基于共生SURF特征的图像检索方法与流程
本发明主要涉及计算机图像处理和模式识别
技术领域:
,具体是一种基于共生surf特征的图像检索方法。
背景技术:
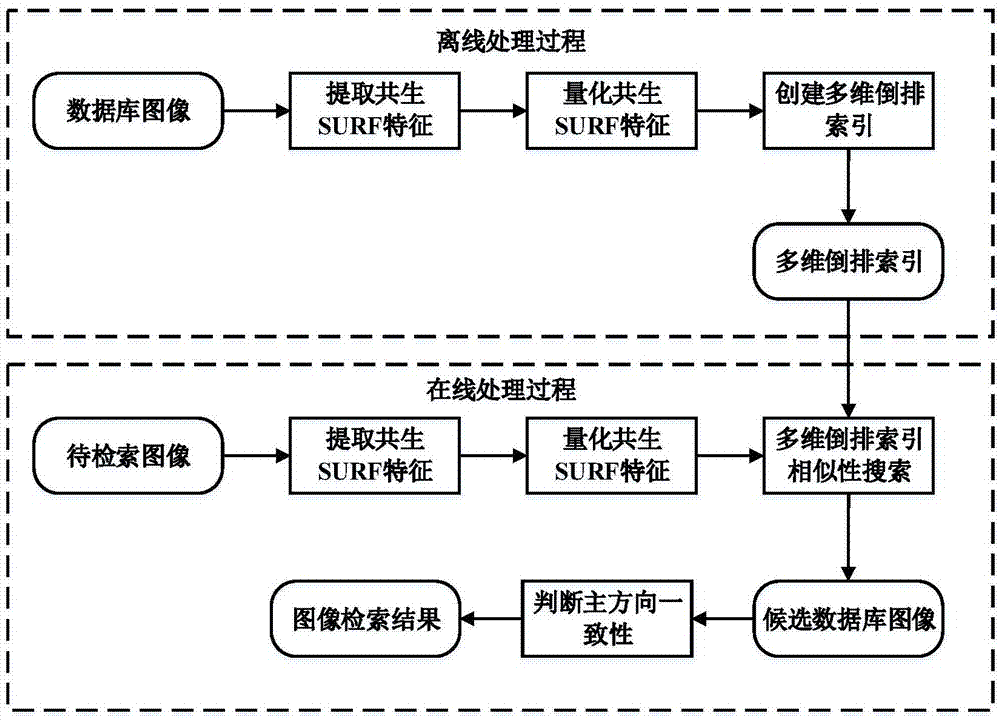
在当前信息时代,图像的采集、获取和传输更加快捷方便,图像的内容更加丰富多样,图像的数量也呈现爆炸式地增长,从而引发了人们越来越关注海量图像的存储、组织和搜索问题。在现实生活中,如何在海量的图像中快速准确地查询到最有用的信息,成为人们研究的热点之一。图像检索技术是指根据文本信息或图像内容信息,在大规模图像库中进行搜索并查找出符合要求的相关图像。图像检索技术分为基于文本的检索方法和基于内容的检索方法。传统的图像检索技术通常是基于文本的检索方法,它采用文字的形式,从图像名称、尺寸、作者等方面描述图像,通过关键词的形式查询图像。与基于文本的检索方法相比,基于内容的检索方法对图像的内容进行客观分析和描述,在早期大多采用颜色、纹理、形状等全局特征进行相似性搜索,如今逐渐被sift、surf等局部特征所取代,并在视觉词袋模型的框架下进行相似性搜索。由于sift、surf等局部特征具有更好的唯一性、不变性和鲁棒性,因此基于局部特征的检索方法更能适应图像背景混杂、局部遮挡、光线变化等各种情况,并在基于内容的图像检索技术中得到广泛应用。经对现有技术的文献检索发现,bay等在文献“surf:speededuprobustfeatures”中首次提出如何在图像中提取surf特征,并且surf特征具有平移、旋转和尺度不变性。sivic等在文献“videogoogle:atextretrievalapproachtoobjectmatchinginvideos”中将sift、surf等局部特征引入图像检索,并提出基于视觉词袋模型的检索框架,但是视觉词袋模型在特征提取时没有考虑局部特征在图像中的空间关系。张一萌等在文献“imageretrievalwithgeometry-preservingvisualphrases”中研究了局部特征在图像中的空间关系,并将空间关系应用于图像检索,但是该空间关系只能保证平移不变性,并且在提取到局部特征后才组织空间关系,增加了检索过程中的计算量。进一步检索发现,钟桦等在专利“一种基于角点描述子的图像检索方法”(申请号:cn201710388212.5,公开日:2017年10月13日)中通过提取图像中角点的局部邻域特征和空间位置实现角点匹配,但是该检索方法没有研究角点描述子在图像中的空间关系。汪友生等在专利“基于改进surf特征的视觉词袋模型构建方法”(申请号:cn201510927757.x,公开日:2016年5月4日)中通过使用渐变信息的盒子滤波对surf特征进行改进,并将其应用于图像检索。但是该方法以单个surf特征为主,没有研究多个surf特征在图像中的空间关系。技术实现要素:本发明针对现有技术存在的上述不足,提供一种基于共生surf特征的图像检索方法,通过在特征检测过程中创建共生surf特征的方式,在图像中组织局部特征的空间关系,使共生surf特征包含的空间关系具有平移、旋转和尺度不变性,进而可以利用此空间关系判断待检索图像和数据库图像之间的空间相似度,将图像之间矢量度量的方式转变为空间关系度量的方式,最终在保证检索效率的同时,提高了检索准确率。本发明是通过以下技术方案来实现的,本发明具体为:首先对数据库图像和待检索图像分别检测局部特征,在每幅图像中提取共生surf特征;然后分别对数据库图像和待检索图像中提取到的共生surf特征进行量化,生成共生视觉词组;接着根据数据库图像中的共生视觉词组创建多维倒排索引,并在倒排索引中利用待检索图像的共生视觉词组进行相似性搜索,查找出候选数据库图像;最后在待检索图像和候选数据库图像之间判断主方向一致性,给出最终的图像检索结果。