基于深度卷积神经网络的SAR图像地物分类识别方法与流程
本发明是一个基于机器学习中的深度学习算法来处理sar图像而进行地物分类的识别技术,属于图像处理领域。
背景技术
合成孔径雷达(syntheticapertureradar,sar)具有全天时,全天候观测地物的能力,已经在农业,环境,军事等各个方面产生广泛的作用。其中,对sar图像进行地物分类是对sar图像进行应用的基础。
对于sar图像的分类目前已有大量研究,这些研究仍然是着眼于传统的研究方法,大多数是监督学习分类,而这中分类方法需要有大量的标记样本,和专业人才进行识别,往往需要大量的人力和物力,并且结果精度不高。
技术实现要素:
针对现有技术存在的问题,本发明提供一种基于深度卷积神经网络的sar图像地物分类识别方法,能够提高识别sar图像的精度。
本发明所要解决的技术问题是通过以下技术方案实现的:
基于深度卷积神经网络的sar图像地物分类识别方法,包括:
首先从得到的sar图像中筛选出对研究目的有用的图像。
接下来对筛选出的sar图像通过利用离散小波变换的稀疏性进行滤波抑制图像的噪点,以提高图像的质量。
再接下来,将滤波处理后的图像作为原始输入数据,对该原始数据图像进行裁剪,将其裁剪为10000*10000(长*宽,单位:像素)的多幅图像。然后从这些图像中抽取80%作为训练样本,剩下的20%作为测试样本用来评估结果精度。
原始输入数据准备好之后开始建立用于地物信息分类的卷积神经网络,通过深度学习方法搭建该卷积神经网络,该神经网络依次包括输入层、卷积层、池化层以及输出层。
其中,第一层是输入层(inputlayer),其将输入的裁剪后的sar图像分解成一个像素矩阵,像素矩阵由像素点构成,以便对单个像素点进行处理。
其后的卷积层共由七层过滤器组成,第一层过滤器的尺寸长*宽为25*25,深度为16,第二层过滤器的尺寸为长*宽为25*25,深度为32,第三层的过滤器的尺寸长*宽为15*15,深度为64;第四层的过滤器的尺寸长*宽为12*12,深度为128,第五层过滤器的尺寸长*宽为4*4,深度为256,第六层过滤器的尺寸长*宽3*3,深度为512,第七层过滤器的尺寸长*宽2*2,深度为1024。
再接下来的池化层采用两种参数的最大池化层,共七层,分别是降维最大池化层和精度最大池化层,前五层降维最大池化层设定池化层的采样窗口为(poolingsize)4*4,滑动步长为4,后两层精度最大池化层设定其采样窗口的大小2*2,滑动步长2。
经过池化层后,图像中的信息被抽象成信息含量更高的特征,被抽象过的图像再经过全连接层(全连接层在输出层的前面,将每个神经元和前面一层的所有神经元相连接,然后最后一层全连接层的输出值就可以用softmax来分类),使用relu函数f(x)=max(x,0)作为全连接层的激活函数,x表示输入的神经元,使用softmax回归使神经网络向前传播得到的结果变成一个概率分布。从而通过交叉熵(crossentropy)来计算预测的概率分布和真实答案的距离,距离越近则说明其更加接近真实值,则取预测结果最接近的作为分类结果,从而完成分类识别。
本发明所达到的有益效果是:
1)本发明通过搭建的深度卷积神经网络结构实现了高分辨率的sar图像的地物分类,不仅可以减少了人工的识别工作量,而且对于精度也较之其他识别算法有了一个较大的提升,使识别的物体类别更加精确。
2)本发明实现了利用深度的卷积神经网络,提高了识别sar图像的精度,解决了卷积神经网络只能简单提取单幅低像素的sar图像的某个物体的信息。
3)本发明克服了现有方法只能选取单个目标物的识别困难,并且大大力高了sar图像的利用率。
附图说明
图1为本发明的网络结构示意图;
图2为本发明的卷积核的示意图;
图3为本发明的卷积5向前传播的过程示意图;
图4为本发明池化层向前传播的过程示意图;
图5为本发明的输出概率示意图。
具体实施方式
为了进一步描述本发明的技术特点和效果,以下结合附图和具体实施方式对本发明做进一步描述。
如图1-5所示,一种基于深度卷积神经网络的sar图像地物分类识别方法,过程如下:
首先是获取相关的数据,数据源为多种气象卫星,如高分三号,sentinel和alospalsar等,然后从这些卫星图像中筛选出对研究目的有用的图像。
接下来,对挑选出来sar图像利用离散小波变换的稀疏性对图像滤波抑制图像中的噪点,以提高图像的质量。
然后将滤波过的图像裁剪成每幅大小10000*10000(单位:像素)的图像,从这些图像中抽取80%作为训练样本,剩下的20%作为测试样本来评估结果精度。
然后将经过滤波处理的sar图像作为原始输入数据,对作为原始输入数据的图像进行裁剪,从裁剪后的图像中抽出部分作为训练样本,剩下的作为测试样本。
再接下来利用上述样本利用深度学习算法,搭建卷积神经网络cnn(convolutionalneuralnetwork),这里采用谷歌公司的tensorflow作为深度学习的框架。该神经网络依次包括输入层、卷积层、池化层以及输出层。
建立起来的cnn的第一层为输入层(inputlayer),该层将之前裁剪好的sar图像分解成一个像素矩阵。图1是本发明的卷积神经网络的网络结构示意图,输入层是整个卷积神经网路的输入,左侧的三维矩阵就是一张sar图像,其中的三维矩阵的长和宽代表了图像的大小,三维矩阵的图像深度代表了图像的通道,sar图像是以灰度形式呈现的,所以深度(deep)为1。
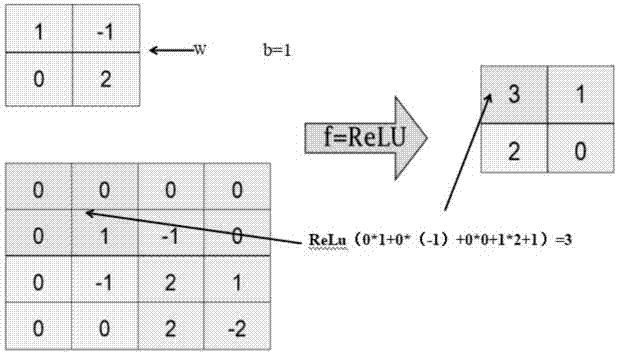
图2是本发明卷积层过滤器的示意结构,左侧图像是过滤器,它的矩阵深度和当前的神经网络节点矩阵深度是一致的,制定长宽维度。过滤器的前向传播是通过左侧小矩阵中的节点计算出右侧单位矩阵中的节点。具体步骤:首先是根据输入的原始图像的矩阵大小来设定卷积层的各项参数,第一个卷积层选取16个(即深度为16)25*25的卷积核(convolutionkernel),输出16个9976*9976的第一层输出图,经过第一个池化层得到的特征图2494*2494。然后经过这个池化层输出的特征图是第二个卷积层的输入图像,第二层卷积层包含32个(深度为32)25*25的卷积核,由此卷积核生成2470*2470的特征图,经过第二个池化层,该池化层参数和第一层相同,得到一个618*618的特征图,接着第三个卷积层是64个像素大小为15*15的卷积核,生成一个604*604的特征图,该特征图后再经过第三层池化层(参数与上述一致)得到一个大小为151*151的特征图,接着第四层,卷积层的包含参数是128个12*12的卷积核,得到输出图层大小为140*140,经过第四层池化层,参数同上,得到35*35的输出图层。完成一个原sar图降维的过程后,下面对输出的35*35的图层进行精确识别,以提高神经网络的识别精度。
第五层,卷积核包含256个4*4的特征图,生成一个32*32的图层,经过重新选定的池化层2*2的图像进行最大池化,得到一个16*16的图像,第六层卷积核包含512个3*3的特征图,得到一个14*14的输出矩阵,经过上述相同的2*2的池化层,得到7*7的图像,第七层卷积层,卷积核的尺寸为2*2,数量是1024,输出图像矩阵6*6,经过池化,得到3*3的图像。至此完成一个图像降维和提高精度的过程。
第三步就是构建输出层,输出层包括是以全连接的方式构建,包括激活函数和归一化层,用relu(rectifiedlinearunit,relu)函数f(x)=max(x,0),x为输入的神经元。这样可以使神经网络不是一个线性模型,从而提高他的识别精度。,这里还需要加一个偏质项,可以设为1。在进行softmax的回归处理,处理完后输出一个经过分类的sar图像。(图5为本发明的输出概率示意图,是通过softmax层将神经网络输出变成一个概率分布)。
图3是本发明的池化层向前传播的过程,图中的不同的线段代表了不同的池化层过滤器,池化层不仅在长度和宽度上移动,还在深度上进行移动。根据人工设定的步长在图像中滑动分块,采用不同颜色区分,这里是用小块2*2去滑动把大块4*4分成了4大块,每一块加上灰色矩阵是权重和偏置值1,然后都去利用之前的relu进行计算,得到一个全新的矩阵,給下面的神经元处理。
图4是本发明池化层向前传播的过程示意图;maxpool叫做最大池化,它就是利用最大值操作的池化层,这里采用不同颜色表示,把一个大的像素矩阵(也就是图片)按照步长分块(这里分成了2*2),每块取最大值,效果就是由4*4然后变成一个2*2的像素矩阵,即降维操作,把一张大图,降低维度到可以处理的大小))。
上述实施例不以任何形式限定本发明,凡采取等同替换或等效变换的形式所获得的技术方案,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!