一种公交线路最高断面客流预测方法与流程
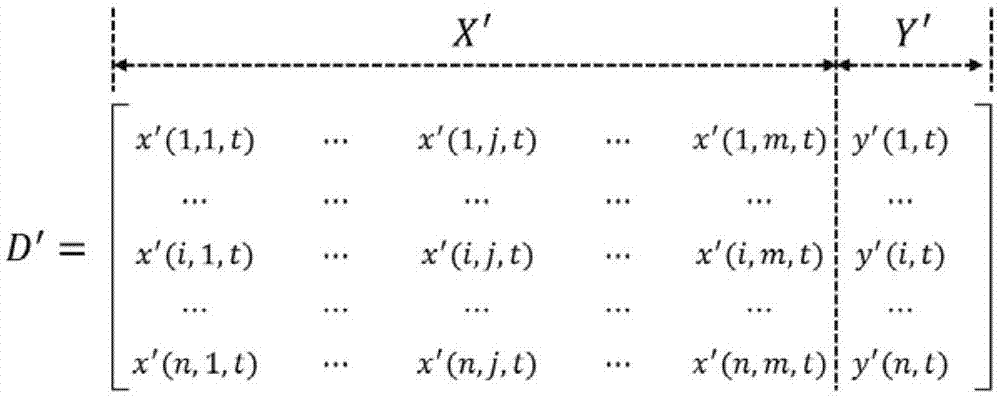
本发明涉及公交运营管理中的客流预测领域,特别涉及基于误差成本和shepard插值的公交线路最高断面客流预测方法。
背景技术:
公交服务的基本目标之一是保证给定时段内的载客量与公交线路沿线上的最大客流量相适应,根据预测时间的跨度,客流预测可分为长期客流预测和短期客流预测,长期客流预测一般服务于公交系统基础设施建设和线路规划等工作,而短期客流预测一般服务于公交运营管理,车辆人员排班等工作。
对于短期公交客流预测问题,目前使用的方法主要分为如下几类:时间序列分析、统计预测、机器学习算法等。但均分别存在缺陷,例如统计学预测方法单纯从数据统计的角度分析客流规律进行预测,其预测质量很大程度上依赖统计数据质量,因而此类方法精度不高,可靠性低。机器学习算法虽然具有较高的预测精度,但均具有模型复杂、参数依赖性大、对训练数据质量依赖性高等缺陷,所以模型稳定性不强,针对不同的模型和应用场景,需要大量的参数寻优工作才能取得可靠的预测模型。
另外,在预测结果评价方面,现有的公交乘客预测精度的评价指标均基于平均误差,如绝对误差和相对误差,然而,公交乘客预测有其特殊性,传统的基于平均误差的评价指标并不一定完全适用于运营调度。经研究在运营调度的层面,线路发车频率设置通常取决于该线路的最高断面客流,而与线路客流总量没有直接关系,在中国专利申请公开说明书(cn106951976a)中已有关于公交客流预测的研究,但仅局限于线路客流总量预测,对最高断面客流预测问题鲜有报道。断面客流量是指在线路中在某一个时间段内,线路某方向的某站点通过的乘客数量,最高断面客流数据不仅可用于计算发车频率,还可用于推荐满载率,在公交规划中具有重要的应用价值。与线路客流总量相比,由于断面客流涉及到沿线客流上车和下车数量分布,其预测将更为复杂且更具不确定性。
如上所述,运营时段的发车车次数取决于最高断面客流的预测值,当一个运营时段的断面客流的预测误差不会导致发车车次数量的变化时,以此预测结果作为公交运力投放的决策依据是可靠的,但是如果某运营时段的断面客流预测误差达不到或者超过计划车辆的运载能力,以此作为公交运力投放将会造成运力不足或者运力浪费的现象,以此造成的运营损失(车次过多或乘客滞留)为此次预测误差造成的成本损失,即误差成本。因此,存在各运营时段乘客量预测结果的平均误差较小但部分时段误差成本过大的情况,也存在平均误差较大但大部分时段误差成本较小的情况。现有技术中大多按照以平均误差最低为目标的传统评价方法,这种方法虽然预测结果较优,但是在以运力与运量相匹配为目标的实际公交运营管理工作中,并不适用。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种公交线路最高断面客流预测方法,此方法具有较高的预测稳定性,因而在以预测误差成本为评价指标的预测模型中表现较优,可为公交线路发车频率设计提供参考。
本发明的目的通过以下的技术方案实现:一种公交线路最高断面客流预测方法,包括以下步骤:
提取公交线路各时段断面客流的影响因子,建立数据空间;
提出基于预测误差成本的评价指标;
以误差成本最小化为目标对数据空间进行参数寻优;
在参数寻优过程中,对目标时段断面客流利用shepard插值算法进行插值预测。
具体的,包括以下步骤:
s1、提取公交线路各时段断面客流的影响因子,对其进行量化与特征工程处理,建立断面客流影响因子组成的多维数据空间,每个时段的最大断面客流量即此数据空间中的数据点;
s2、利用“报童模型”的思想,建立基于预测误差成本的评价指标,该评价指标能综合反映车次冗余成本和因车次不足而造成的乘客滞留成本,可为后续公交发车频率优化提供更为直接的参考;
s3、利用历史数据评价每个影响因子与断面客流之间的影响程度,对每个影响因子进行欧式距离加权,从而量化每个影响因素对预测对象之间的相似性的贡献大小,以此对数据空间进行缩放;引入模型参数b,用以量化预测对象影响因素之间的相似性对目标值影响程度的大小;
s4、在缩放处理后的数据空间中,以历史数据点为观测值,利用基于预测误差成本的评价指标与shepard插值算法相耦合的优化模型对步骤s3中每个欧氏距离权值及其参数b进行寻优确定,然后进行插值预测。利用插值算法进行预测,具有较高的预测稳定性,因而在以预测误差成本为评价指标的预测模型中表现较优,可为公交线路发车频率设计提供参考。