所述的对数据库图像和待检索图像分别检测局部特征是指:在离线处理过程,对图像库中的数据库图像提取共生surf特征,在在线处理过程,对待检索图像提取共生surf特征。进一步的,所述的对数据库图像和待检索图像分别检测局部特征的步骤包括:1)在离线处理过程,对于图像库i=(i1,i2,…ii…,in)中的数据库图像ii,提取到的共生surf特征为其中是图像ii中第l组共生surf特征,mi是图像ii中共生surf特征的数量,进而图像库i中提取到的所有共生特征表示为p=(p1,p2,…pi…,pn),其中n为数据库图像的数量;2)在在线处理过程,对于待检索图像,提取到的共生surf特征为其中dr是待检索图像中第r组共生surf特征,nq是待检索图像中共生surf特征的数量。所述的对每幅图像提取共生surf特征是指:在对每幅图像进行局部特征检测时,提取到的共生surf特征由主要特征和附属特征两部分组成,主要特征由快速海森检测子(fasthessiandetector)在图像中检测得到,而附属特征基于主要特征的空间坐标和主方向进行创建。进一步的,对每幅图像提取共生surf特征,包括提取主要特征和附属特征两个步骤,其中:i.主要特征p由快速海森检测子在图像中检测得到,并表示为p(x,y,σ,θ),其中(x,y)为特征p在图像中的空间坐标,σ为特征尺度,θ为特征主方向;ii.在主要特征p的基础上,依次生成多个附属特征。对于第一附属特征p1,从特征p的空间坐标(x,y)出发,沿着主方向θ平移距离nσ,就可以确定特征p1的空间坐标(x1,y1),其中x1和y1分别计算为:x1=x+nσcosθ,y1=y+nσsinθ,为了生成特征p1的描述向量,使特征p1的尺度和主方向与特征p的相同,进而特征p1表示为p1(x1,y1,σ,θ),与特征p1的创建过程类似,剩余的附属特征通过旋转特征p的主方向θ进行创建,设主方向θ旋转的角度为则可以创建的附属特征的总数na为:在生成na个附属特征后,一组共生surf特征表示为所述的分别对数据库图像和待检索图像中提取到的共生surf特征进行量化,生成共生视觉词组是指:对数据库图像中提取到的surf特征进行聚类,基于聚类中心创建视觉词典,分别对数据库图像和待检索图像中的共生surf特征统一量化,将共生surf特征转换为共生视觉词组。进一步的,所述的分别对数据库图像和待检索图像中提取到的共生surf特征进行量化,生成共生视觉词组的步骤包括:i.在离线处理过程,基于图像库中的共生surf特征p=(p1,p2,…pi…,pn),抽取其中全部主要特征,采用近似k-means算法进行聚类,并根据聚类中心创建视觉词典;ii.基于视觉词典将数据库图像ii中的共生surf特征依次量化,表示为共生视觉词组其中vj为图像ii中的共生视觉词组,为主要特征量化后的视觉单词,为第z个附属特征量化后的视觉单词,na为附属特征的数量,k为视觉词典中视觉单词的总数;iii.在在线处理过程,基于视觉词典将待检索图像d中的共生surf特征依次量化,表示为共生视觉词组其中vt为待检索图像d中的共生视觉词组,为主要特征量化后的视觉单词,为第z个附属特征量化后的视觉单词。所述的根据数据库图像中的共生视觉词组创建多维倒排索引,并在倒排索引中利用待检索图像的共生视觉词组进行相似性搜索,查找出候选数据库图像是指:在共生视觉词组的基础上,待检索图像和数据库图像分别表示为共生视觉词组袋的形式,如果图像之间的共生surf特征通过相同的共生视觉词组进行表示,图像之间就确定了空间对应关系,为了快速查找待检索图像和数据库图像之间的空间对应关系,在离线处理过程根据共生视觉词组和数据库图像之间的反向关系创建多维倒排索引,并在在线处理过程利用多维倒排索引进行相似性搜索。