联邦建模方法、设备及存储介质与流程
本发明涉及联邦学习技术领域,尤其涉及一种联邦建模方法、设备及存储介质。
背景技术
现有的联邦建模方法一般应用于联邦建模双方的重叠样本上,而现实中很多场景都是联邦建模双方的重叠样本较少,而非重叠样本较多,但是现有的联邦建模方法无法在不泄露双方样本隐私的情况下,应用联邦建模双方的非重叠样本进行模型训练或进行结果预测,导致联邦建模的应用范围较小。
技术实现要素:
本发明提供一种联邦建模方法、设备及存储介质,旨在解决联邦建模的应用范围较小的问题。
为实现上述目的,本发明提供一种联邦建模方法,所述方法包括:
输入第一训练样本和第二训练样本,所述第一训练样本包括第一训练样本id和第一训练样本特征,所述第二训练样本包括第二训练样本id、第二训练样本特征以及样本标签;
基于极端梯度提升xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;
根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。
可选地,所述输入第一训练样本和第二训练样本的步骤之前还包括:
获取第一方样本和第二方样本,所述第一方样本由联邦建模的第一方提供,所述第二方样本由联邦建模的第二方提供;
对所述第一方样本和所述第二方样本进行筛选,获取第一训练样本和第二训练样本。
可选地,所述对所述第一方样本和所述第二方样本进行筛选的步骤包括:
筛选所述第一方样本与所述第二方样本中的重叠样本和非重叠样本,将所述第一方样本和所述第二方样本分为第一方重叠样本、第二方重叠样本、第一方非重叠样本、第二方非重叠样本以及第一方缺失样本;
将所述第一方重叠样本和所述第一方缺失样本作为第一训练样本,将所述第二重叠样本和所述第二方非重叠样本作为第二训练样本。
可选地,所述输入第一训练样本和第二训练样本的步骤之后还包括:
对齐所述第一训练样本和所述第二训练样本。
可选地,所述第一方和所述第二方各自拥有服务器,所述基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型的步骤包括:
在模型训练的迭代过程中,所述第二方基于当前决策树模型和样本标签计算所述第二训练样本的梯度,并根据加密算法对所述梯度进行加密,将加密后的梯度发送至第一方,由所述第一方根据加密后的梯度计算所述第一训练样本在当前决策树模型中所有分割点的第一收益,将所述第一收益返回至第二方;
所述第二方接收并解密所述第一收益,并结合第二训练样本的第二收益确定全局最佳分割点;
保存所述全局最佳分割点的具体信息;
根据所述全局最佳分割点对当前节点的样本进行分割,生成新的节点
直到达到预设停止条件,则停止所述迭代过程,得到完整的决策树预测模型。
可选地,所述保存所述全局最佳分割点的具体信息的步骤包括:
判断所述全局最佳分割点对应的特征是归属于第一方还是第二方;
若所述全局最佳分割点对应的特征归属于第一方,则将所述全局最佳分割点的具体信息存储在第一方;
若所述全局最佳分割点对应的特征归属于第二方,则将所述全局最佳分割点的具体信息存储在第二方。
可选地,所述根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测的步骤包括:
在所述联邦建模的决策树预测模型中输入待预测样本;
基于预设的样本标签预测方法计算所述第一方决策树预测模型中每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心;
根据所述每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心、叶子节点向量及待预测样本计算每个叶子节点对应的待预测样本的权重;
获取使所述权重取最小值时对应的叶子节点;
所述叶子节点函数最小值对应的叶子节点在决策树中的结果即为预测结果。
可选地,所述根据所述决策树预测模型和预设样本标签预测方法对待预测样本进行预测的步骤之后还包括:
输出预测结果。
本发明还提出一种联邦建模设备,所述设备包括存储器、处理器以及存储在所述存储器上的联邦建模程序,所述程序被处理器执行时实现如上所述的联邦建模方法的步骤。
本发明还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有联邦建模程序,所述联邦建模程序被处理器运行时实现如上所述的联邦建模方法的步骤。
相比现有技术本发明提出的一种联邦建模方法、设备及存储介质,输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型,由所述联邦建模的第一方将所述决策树预测模型保存为第一方决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此,拓展了联邦建模的应用范围。
附图说明
图1是本发明联邦建模方法第一实施例的流程示意图;
图2是本发明联邦建模方法第二实施例的流程示意图;
图3是本发明联邦建模方法一实施例的场景示意图;
图4是本发明联邦建模方法第三实施例的流程示意图;
图5是本发明联邦建模方法另一实施例的场景示意图;
图6是本发明联邦建模方法第四实施例的流程示意图;
图7是本发明实施例方案涉及的联邦建模设备结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例的主要解决方案是:输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此,拓展了联邦建模的应用范围。
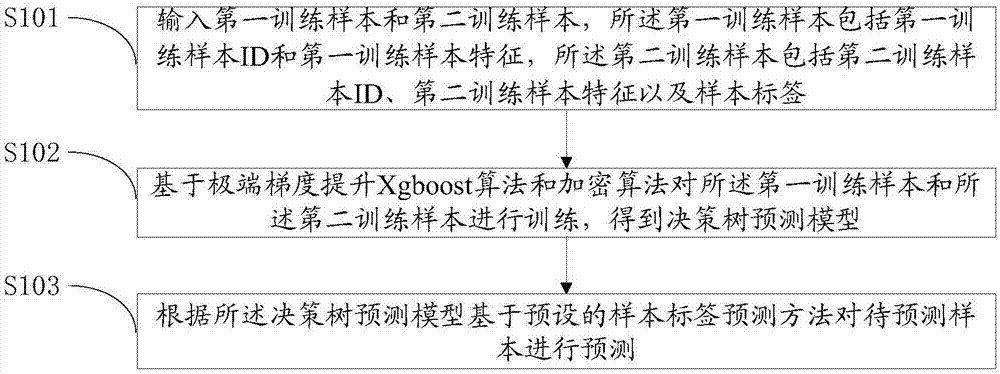
本发明实施例提出了一种联邦建模方法,具体地,参照图1,图1是本发明联邦建模方法第一实施例的流程示意图。
现有的联邦建模方法一般应用于联邦双方共同的样本上,而现实中很多实用场景都是联邦双方的共同样本少,单独拥有的样本多,而现有的联邦建模方法无法预测样本标签缺失方的待预测样本。考虑到上述问题,本发明实施例提供一种联邦建模方法,所示方法包括:
步骤s101,输入第一训练样本和第二训练样本,所述第一训练样本包括第一训练样本id和第一训练样本特征,所述第二训练样本包括第二训练样本id、第二训练样本特征以及样本标签;
本实施例中,由联帮建模的第一方和联帮建模的第二方共同参与,其中,所述联帮建模的第一方通过第一方服务器输入第一方训练样本,所述联帮建模的第二方通过第二方服务器输入第二方训练样本。所述第一训练样本包括第一训练样本id和第一训练样本特征,所述第二训练样本包括第二训练样本id、第二训练样本特征以及样本标签。所述训练样本特征包括年龄、性别、收入水平、贷款情况、消费信息、受教育程度等,所述样本标签包括收入水平、贷款情况、消费信息、游戏爱好程度等。
步骤s102,基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;
极端梯度提升(extremegradientboosting,xgboost)算法是一种机器学习算法,具有速度快、效果好、能处理大规模数据、支持多种语言、支持自定义损失函数等优点。在本实施例中支持同态加密算法,同态加密是基于数学难题的计算复杂性理论的密码学技术。对经过同态加密的数据进行处理得到输出结果,将所述输出结果进行解密,其解密结果与未加密的原始数据的一致。
本实施例中,所述第一方样本归属于第一方,所述第二方样本归属于第二方,所述第一方和所述第二方各自拥有服务器,所述基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型的步骤包括:在模型训练的迭代过程中,所述第二方基于当前决策树模型和样本标签计算所述第二训练样本的梯度,并根据加密算法对所述梯度进行加密,将加密后的梯度发送至第一方;由所述第一方解密所述加密后的梯度并根据解密后的梯度计算所述第一训练样本在当前决策树模型中所有分割点的第一收益,将所述第一收益返回至第二方;所述第二方接收并解密所述第一收益,并结合第二训练样本的第二收益确定全局最佳分割点;保存所述全局最佳分割点的具体信息;根据所述全局最佳分割点对当前节点的样本进行分割,生成新的节点;直到达到预设停止条件,则停止所述迭代过程,得到完整的决策树预测模型。
具体地,决策树模型训练过程基于xgboost算法,采用本地计算和通信加密机制。由所述第一方对所述第一训练样本的样本特征进行编码,由所述第二方对所述第二训练样本的样本特征进行编码。本实施例中,用eaf(i)表示所述第一方对第一训练样本中样本的第i特征的编码,用ebf(i)表示所述第二方对第二训练样本中样本的第i特征的编码。在模型训练的迭代过程中,首先由所述第二方基于当前决策树模型和样本标签计算所述第二训练样本的一阶梯度和二阶梯度,并根据加密算法对所述一阶梯度和所述二阶梯度进行加密,并将加密后的一阶梯度和二阶梯度发送给第一方。所述第一方通过与第二方相同的加密算法对所述加密后的一阶梯度和二阶梯度进行解密,得倒解密后的一阶梯度和二阶梯度后,再基于当前决策树模型计算第一训练样本中所有可能的分割点的第一收益,并将计算所得的所述第一收益返回至第二方。所述第二方接收并解密所述第一收益,并结合第二训练样本的第二收益确定决策树模型每个节点的全局最佳分割点;保存所述全局最佳分割点的具体信息;根据所述全局最佳分割点对当前节点的样本进行分割,生成新的节点;直到达到预设停止条件,则停止所述迭代过程,得到完整的决策树预测模型。在本实施例中,所述预设停止条件包括预设深度、新的节点的收益阈值等,当所述决策树到达预测深度时或新的节点的收益小于阈值,则停止所述迭代过程。由此,所述第一方和所述第二方通信的数据都是加密后的加密数据,而对应训练样本的原始数据不会泄露。本实施例中,决策树预测模型的训练过程可采用部分同态加密算法,并支持加法同态加密算法。由此通过加密算法由样本拥有方在本地对样本信息进行加密,因而不会泄露样本隐私。
本实施例中,所述保存所述全局最佳分割点的具体信息的步骤包括:判断所述全局最佳分割点对应的特征是归属于第一方还是第二方;若所述全局最佳分割点对应的特征归属于第一方,则将所述全局最佳分割点的具体信息存储在第一方;若所述全局最佳分割点对应的特征归属于第二方,则将所述全局最佳分割点的具体信息存储在第二方。例如,可将对应的特征归属于第一方的所述全局最佳分割点记录为(sitea,eaf(i)),将对应的特征归属于第二方的所述全局最佳分割点记录为(siteb,ebf(i)),其中sitea表示所述全局最佳分割点存储在a方,siteb表示所述全局最佳分割点存储在b方,eaf(i)表示所述第一方对第一训练样本中样本的第i特征的编码,ebf(i)表示所述第二方对第二训练样本中样本的第i特征的编码。
本实施例中,所述决策树模型建立之后,由所述联邦建模的第一方将所述决策树预测模型保存为第一方决策树预测模型。由此,所述联邦建模的第一方可单独使用所述决策树预测模型对待预测样本进行预测。同时所述联邦建模的第二方将所述决策树预测模型保存为第二方决策树预测模型。所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,即所述联邦建模的双方可联合使用所述决策树预测模型对待预测样本进行预测。
步骤s103,根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测,所述待预测样本缺失所述样本标签。
本实施例中,所述决策树预测模型主要用来预测第一方样本。对于传统的联邦建模方法,在预测过程中,需要联邦建模的双方分别输入各自的样本,才能输出预测结果。本实施例中,可在不需要所述联邦建模的第二方配合的条件下,由所述联邦建模的第一方在所述联邦建模的第一方决策树预测模型中输入待预测样本,由第一方决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。
本实施例中,所述方法还可由所述联邦建模的第一方和第二方,分别在本地保存的第一决策树和第二决策树中,分别输入待预测样本,由所述第二方主导完成对待预测样本的联邦预测。具体地,通过遍历过程遍历梯度提升树模型对应的回归树以确定待预测样本的所属的叶子节点,通过所述遍历过程比较待预测样本的数据点与当前遍历节点的属性值进行确定。
本实施例中,需要预先设置样本标签预测方法。所述根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测的步骤包括:在所述联邦建模的决策树预测模型中输入待预测样本;基于预设的样本标签预测方法计算所述第一方决策树预测模型中每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心;根据所述每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心、叶子节点向量及待预测样本计算每个叶子节点对应的待预测样本的权重;获取使所述权重取最小值时对应的叶子节点;所述叶子节点函数最小值对应的叶子节点在决策树中的结果即为预测结果。
本实施例中,计算第一方决策树预测模型中每个叶子节点对应集合的样本聚类中心,具体地,由第一方使用所述决策树模型对第一方的待预测样本进行预测,所述待预测样本包括样本id和样本特征,所述待预测样本共有m个特征,用xaj表示第一方样本的第j维特征,故将所述待预测样本表示为:
xa={xa1,xa2,...,xam};
对于所述决策树上的第i个叶子节点,将所述第i叶子节点表示为一个有m个元素的am维向量,其中,第k个元素的向量是
其中,xj.θi=(xj1θi1,xj2θi2,...,xjmθim);
获得决策树中所有叶子节点的μi后,根据所述叶子节点对应集合的样本聚类中心μi、叶子节点向量θi及待预测样本计算所述叶子节点i对应待预测样本xa的权重的权重βi,将所述权重βi表示为:
其中,θij表示第i叶子节点第j维特征向量;
根据所述权重βi取最小值时对应的叶子节点i,所述叶子节点i的计算方法为:
i=argmini(βi)
所述权重βi最小值对应的叶子节点i在决策树中的结果即为预测结果。
本实施例通过上述方案,输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此,拓展了联邦建模的应用范围。
进一步地,参照图2,基于上述图1所示的第一实施例,提出了本发明联邦建模方法的第二实施例,所述输入第一训练样本和第二训练样本的步骤之前还包括:
步骤s1001,获取第一方样本和第二方样本,所述第一方样本包括第一样本id和第一样本特征,所述第二方样本包括第二样本id、第二样本特征以及样本标签;
本实施例中,所述第一方样本包括第一样本id和第一样本特征,所述第二方样本包括第二样本id、第二样本特征以及样本标签,其中所述样本id包括用户名、用户联系方式、用户id号码等。所述样本特征包括年龄、性别、收入水平、贷款情况、消费信息、受教育程度等,所述样本标签包括收入水平、贷款情况、消费信息、游戏爱好程度等。所述第一方样本不具有样本标签。在本实施例中所述第一方第一样本id和第一样本特征,所述第二方样本包括第二样本id、第二样本特征以及样本标签。
步骤s1002,对所述第一方样本和所述第二方样本进行筛选,获取第一训练样本和第二训练样本。
所述对所述第一方样本和所述第二方样本进行筛选的步骤包括:
筛选所述第一方样本与所述第二方样本中的重叠样本和非重叠样本,将所述第一方样本和所述第二方样本分为第一方重叠样本、第二方重叠样本、第一方非重叠样本以及第二方非重叠样本;将所述第一方重叠样本和所述第一方缺失样本作为第一训练样本,将所述第二方重叠样本和所述第二方非重叠样本作为第二训练样本。
本实施例中,将所述第一方样本和所述第二方样本分为第一方重叠样本、第二方重叠样本、第一方非重叠样本以及第二方非重叠样本。
参照图3,图三是本发明联邦建模方法一实施例的场景示意图。如图3所示,所述第一方样本包括第一方非重叠样本和第一方重叠样本,所述第二方样本包括第二方非重叠样本和第二方重叠样本。由于第二方样本具有第二样本id、第二样本特征以及样本标签,故将第二方样本作为第二训练样本。而第一方样本不具有样本标签,故在第一方样本中补齐第一方不具有的第二方非重叠样本并表示为第一方缺失样本,再将第一方缺失样本和第一方重叠样本作为第一训练样本。所述第一方重叠样本与所述第二方重叠样本有相同的样本id或样本特征,例如有相同的用户名、相同的消费时间、相同的消费水平等。在筛选所述第一方样本与所述第二方样本中的重叠样本时,可以选择一个或多个相同的样本id,也可以选择一个或多个相同的样本特征,可以是相同样本id或相同样本特征的组合中的一个或多个。所述第一方非重叠样本或所述第二方非重叠样本则不具有预先设定的相同的样本id或样本特征。一般地,所述第一方非重叠样本即为待预测样本。
本实施例通过上述方案,获取第一方样本和第二方样本,所述第一方样本由联邦建模的第一方提供,所述第二方样本由联邦建模的第二方提供;对所述第一方样本和所述第二方样本进行筛选,获取第一训练样本和第二训练样本输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此,拓展了联邦建模的应用范围。
进一步地,参照图4,基于上述第一、二实施例,提出了本发明联邦建模方法的第三实施例,所述输入第一训练样本和第二训练样本的步骤之后还包括:
步骤s1011,对齐所述第一训练样本和所述第二训练样本。
本实施例中,所述第一训练样本包括第一样本id和第一样本特征,所述第二训练样本包括第二样本id、第二样本特征以及样本标签。第一方确定所述第一训练样本和所述第二训练样本中的共同样本特征,将样本id或所述共同样本特征中的一个或多个信息作为训练样本对齐参数。根据所述样本对齐参数,从第二训练样本中获取与所述第一训练样本中样本对齐参数一致的第二训练样本和对应的第一训练样本进行标记,并提取相应的其它样本id或样本特征,之后所述第一训练样本就可根据所述样本对齐参数与所述第二训练样本进行对齐。例如,以训练样本id作为训练样本对齐参数,将训练样本id相同的第一训练样本和第二训练样本进行标记,将标记后的第一训练样本和第二训练样本对齐,则获得对齐后的训练样本。
参照图5,图5是本发明实施例另一实施例的场景示意图。如图所示,将第一训练样本与第二训练样本进行对齐。
本实施例以用户id为例进行详细说明。将训练样本的用户id表示为un,表示训练样本用户id的序号;将第一训练样本的特征表示为xanm,将第二训练样本的特征表示为xbnm,其中,n表示用户id的序号,m表示训练样本的样本特征。以训练样本的用户id作为训练样本对齐参数,将有相同用户id的样本进行对齐,例如将第一训练样本中的第一组样本表示为(u1,xa11,xa12,…,xa1m),将将第二训练样本中的第一组样本表示为(u1,xb11,xb12,…,xb1m,y1),其中y表示第二训练样本中的样本标签,若所述第二训练样本中的样本标签缺失,则丢弃样本标签缺失的样本。继续筛选对齐,直到在所述第一训练样本和所述第二训练样本中获得所有具有相同用户id的样本,并分别对齐所述具有相同用户id的样本,(u1,xa11,xa12,…,xa1m)对齐于(u1,xb11,xb12,…,xb1m,y1),(u2,xa21,xa22,…,xa2m)对齐于(u2,xb21,xb22,…,xb2m,y2)……直到对齐最后一组具有相同用户id的样本(un,xan1,xan2,…,xanm)对齐于(un,xbn1,xbn2,…,xbnm,yn)。
本实施例中,将第一训练样本中不存在于第二训练样本中的样本称为第一方缺失样本,所述第一方缺失样本对应于第二方非重叠样本。在样本对齐过程中,将所述第一方缺失样本补0,记为(0),然后与所述第二方非重叠样本进行对齐。例如将(0)对齐于(un+1,xb(n+1)1,xb(n+1)2,…,xb(n+1)m,yn+1),将(0)对齐于(un+2,xb(n+2)1,xb(n+2)2,…,xb(n+2)m,yn+2),将(0)对齐于(un+t,xb(n+t)1,xb(n+t)2,…,xb(n+t)m,yn+t)。
本实施例中,将第一训练样本与第二训练样本进行对齐后再基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练。
在其它实施例中,可由第一方对第一训练样本进行加密,由第二方对第二训练样本进行加密。由此,能防止训练样本泄露。
本实施例通过上述方案,获取第一方样本和第二方样本,对所述第一方样本和所述第二方样本进行筛选,获取第一训练样本和第二训练样本;输入第一训练样本和第二训练样本;对齐所述第一训练样本和所述第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。由此,通过训练得到的决策树预测模型基于预设的样本标签预测方法,拓展了联邦建模的应用范围。
进一步地,参照图6,基于上述所示的实施例,提出了本发明联邦建模方法的第四实施例,所述根据所述决策树预测模型和样本标签预测方法对待预测样本进行预测的步骤之后还包括:
步骤s104,输出预测结果。
本实施例中,根据所述第一决策树预测模型和预设的样本标签预测方法对待预测样本进行预测之后就能得到预测结果,并由所述第一决策数预测模型在联邦建模的第一方输出所述预测结果,所述预测结果的预测对象为第一方样本不具有的样本标签。具体地,将待预测样本输入所述第一方决策树预测模型,并根据所述预设的样本标签预测方法就得到的所述待预测样本的样本标签的预测结果。一般的,所述待预测样本为第一方所拥有的样本,所述待预测样本不具有样本标签,故可根据所述决策树预测模型进行预测,得到对决策树模型中样本标签的预测结果,并输出所述预测结果。此外,还能保护第一方样本的隐私。
在其它实施例中,可按预设周期对所述决策树预测模型进行更新,以完善所述决策树预测模型,获得准确性更高的预测结果。例如将所述预测周期设为10天、15天、30天等,在到达预设周期后,则重新获取第一训练样本和第二训练样本,可将样本周期时间超过阈值的的训练样本丢弃,使用最新的训练样本,也可在原训练样本的基础上,加入新增的训练样本。再基于xgboost算法和加密算法对重新获取的所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;在需要对待预测样本进行预测时,则根据所述决策树预测模型和样本标签预测方法对待预测样本进行预测。
本实施例通过上述方案,输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此,拓展了联邦建模的应用范围。
此外,本发明还提出一种联邦建模设备,所述设备包括存储器、处理器以及存储在所述存储器上的联邦建模程序,所述程序被处理器执行时实现如下操作:
输入第一训练样本和第二训练样本,所述第一训练样本由联邦建模的第一方提供,所述第二训练样本由联邦建模的第二方提供;
基于极端梯度提升xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型,由所述联邦建模的第一方将所述决策树预测模型保存为第一方决策树预测模型;
在所述联邦建模的第一方决策树预测模型中输入待预测样本,由第一方决策树预测模型基于所述决策树预测模型和样本标签预测方法对待预测样本进行预测。
具体地,如图7所示,本实施例联邦建模设备可以包括:处理器1001,例如cpu,网络接口1004,用户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图6中示出的设备结构并不构成对设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图7所示,作为一种计算机存储介质的存储器1005中可以包括操作装置、网络通信模块、用户接口模块以及联邦建模程序。
在图7所示的设备中,网络接口1004主要用于连接网络服务器,与网络服务器进行数据通信;而处理器1001可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
输入第一训练样本和第二训练样本,所述第一训练样本包括第一训练样本id和第一训练样本特征,所述第二训练样本包括第二训练样本id、第二训练样本特征以及样本标签;
基于极端梯度提升xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;
根据所述决策树预测模型基于所述决策树预测模型和预设的样本标签预测方法对待预测样本进行预测,所述待预测样本缺失所述样本标签。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
获取第一方样本和第二方样本,所述第一方样本由联邦建模的第一方提供,所述第二方样本由联邦建模的第二方提供;
对所述第一方样本和所述第二方样本进行筛选,获取第一训练样本和第二训练样本。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
筛选所述第一方样本与所述第二方样本中的重叠样本和非重叠样本,将所述第一方样本和所述第二方样本分为第一方重叠样本、第二方重叠样本、第一方非重叠样本、第二方非重叠样本以及第一方缺失样本;
将所述第一方重叠样本和所述第一方缺失样本作为第一训练样本,将所述重叠样本和所述第二方非重叠样本作为第二训练样本。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
对齐所述第一训练样本和所述第二训练样本。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
在模型训练的迭代过程中,所述第二方基于当前决策树模型和样本标签计算所述第二训练样本的梯度,并根据加密算法对所述梯度进行加密,将加密后的梯度发送至第一方,由所述第一方根据加密后的梯度计算所述第一训练样本在当前决策树模型中所有分割点的第一收益,将所述第一收益返回至第二方;
所述第二方接收并解密所述第一收益,并结合第二训练样本的第二收益确定全局最佳分割点;
保存所述全局最佳分割点的具体信息;
根据所述全局最佳分割点对当前节点的样本进行分割,生成新的节点;
直到达到预设停止条件,则停止所述迭代过程,得到完整的决策树预测模型。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
判断所述全局最佳分割点对应的特征是归属于第一方还是第二方;
若所述全局最佳分割点对应的特征归属于第一方,则将所述全局最佳分割点的具体信息存储在第一方;
若所述全局最佳分割点对应的特征归属于第二方,则将所述全局最佳分割点的具体信息存储在第二方。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
在所述联邦建模的决策树预测模型中输入待预测样本;
基于预设的样本标签预测方法计算所述第一方决策树预测模型中每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心;
根据所述每个叶子节点对应集合的样本关于所述第一样本特征的聚类中心、叶子节点向量及待预测样本计算每个叶子节点对应的待预测样本的权重;
获取使所述叶子节点函数取最小值时对应的叶子节点;
所述权重最小值对应的叶子节点在决策树中的结果即为预测结果。
进一步地,处理器1001还可以用于调用存储器1005中存储的联邦建模程序,并执行以下操作:
输出预测结果。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有联邦建模程序,所述联邦建模程序被处理器运行时实现如上所述的联邦建模方法的步骤,在此不再赘述。
相比现有技术,本发明提出了一种联邦建模方法、设备及存储介质,输入第一训练样本和第二训练样本;基于xgboost算法和加密算法对所述第一训练样本和所述第二训练样本进行训练,得到决策树预测模型;根据所述决策树预测模型基于预设的样本标签预测方法对待预测样本进行预测。本发明根据所述决策树预测模型基于预设的样本标签预测方法,对待预测样本进行预测,所述方法包括由联邦建模的第一方在第一方决策树预测模型中输入待预测样本,所述方法还包括由联邦建模的第一方和第二方分别在决策树预测模型中输入待预测样本,由此拓展了联邦建模的应用范围。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!