,将监控视频图像输入到行人检测及跟踪模块进行行人检测跟踪得到同一个人的多张行人图像;对得到的同一个人的多张行人图像进行行人关键点检测,通过计算得到行人关键点轨迹特征,将得到行人关键点轨迹特征与行人特征提取子网络连接的全连接层进行特征融合得到融合特征s1;将得到的同一个人的多张行人图像输入到人脸检测模块进行人脸检测得到同一个人的多张人脸图像;判断同一个人的多张人脸图像分辨率,将分辨率较高的人脸图片直接输入到人脸多任务识别子网络中,对分辨率较低的人脸图片进行超分辨率处理后再输入到人脸多任务识别子网络中;对同一个人多张人脸图像进行关键点检测得到的人脸关键点,通过计算得到人脸关键点轨迹特征,将得到人脸关键点轨迹特征与人脸多任务识别子网络连接的全连接层进行特征融合得到融合特征s2,利用融合特征s2进行人脸及其属性识别;将融合特征s1和融合特征s2进行特征融合得到特征融合s3,利用融合特征s3进行行人及其属性识别。该网络结构提高人脸与行人及其属性识别的准确率。
附图说明
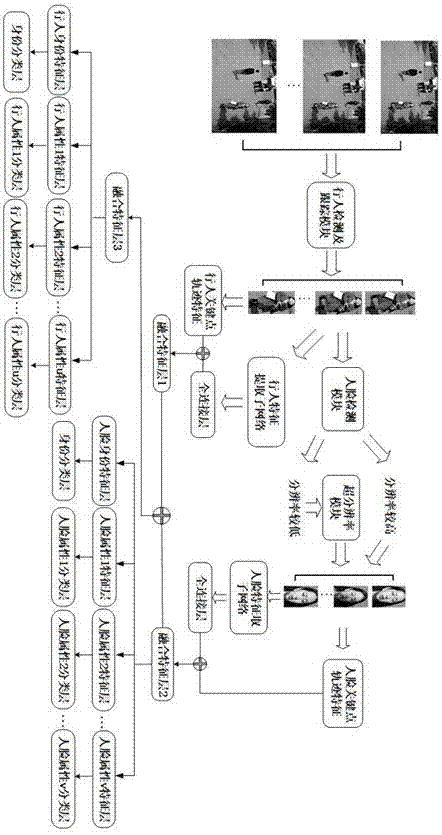
图1是基于深度学习的人脸与行人及其属性识别网络结构示意图。
图2是行人特征提取子网络结构示意图。
图3是人脸特征提取子网络结构示意图。
具体实施方式
本实施例中,如图1所示,一种基于深度学习的人脸与行人及其属性识别网络结构示意图,具体实现主要包括如下步骤:
步骤(1):将由监控摄像头捕获的连续15帧视频图像输入到行人检测及跟踪模块,当视频图像中出现第i个行人时,输出第i个行人的连续15帧行人图像序列所述行人检测采用开源的fasterr-cnn算法,该算法包含三个基本框架,第一个是候选区域网络结构(regionproposalnetwork,rpn),用来为每一张监控视频图像产生候选区域,第二个是卷积神经网络,用来从候选区域中提取行人特征,第三个是二元softmax分类器,用来判断候选区域中是否包含行人,所述行人跟踪采用opencv的光流跟踪函数;
步骤(2):分别将由步骤(1)得到的第i个行人的连续15帧行人图像序列输入到基于卷积神经网络的行人特征提取子网络中,该网络包含卷积层、最大采样层两种网络层,采用两个卷积层接最大采样层作为一个子结构,所述行人特征提取子网络包含10个串联子结构;
步骤(3):分别对由步骤(1)得到的第i个人的连续15帧行人图像序列进行行人关键点检测得到相应的18个行人关键点通过18个行人关键点位置变化对行人关键点轨迹采用关键点轨迹计算公式进行计算,对获得的18个行人关键点轨迹向量分别采用关键点轨迹归一化公式进行归一化,并将经过归一化的18个向量进行合并,作为行人关键点轨迹特征,将行人关键点轨迹特征与行人特征提取子网络连接的全连接层pc的输出进行特征融合,得到融合特征s1,所述特征融合采用深度学习框架caffe中的concat层,将行人关键点轨迹特征和行人特征提取子网络连接的全连接层pc的输出作为concat层的输入,其中,行人关键点轨迹特征的维度为504维,行人特征提取子网络相连的全连接层pc的维度为512维,最终concat层的输出即为融合特征s1;
步骤(4):分别将由步骤(1)得到的第i个行人的连续15帧行人图像序列输入到人脸检测模块进行人脸检测,得到第i个人的连续15帧人脸图像序列所述人脸检测模块采用开源人脸识别引擎seetaface的人脸检测模块,该模块采用漏斗型级联结构(funnel-structuredcascade,fust),fust级联结构在顶部由多个针对不同姿态的快速lab级联分类器构成,紧接着是若干个基于surf特征的多层感知机(mlp)级联结构,最后由一个统一的mlp级联结构来处理所有姿态的候选窗口,最终保留正确的人脸窗口,得到人脸图像;
步骤(5):判断由步骤(4)得到的第i个行人的连续15帧人脸图像序列分辨率,将分辨率大于112×112的人脸图像不进行超分辨率处理,将分辨率小于112×112的人脸图像进行超分辨率处理,最终得到第i个行人分辨率较高的连续15帧人脸图像序列
步骤(6):分别将由步骤(5)得到的人脸图像序列输入到基于卷积神经网络的人脸特征提取子网络中,该网络由20个卷积层构成;