进一步的,所述的根据数据库图像中的共生视觉词组创建多维倒排索引,并在倒排索引中利用待检索图像的共生视觉词组进行相似性搜索,查找出候选数据库图像的步骤包括:①在离线处理过程,由于数据库图像ii表示为共生视觉词组袋的形式,可以确定共生视觉词组vj及其所属数据库图像ii的反向关系:vj→ii,由于vj由na+1个视觉单词组成,进而反向关系表示为②基于共生视觉词组vj和数据库图像ii的反向关系,创建多维倒排索引。该倒排索引为词组vj中的每个视觉单词提供一个入口,根据词组vj中视觉单词的个数,需要同时提供na+1个入口,因此多维倒排索引的维数为na+1,然后将词组vj对应的数据库图像ii的编号存储到入口对应的索引列表中,如果相同的共生视觉词组在同一幅数据库图像中出现多次,该数据库图像的编号在对应索引列表中只记录一次,依次遍历数据库图像中每个共生视觉词组,并将图像编号存储在索引列表中,就完成多维倒排索引的创建;③在在线处理过程,基于待检索图像d中的共生视觉词组vt,在多维倒排索引中找到对应的na+1个入口,并根据入口确定相应的索引列表,多维倒排索引为每幅数据库图像提供一个累加器,根据索引列表提供的图像编号,累加器统计数据库图像出现的次数,由于待检索图像和数据库图像在倒排索引中利用入口对应相同的共生视觉词组,因此累加器中图像出现的次数就是待检索图像和数据库图像的空间相似度,当待检索图像d中所有的共生视觉词组在倒排索引中查询完成后,根据累加器记录的空间相似度对数据库图像排序,并返回空间相似度最高的前s幅图像,作为候选数据库图像。所述的在待检索图像和候选数据库图像之间判断主方向一致性,给出最终的图像检索结果是指:共生视觉词组没有涉及共生surf特征包含的主方向,导致包含不同主方向的共生surf特征在量化后可能生成错误的空间对应关系,进而在候选数据库图像中包括错误的检索结果,因此,在待检索图像和候选数据库图像之间采用“假设-验证”的方式判断主方向的一致性,验证图像之间的空间对应关系,精炼候选数据库图像。进一步的,所述的在待检索图像和候选数据库图像之间判断主方向一致性,给出最终的图像检索结果的步骤包括:(a)在待检索图像和候选数据库图像之间,基于共生视觉词组确定空间对应关系其中cw为第w对空间对应关系,nc为空间对应关系的总数,并将c划分为单一空间对应关系cs和多重空间对应关系cm。如果nc≤λ,其中λ为设定的阈值,就认为候选数据库图像和待检索图像之间的空间相似度非常小,在这种情况下,不再验证图像之间的空间对应关系;(b)如果空间对应关系包含的主方向具有一致性,那么不同主方向之间的夹角同样具有相似性。为了计算两个主方向之间的夹角,需要选定计算夹角的参考主方向,为此,从单一空间对应关系cs中随机选取一组,将空间对应关系包含的主方向θq和θc分别看作待检索图像和候选数据库图像的参考主方向,并假设主方向θq和θc具有一致性;(c)为了验证剩余空间对应关系包含的主方向是否一致,基于参考主方向θq和θc,分别在待检索图像和候选数据库图像中计算剩余主方向与参考主方向的夹角和其中aq,j和ac,j分别为待检索图像和候选数据库图像中第j个主方向夹角,并且计算为:aq,j=|θq,j-θq|,ac,j=|θc,j-θc|。为了判断对应的夹角aq,j和ac,j是否具有相似性,二者之间的误差ej计算为:ej=|aq,j-ac,j|,如果误差ej≤η,其中η为设定的阈值,就认为待检索图像中的夹角aq,j相似于候选数据库图像中的夹角ac,j,进而认为两个夹角对应的主方向具有一致性,相应地,主方向所属的空间对应关系为正确的空间对应关系,同时累加正确的空间对应关系的数量np。(d)重复进行步骤(b)和(c),直至达到预先设定的迭代次数tc,由于每次迭代都会统计正确的空间对应关系的数量,经过tc次迭代后正确的空间对应关系的最大值可以看作待检索图像和候选数据库图像的空间相似度,并在验证所有的候选数据库图像后对其重新排序,给出最终的图像检索结果。本发明的有益效果是:本发明在局部特征检测过程中通过创建共生surf特征组织空间关系,使得这一空间关系继承了surf特征的稳健性,从而能够容忍图像之间存在的平移、旋转和尺度变换。通过将共生surf特征量化为共生视觉词组,就能确定图像之间的空间对应关系,进而可以判断待检索图像和数据库图像之间的空间相似度,减少了检索过程中的计算量,提高了检索效率。通过基于共生视觉词组创建的多维倒排索引,可以在海量的数据库图像中快速计算空间相似度,并给出相似的候选数据库图像。通过在待检索图像和候选数据库图像之间判断主方向的一致性,可以精炼候选数据库图像,并给出最终的图像检索结果。与现有技术相比,本发明在保证检索效率的同时,提高了检索准确率。附图说明图1为本发明方法流程图。图2为在杂志图像库和imagenet图像库中比较基于共生surf特征的图像检索方法、视觉词袋模型以及基于几何保存视觉词组的检索方法的准确率。图3为在杂志图像库和imagenet图像库中比较基于共生surf特征的图像检索方法、视觉词袋模型以及基于几何保存视觉词组的方法的检索效率。具体实施方式结合附图和具体实施例,对本发明作进一步说明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所限定的范围。本实施例采用基于共生surf特征的图像检索方法,具体实施步骤如下:1.在数据库图像和待检索图像中分别提取共生surf特征。在离线处理过程,对于图像库i=(i1,i2,…ii…,in)中的数据库图像ii,提取到的共生surf特征为其中是图像ii中第l组共生surf特征,mi是图像ii中共生surf特征的数量,在在线处理过程,对于待检索图像,提取到的共生surf特征为其中dr是待检索图像中第r组共生surf特征,nq是待检索图像中共生surf特征的数量。对于图像中每组共生surf特征,这里只提取第一附属特征,因此由主要特征和第一附属特征两部分组成,主要特征p由快速海森检测子在图像中检测得到,并表示为p(x,y,σ,θ),其中(x,y)为特征p在图像中的空间坐标,σ为特征尺度,θ为特征主方向。对于第一附属特征p1,从特征p的空间坐标(x,y)出发,沿着主方向θ平移距离nσ,这里设定n=1.5,就可以确定特征p1的空间坐标(x1,y1)。为了生成特征p1的描述向量,使特征p1的尺度和主方向与特征p的相同,进而特征p1表示为p1(x1,y1,σ,θ)。2.分别对数据库图像和待检索图像中提取到的共生surf特征进行量化,生成共生视觉词组。在离线处理过程,基于图像库中的共生surf特征p=(p1,p2,…pi…,pn),抽取其中全部主要特征,采用近似k-means算法进行聚类,聚类中心的数量k=50000,并在聚类完成后根据聚类中心创建视觉词典。基于视觉词典将数据库图像ii中的共生surf特征依次量化,表示为共生视觉词组其中vj为图像ii中的共生视觉词组,为主要特征量化后的视觉单词,为第一附属特征量化后的视觉单词。在在线处理过程,基于视觉词典将待检索图像d中的共生surf特征依次量化,表示为共生视觉词组其中vt为待检索图像d中的共生视觉词组,为主要特征量化后的视觉单词,为第一附属特征量化后的视觉单词。3.根据数据库图像中的共生视觉词组创建多维倒排索引,并在倒排索引中利用待检索图像的共生视觉词组进行相似性搜索,查找出候选数据库图像。在离线处理过程,根据共生视觉词组vj及其所属数据库图像ii的反向关系可以确定多维倒排索引的维数为2,多维倒排索引转换为二维倒排索引。根据视觉词典中视觉单词的总数,倒排索引中每一维入口的数量为50000,从而可以提供2.5×109条索引列表。依次遍历数据库图像中每个共生视觉词组,并将图像编号存储在对应的索引列表中。在在线处理过程,基于待检索图像d中的共生视觉词组vt,在多维倒排索引中找到对应的2个入口,并根据入口确定相应的索引列表,根据索引列表提供的图像编号,累加器统计数据库图像出现的次数,作为图像之间的空间相似度,当待检索图像d中所有的共生视觉词组在倒排索引中查询完成后,根据累加器记录的空间相似度对数据库图像排序,并返回空间相似度最高的前10幅图像,作为候选数据库图像。4.在待检索图像和候选数据库图像之间判断主方向一致性,给出最终的图像检索结果。在待检索图像和候选数据库图像之间,基于共生视觉词组确定空间对应关系并将c划分为单一空间对应关系cs和多重空间对应关系cm,从单一空间对应关系cs中随机选取一组,将空间对应关系包含的主方向θq和θc分别看作待检索图像和候选数据库图像的参考主方向,并假设主方向θq和θc具有一致性。基于参考主方向θq和θc,分别在待检索图像和候选数据库图像中计算剩余主方向与参考主方向的夹角和其中aq,j和ac,j分别为待检索图像和候选数据库图像中第j个主方向夹角。接着计算对应的夹角aq,j和ac,j的误差ej=|aq,j-ac,j|,如果ej≤η,其中阈值η=5°,就认为待检索图像中的夹角aq,j相似于候选数据库图像中的夹角ac,j,主方向所属的空间对应关系为正确的空间对应关系,同时累加正确的空间对应关系的数量np,重复进行上述步骤,直至达到预先设定的迭代次数tc=10,经过10次迭代后正确的空间对应关系的最大值可以看作待检索图像和候选数据库图像的空间相似度。在验证所有的候选数据库图像后,给出重新排序后的图像检索结果。对本发明方法仿真实验如下:本实验选取了杂志图像库和imagenet图像库进行了检索测试,其中imagenet图像库主要用来测试检索方法在大规模图像库中的检索性能。表1给出了两个图像库中图像的数量以及提取的共生surf的数量。表1两个图像库的技术指标图像数据库图像数量surf描述子数量杂志图像库7,6656,013,352imagenet图像库100,00079,871,829在图2中,本实验比较了基于共生surf特征的图像检索方法、视觉词袋模型以及基于几何保存视觉词组的检索方法的准确率。当imagenet图像的数量从2万幅增加到10万幅时,虽然三种方法的准确率都会有相应地降低,但是基于共生surf特征的检索方法高于其它两种检索方法。即使在imagenet图像的数量增加到10万幅时,基于共生surf特征的检索准确率仍然高于其它两种方法的准确率。从图2可以看出,基于共生surf特征的检索方法在大规模图像库中保证了检索准确率。在图3中,本实验比较了基于共生surf特征的图像检索方法、视觉词袋模型以及基于几何保存视觉词组的方法的检索效率。当imagenet图像的数量从2万幅增加到10万幅时,虽然三种方法的检索时间都相应地增加,但是基于共生surf特征的检索方法耗费的时间低于其它两种方法的时间。即使在imagenet图像的数量增加到10万幅时,基于共生surf特征的检索时间仍然少于其它两种方法的检索时间。从图3可以看出,基于共生surf特征的检索方法在大规模图像库中保证了检索效率。本实施例中所涉及的算法均在matlab7.7上运行。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1