优选的,步骤s1中,根据公交线路各时段断面客流的影响因子,得到每个时段的最大断面客流量,方法是:
s1.1、计算某一时段t内的断面客流量,计算方法是,提取对应时段内发出的所有车次任务,并提取每个车次所搭载的乘客od(起点-终点)信息;
s1.2、计算线路某方向各站点的断面客流,每个方向各站点的断面客流即上车站点为此站点之前(包括此站点)、下车站点为此站点之后(不包括此站点)的所有乘客数量之和;
s1.3、某个方向每个站点断面客流量的最大值即为这个时间段t内该方向的最大断面客流量y(i,t),其中i表示第i个历史记录。
优选的,步骤s3中定义公交线路各时段断面客流的影响因子序列为:{x(i,j,t)|i=1,…,n;j=1,…,m;t=1,…,t};历史时段断面客流量序列为:{y(i,t)|i=1,…,n;t=1,…,t},其中,n为样本个数,m为影响因子个数,x(i,j,t)为第i个样本的第j个影响因子在时段t的量化值,y(i,t)为第i个样本在t时段对应的历史断面客流值。
更进一步的,为消除影响因子的量纲效应,对影响因子进行标准化处理:
其中,e(x(j,t))、s(x(j,t))分别为第j个影响因子在t时段样本序列的均值和标准差。
优选的,步骤s2中在公交线路发车频率和车载容量设计问题中引入“报童模型”的思想,计算误差成本,通过设计合理的配置参数兼顾乘客和运营者的利益。具体计算方法如下:
其中,yi为实际断面客流值;yu-为必要发车车次不变时最低断面乘客数量;yu+为发车车次不变时最高断面乘客数量;yu为单车载客量;n(t)为时段t的发车数量;y(t)为时段t最大断面客流量;fmin为最小发车频率;lt为时段t长度;cp为一个乘客的滞留成本;cm为单位时间等车成本;lt为时段t的期望发车间隔;cb为一个车次的成本,可计算为单位公里车辆运行成本与线路长度之积;cb和cp可分别理解为运力不足和运力过剩的惩罚,相当于“报童模型”中的由于报纸订购数量不足造成的潜在收益损失和数量过剩造成的亏损,实际应用中可以调整参数兼顾乘客和运营者的利益;
更进一步的,对于两站点对向发车的路线,可视为重叠且反向的两条线路,对上行下行的断面客流分别进行预测。
优选的,步骤s3中,令影响因子x(j,t)对目标值y(t)的权重为w(j,t),依次评估候选影响因子与目标值的影响程度的向量w=[w(1,t),…,w(j,t),…,w(m,t)],若w(j,t)越大,第j个影响因子在t时段与目标值的影响程度越大,否则影响程度越小。
计算目标值的影响因子与每个历史值的影响因子之间的加权欧式距离:
其中,di为第i天的影响因子与预测目标的影响因子之间的距离。
优选的,步骤s4中,基于预测误差成本的评价指标与shepard插值算法相耦合的优化模型,其目标函数为:
s.t.1≤b≤10
0≤w(i,j)≤1
该模型中,目标函数为最小化平均预测误差成本;1≤b≤10表示影响因子向量之间的相异度对目标值的影响程度约束;0≤w(i,j)≤1表示每个影响因子的权值对应的权值约束。为了获取最优的参数,本发明利用遗传算法对上述模型进行求解,将w(i,j)设定为决策参数,根据b值的取值不同生成不同的种群,每个种群分别进行进化过程,最终对每个种群的最优个体进行比较,选取最优个体所在种群的b值为最优b值,最优个体的w(i,j)设为最优的欧氏距离权值。通过这种方法,可保证模型的精确性。
优选的,步骤s4中,shepard插值算法是指根据此次预测值的影响因子向量,利用历史n个全局样本点的反距离权重来内插本次预测值。具体计算步骤为:
s4.1、取加权欧式距离倒数的b次方为目标值与历史值之间的反距离权重;公式为:
其中,wdi为第i个历史值的权重;b表示影响因子向量之间的相异度对目标值的影响程度大小,一般为大于1的常数;
s4.2、对所有历史值进行反距离加权累加,计算目标值的预测值,计算公式如下:
其中,
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明从公交运营优化的视角,利用“报童模型”的思想,提出了基于预测误差成本的评价指标,该指标能综合反映车次冗余成本和因车次不足而造成的乘客滞留成本,可为后续公交发车频率优化提供更为直接的参考;
2、本发明在插值算法实现过程中,可以根据实际情况,通过对历史数据的回归拟合调整模型参数,对各影响因子对目标值的影响程度进行寻优;
3、本发明利用插值算法进行预测,具有较高的预测稳定性,奇异值会在大量历史数据加权回归的过程中减弱影响。因而在以预测误差成本为评价指标的预测模型中表现较优,可为公交线路发车频率设置、运力投放、最优满载率提供参考。
附图说明
图1(a)为本发明断面客流影响因子数据集示意图。
图1(b)为各维度的欧氏距离加权(数据空间缩放)过程示意图。
图2为本发明预测误差成本示意图。
图3为本发明数据处理及算法流程图。
图4为广州60路公交运营路线。
图5为本发明各属性与断面客流之间的欧氏距离权重。
图6为本发明成本下降曲线。
图7(a)为本发明模型与其它传统模型预测结果的绝对误差积累图。
图7(b)为本发明模型与其它传统模型预测结果的误差成本积累图。
图8(a)、(b)分别为本发明cb和cp的敏感性分析。
图9为本发明yu的敏感性分析。
具体实施方式
为了更好的理解本发明的技术方案,下面结合附图详细描述本发明提供的实施例,但本发明的实施方式不限于此。
实施例1
1、公交断面客流量影响因子数据空间的建立
一个时段的公交断面客流量受多种因素的影响,包括日期、工作日/节假日、天气、气温等因素,这些多源数据在现有信息条件下不难获得,可以作为短期未来断面客流量预测的有效依据。在插值模型中,各影响因子必须量化为有效的模型参数,以参与模型的建立和预测过程,为此,本发明利用特征工程的概念[murphykp.machinelearning:aprobabilisticperspective[m].mitpress,2012.],将研究对象的影响因子抽象量化为多维矢量,并通过标准化处理去除量纲效应。
定义样本影响因子序列为:{x(i,j,t)|i=1,…,n;j=1,…,m;t=1,…,t};历史时段断面客流量序列为:{y(i,t)|i=1,…,n;t=1,…,t},其中,n为样本个数,m为影响因子个数,x(i,j,t)为第i个样本的第j个影响因子在时段t的量化值,y(i,t)为第i个样本在t时段对应的历史断面客流值。客流受季节影响较大,所以本发明第一个属性因子赋值为一年中的第几周,用x1表示;工作日/节假日属性是影响客流和客流分布的一大因素,将工作日属性赋值为0,假日属性赋值为1,用x2表示;气温对客流的时间分布和非刚需客流的断面客流量有一定的影响,根据研究时间和研究区域实地情况,气温取值范围为0~40℃,用x3表示。降雨天气对非刚需客流和客流的时间分布有一定的影响,本发明将降雨天气赋值为1,非降雨天气赋值为0,用x4表示。断面客流量在一周内具有周期性的波动规律,本发明赋值1~7对应相应日期的星期属性,用x5表示。空气质量对乘客出行可能有一定的影响,赋值为当天的空气质量指数,用x6表示。各影响因子选取及其取值如表1所示。
为消除影响因子的量纲效应,首先对影响因子进行标准化处理:
其中e(x(j,t)),s(x(j,t))分别为第j个影响因子在t时段样本序列的均值和标准差。
表1影响因子的选取与取值
插值算法的逻辑基础为影响因子相似则目标值相近。上述模型中,x两个矢量之间距离越相近,则其分别对应的目标值y之间越倾向于相近。但x中每个维度的值对距离的贡献是不同的,如热点通勤线路中早晚高峰时段的断面客流量受工作日/节假日的影响远大于降雨的影响,如x2与x4的权重相同,则两矢量之间的欧式距离与目标值之间的差异很可能不成正比,以此数据为基础的插值预测算法也是不准确的,所以有必要按照对距离的贡献程度的不同对各个维度赋予相应的权重,即加权欧氏距离,此过程也可以视为对数据空间的缩放,即对数据空间的每个维度的量纲进行缩小或放大,目的是使在数据空间中距离相近的点其数值也更趋于接近。在本例中,工作日节假日性质的权重明显应该大于降雨的权重。因此,本发明在评价x之间的距离时采用加权欧氏距离,利用历史数据建立优化模型,对每个维度的权重进行寻优,具体模型见下面第2.2小节说明。
令影响因子x(j,t)对目标值y(t)的权重为w(j,t),依次评估候选影响因子与目标值的影响程度的向量w=[w(1,t),…,w(j,t),…,w(m,t)],若w(j,t)越大,第j个影响因子在t时段与目标值的影响程度越大,否则影响程度越小。图1(b)为欧氏距离加权的示意图,其中x′为影响因子矩阵,y′为断面客流量矩阵,w为欧式距离权矩阵,d′为原始的影响因子及其对应断面客流量的矩阵,如图1(a)所示。dw′为加权后的影响因子及其对应断面客流量的矩阵。加权过程即对x′行的影响因子矢量与w的值对应相乘,即实现了影响因子组成的数据空间中每个维度的欧氏距离加权,以及对数据空间每个维度的数值进行缩小或放大,w的取值可以使在数据空间中x之间欧氏距离相近的数据点其目标值y也更趋于接近。w的寻优过程详见下面第3小节说明。
2、基于误差成本的预测结果评价指标
2.1、报童模型思想引入
传统的预测问题研究中,对预测结果的评估一般利用基于误差的指标进行评价,如平均绝对误差(mae),平均绝对百分比误差(mape)等。基于误差的评价指标越小,则预测结果与实际值之间的平均偏离程度越小,说明预测模型越准确。然而,与传统的数值预测问题不同,公交断面客流预测问题有其特殊性,不能简单抽象为数值预测问题。
在实际运营中,线路发车频率的设置一般根据最大断面客流的预测值[ceder,a.publictransitplanningandoperation:theory,modellingandpractice[m].elsevier,2007],因此,实际值与预测值之间的偏差会造成车次过多或车次过少。例如,当最大断面客流预测值为500,单车载客量为50时,计划最优的发车车次数为10车次,若此时真实值为550,则有50人会滞留因而会增加等车成本;若此时预测值为450,最优发车车次数为9车次,此时多发一个车次,带来了多发一个车次的运营成本。这两种情况下,虽然乘客量预测的绝对误差相等(均为50人),但带来的运营成本的损失是不同的,且与单车载客量、等车时间成本、发车间隔、车次成本等运营参数密切相关。由于车次过多和车次过少造成的运营成本损失是不同的,如果能设计合理的算法,使预测误差沿着损失较少的方向偏移,则能有效降低运营成本损失。
上述的最大断面客流预测问题可以类比为报童问题。报童问题可描述为在给定报纸售价、成本和退回价的情况下,确定报童每天需要购进报纸数量使收入最大化。由于需求是随机的,购进太多可能会卖不完,从而赔钱;购进太少可能导致报纸不够销售从而减少收入。因此,存在一个最优的购进量使收入最大化。报童模型已在供应链库存管理、航空和酒店服务预定领域有所应用。文献[khoujam.,thesingle-period(news-vendor)problem:literaturereviewandsuggestionsforfutureresearch[j].omega,1999,27(5),537-553]系统总结了单周期报童模型及其拓展研究。最近,文献[herbona.,hadas,y.determiningoptimalfrequencyandvehiclecapacityforpublictransitroutes:ageneralizednewsvendormodel[j].transportationresearchpartb,2015,71,85-99.]在公交线路发车频率和车载容量设计问题引入报童模型的思想,通过设计合理的配置参数兼顾乘客和运营者的利益。受文献[herbona.,hadas,y.determiningoptimalfrequencyandvehiclecapacityforpublictransitroutes:ageneralizednewsvendormodel[j].transportationresearchpartb,2015,71,85-99.]的启发,本发明利用报童模型的思想,提出一种新的预测结果评价指标,该指标能有效权衡预测结果对车辆调度的影响。
2.2、基于误差成本的预测结果评价指标
对于公交线路某个发车方向,一个时段的发车量由最大断面客流决定。在给定车型的情况下,相应时段的最小发车车次数必须保证能够满足线路的最大断面客流需求,同时满足最小发车频率的需求。在保证最小发车频率的情况下,某时段内的最大断面客流与单车载客容量之比为该时间窗内的发车车次。具体计算方法如下:
其中n(t)为时段t的发车数量,y(t)为时段t最大断面客流量,yu为单车载客量,fmin为最小发车频率,lt为时段t长度。
基于“报童模型”的思想,如果一个时段的断面客流预测误差导致最优的发车车次数的改变,则会在调度层面出现运力不足或者运力浪费的现象,当运力不足时,则会产生乘客滞留从而影响服务水平;当运力过剩时,则会增加运营成本;出现这些情况都会产生无效的预测误差成本,而传统基于绝对误差或相对误差的评价指标无法反映每次预测的误差成本。
有鉴于此,本发明提出基于预测误差成本的评价准则,定义预测误差成本为运力过剩造成的冗余车次成本和运力不足引起的乘客滞留成本损失。
图2为预测误差成本的示意图,其中横轴为以一小时为长度的时段断面客流值,纵轴为时段发车车次,图中曲线为以yu=80,fm=6时的发车车次数量随断面客流的变化曲线,yi为实际断面客流值,预测值在阴影部分时,根据断面客流预测值确定的发车车次不变,此次预测值的预测在车辆调度层面是可靠的,即无成本损失。当预测值
其中,yi为实际断面客流值,cei表示第i个预测值的预测误差成本;
3、shepard插值算法及其参数优化
为了保证误差成本在一定范围内稳定,对预测模型的稳定性和精确性均提出了较高的要求。插值预测方法利用影响因子相似则目标值相近的原理,按照影响因子的相似性对历史数据进行加权回归获取预测值,除精确度较高的优点外,相比于时间序列分析、统计预测、机器学习算法等其他预测方法具有较高的稳定性,奇异值会在大量历史数据加权回归的过程中减弱影响。根据插值预测理论,在较小的参数区间内,断面客流与其影响因子之间的相关关系可利用简单近似函数对未知观测点数据进行插值预测。在实际的断面客流预测问题中,影响因子越相似的时段,断面客流量越趋向于相近。基于插值预测理论和实践经验,本发明提出基于shepard插值算法的断面客流预测方法。shepard算法(即全局距离加权近邻算法)是一种相似预测法,基于相近相似的原理,若两个对象影响因子相近,则目标值相近;反之,影响因子相似性越小,目标值相差越大。在断面客流预测问题中,日期属性之间的相似性越高,则断面客流状态越相近。此预测算法以预测点与历史点之间的日期属性相似性为权重进行加权回归插值,与预测点越相似则赋予的权重越大[张峰,吕震宙,赵新攀.基于序列shepard插值的结构可靠性分析[j].机械工程学报.2010,46(10):176-181.]。
shepard算法使用条件有两条:1.预测因子与目标值之间的相关性在统计上是显著的。2.预测因子与目标值之间的历史样本集应具有足够的代表性。针对条件1,本发明通过建立优化模型的方法,精确评价了每个预测因子与目标值之间影响程度的大小,针对条件2,现代公交系统利用ic卡进行公交收费较为普及,以本发明实验线路为例,每日ic刷卡乘客量占总乘客量达90%,可以较完整的反映线路断面客流信息。并且ic刷卡数据收集长时间跨度,细时间粒度,特定线路的断面客流历史信息,具有很高的代表性。
shepard预测的基本思想是:根据此次预测值的影响因子向量,利用历史n个全局样本点的反距离权重来内插本次预测值。具体计算步骤为:
1)计算目标值的影响因子与每个历史值的影响因子之间的加权欧式距离;
2)取加权欧式距离倒数的b次方为目标值与历史值之间的反距离权重;
3)对所有历史值进行反距离加权累加,计算目标值的预测值。
具体计算方法如下所示:
其中di为第i天的影响因子与预测目标的影响因子之间的距离,wdi为第i个历史值的权重,b表示影响因子向量之间的相异度对目标值的影响程度大小,一般为大于1的常数。
建立shepard模型的关键在于根据历史数据确定模型参数b的最优值,b值过低则远距离历史值的权重过大,拟合曲面平坦,插值精度不足;b值过高则近距离历史值的权重过大,预测值趋向于与最接近的历史值相等,拟合曲面粗糙,出现过拟合现象。根据文献[金菊良,魏一鸣,丁晶等.年径流预测的shepard插值模型[j].长江科学院院报.2002,19(1):52-55.],b的经验取值范围为1~10。w=[w(1,t),…w(j,t),…,w(m,t)]决定了各个影响因子对目标值的影响程度,对模型的表现影响较大。为保证模型的精确度,本发明利用训练数据单个交叉验证的方法,即利用除第i个值之外的其它值对第i个值进行插值预测,以此对b值和wt建立优化模型寻找最优解。
将本发明提出的基于预测误差成本的指标与shepard插值算法相耦合,得到如下优化模型:
s.t.1≤b≤10
0≤w(i,j)≤1
目标函数为最小化平均预测误差成本;1≤b≤10表示影响因子向量之间的相异度对目标值的影响程度约束;0≤w(i,j)≤1表示每个影响因子的权值约束对应的权值约束。为了获取最优的参数,本发明利用遗传算法对上述模型进行求解,将w设定为决策参数,根据b值的取值不同生成不同的种群,每个种群分别进行进化过程,最终对每个种群的最优个体进行比较,选取最优个体所在种群的b值为最优b值,最优个体的w设为最优的欧氏距离权取值。
4、数据处理流程
图3为本发明数据处理及算法流程图,具体步骤如下:
1)用ic刷卡数据,获取每个乘客的刷卡时间和刷卡车次;用车辆运营数据,获取每个车次的发车时间。
2)用刷卡数据计算断面客流量。断面客流量是指在线路中在某一个时间段内,线路某方向的某站点通过的乘客数量,而最大断面客流是该线路方向所有站点断面客流量的最大值,具体步骤为:
i.提取该时间窗内发出的所有车次任务。提取每个车次所搭载的乘客od信息。由于乘客ic刷卡数据不包含下车站点信息,为此,本发明利用文献[liuz,yany,qux,etal.busstop-skippingschemewithrandomtraveltime[j].transportationresearchpartc,2013,35(9):46-56.chenj,liuz,zhus,etal.designoflimited-stopbusservicewithcapacityconstraintandstochastictraveltime[j].transportationresearchparte,2015,83:1-15.]的od反推技术获取断面客流的od矩阵。
ii.计算线路某方向各站点的断面客流。每个方向各站点的断面客流即上车站点为此站点之前(包括此站点)、下车站点为此站点之后(不包括此站点)的所有乘客数量之和。
iii.某个方向每个站点断面客流量的最大值即为这个时间段t内该方向的最大断面客流量y(i,t)。其中i表示第i个历史记录。
iv.利用上述方法可获取每个时段最大断面客流数据集。
3)将断面客流量统计数据集和影响因子数据集按照时间进行连接,获取训练数据集d’(详见表1)。训练数据集中的影响因子均进行量化,用以在插值预测模型中建立插值空间。
4)选取一时间点,将时间点之前的数据集设定为训练数据集,时间点之后的数据集设定为测试数据集。
5)利用训练数据集对预测模型进行训练,并用测试数据集对预测模型进行测试,获取预测结果的评价指标。
这套训练数据集同时作为对比实验模型中的训练数据。模型预测结果为每个目标日期每个目标时段的乘客量,最后对乘客量预测结果进行评价。需要注意的是,断面客流预测的精确度与断面客流下车概率有关,下车概率可通过实际调查获取,也可通过一定的方法进行推算,而这方面已有较多的研究,并不是本发明的研究重点,可直接借鉴客流下车概率模型(如文献[liuz,yany,qux,etal.busstop-skippingschemewithrandomtraveltime[j].transportationresearchpartc,2013,35(9):46-56.chenj,liuz,zhus,etal.designoflimited-stopbusservicewithcapacityconstraintandstochastictraveltime[j].transportationresearchparte,2015,83:1-15.])或公交od反推模型,本发明使用文献[liuz,yany,qux,etal.busstop-skippingschemewithrandomtraveltime[j].transportationresearchpartc,2013,35(9):46-56.chenj,liuz,zhus,etal.designoflimited-stopbusservicewithcapacityconstraintandstochastictraveltime[j].transportationresearchparte,2015,83:1-15.]的推导方法,在实际应用时可根据具体情况选取不同方法,不影响本发明模型的普适性。
5、应用实例
为验证本发明方法的有效性,本发明选取广州市60路2017年10月1日至2017年12月31日每天6点至22点每一小时时段的客流统计数据为例,利用所提出的模型,预测2017年12月1日至2014年12月31日的分时段最高断面客流。运营参数取值参考文献[巫威眺,靳文舟,任然.单线公交车辆组合调度与购车计划的双层规划模型[j].吉林大学学报(工学版),2013,43(5):1196-1203.]的研究结果,cb的取值范围为60~120元/车次,cp的取值范围为5~15元/小时,单车最大载客量yu的取值范围为50~150pax/veh。60路运营路线如图4所示,共有21个站点,线路全长16.3公里,终点站为机场路总站和奥林匹克体育中心总站,途经广州市天河区、越秀区和白云区,沿途经过居住区、商业区、重要交通枢纽、医院学校等城市功能区,客流组成和交通状态复杂。该公交线所有运营车辆均配备有gps设备并完整记录运营数据,数据完备性好,准确性高,线路乘客刷卡率达90%,ic卡刷卡数据能较完整地反映客流时空分布等本发明方法所需信息。本发明所研究的方向为从机场路总站出发所在的方向。
5.1、欧式距离权重的优化结果
由于出行目的多样性和客流结构的复杂性,各影响因子对特定的线路断面客流在不同时段的影响程度是不同的。为此,本发明利用遗传算法优化每个时段各属性对目标值的欧式距离的权重,此权重可视为各影响因子对断面客流量的影响程度,权值越大,则影响程度越大,获取的最优解如图5所示。观察可知,在早高峰时期(6时至8时),影响程度较大的因素为工作日/节假日因素,另外星期和天/年因素也有较大影响,这是因为早高峰客流多为通勤客流,受节假日影响较大,但在长时间跨度内,客流具有季节性的变化,所以工作日/节假日因素是决定性因子,星期和天/年是次要影响因子,其它影响因子影响力较小。在上午至中午的平峰时段(9时至13时)许多影响因子都对断面客流有较大的影响,这是因为这个时段内客流组成复杂,出行目的多样,断面客流总量易受多种因素的影响。14时至15时的断面客流受星期属性影响较大,说明这些时段内的断面客流在一周内呈现明显的周期性变化,而对其它的影响因子都不敏感,但是在16时时段,气温对断面客流的影响明显增大,其原因是高温在午平峰时段对非刚需断面客流的影响较大。在晚高峰时期17时至18时与早高峰时期相似,不同之处在于晚高峰时期有更大的季节波动。19时至23时影响因子对断面客流的影响比较复杂,原因在于此时间段的断面客流组成的复杂程度和出行目的的多样性是一天中的最大,各影响因子都会对断面客流量造成一定的影响。
5.2、时段最优b值及其寻优过程
本发明根据b值的不同建立了不同的种群,每个种群独自进化,取每个种群的最优解为局部最优解,最终对各种群的局部最优解进行选优,获取全局最优解。遗传算法参数种群大小设为200,交叉概率设为0.6,变异概率设为0.2,最大进化代数设为200。图6展示了单车最大载客量yu设置为100时,给定最优b值的各个时段成本下降曲线。观察可知,在早晚高峰时期的典型时段,这些时段受工作日/节假日的影响较大,其它因素的影响较小,进化过程中收敛迅速,在进化100代之前接近收敛。10时和22时是典型的断面客流组成复杂程度和出行多样性都较大的时段,有效的影响因子较多且影响关系复杂,进化过程收敛速度较慢,在100代之后接近收敛。
图6展示了一天中不同时段的最优b值,该值越大说明随着影响因子距离的减少,距离近的数据点对目标时段预测值的参考意义的增加程度越大;而该值越小说明随着影响因子距离的减少,距离近的数据点对目标时段的预测值的参考意义的增加程度越小。从图中可以看出,早晚高峰的断面客流在短期内稳定,在长期内变化,其他影响因子影响程度较小,所以b值一般较大;而午平峰长期稳定,干扰因素少,所以b值取值较小;其他时段的影响因子多且关系复杂,所以b值的取值多样化。
5.3、模型对比与分析
为检验本发明所提出算法的有效性,本发明利用相同的训练和测试数据集,对不同的预测模型进行训练与测试,模型算法均使用网格法对各模型参数进行优化[murphykp.machinelearning:aprobabilisticperspective[m].mitpress,2012.],即在各个模型参数可行取值范围内,对数值进行等距取值,然后列出所有可能的模型参数组合,生成模型参数网格,在此模型参数网格中选取最优的模型参数组合,此方法可在可控的时间内选取较优的模型参数组合,参数寻优效率较高。具体参数及平均绝对误差见表2,可见本发明算法稳定性较强(绝对误差标准差较小)。
表2实验模型参数
图7(a)为本发明模型与其它传统模型预测结果的绝对误差积累图,图7(b)为本发明模型与其它传统模型预测结果的误差成本积累图。通过观察图7(a),可以发现本发明模型的预测误差大左侧拖尾较小,右侧拖尾较大,本发明模型的误差分布曲线相对于其它模型的误差分布曲线明显右移,说明正误差较多而负误差较少。从图7(b)可以看出,在引入预测误差成本的概念之后,shepard插值算法的预测误差成本比其它模型更小,其原因是由于单车载客量yu设定为50,大部分无误差成本的预测结果的误差处在-50~50区间内,这些结果虽有预测误差但无运营成本损失,误差在这范围内的预测结果占绝大多数,有效降低了运营成本损失。
在预测误差为较大的正值时,会发生实际发车车次数超过乘客需求的现象,产生了多发车次的成本,误差成本呈阶梯状增长。预测误差为较小的负值时,会发生乘客滞留现象,带来额外的乘客等车时间成本,误差成本呈线性增长,并根据实际的发车间隔有不同的增长速度。模型会根据实际情况决定相应时段预测值的左右偏移,以整体上减少预测误差带来的成本损失。本算例图7(a)中,预测误差整体向右偏移,说明模型偏向于尽量减少等车时间成本的快速增长,合理的多发车次以降低运营成本损失,使得误差积累曲线向右边偏移。从图7(b)可以看出,与其它模型相比,本发明模型的误差成本明显集中在成本较少的区间内,这是因为模型会在等车时间成本与发车成本之间权衡,使得预测误差向成本增长速度较小的方向偏移。本发明模型70%以上的预测误差成本保持在60元以下,积累曲线在横轴60处有明显的纵向跃升,这是因为预测误差在60时的误差成本均为多发一个车次的成本60元,导致了累积曲线在横轴为60元处的纵向跃升;而在120元处的纵向跃升不明显,是因为模型精度较高,极少数的预测误差成本达到两个车次,即120元及以上。
基于预测误差的模型优化过程对精确度和稳定性均具有较高的要求,从预测结果来看,预测误差累积曲线整体向右偏移,插值方法以历史最高断面客流量记录为参考点,以影响因子的反距离值为权重,对目标预测值进行加权回归预测,具有很强的稳定性,并且可以通过对各影响因子的欧氏距离权的控制(模型优化过程),使得预测结果的分布向预测误差成本减小的方向偏移,因此,插值预测方法适用于基于误差成本为评价方式的公交最高断面客流预测。传统的预测方法模型参数的优化目的,均为预测结果平均绝对误差的降低,忽略了对误差值的内部组成结构的深入评估分析。本发明结合断面客流和发车频率的计算方法,将绝对误差换算为最高断面客流量预测误差造成的公交运营成本损失,以此为目的进行模型参数优化,虽然模型在平均绝对误差上优势不大(见表2),但预测结果的稳定性有所提高,且其造成的公交运营成本损失较传统方法大大降低,因此预测结果对公交运营计划的制定更加具有参考意义。
图8(a)、(b)展示了模型参数车次成本cb和乘客滞留成本cp的敏感性分析结果,根据车型、车辆耗油量、司乘人员成本、线路长度等因素每条线路的车次成本cb是不同的,cb和cp也可分别理解为对运力不足和运力过剩的惩罚,实际应用中可以调整参数兼顾乘客和运营者的利益。图8(a)展示了cp=5元/小时,不同cb取值时的断面客流量误差成本累积概率图,可见误差成本累积图在cb的整数倍取值处有纵向的跃升,且随着误差成本的增长跃升幅度显著减少,其原因与图7(b)所分析之原因相同,即本发明模型的误差成本集中在预测误差成本较少的区间内,预测误差在cb时的误差成本均为多发一个车次的成本cb元,在cb处有明显跃升,而在cb大于1的整数倍处的纵向跃升不明显,是因为模型精度较高,极少数的预测误差成本达到cb大于1的整数倍处,在cb的整数倍之间,主要会因为等车时间成本带来的误差成本的增加而增加。
图8(b)展示了cb取值60元时,不同cp取值时的断面客流量误差成本累积概率图,可见累积概率曲线的跃升还是出现在cb的整数倍取值处,不同的是在cb的整数倍取值处之间,误差成本的累积概率随着cp的增加而减小,其原因是在其它成本不变的情况下,cp的增加会总体上增加等车带来的误差成本。
图9展示了cb=60,cp=5时单车载客量参数yu的敏感性分析结果,可见随着单车载客量增加,预测误差成本的分布明显趋向于降低。当单车载客量由50增加至150时,误差成本为0的预测结果由56%增长到82%,误差成本为cb的预测结果由92%增长到96%,说明增大单车载客量可降低预测误差。其原因是较大的单车载客量对预测误差有较大的容忍度,即最高断面客流量预测误差有较小的可能性影响发车的车次数,从而减少预测误差带来的成本损失。
传统的乘客量预测方法将乘客量抽象为数值型的时间序列,追求的预测目标为整体的误差偏差最小,但在实际运营中,不同的误差组成结构(如误差的正负以及绝对值的大小)和具体的发车间隔、车次成本、乘客等待时间、车型大小等因素共同决定了预测误差所带来的运营损失成本。从公交运营者的视角,针对公交最高断面客流量预测问题,不必过分追求预测的准确度,而应在现有的运营条件约束下,追求预测的不确定性所带来的运营成本损失最小,如在高峰期车次较多,发车间隔小,等车成本的增长速度较低,可以合理地降低车次以减少发车成本;低峰期车次较少,发车间隔大,等车成本的增长速度较高,多发车次带来的等车成本的减少较为明显,这之间的成本增长利用传统评价方式和预测模型难以进行权衡。本发明模型以历史断面客流量为基础,以现有运营条件为约束,以减少运营成本损失为目标,对乘客量进行预测,相比于单纯的乘客量数值预测更加具有参考意义。
上述实施例为本实施例较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!