步骤(7):分别对由步骤(5)得到的人脸图像序列进行人脸关键点检测得到相应5个人脸关键点通过5个人脸关键点位置变化对人脸关键点轨迹采用关键点轨迹计算公式进行计算,对获得的5个人脸关键点轨迹向量分别采用关键点轨迹归一化公式进行归一化,并将经过归一化的5个向量进行合并,作为人脸关键点轨迹特征,将人脸关键点轨迹特征与人脸特征提取子网络连接的全连接层fc的输出进行特征融合,得到融合特征s2,其中,人脸关键点轨迹特征的维度为140维,人脸特征提取子网络相连的全连接层fc的维度为512维;
步骤(8):将由步骤(7)得到的融合特征s2作为人脸身份特征层、性别特征层、表情特征层、年龄特征层的输入,将人脸身份特征层作为身份分类层的输入,性别特征层作为性别分类层的输入,表情特征层作为表情分类层的输入,年龄特征层作为年龄分类层的输入;
步骤(9):对由步骤(3)得到的融合特征s1和由步骤(7)得到的融合特征s2进行特征融合得到特征融合s3,其中融合特征s1的维度为1016维,融合特征s2的维度为652维;
步骤(10):将由步骤(9)得到的融合特征s3作为行人身份特征层、性别特征层、发型特征层、衣服类型特征层的输入,将行人身份特征层作为行人身份分类层的输入,性别特征层作为性别分类层的输入,发型特征层作为发型分类层的输入,衣服类型特征层作为衣服类型分类层的输入;
关键点轨迹计算公式为:
其中,当t=0时,表示计算第i个行人的行人关键点轨迹,k表示第i个行人的第k个行人关键点,k∈[1,m],j表示第i个行人的第j帧行人图像,j∈[1,n-1],表示第i个行人的第j帧到第j+1帧行人图像的第k个行人关键点轨迹,表示第i个行人的第j+1帧行人图像的第k个行人关键点坐标,表示第i个行人的第j帧行人图像的第k个行人关键点坐标,表示第i个行人的第j+1帧行人图像第k个行人关键点的x轴坐标,表示第i个行人的第j+1帧行人图像第k个行人关键点的y轴坐标,表示第i个行人的第j帧行人图像第k个行人关键点的x轴坐标,表示第i个行人的第j帧行人图像第k个行人关键点的y轴坐标,当j=1,k=1时,则第i个人的第1帧到第2帧行人图像的第1个行人关键点轨迹为:
当t=1时,表示计算第i个行人的人脸关键点轨迹,k表示第i个行人的第k个人脸关键点,k∈[1,s],j表示第i个行人的第j帧人脸图像,j∈[1,n-1],表示第i个行人的第j帧到第j+1帧人脸图像的第k个人脸关键点轨迹,表示第i个行人的第j+1帧人脸图像的第k个人脸关键点坐标,表示第i个行人的第j帧人脸图像的第k个人脸关键点坐标,表示第i个行人的第j+1帧人脸图像第k个人脸关键点的x轴坐标,表示第i个行人的第j+1帧人脸图像第k个人脸关键点的y轴坐标,表示第i个行人的第j帧人脸图像第k个人脸关键点的x轴坐标,表示第i个行人的第j帧人脸图像第k个人脸关键点的y轴坐标,当j=1,k=1时,则第i个人的第1帧到第2帧人脸图像的第1个人脸关键点轨迹为:
关键点轨迹归一化公式为:
其中,当t=0时,表示对第i个行人的行人关键点轨迹向量进行归一化,k表示第i个行人的第k个行人关键点,k∈[1,m],j表示第i个行人的第j帧行人图像,j∈[1,n-1],表示第i个行人的连续n帧行人图像的第k个行人关键点轨迹特征,为(n-1)×2维的向量,表示第i个行人的连续n帧行人图像的第k个行人关键点轨迹,表示第i个行人的第j帧到第j+1帧行人图像的第k个行人关键点轨迹长度,当n=15,k=1时,则第i个行人连续15帧行人图像的第1个行人关键点轨迹向量归一化为:
当t=1时,表示对第i个行人的人脸关键点轨迹向量进行归一化,k表示第i个行人的第k个人脸关键点,k∈[1,s],j表示第i个行人的第j帧人脸图像,j∈[1,n-1],表示第i个行人的连续n帧人脸图像的第k个人脸关键点轨迹特征,为(n-1)×2维的向量,表示第i个行人的连续n帧人脸图像的第k个人脸关键点轨迹,表示第i个行人的第j帧到第j+1帧人脸图像的第k个人脸关键点轨迹的长度,当n=15,k=1时,则第i个行人连续15帧人脸图像的第1个人脸关键点轨迹向量归一化为: